- Model Set
--data set 후--
def model_fn(a_layer=None) :
model = keras.Sequential()
model.add(keras.layers.Flatten(input_shape=(28,28)))
model.add(keras.layers.Dense(100, activation='relu'))
if a_layer:
model.add(a_layer)
model.add(keras.layers.Dense(10, activation='softmax'))
return model
model = model_fn()
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
history = model.fit(train_scaled, train_target, epochs=20, verbose=0, validation_data=(val_scaled, val_target))
print(history.history.keys())dict_keys(['loss', 'accuracy', 'val_loss', 'val_accuracy'])
📌 손실 곡선
-
history 객체 : loss, accuracy 속성
각 epoch 마다의 속성값 저장되어있음 -
검증 손실도 확인 (val set)
import matplotlib.pyplot as plt
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train','val'])
plt.show()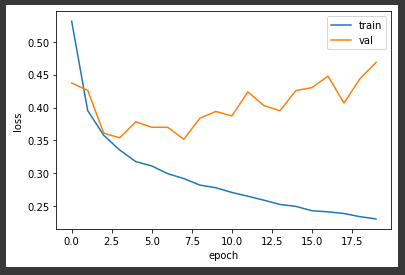
- accuracy
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.legend(['train','val'])
plt.show()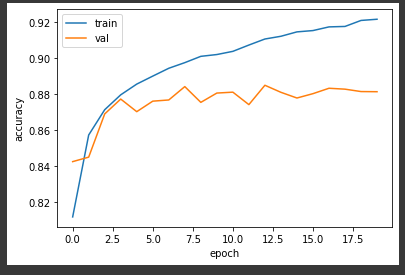
-> 훈련세트에 잘 맞는 과대적합
👉규제 by 드롭아웃
📌 드롭아웃
- 한 샘플을 처리할 때 마다 은닉층의 뉴런 n%를 off하고 계산
-> 특정 뉴런에 과도하게 적합/의존되는 것을 막음 - Dropout() : 은닉층 다음에 드롭아웃층 추가
model.add(keras.layers.Dropout(0.3))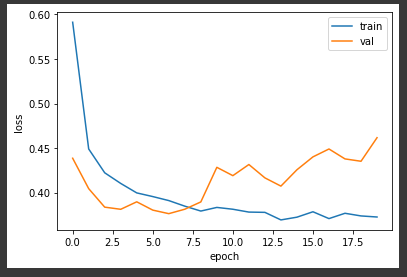
-> 검증 set와 훈련 set의 손실의 차이 감소
📌 모델 저장/복원
- save_weights(' ') : 모델 파라미터(가중치)만 저장
- save(' ') : 모델의 구조도 저장 -> 모델을 만들지 않아도 됨
model.save_weights('model-weghts.h5')
model.save('model-whole.h5')
model.load_weights('model-weights.h5')
model2 = keras.models.load_model('model-whole.h5')
📌 콜백
-
모델을 학습하는 도중에 요청한 작업을 수행하는 함수
-
ModelCheckpoint() : 가장 손실값이 낮은 값을 모델 가중치로 저장
-
EarlyStopping() : 모델 훈련 중 손실값이 감소하다가 증가하는 순간부터는 무의미 -> 조기종료
patience : 몇 번 연속 증가하는 순간 멈출 것인가
restore_best_weights=True : 가장 손실이 낮았던 곳으로 되돌려라 -
콜백 객체 생성, fit()의 callbacks 매개변수에 리스트로 전달
model = model_fn(keras.layers.Dropout(0.3))
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy',
metrics='accuracy')
checkpoint_cb = keras.callbacks.ModelCheckpoint('best-model.h5')
early_stopping_cb = keras.callbacks.EarlyStopping(patience=2,
restore_best_weights=True)
history = model.fit(train_scaled, train_target, epochs=20, verbose=0,
validation_data=(val_scaled, val_target),
callbacks=[checkpoint_cb, early_stopping_cb])
print(early_stopping_cb.stopped_epoch)
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train','val'])
plt.show()12
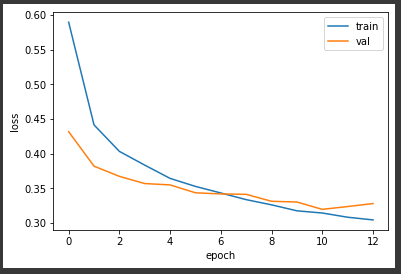
-> 10~12번째에서 2번 연속 loss 값이 증가, 조기종료
