랭체인에 대해서 개인적인 정리글 입니다.
익숙한 앵무새 그림이죠 LLM을 서비스로 활용할 때 필수적인 요소인 랭체인에 대한 이야기를 해보겠습니다.
LLM을 실제 서비스에 적용하고 사용할 때는 여러가지 부가적인 문제들이 있습니다. chat-gpt를 예로 들자면 최신의 데이터를 학습하지 못한 상태에서 해당 질문에 대한 거짓답변 혹은 답변하지 못하는 경우가 있고, 신뢰성 없는 데이터들도 함께 학습을 하는 탓에 거짓된 답변을 하기도 합니다. 이를 AI 할루시네이션 현상이라고 하죠
간단한 검색이나 질문을 위해서 chat-gpt를 사용할 때는 별다른 문제점을 못 느낄 수 있지만 신뢰성이 중요한 서비스를 구성하거나 중요한 질문을 할 때는 큰 문제가 될 수 있습니다.
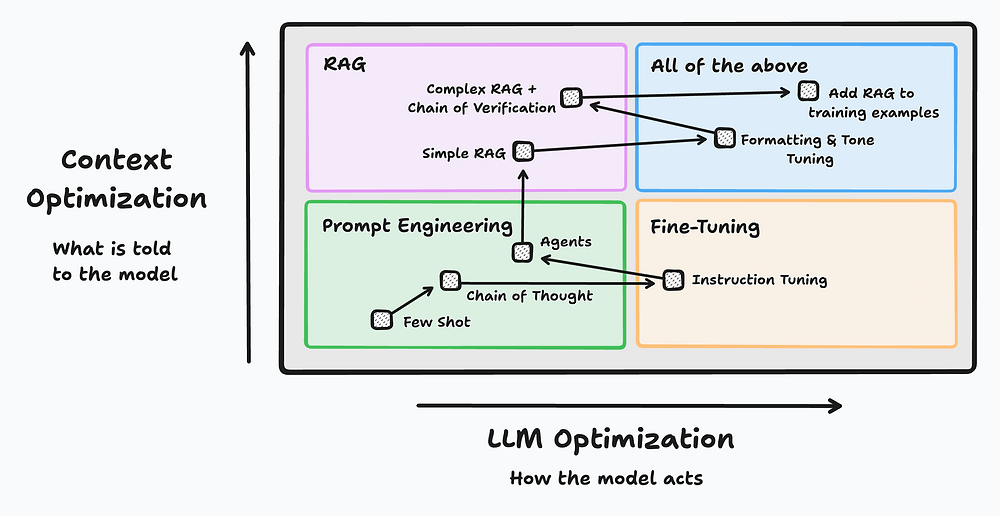
chat-gpt의 전문성을 향상시키고 더 나은 결과 값을 받기 위해서 다양한 방법론들이 있지만 위의 3가지 방법론들이 많이 사용됩니다.
- Fine-Tuning
사전 학습된 모델의 파라미터를 특정 작업에 맞게 조정하는 과정입니다. 사전 학습된 데이터셋보다는 작은 소규모의 데이터셋을 사용하여 특정 분야에서 더 나은 성능을 보이도록 합니다.- In-context Learning
LLM 모델이 주어진 프롬프트 내에서 제공된 예시나 지시사항을 바탕으로 작업을 수행하는 학습 방식입니다. 이 과정에서 모델의 파라미터는 변경되지 않고, 단지 입력된 예시를 기반으로 추론을 합니다.- RAG(Retrieval-Augmented Generation)
외부 데이터 소스에서 관련 문서를 검색하고, 이를 바탕으로 생성된 응답을 보강하는 방식입니다.
근거가 보장되어있는 답변을 하기 때문에 향상된 신뢰성과 전문성을 보입니다.
여기서 langchain은 In-context Learning과 RAG를 사용하여 LLM의 단점을 보완할 수 있는 프레임워크입니다.
langchain은 아래와 같은 요소/모듈들로 이루어져 있습니다.
- Models: 랭체인의 코어로 답변을 생성하는 주요 모델입니다.
ex) LLMs, Chat Models, Text Embedding Models - Prompts: 모델에 지시하는 명령문입니다.
Prompt Templates, Example Selectors, Output Parsers - Indexes: 모델이 문서를 쉽게 탐색 할 수 있도록 만들어주는 모듈입니다.
Document Loaders, Text Splitters, Vector Stores, Retrievers - Memory: 이전의 대화내역을 기억하고 차후의 대화에 사용할 수 있도록 하는 모듈입니다.
Chat Message History, Various Memory Types - Chains: 모델들의 사슬을 형성하여 연속적인 호출을 가능하도록하는 모듈입니다.
LLMChain, Sequential Chain, Router Chain - Agents: 기존의 프롬프트로는 불가능한 작업을 가능하게하는 모듈입니다.
Agent Types, Tools, Toolkits, Agent Executors

언제나 탐구하는 개발자입니다.