✏️Sequential Model
- sequential data : audio, text, video ...
Naive sequence model
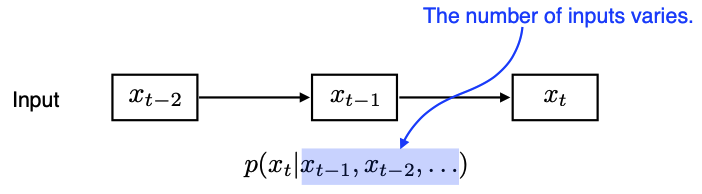
- 몇 개의 input이 들어오든 이 모델은 동작할 수 있어야 한다.
- 시간(layer)이 흐를수록 고려하는 과거 정보량이 점점 늘어남. ex) language model
Autoregressive model
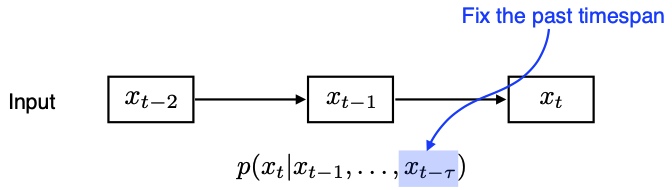
- Fix the past timespan → ex) (timespan=5) : 과거 5개의 정보만 사용하겠다.
Markov model ( first-order autogregressive model = AR(1) )
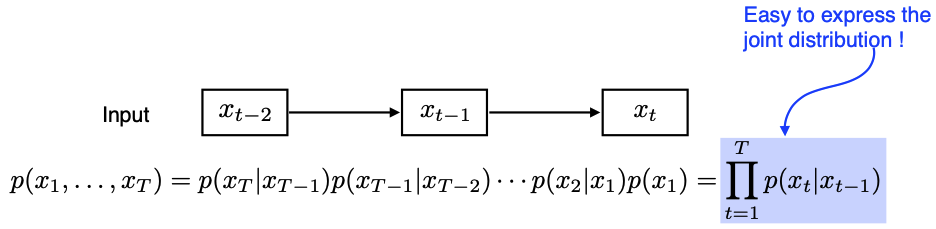
- markov model은 많은 정보를 버리게 된다. But joint distribution 표현에는 용이!
Latent autoregressive model
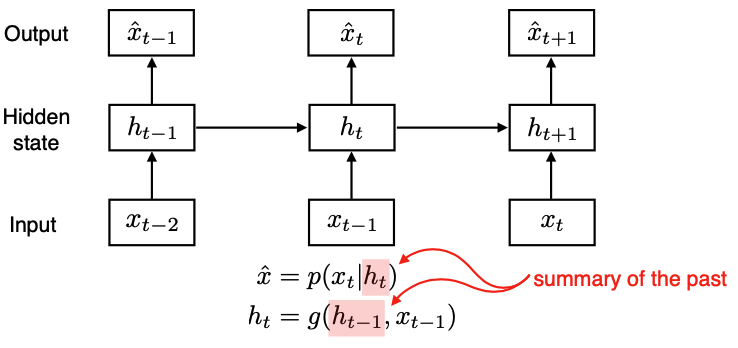
- AR(1)의 단점 : 과거의 많은 정보를 고려해야 하는데, 불가능.
-> 과거 정보를 요약 & 전달하는 hidden state을 사용
✏️RNN (Recurrent Neural Networks)
Vanilla RNN
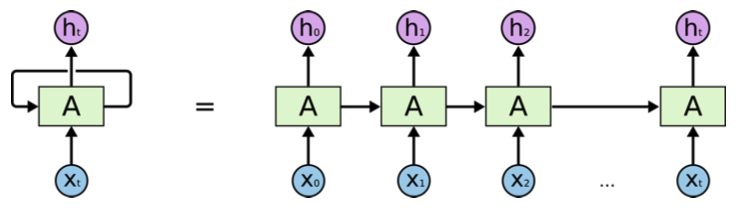
- 오른쪽 도식은 RNN 구조를 unroll time한 것
-> RNN을 시간 순으로 풀면 입력이 굉장히 많은 FC layer로 표현될 수 있다.
