학습 내용
Neck
Neck은 Backbone과 RPN 사이에 위치하여 특정 작업을 수행하는 network를 의미한다.
지난 Faster R-CNN까지를 돌이켜보면, Backbone network를 통과해 나온 Feature map은 RPN에 들어가 RoI를 추출해내고, 이를 Head(classification head, coordinates head)에 넣어 Bbox regression과 classification을 수행했었다. 이 때 지금까지 RPN에 Input으로 들어가는 Feature map은 Backbone network의 마지막 layer의 output뿐이었다. 하지만 backbone network의 중간 과정에도 여러 feature map들이 존재할 것이고, 이 feature map들을 모두 활용하면 다양한 상황에 대응할 수 있을 것이다. 이를 위해 Neck에서는 backbone network의 여러 layer에서 뽑은 feature map을 활용한다.
일반적으로 receptive field가 클수록(상위 layer일수록) 더 큰 범위를 보며 semantic한 특징과 객체를 잘 잡아내며, receptive field가 작을수록(하위 layer일수록) 더 작은 범위를 보며 선이나 기울기 같은 특징을 포착한다. 따라서 backbone의 마지막 layer만 사용한다면 receptive field가 크기 때문에 이미지의 작은 정보들은 포착하기 힘들다.
다양한 크기의 feature map을 사용하면 큰 정보 뿐만 아니라 작은 정보들도 잘 잡아낼 수 있게 된다. 또한 크기가 작은 객체도 잘 찾아낼 수 있게 된다.
이 때 단순히 각 layer의 feature map에서 각각 RoI를 뽑을 수도 있겠지만, 이 보다는 각 feature map들을 종합하여 여러 정보들이 잘 섞이게 해주는 것이 좋다. 하위 level의 feature는 semantic한 정보가 약하므로 상대적으로 semantic이 강한 상위 feature와 교환을 해주는 것이다. 이를 Neck에서 진행한다.
기존에 Neck을 사용하지 않았을 때는 그냥 마지막 feature map만 사용하거나, 이미지 크기를 여러 개로 만들어 backbone을 통과시켜 여러 feature map을 얻기도 했다.
FPN(Feature Pyramid Network)
feature map들 중 high level의 semantic 정보들을 low level로 전달하기 위해, top-down path way를 사용하였다. 즉, high level feature를 적절히 바로 아래 level의 feature에 섞어주고, 이를 최하위 feature map까지 반복하는 것이다.
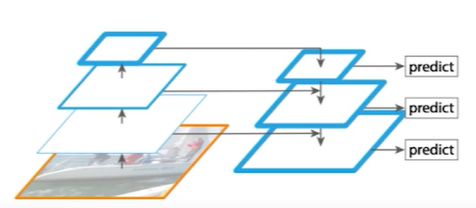
그렇다면 어떻게 각 feature map들을 섞는것인가?
사실 간단하게, 두 feature map의 shape과 channel 수만 동일하게 맞춰주면 된다. 어차피 둘은 서로 다른 feature들을 갖고 있기 때문에 둘이 같은 shape을 갖는다면 elementwise하게 더해주면 되는 것이다.
다만, 처음엔 둘의 shape이 다르다. FPN 구조에서 보면 backbone에서 가져온 feature map은 channel 수가 적고, Neck의 high level에서 내려온 feature map은 size가 절반이다. 따라서 backbone에서 가져온 feature map에는 1x1 convolution 연산으로 channel 수를 맞춰주고, high level에서 내려온 feature map은 upsampling을 통해 size를 맞춰준다.
