TL;DR
- Model features
- 준지도학습과 지도학습을 동시에 수행 (Next Token Prediction + Task Classification)
- Masked Self-Attention을 통해 NSP시 예측할 토큰 이전의 토큰의 정보만 사용하도록 함
- Next Token Prediction과 Task Classification Loss의 비중도 학습하도록 설정
1. Introduction 요약
저자들은 Transformer 아키텍처를 활용해 여러 유형의 task에 대해 높은 성능을 보일 수 있음을 연구성과로 제시하였습니다. 비지도학습과 지도학습의 결합으로 여러 task에 알맞는 모델을 연구하였다고 언급하였습니다. 비지도학습은 Next Token Prediction을 의미하여 지도학습은 각 task에 대한 예측을 의미합니다.
2. Architecture 요약
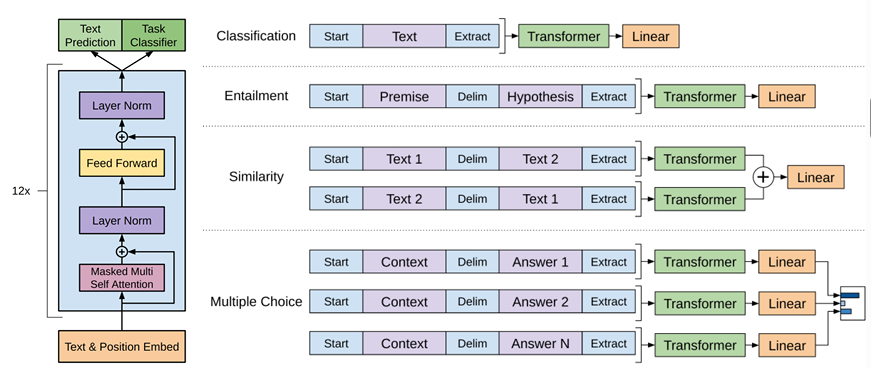
위는 GPT-1의 아키텍처 입니다. Transformer 구조를 그대로 가져왔으나, 각 토큰에 대한 예측을 수행할 때 직전 토큰까지의 정보만을 활용하는 Masked Self-Attention이 핵심입니다. Fine-Tuning은 NSP 와 Task Classification을 같이 수행하는 것으로 학습됩니다. Next Token Prediction은 ‘Text Prediction’이 Task Classification은 ‘Text Classifier’가 각각 수행됩니다.
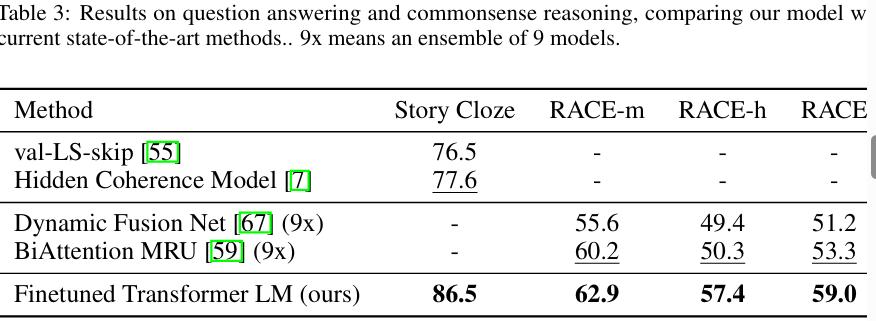
저자들은 위와같이 특히 Q&A 및 commonsense reasoning 에서 두드러진 성능을 보인다고 말합니다. 이러한 부분은 또한 GPT가 긴 문맥을 효과적으로 파악하고 그에 대한 추론을 할 수 있다는 것을 설명하는 것이라고 합니다.

바로 활용 가능한 정보 공유를 목적으로 합니다