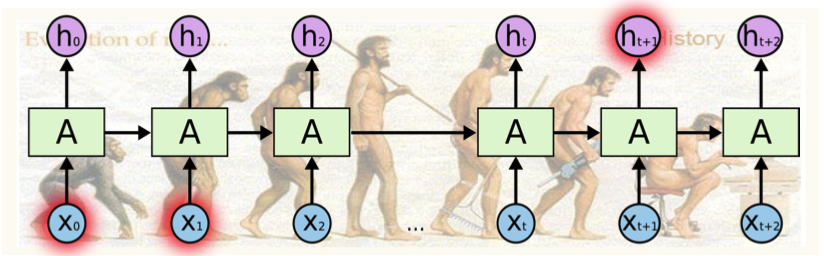
- Short-term dependencies
-> 먼 과거 정보가 미래까지 전해지기 어렵다. - Long-term dependencies를 위해 LSTM으로 보완
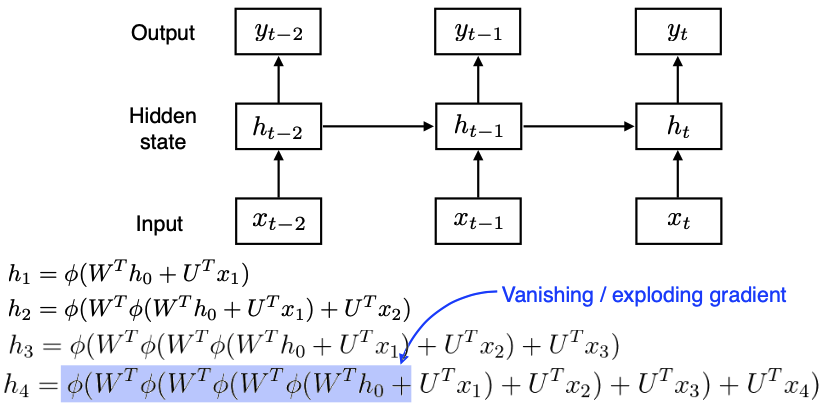
- 학습이 어려운 이유 : unroll in time → layer의 width가 time step만큼 길어지는, deep neural network가 되기 때문
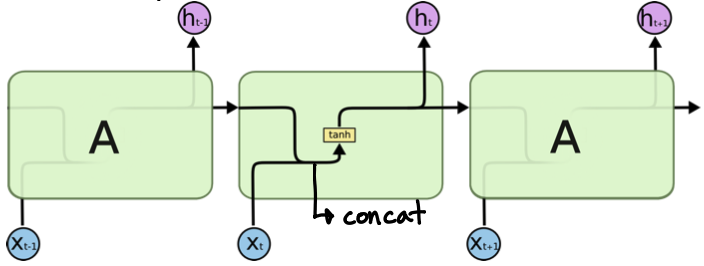
LSTM(Long Short Term Memory)
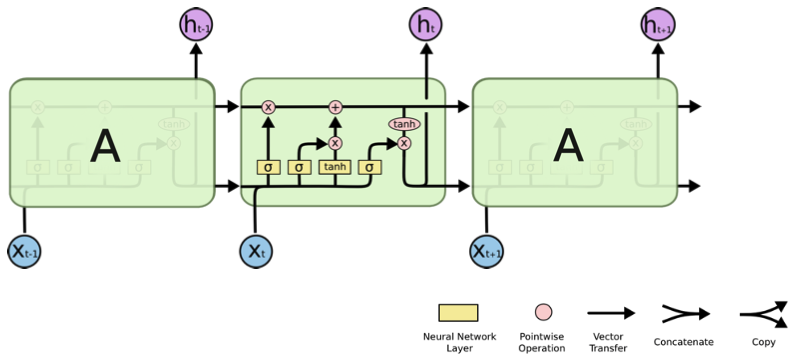
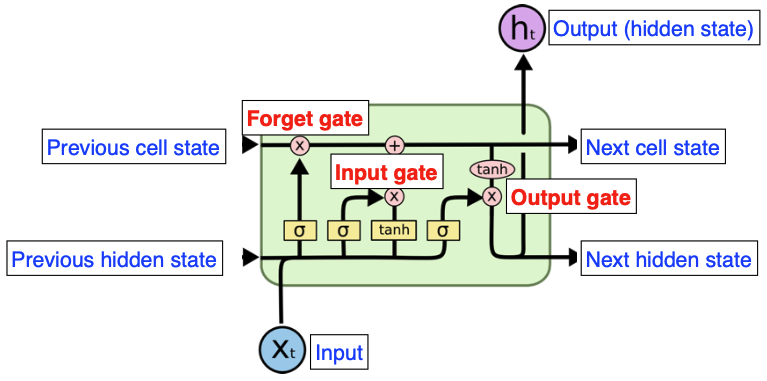
- # input = 3, # output = 3 → 실제로 나가는 output은 1개
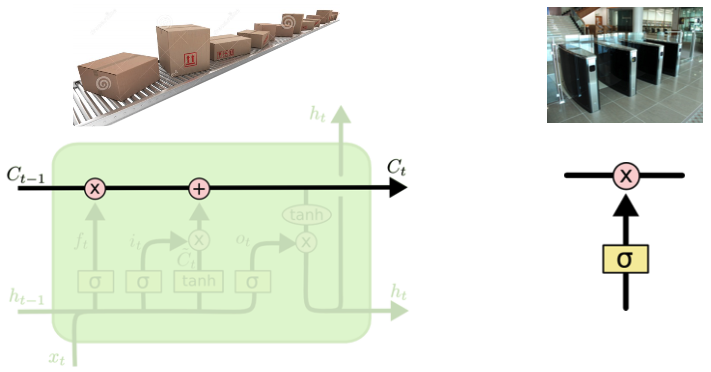
- Cell State : 0 ~ t-1 까지의 정보를 다 취합한 summary 정보; 밖으로 나가지 않는 정보
-> 정보의 유용성을 판단하여 다음 t-state layer로 넘김 (컨베이어 벨트에 상자를 올리고 빼는 것처럼)
-> element-wise multiplication(x) : gate 역할