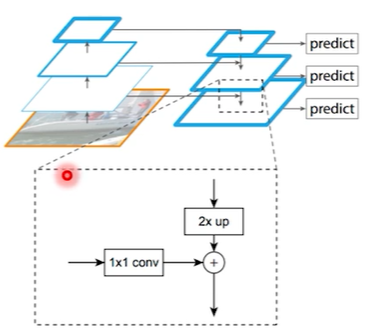
Upsampling엔 다양한 종류가 있지만, FPN에선 Nearest Neighbor Upsampling을 사용하였다. 이 방법은 단순하게 한 cell의 값을 cell의 오른쪽, 아래, 오른쪽 아래 대각선으로 확장하는 것이다.
feature map merge를 진행하여 나온 새로운 feature map들(P5~P2)을 RPN에 넣어 각 stage마다 RoI들을 많이 얻을 수 있을 것이다. 이들을 통합한 뒤 Object score가 높은 순서대로 정렬한 후 상위 N개를 뽑고, 다시 NMS를 진행하여 1000개의 RoI를 얻는다. 이 RoI들은 다시 RoI가 추출된 feature map에 projection 되어야 하는데, 이 때 RoI가 추출된 feature map을 찾는 것은 식을 사용한다. w,h는 RoI는 width, height이고, w,h가 작아질수록 k가 작아져 P2나 P3(low level)에 있을 것이고, w,h가 커지면 반대가 될 것이다. w,h가 작다는 건 작은 크기의 RoI를 추출했다는 것이므로, 작은 크기의 정보(low level)을 담고 있는 상위 layer에서 추출됐다는 것이다.
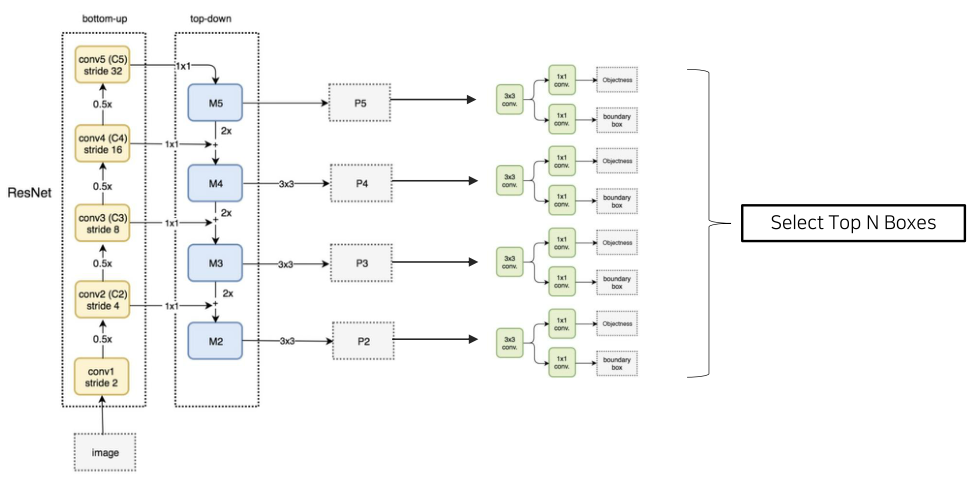
FPN은 기존의 high level feature map만 사용해 RoI를 추출했을 때와 비교해 Average recall 값이 증가하였다. 특히, large box는 크게 성능 차이가 없지만 small box에 대해서는 엄청난 성능 향상이 있었다.
PANet(Path Aggregation Network)
FPN을 그림으로 보면 layer 수가 적어 low level의 feature가 high level로 잘 전달되겠구나 생각할 수 있지만, 실제 FPN의 backbone은 ResNet이고, 이는 엄청나게 많은 수의 layer를 사용하기 때문에 하위 layer의 정보를 상위 layer로 잘 전달할 수 없게 된다.이를 해결하기 위해 top-down 과정 이후 Bottom-up path Augmentation을 한번 더 진행해준다.
또 RoIPooling 과정(원래 PANet은 segmentation 모델이라 RoIAlign이 맞지만 우리가 배우고 있는 부분은 detection 관련 내용이니 pooling 부분이라 이해하자.) RPN은 특정 feature map에 RoI를 projection해서 사용했지만, PANet은 모든 feature map에 해당 RoI를 projection하고, 이를 fc layer로 만들어 여러 stage의 정보를 모두 활용하도록 하였다. 이를 Adaptive Feature Pooling이라 한다.
