[논문리뷰] Pre-training of Deep Bidirectional Transformers for Language Understanding (BERT)
논문리뷰
목록 보기
4/6
TL;DR
- Model features
- 양 방향의 모든 단어 정보를 활용하여 NSP task를 수행하도록 설계
- Pre-training 후 Fine-Tuning을 하는 방식을 통해 높은 성능을 보이도록 설계
1. Introduction 요약
BERT는 Pre-Training & Fine-Tuning 단계를 나누어 학습함으로서 다양한 Downstream task를 수행할 수 있는 모델을 효과적으로 만들 수 있다고 언급합니다. Transformer의 Encoder 및 Decoder 모듈을 둘다 활용하여 GPT-1과는 다르게 Token Classification을 수행 시 양방향의 정보를 모두 사용합니다. 저자들은 이러한 방법이 문장의 context를 학습시키는 데 효과적으로 작용하는 구조라고 주장합니다.
2. Architecture 요약
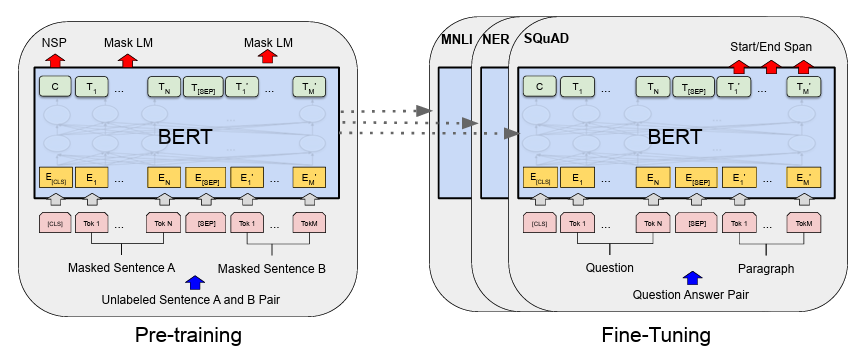
저자들은 GPT-1과 다르게 Pre-training 단계 후 Fine-Tuning 단계를 거쳐 Downstream task를 수행하는 모델을 만들었을 때 더 효과가 좋다고 언급하였습니다.
또한 Bidirectional 이란 의미를 반영하듯, 왼쪽 Pre-training 단계에서 Masked Language Modeling 방식으로 학습하게 됩니다. 특정 위치에 있는 토큰이 무엇인지 분류할 때 양방향의 모든 토큰의 정보를 활용하여 예측하게 됩니다.
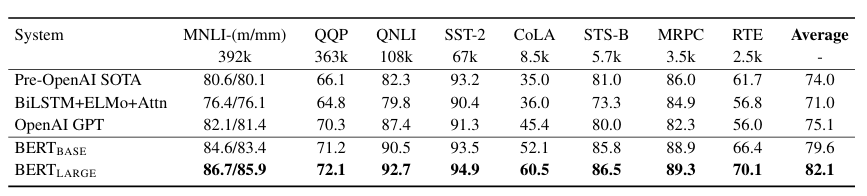
저자들은 기존 RNN 기반 아키텍처 및 OpenAI GPT 비해 압도적인 성능을 보여줄 수 있음을 증명하였습니다. 특히, large 사이즈의 BERT는 모든 task에서 SOTA를 달성하는 모습을 보여줬습니다.

바로 활용 가능한 정보 공유를 목적으로 합니다