📌 LSTM 신경망
- LSTM 셀
- 은닉상태(h) x 셀(w) 4개 -> 셀(cell)상태
- 셀 상태 에서 순환되는 상태 값
📍 모델 생성
- LSTM(8) : 8개 뉴런, dropout 지정
model = keras.Sequential()
model.add(keras.layers.Embedding(500, 16, input_length=100))
model.add(keras.layers.LSTM(8, dropout=0.3))
model.add(keras.layers.Dense(1, activation='sigmoid'))
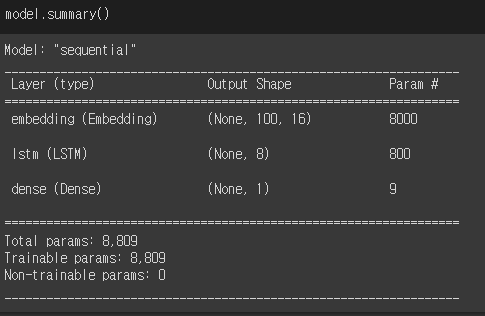
- LSTM Param
( 16개 입력 x 8개 뉴런 완전연결
+8개 뉴런 x 8개 은닉상태
+8개 절편 ) x 4개 셀
= 800
📍 모델 훈련
model.add(keras.layers.LSTM(8, dropout=0.3, return_sequences=True))
rmsprop = keras.optimizers.RMSprop(learning_rate=1e-4)
model.compile(optimizer=rmsprop, loss='binary_crossentropy',
metrics=['accuracy'])
checkpoint_cb = keras.callbacks.ModelCheckpoint('best-2rnn-model.h5',
save_best_only=True)
early_stopping_cb = keras.callbacks.EarlyStopping(patience=3,
restore_best_weights=True)
history = model.fit(train_seq, train_target, epochs=100, batch_size=64,
validation_data=(val_seq, val_target),
callbacks=[checkpoint_cb, early_stopping_cb])
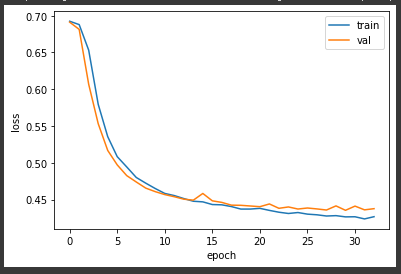
import matplotlib.pyplot as plt
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train', 'val'])
plt.show()
📌 GRU 신경망
- GRU 셀
- 뉴런마다 절편 2개씩 필요
- LSTM보다 효율적. 메모리 절감
📍 모델 생성&훈련
model4 = keras.Sequential()
model4.add(keras.layers.Embedding(500, 16, input_length=100))
model4.add(keras.layers.GRU(8))
model4.add(keras.layers.Dense(1, activation='sigmoid'))
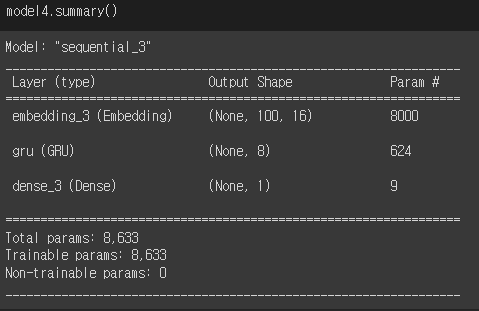
- GRU Param
( 16개 입력 x 8개 뉴런 완전연결
+8개 뉴런 x 8개 은닉상태
+8개 뉴런 x 2개 절편) x 3개 셀
= 624
rmsprop = keras.optimizers.RMSprop(learning_rate=1e-4)
model4.compile(optimizer=rmsprop, loss='binary_crossentropy',
metrics=['accuracy'])
checkpoint_cb = keras.callbacks.ModelCheckpoint('best-gru-model.h5',
save_best_only=True)
early_stopping_cb = keras.callbacks.EarlyStopping(patience=3,
restore_best_weights=True)
history = model4.fit(train_seq, train_target, epochs=100, batch_size=64,
validation_data=(val_seq, val_target),
callbacks=[checkpoint_cb, early_stopping_cb])
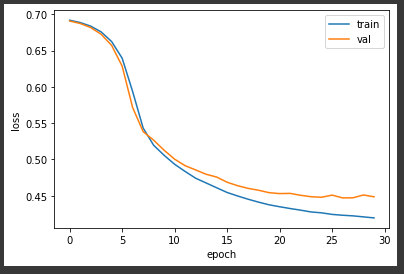
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train', 'val'])
plt.show()
🔗 혼공 MLDL-25
