
우리는 실제 부동산 회사에 최근에 고용된 데이터 과학자라고 가정합시다. 그리고 이 머신 러닝 프로젝트를 처음부터 끝까지 살펴봅시다!!
1. Look at the big picture
Frame the problem

최종 목표
주택 가격 예측(머신러닝 모델)을 통해서 해당 지역이 투자할 가치가 있는지 파악하고, 투자를 통해 수익을 얻는 것이 최종 목표입니다.
현재 상황
현재 지구의 주택 가격은 전문가들에 의해 수동으로 추정되고 있습니다: 팀은 지구에 관한 최신 정보를 수집하고, 주택 가격을 얻을 수 없을 때 복잡한 규칙을 사용하여 추정합니다.
이것은 비용이 많이 들고 시간이 많이 걸리며, 그들의 추정치는 그리 좋지 않습니다. 실제 주택 가격을 알아낼 수 있는 경우에 종종 그들의 추정치가 20% 이상 벗어났음을 깨달았습니다.
Q1. 먼저 문제를 설정해야 합니다: 지도 학습, 비지도 학습, 또는 강화 학습 중 어떤 것인가요?
주어진 dataset에 레이블이 붙어 있기 때문에, 이것은 전형적인 지도 학습 작업입니다 (각 인스턴스는 예상 출력값, 즉, 주택 가격과 함께 제공됩니다).
Q2. 분류 작업, 회귀 작업, 또는 다른 것인가요?
multiple regression, univariate regression
Q3. 배치 학습이나 온라인 학습 기법 중 어떤 것을 사용해야 하나요?
시스템으로 지속적으로 데이터가 들어오지 않으며, 빠르게 변화하는 데이터에 적응할 특별한 필요성이 없고, 데이터가 메모리에 충분히 들어갈 만큼 작기 때문에, 단순한 배치 학습이 잘 맞을 것입니다.
Select a performance measure
RMSE(L2) vs MAE(L1)
RMSE(평균 제곱근 오차)가 MAE(평균 절대 오차)보다 이상치(outliers)에 더 민감합니다. 그러나 이상치가 지수적으로 드물게 발생하는 경우 (예: 종 모양의 곡선에서처럼), RMSE는 매우 잘 작동하며 일반적으로 선호됩니다.
2. Get the data
일반적인 환경에서 데이터는 관계형 데이터베이스(또는 다른 일반적인 데이터 저장소)에 저장되어 있을 것이며 여러 테이블/문서/파일에 분산되어 있을 것입니다.
그러나 이 프로젝트에서는 상황이 훨씬 간단합니다: 당신은 단순히 하나의 압축 파일인 housing.tgz를 다운로드할 것입니다. 이 파일 안에는 모든 데이터가 포함된 쉼표로 구분된 값(CSV) 파일인 housing.csv가 있습니다.
