📌 트리의 앙상블
앙상블(Ensemble) : 여러 개의 모델을 사용해서 각각의 예측 결과를 만들고 그 예측 결과를 기반으로 최종 예측결과를 결정하는 방법
-
배깅(Bagging)
: 분할정복(divide and conquer and combine)과 같은 것
: 전체 데이터를 여러개로 분할 후 각 set별로 모델 학습->결합
-> 랜덤 포레스트, 엑스트라 트리 -
부스팅(Boosting)
: 순차적으로 약한 학습자를 추가 결합하여 하나의 강한 모델 만드는 방법
-> 그래디언트 부스팅
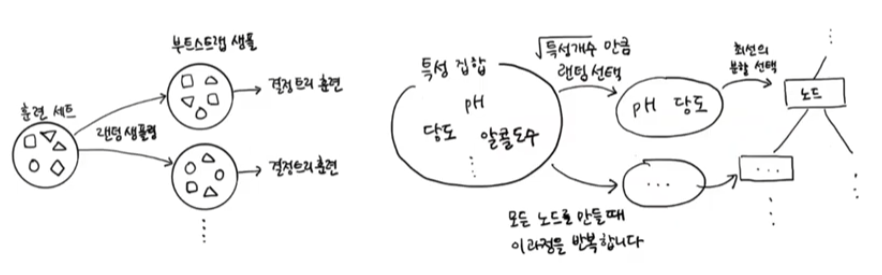
📌 랜덤 포레스트
- 여러개의 랜덤 결정 트리 -> 랜덤 포레스트
- 여러개의 모델 훈련 -> 확률(분류)/예측(회귀)의 평균
- Bootstrap sampling (데이터 내에서 반복적으로 샘플 사용, 중복허용)
- 훈련 샘플 랜덤, 노드를 분할할 특성 랜덤
- Data Set
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
wine = pd.read_csv('https://bit.ly/wine_csv_data')
data = wine[['alcohol', 'sugar', 'pH']].to_numpy()
target = wine['class'].to_numpy()
train_input, test_input, train_target, test_target = train_test_split(
data, target, random_state=42, test_size=0.2
)- 랜덤 포레스트 훈련
from sklearn.model_selection import cross_validate
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(n_jobs=-1, random_state=42)
scores = cross_validate(rf, train_input, train_target,
return_train_score=True, n_jobs=-1)
print(np.mean(scores['train_score']), np.mean(scores['test_score']))
rf.fit(train_input, train_target)
print(rf.feature_importances_)0.9973541965122431 // 훈련 set
0.8905151032797809 // 검증 set
[0.23167441 0.50039841 0.26792718] // 특성 중요도
- OOB sample : 랜덤으로 뽑을 때 마다 남는 샘플들
-> 검증 set로 사용 가능 (oob_score_)
rf = RandomForestClassifier(oob_score=True, n_jobs=-1, random_state=42)
rf.fit(train_input, train_target)
print(rf.oob_score_)0.8934000384837406
📌 엑스트라 트리
- 랜덤 포레스트와 많은 것을 공유함
- 전체 샘플 사용 (Bootstrap sample X)
- 노드 분할시 특성 3개 랜덤 분할 -> 최적을 pick
- 속도 빠름
from sklearn.ensemble import ExtraTreesClassifier
et = ExtraTreesClassifier(n_jobs=-1, random_state=42)
scores = cross_validate(et, train_input, train_target,
return_train_score=True, n_jobs=-1)
print(np.mean(scores['train_score']), np.mean(scores['test_score']))
et.fit(train_input, train_target)
print(et.feature_importances_)0.9974503966084433 // 훈련 set
0.8887848893166506 // 검증 set
[0.20183568 0.52242907 0.27573525] // 특성 중요도
📌 그레이디언트 부스팅
- 앙상블 알고리즘 중 가장 좋음
- 분류-로지스틱 손실함수, 회귀-평균제곱오차 사용
(경사하강법과 마찬가지)
-> 손실값이 낮아지도록 얕은 결정 트리를 추가 - learning-rate : 최저점을 지나치지 않도록 학습 속도 제어
from sklearn.ensemble import GradientBoostingClassifier
gb = GradientBoostingClassifier(random_state=42)
scores = cross_validate(gb, train_input, train_target,
return_train_score=True, n_jobs=-1)
print(np.mean(scores['train_score']), np.mean(scores['test_score']))0.8881086892152563
0.8720430147331015
- 트리 갯수, 속도 증가 시키면
gb = GradientBoostingClassifier(n_estimators=500, learning_rate=0.2, random_state=42)0.9464595437171814
0.8780082549788999
-> 과대적합 억제
- 특성 중요도
gb.fit(train_input, train_target)
print(gb.feature_importances_)[0.15872278 0.68010884 0.16116839] // 당도 중요
📌 히스토그램 기반 그레이디언트 부스팅
- 특성 변환 : 훈련 데이터 -> 256개 구간으로 분할해 학습
-> 제한된 특성의 범위로 빠른 학습
from sklearn.experimental import enable_hist_gradient_boosting
from sklearn.ensemble import HistGradientBoostingClassifier
hgb = HistGradientBoostingClassifier(random_state=42)
scores = cross_validate(hgb, train_input, train_target,
return_train_score=True, n_jobs=-1)
print(np.mean(scores['train_score']), np.mean(scores['test_score']))0.9321723946453317 0.8801241948619236
📍 XGBoost vs LightGBM
- (히스토그램) 그래디언트 부스팅 전용 라이브러리
- 그레디언트 부스트 결정 트리(Gradient Boosted Decision Trees) 알고리즘의 오픈 소스 구현
