[논문리뷰] Deep Self-Attention Distillation for Task-Agnostic Compression of Pre-Trained Transformers (MiniLM)
논문리뷰
목록 보기
5/6
TL; DR
<모델 아키텍처 요약>
- 마지막 Transformer block의 attention 정보만 사용하여 distilation
- Self-attention between Query & Key, Self-attention betwwen Values 이라는 추가적인 self-attention 연산을 통해 모방을 깊은 정보를 더 잘 학습할 수 있도록 함
1. Architecture 요약
저자들은 기존 DistilBERT, TinyBERT, MobileBERT 와 같은 distilation 모델의 학습방법과 다른 방법을 제시하였습니다. 이전 모델들과는 다르게 student모델의 아키텍처를 좀 더 유연하게 조절할 수 있다고 하였습니다.’
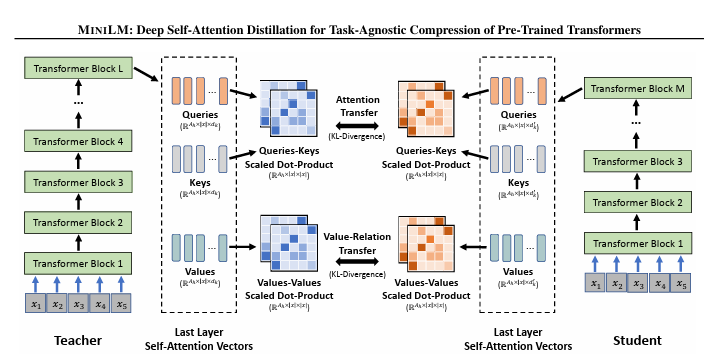
핵심 아이디어는 self-attention 모듈을 최대한 모방하도록 훈련시키는 것입니다, MiniLM 모델은 이전 접근들과는 다르게 가장 마지막 Transformer block 내 attention 모듈의 정보만을 활용합니다. 이러한 방법을 통해 student 모델이 더 유연한 아키텍처를 가질 수 있도록 합니다.
attention 모듈의 정보 중 아래와 같은 추가적인 attention 연산을 통해 matrix을 얻어내고 이 matrix를 통해 정보를 student 에게 transfer 하게 됩니다. loss function은 MSE 혹은 KL-Divergence가 적절하다고 하였고, 저자들은 KL-Divergence를 사용했다고 하였습니다.
- Self-attention between Query & Key
- Self-attention betwwen Values
저자들은 MiniLM이 유사한 distilation 모델 들 중에서는 SOTA 성능을 내는 결과를 보인다고 하였습니다.
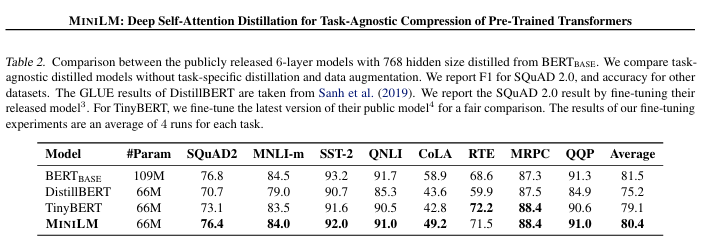

바로 활용 가능한 정보 공유를 목적으로 합니다