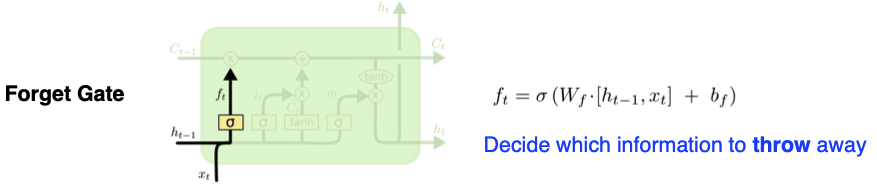
- Forget Gate : 정보를 빼고 유지

- Input Gate : cell state candidate 선별
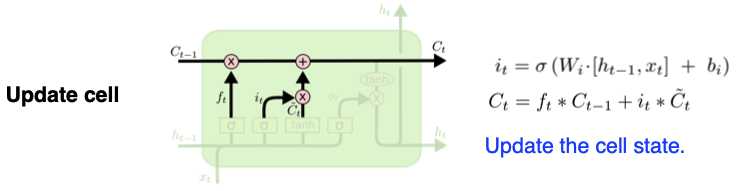
- Update Cell : 버릴 정보는 버리고, 현재 정보 기준으로 유지할 건 하고 업데이트
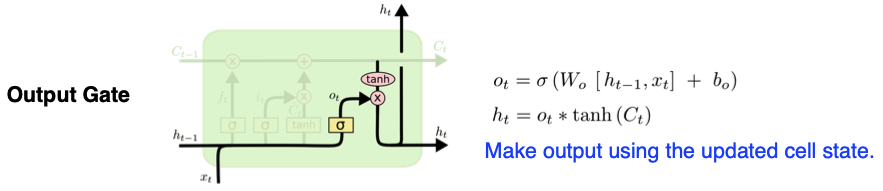
- Output Gate : 다음 time state로 hidden state을 넘기고, output 출력
GRU(Gated Recurrent Unit)
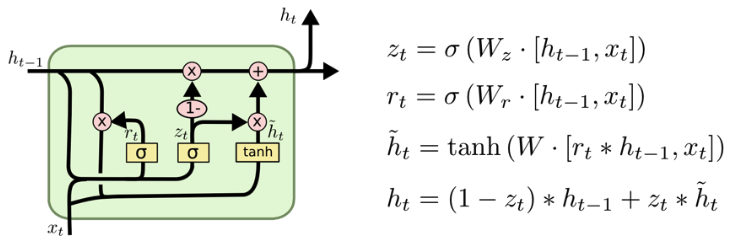
- simpler architecture with two gates : reset gate(≈ forget gate) and update gate
- No cell state, just hidden state
- # parameters ⬇ than LSTM → generalization performance ⬆ → LSTM보다 성능 좋을 때 있다.
- NYU 조경현 교수님 작품
✏️Transformer
- 최근엔 LSTM & GRU 사용 X → RNN 구조를 transformer로 거의 대체
