학습 내용
경사하강법
-
미분 : 변수의 변화에 따른 함수의 변화량
-
numpy.diff 를 통해 미분을 컴퓨터로 계산 가능
-
미분은 그림으로 나타냈을 때, 특정 x 지점에서의 접선의 기울기를 의미
접선의 기울기를 안다 -> 어느 방향으로 움직여야 함수값이 증가/감소하는지 알 수 있다. -
미분값이 양수이든 음수이든, 미분값을 더하면 함수는 증가하고, 미분값을 빼면 함수는 감소한다.
: f'(x)를 더했을 때, f'(x) > 0 이면, 함수의 오른쪽으로 이동하여 값이 커졌을 것이고, f'(x) < 0이면 함수의 왼쪽으로 이동하여 값이 커진다. 반대의 경우도 동일 -
이를 통해 경사 상승법, 경사 하강법 도출 가능
-
경사 상승법 : 미분값을 더해가며 구함, 함수의 극대값 구할 때 사용
-
경사 하강법 : 미분값을 빼며 구함, 함수의 극소값 구할 때 사용
-
경사 상승법이든 하강법이든 극값에 다다르면 미분값이 0에 가까워져 대부분 수렴한다. 따라서 종료조건을 미분의 절대값의 크기가 일정 수치가 되었는지를 기준으로 잡으면 된다.
gradient vector
-
변수가 벡터이면? 편미분 사용
-
편미분을 통해 x의 i번째 값만의 변화율을 구할 수 있다.
-
위 과정을 통해 i개의 편미분 값을 벡터들로 표현할 수 있는데, 이 벡터들을 모아 gradient vector라 한다.
-
gradient vector를 이용해 경사하강법/경사상승법 사용 가능하고, 이를 통해 수직선상에서의 변화량이 아닌 d차원에서의 변화량을 알 수 있다.
-
gradient vector는 벡터이기 때문에 미분값처럼 절대값의 크기로 종료조건을 판별할 수 없고, norm을 계산해서 종료조건을 할당해준다.
-
결론 : gradient vector를 활용해 각 성분들의 변화 방향을 모두 종합하여 d차원 공간에서도 극소/극대값을 향하게 만들어 주는 것 같다.

확률적 경사하강법(stochastic gradient descent, SGD)
- 지난 시간에 선형회귀(linear regression) 모델에서 유사역행렬을 이용해 선형모델을 찾았었는데, 경사하강법을 이용해서도 찾을 수 있다.
- 경사하강법을 쓰는 이유 : 선형 모델에서는 유사역행렬을 써도 되지만, 다른 비선형 모델에서는 못쓰기 때문에 일반적으로 널리 쓸 수 있는 경사하강법을 이용한다.
-
경사하강법은 볼록(convex)한 함수, 특히 선형회귀에 대해선 수렴이 보장된다. (적절한 학습률과 학습횟수는 필요함)
-
비선형모델은 수렴이 보장되지 않는다.(non-convex 함수에 적용 못한다는 의미)
-
확률적 경사하강법(stochastic gradient descent, SGD) : 데이터 한개 또는 일부만 사용해 업데이트(일부를 사용하는 경우 mini-batch SGD)
-
보통 mini-batch를 많이 쓰므로 SGD가 mini-batch SGD라 생각해도 될지도..
-
머신러닝과 딥러닝의 경우 경사하강법보다 SGD가 더 낫다고 검증되었다!
-
데이터 일부만 활용하기 때문에, 연산량을 적게 가져가면서도 경사하강법과 유사한 결과를 얻을 수 있다.
-
mini batch(X의 일부 데이터셋)은 매번 바뀌므로, 목적식(함수) 모양이 바뀐다. 따라서 non-convex 형태에서 지역적인 극소 위치에 오게 되더라도 mini-batch가 아니면서 극소가 아니게 될 확률이 생기고, 이를 통해 지역적인 극소에서 탈출하는게 가능하다.
(미분값이 0이지만 극소가 아닌 위치를 지역적인 극소라 표현하였습니다. 용어가 생각이 안남..) -
정리 : SGD는 non-convex 목적식에서 사용 가능하므로 머신러닝과 딥러닝에서 경사하강법보다 더 효율적이다. 다만 batch size를 잘 잡아야한다.(너무 낮게 잡으면 성능 더 나빠질 수 있음)
또한, 최근 딥러닝에서 사용되는 데이터는 굉장히 size가 크고 데이터 수도 많기 때문에, 모든 데이터를 쓰는 대신 일부 데이터만 활용한든 SGD가 훨씬 유리
딥러닝
-
선형모델에서 실제 정답값 y와 선형모델의 정답값인 ^y(y-hat)의 차이의 L2-norm를 최소화하는 β를 찾는 것이 목표였다
-
하지만 선형모델만으론 예측하기 힘든 상황이 많다. -> 비선형모델인 신경망을 사용하는 이유
선형모델 복습
-
데이터를 모은 행렬 X, X를 다른 차원으로 보내는 가중치행렬 W의 곱을 통해 선형모델 표현 가능했었음
-
b : y절편 행렬, 각 행이 같은 값을 가지고 있다 보면 된다 -> 모든 데이터에 대해 똑같은 값을 더해준다.
