📌 Data set
📍 넘파이를 이용한 fish data, target
column_stack()
length, weight를 각각 1열로 정렬하여 [length, weight] 쌍으로concatenate()
배열을 나란히 붙여줌ones(n) / zeros(n,m) / full((n,m),9)
[1]x n / [0]x nxm / [9]x nxm 배열 생성
import numpy as np
fish_data = np.column_stack((length, weight))
fish_target = np.concatenate((np.ones(35), np.zeros(14)))📍 사이킷런으로 데이터 나누기
train_test_split()
훈련 set, 테스트 set 나누어줌
stratify 매개변수에 적절히 나누어져야하는 리스트를 입력
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(
fish_data, fish_target, stratify=fish_target, random_state=42
)📌 새로운 데이터 판별하기
- k-최근접 이웃으로 정확도 판별
from sklearn.neighbors import KNeighborsClassifier
kn = KNeighborsClassifier()
kn.fit(train_input, train_target)
kn.score(test_input, test_target)1.0
📍 길이 25, 무게 150인 물고기 = ?
- 빙어로 판별
print(kn.predict([[25, 150]]))[0.]
- 가장 근접한 5개의 데이터 -> indexes 저장
distances, indexes = kn.kneighbors([[25, 150]])
print(distances, indexes)[[ 92.00086956 130.48375378 130.73859415 138.32150953 138.39320793]] [[21 33 19 30 1]]
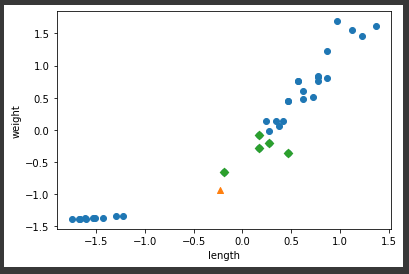
- 각 데이터 구분해서 산점도 그리기
import matplotlib.pyplot as plt
plt.scatter(train_input[:, 0], train_input[:, 1])
plt.scatter(25, 150, marker='^')
plt.scatter(train_input[indexes, 0], train_input[indexes, 1], marker='D')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()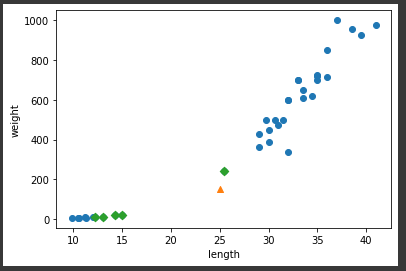
-> x축, y축의 스케일이 맞지 않아서 문제 발생
📍 스케일 문제
- x축의 범위 -> 0~1000
plt.xlim((0,1000))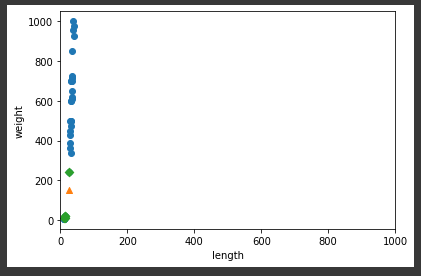
-> 스케일이 큰 특성(무게)의 영향을 받아 최근접 탐색
📍 기준 맞추기 - 표준 점수
- 표쥰 점수 z = (특성 - 평균) / 표준편차
- mean(), std() 함수로 평균과 표준편차 구하기
- 36x2 배열 - 1x2 배열 => 모든 행에 대해 적용해줌 (넘파이 브로드캐스팅)
mean = np.mean(train_input, axis=0)
std = np.std(train_input, axis=0)
train_scaled = (train_input - mean) / std
new = ([25, 150] - mean) / std
plt.scatter(train_scaled[:, 0], train_scaled[:, 1])
plt.scatter(new[0], new[1], marker = '^')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()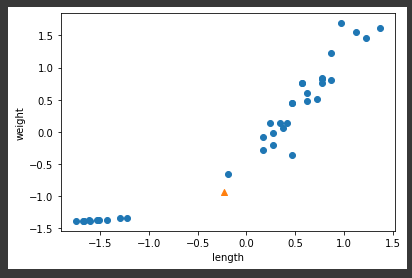
📍 데이터 전처리 후 모델 예측
- 도미로 판별
kn.fit(train_scaled, train_target)
test_scaled = (test_input - mean) / std
print(kn.predict([new]))[1.]
- 다시 최근접 판별 후 산점도 그리기
distances, indexes = kn.kneighbors([new])
plt.scatter(train_scaled[:,0], train_scaled[:,1])
plt.scatter(new[0], new[1], marker='^')
plt.scatter(train_scaled[indexes, 0], train_scaled[indexes,1], marker='D')
plt.xlabel('length')
plt.ylabel('weight')
plt.show(