📌 회귀
- k-최근접 이웃 분류 vs k-최근접 이웃 회귀
분류는 다수결 채택, 회귀는 target 값의 평균
📍 Data Set
- 사이킷런 train_test_split()
- 회귀에서는 적절히 섞는 stratify 필요 X
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(
perch_length, perch_weight, random_state=42
)- 이전과 다르게 입력, 출력 리스트가 1차원 넘파이 배열임
- 샘플 x 특성 2차원 리스트로 변경
-> reshape(-1, 1) : 열이 1개인 2차원 배열로
train_input = train_input.reshape(-1, 1)
test_input = test_input.reshape(-1, 1)📍 회귀 모델 훈련
- KNeighborsRegressor()
- 회귀의 score = 결정계수 R²
R² = 1 - { Σ(타깃 - 예측)² / Σ(타깃 - 평균)² }
예측->평균 👉 R² -> 0 bad
예측->타깃 👉 R² -> 1 good
from sklearn.neighbors import KNeighborsRegressor
knr = KNeighborsRegressor()
knr.fit(train_input, train_target)
knr.score(test_input, test_target)0.992809406101064 -> good
- |예측-타깃| 오차의 평균
from sklearn.metrics import mean_absolute_error
test_prediction = knr.predict(test_input)
mae = mean_absolute_error(test_target, test_prediction)
print(mae)19.157142857142862
📍 과대적합 / 과소적합
- 훈련set, 테스트set 모두 이용해 평가
- 일반적으로 score(train) > score(test)
knr.score(train_input, train_target)0.9698823289099254
-> train 점수가 낮음 = 과소적합
if ) test 점수가 과하게 낮음 = 과대적합
👉 적절한 이웃 k의 개수가 중요 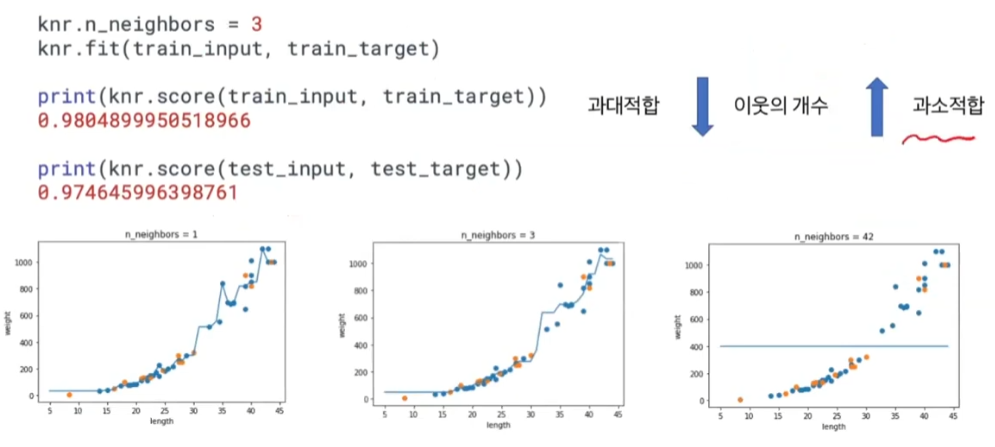
- 이웃의 개수 k가 과하게 작으면 과대적합
if) k=1 -> 이웃으로 평균을 내므로 그래프가 완만하지 못함 - 이웃의 개수 k가 과하게 크면 과소적합
if) k=42 -> 전체의 평균이 되므로 값이 하나가 됨