-
가중치행렬 W(d p) : 데이터 X(n d)에 곱해 d차원에서 p차원으로 보냄(d개의 변수로 p개의 선형모델을 만든다.)
일반적인 dense layer에서의 간선들이 Wij 가 의미하는 것들임.
신경망
-
softmax : 모델의 출력을 확률로 해석하는 연산
-
classification 문제에서 선형 모델과 결합하여, 특정 벡터가 특정 클래스에 속할 확률로 해석할 수 있다.
-
학습을 할 때는 softmax를 쓰되, 추론을 할 때는 one-hot encoding을 사용한다.
-
신경망 : 선형모델과 활성함수(activation function)을 합성한 함수
-
활성함수를 왜 쓰나요? : 활성함수는 비선형함수라서 선형모델을 비선형모델로 바꿔준다.
활성함수를 쓰지않으면 선형모형과 차이가 없어짐! -
딥러닝에선 활성함수로서 ReLU를 많이 쓰고있다.
-
다층 퍼셉트론 : 신경망이 여러층 합성된 함수, 딥러닝의 기초
-
층이 깊어질수록 층이 얕은 신경망보다 더 효율적이다
: 층이 깊어지면 층이 얕을 때보다 더 적은 뉴런(적은 파라미터)으로도 표현이 가능하다. -
역전파 알고리즘(back propagation) : forward propagation의 반대, 윗층부터 역순으로 각 층의 파라미터를 학습하는 방법
-
chain-rule 기반 자동미분을 사용한다(아래 그림과 같은 계산방식)
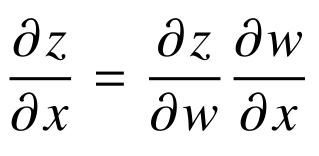
-
뒤에 더 복잡한 신경망 구조에서의 역전파 과정에 대한 설명이 있는데, 너무 복잡해서 지금은 이해를 못하겠다...
피어 세션
- 오늘 과제가 어제보다 더 복잡하고 test case가 까다로워, 접근법과 test case 구조 및 디버깅 방법에 대해 얘기를 나누었다.
- 어제 오늘 과제에 대한 얘기를 위주로 했었는데, 과제를 푸는데 시간이 많이 걸릴 뿐더러 피어세션 때 과제를 다루다보니 강의를 잘 듣지 못하는 일이 발생해 내일부턴 강의 위주로 피어 세션을 진행하고 과제에 대해선 애로사항정도 얘기할 것 같다.
팀원들이 사전에 모은 질문
-
수식을 모르겠다

: 나도 모르겠다...
: 팀원분들 얘기에서 통계쪽 수식이라는 짐작을 할 수 있었다. -
numpy array보다 list가 더 연속된 주소를 갖고 있는 것 같은데?
: 아리송해서 검색해본 결과 numpy는 c언어로 구현되었고, list는 포인터처럼 각 index가 다른 주소를 갖고 있고, numpy array는 각 index가 같은 id를 갖는 것을 확인할 수 있었다. numpy가 확실히 더 효율적인 게 맞다. -
mock patch를 잘 모르겠다.
: test case관련 python의 모듈이다.
: 공식 문서가 있는 만큼 추후 공부해야한다.
느낀점
- 아직 이틀차라 그런지 집중이 잘 되지 않는다. velog에 올리기 위해 강의 내용 최대한 이해하고 정리하고, 과제까지 하는게 시간이 많이 필요해서 집중을 해야하는데, 아직 편안했던 지난주까지를 내 몸이 잊지 못하는 것 같다. 최대한 잊어보도록 노력할 수 밖에 없다.
- 강의 하나하나가 내가 기존에 알고있던 개념을 세세히 파고든다는 느낌을 받았다. 일단 수식의 압박이 엄청나서 고통스러운데, 그래도 이해해야 한다.
- 그래서 강의 중간에 이해가 안가는 부분이 생기지 시작했다. 아직 진도가 빠듯해서 수식 관련 부분은 확실히 정리하지 않았는데, 목요일이나 금요일에 강의나 과제가 여유가 생기면 정리가 안된 부분을 다시 한번 정리하고, 안되면 주말에 공부해서 관련 내용을 velog에 올리도록 해야겠다. 앞으로도 그 주에 이해 안되는 내용을 따로 정리하는 날을 갖도록 하는게 좋을 것 같다.