fetch the data
import os
import tarfile
from six.moves import urllib
DOWNLOAD_ROOT = "https://raw.githubusercontent.com/ageron/handson-ml2/master/"
HOUSING_PATH = os.path.join("datasets", "housing")
HOUSING_URL = DOWNLOAD_ROOT + "datasets/housing/housing.tgz"
def fetch_housing_data(housing_url=HOUSING_URL, housing_path=HOUSING_PATH):
if not os.path.isdir(housing_path):
os.makedirs(housing_path)
tgz_path = os.path.join(housing_path, "housing.tgz")
urllib.request.urlretrieve(housing_url, tgz_path)
housing_tgz = tarfile.open(tgz_path)
housing_tgz.extractall(path=housing_path)
housing_tgz.close()Load the data
import pandas as pd
def load_housing_data(housing_path=HOUSING_PATH):
csv_path = os.path.join(housing_path, "housing.csv")
return pd.read_csv(csv_path)Take a quick look at data structure
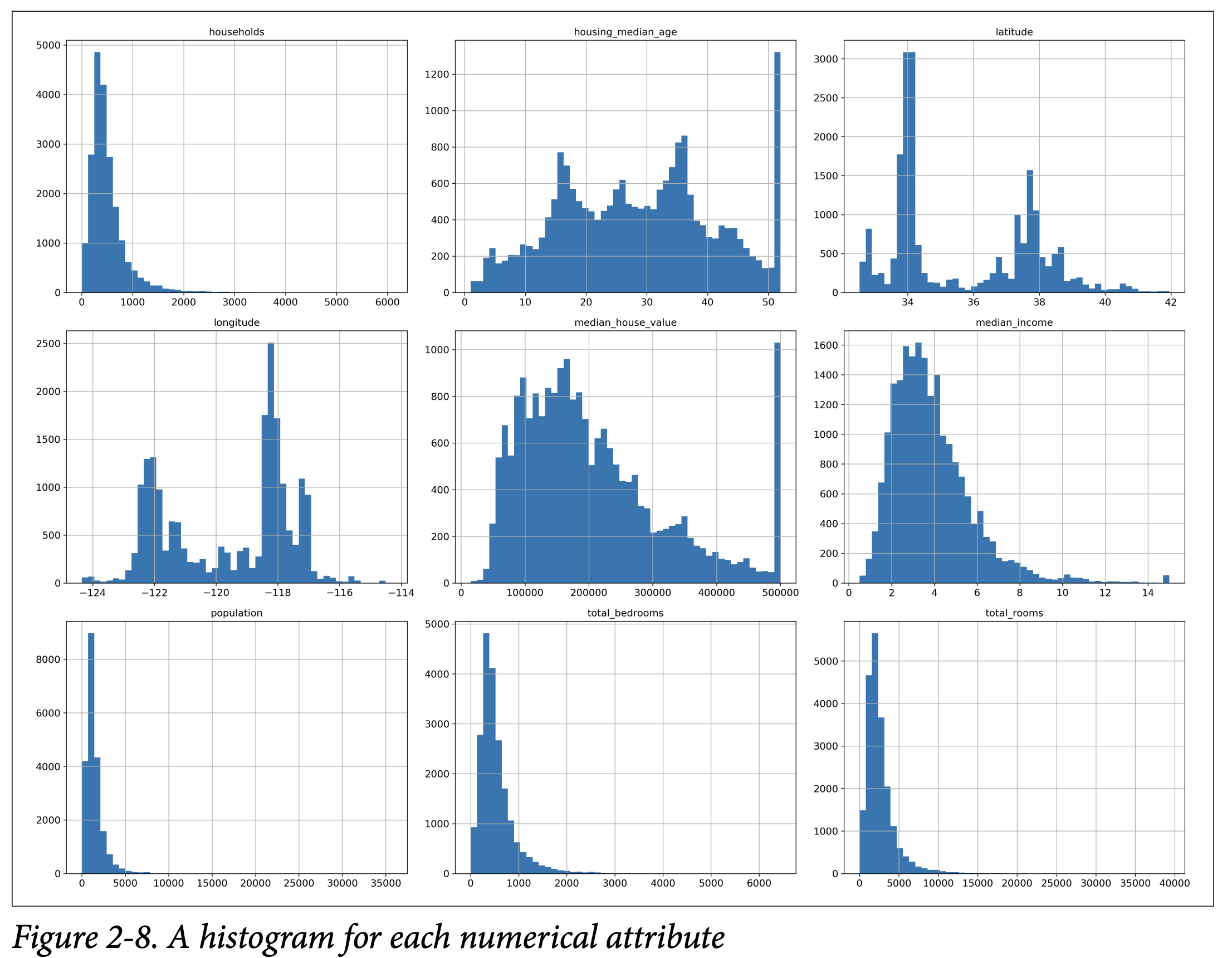
이 히스토그램에서 주목해야 할 몇 가지 사항들이 있습니다:
첫째, 중앙 소득 특성이 미국 달러(USD)로 표현된 것처럼 보이지 않습니다. 데이터는 스케일링되어 있고, 높은 중앙 소득에 대해 15에서, 낮은 중앙 소득에 대해 0.5에서 상한을 설정했습니다. 숫자는 대략 수만 달러를 나타냅니다 (예: 3은 $30,000을 의미합니다).
주택 중앙 연령 및 중앙 주택 가치도 상한을 설정했습니다. 중앙 주택 가치는 당신의 목표 특성(당신의 레이블)이므로, 이것은 심각한 문제가 될 수 있습니다. $500,000 이상에서도 정확한 예측이 필요하다면 두 가지 옵션이 있습니다:
• 상한을 설정한 지역의 적절한 레이블을 수집합니다.
