📕(강의) Dataset & Data Generation
- Vanilla dataset에서, 모델에 맞는 dataset으로 변환이 필요
Pre-processing (전처리)
- 중요한 작업 - 80% pre-processing, 20% modeling, etc..
-> ML pipeline에 있어 큰 비중을 차지한다. - Real data는 매우 raw하다. - outlier, noise 등
- 좋은 data가 model의 성능을 향상시키는 건 자명한 사실
Bounding box

- 가끔 필요 이상으로 많은 정보를 가지고 있기도 한다.
Resize
- 계산의 효율을 위해 적당한 크기로 사이즈 변경
- 모델 성능에 큰 영향을 주는 경우는 별로 없다.
- 효율적인 사이즈를 찾고 여러 실험을 진행하는 것이 더 좋다.
Example: APTOS Blindness Detection
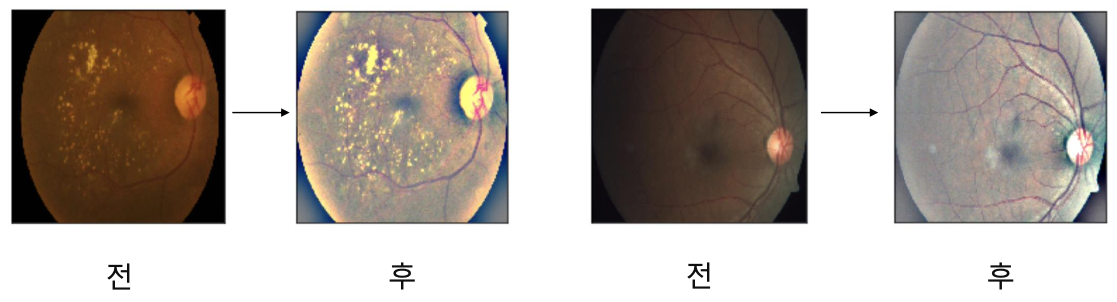
- Domain, data format에 따라 정말 다양한 case가 존재
- master key는 아니지만, 전처리를 진행함으로써 좋은 결과를 도출 해낼 수 있다.
- 실험을 통해 당위성을 증명해내자!
Generalization
Bias & Variance
- 모든 데이터는 noise가 존재한다.
- noise까지 잘 fitting하는 모델은 분산이 크다(High Variance). → overfitting
- data가 적고, 학습이 적어 일부분에 대한 편향된 결과를 갖는다(High Bias). → Underfitting
Train & Validation
- train set 중 일정 부분을 따로 분리, validation set으로 활용
- data가 줄기 때문에 bias된다고 생각할 수도 있는데, 학습에 이용하지 않은 분포를 통해 얼만큼의 일반화를 갖는지 checking하기 위해 validation set이 필요
- 성능에 집적적인 영향을 주는 절차보다 확인용 절차
Data Augmentation

- data를 일반화하는 과정
-> 주어진 데이터가 가질 수 있는 case(경우), state(상태)의 다양성 - noise data에 robust한 모델을 만들 수 있음
- 문제가 만들어진 배경과 모델의 쓰임새를 살펴보면 힌트를 얻을 수 있다.
'무조건' 이라는 단어를 제일 조심하자.
- 항상 좋은 결과를 가져다 주지 않음
- 위 함수들은 여러가지 도구 가운데 하나일 뿐, 무조건 적용 가능한 마스터 키 같은 것도 사실 없다.
- 앞서 정의한 problem(주제)을 깊이 관찰해서 어떤 기법을 적용하면 이러이러한 다양성을 가질 수 있겠다 가정하고 실험으로 증명해야 한다.
Albumentations 라이브러리
- pytorch transforms보다 좀 더 빠르고, 더 다양하다.