• 해당 지역을 훈련 세트와 테스트 세트에서 제거합니다.
이러한 속성들은 매우 다른 스케일을 가지고 있습니다.
마지막으로, 많은 히스토그램이 끝이 무거워 보입니다. 이것은 일부 기계 학습 알고리즘이 패턴을 감지하는 데 어려움을 겪을 수 있습니다. 나중에 이러한 속성을 더 종 모양의 분포를 가지도록 변환해 볼 것입니다.
Create a test set
데이터셋의 일반적으로 20% (데이터셋이 매우 크다면 그보다 적게)를 무작위로 선택하고, 그것들을 따로 빼놓습니다.
3. Discover and visualize the data to gain insights
먼저, 테스트 세트를 따로 빼놓았는지 확인하고 훈련 세트만 탐색하고 있는지 확인하세요. 또한, 훈련 세트가 매우 크다면, 조작을 쉽고 빠르게 하기 위해 탐색 세트를 샘플링하는 것이 나을 수 있습니다.

해변가에 위치한 집들이 높은 가격을 형성하고 있다는 것을 알 수 있습니다.
Looking for Correlations
데이터셋이 너무 크지 않기 때문에, standard correlation coefficient (also called Pearson’s r)를 쉽게 계산할 수 있습니다. standard correlation coefficient는 선형 상관 관계만을 측정합니다.
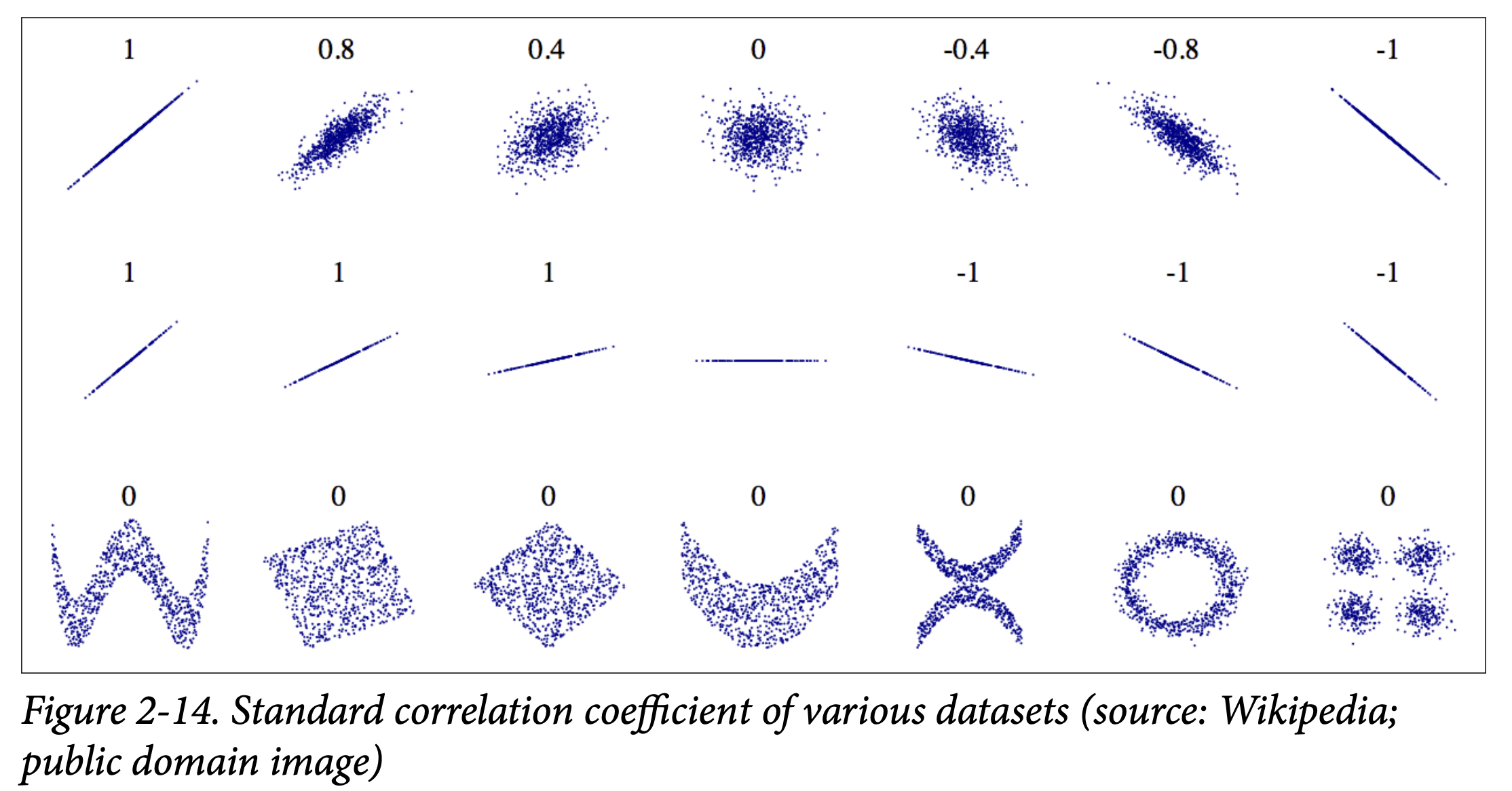

전체 침실 수보다 전제 방 수 보다는 bedrooms_per_room이 더 좋은 correlation 값을 보입니다. 이런 식으로 feature를 만들어 사용할 수 있습니다.
4. Prepare the Data for Machine Learning Algorithms
Data Cleaning
-
Separate the predictors and the labels
-
Take care of missing features
Ex: total_bedrooms attribute has some missing values, so let’s fix this.- Get rid of the corresponding districts.
- Get rid of the whole attribute.
- Set the values to some value (zero, the mean, the median, etc.).
Handling Text and Categorical Attributes
이전에 우리는 ocean_proximity라는 범주형 속성을 제외했습니다. 왜냐하면 이것은 텍스트 속성이기 때문에 중앙값을 계산할 수 없기 때문입니다.
우리는 이 텍스트로 이루어진 카테코리를 숫자로 바꾸어 주려고 합니다.

이 표현법의 문제점은 기계 학습 알고리즘이 가까운 두 값이 먼 두 값보다 더 유사하다고 가정한다는 것입니다.
해결책: 각 카테고리별로 이진 속성을 하나씩 생성합니다.
이것을 one-hot encoding이라고 합니다.
Feature Scaling and Transformation
Feature Scaling
데이터에 적용해야 할 가장 중요한 변환 중 하나는 특성 스케일링입니다. 소수의 예외를 제외하고, 입력 수치 특성의 스케일이 매우 다를 때 기계 학습 알고리즘은 잘 수행되지 않습니다. 주택 데이터의 경우: 전체 방의 수는 대략 6에서 39,320까지 범위를 가지며, 중앙 소득은 0에서 15까지의 범위만을 가집니다. (목표값을 스케일링할 필요는 일반적으로는 없습니다!!)
모든 속성이 같은 스케일을 갖게 하는 두 가지 일반적인 방법:
- 최소-최대 스케일링 (=정규화)
- 표준화
최소-최대 스케일링 (=정규화)
- 값들이 0에서 1의 범위로 끝나도록 이동하고 재조정됩니다.
표준화
- 먼저 평균 값을 뺀 다음 (따라서 표준화된 값은 항상 평균이 0입니다), 결과 분포가 단위 분산을 가지도록 표준 편차로 나눕니다.
- 최소-최대 스케일링과는 달리, 표준화는 값들을 특정 범위로 제한하지 않습니다. 이는 일부 알고리즘들 (예: 신경망은 종종 0에서 1의 범위로 입력 값을 기대합니다)에 문제가 될 수 있습니다. 그러나, 표준화는 이상치에 훨씬 덜 영향을 받습니다.
모든 변환과 마찬가지로, 스케일러를 훈련 데이터에만 적합시키는 것이 중요합니다. 전체 데이터셋 (테스트 세트 포함)에는 아닙니다. 그런 다음에만 훈련 세트와 테스트 세트 (그리고 새로운 데이터)를 변환할 수 있습니다.
Transformation

5. Select and Train a Model


RMSE 값이 크게 나오므로 underfitting입니다.

RMSE값이 너무 작게 나오므로 overfitting이 되었을 가능성이 큽니다!!

validation에서 RMSE 값이 매우 크므로 overfitting임을 확인할 수 있습니다. RMSE 값이 적절히(너무 크지도 작지도 않게) 나와야 훈련이 잘 되었음을 의미합니다.
6. Fine-Tune Your Model
Grid Search
수동으로 하이퍼파라미터를 조절하여, 하이퍼파라미터 값의 훌륭한 조합을 찾을 때까지 조정하는 것입니다.
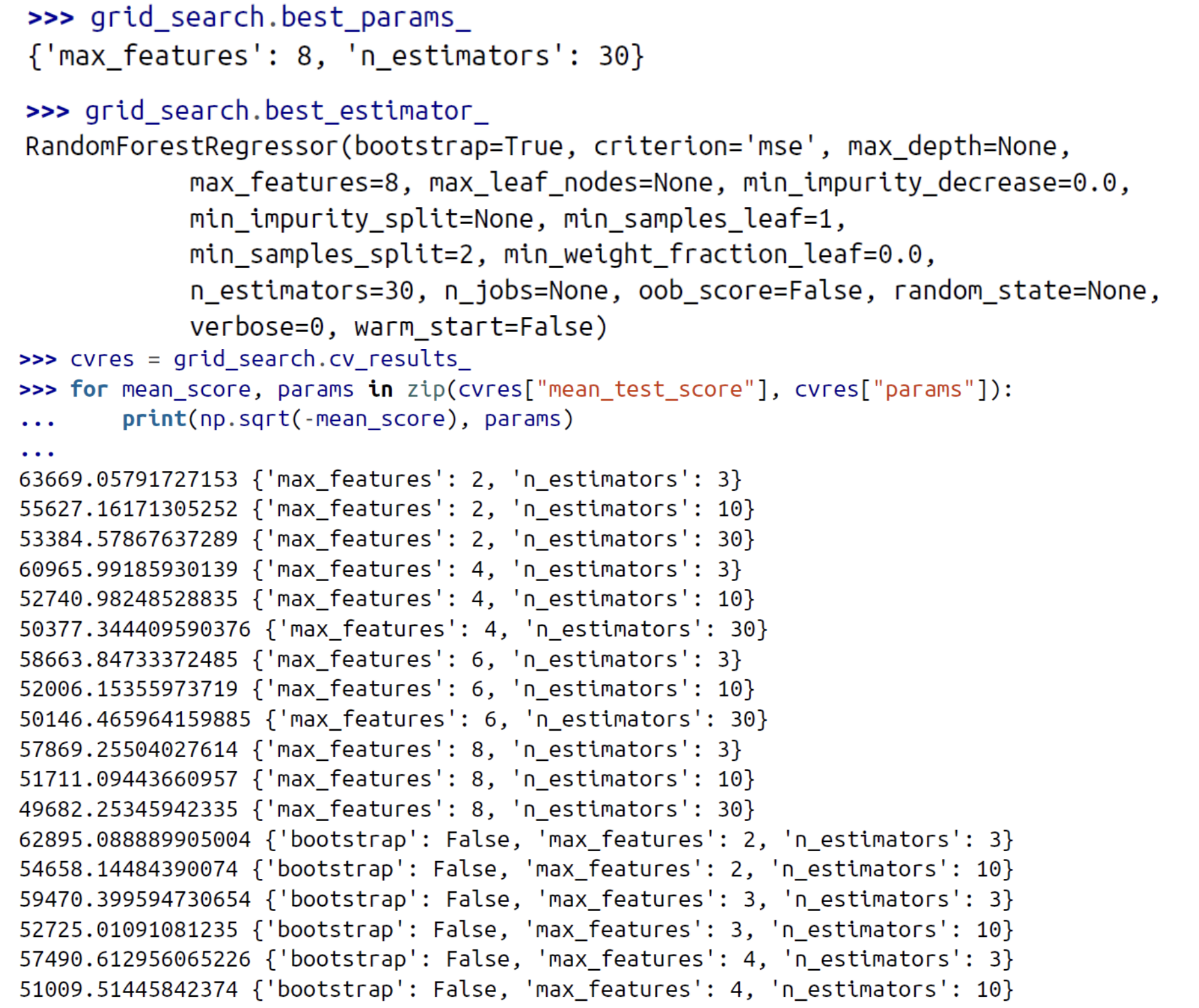
이 중에서 RMSE가 49682일 때가 가장 좋은 성능을 보입니다.
Randomized Search
그리드 검색 접근법은 상대적으로 적은 조합을 탐색할 때 괜찮습니다만, 하이퍼파라미터 검색 공간이 큰 경우 대신 RandomizedSearchCV를 사용하는 것이 종종 바람직합니다. 모든 가능한 조합을 시도하는 대신, 각 반복마다 모든 하이퍼파라미터에 대해 무작위 값을 선택하여 주어진 횟수의 무작위 조합을 평가합니다.
주요한 두 가지 이점이 있습니다:
무작위 검색을, 예를 들어, 1,000번의 반복으로 실행하면, 이 접근법은 각 하이퍼파라미터에 대해 1,000개의 다른 값을 탐색합니다 (그리드 검색 접근법을 사용할 때 하이퍼파라미터 당 몇 개의 값만 탐색하는 것에 비해).
반복 횟수를 설정함으로써, 하이퍼파라미터 검색에 할당하고 싶은 컴퓨팅 예산에 대해 더 많은 통제를 가질 수 있습니다.
Ensemble Methods
시스템을 미세 조정하는 또 다른 방법은 가장 잘 수행되는 모델들을 결합하는 것입니다. 그룹 (또는 "앙상블")은 종종 최고의 개별 모델보다 더 나은 성능을 보입니다 (개별 결정 트리에 의존하는 랜덤 포레스트가 그렇듯이), 특히 개별 모델들이 매우 다른 유형의 오류를 만들 때 특히 그렇습니다.
Evaluate Your System on the Test Set
일반화 오류에 대한 95% 신뢰 구간을 계산할 수 있습니다.
- 하이퍼파라미터 튜닝을 많이 했다면, 성능은 교차 검증을 사용하여 측정한 것보다 약간 나쁠 것입니다 (시스템이 검증 데이터에서 잘 수행되도록 미세 조정되기 때문에 알려지지 않은 데이터셋에서는 그렇게 잘 수행되지 않을 가능성이 높습니다).
- 이런 상황이 발생하면, 테스트 세트에서 숫자가 좋아 보이게 하이퍼파라미터를 조정하는 유혹을 저항해야 합니다. 개선점은 새로운 데이터에 일반화될 가능성이 낮습니다.
7. Launch, Monitor, and Maintain Your System
Deploy
훈련된 Scikit-Learn 모델을 저장합니다 (예: joblib 사용), 전체 전처리 및 예측 파이프라인을 포함하여. 이 훈련된 모델을 생산 환경에서 로드합니다.
- predict() 메서드를 호출하여 예측을 수행합니다.
클라우드에 모델 배포하기 (예: Google Cloud AI Platform)
joblib을 사용하여 모델을 저장하고 Google Cloud Storage(GCS)에 업로드합니다. - Google Cloud AI Platform으로 이동하여 GCS 파일을 가리키는 새로운 모델 버전을 생성합니다.
- 장점: 이를 통해 부하 분산 및 스케일링을 처리하는 간단한 웹 서비스를 얻게 됩니다.
Monitoring
시스템의 실시간 성능을 정기적으로 확인하고 성능이 감소할 때 알림을 trigger하는 모니터링 코드를 작성해야 합니다.
이는 오랜 시간 동안 쉽게 눈치채지 못할 수 있는 서서히 이루어지는 감소일 수 있습니다. 모델이 시간이 지남에 따라 "부식"되는 경향이 있기 때문에 이러한 현상은 꽤 흔합니다.
- 데이터가 계속 변화한다면, 데이터셋을 업데이트하고 모델을 정기적으로 다시 학습해야 합니다.
- 또한 모델의 입력 데이터 품질을 평가하는 것이 중요합니다. 때로는 신호의 질이 떨어져서 성능이 약간 저하될 수 있습니다.
- 마지막으로, 생성한 모든 모델의 백업을 유지하고, 어떠한 이유로 새로운 모델이 크게 실패하기 시작할 경우 이전 모델로 빠르게 롤백할 수 있는 프로세스와 도구를 갖추고 있어야 합니다

👏👏👍