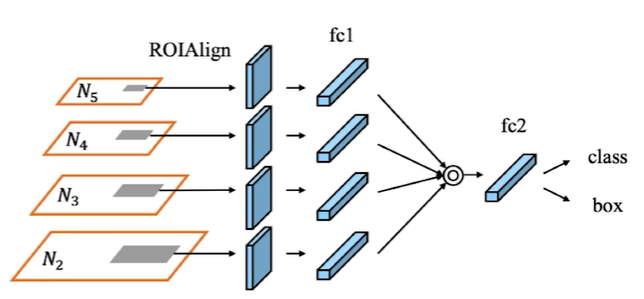
After FPN
FPN에 영감을 받아 많은 Neck 들에 관한 내용이 나왔다.
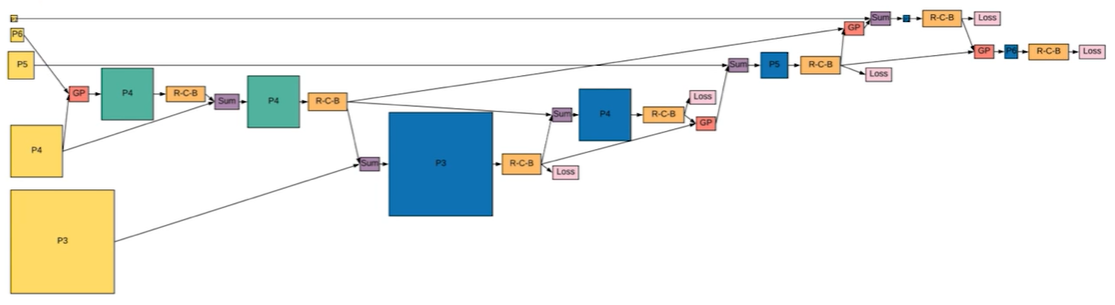
DetectoRS
Recursive Feature Pyramid(RFP)를 사용하였다.
- top-down path way 의 각 stage들을 recursive하게 backbone으로 넘겨준다.
- low level feature에 high level feature가 전달될 수 있는 장점이 있지만 연산을 많이 해야해 Flops가 높고 학습 속도가 느리다.
- FPN layer에서 나온 feature들을 그대로 backbone으로 보내는 것이 아니라, ASPP라고 부르는 방법을 사용해 receptive field를 키운 후 backbone에 전달된다.
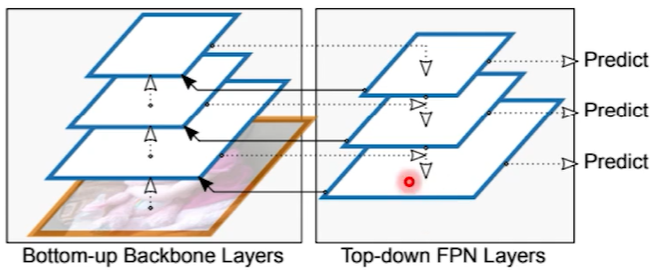
BiFPN
EfficientDet에서 제안된 Neck이다.
- 효율을 위해 feature map이 sum 되는 곳이 아닌, 한 곳에서만 오는 곳을 없앴다.
- 가장 큰 특징은 FPN에서 feature map merging을 할 때 각 feature map을 weighted sum한다는 것이다.

- residual block처럼 in layer에서 out layer로 건너뛰어 전달되는 feature도 있으며, 이 또한 weighted sum에 포함된다.
를 통해 찾는다.
- FPN에 비해 Flops도 높고 성능이 좋지만, 해당 architecture에 성능이 국한되어 범용적이지 못하고 다른 dataset이나 backbone에서 가장 좋은 성능을 내는 architecture를 찾으려 하면 여기에 search cost가 들어가야 한다.
AugFPN
Residual Feature Augmentation
- P5에선 3x3 convolution등으로 인해 high level 정보 손실이 발생할 수 밖에 없는데, 이를 해결하기 위해 C5로부터 새롭게 M6를 만들어 이를 P5에 전달해준다.
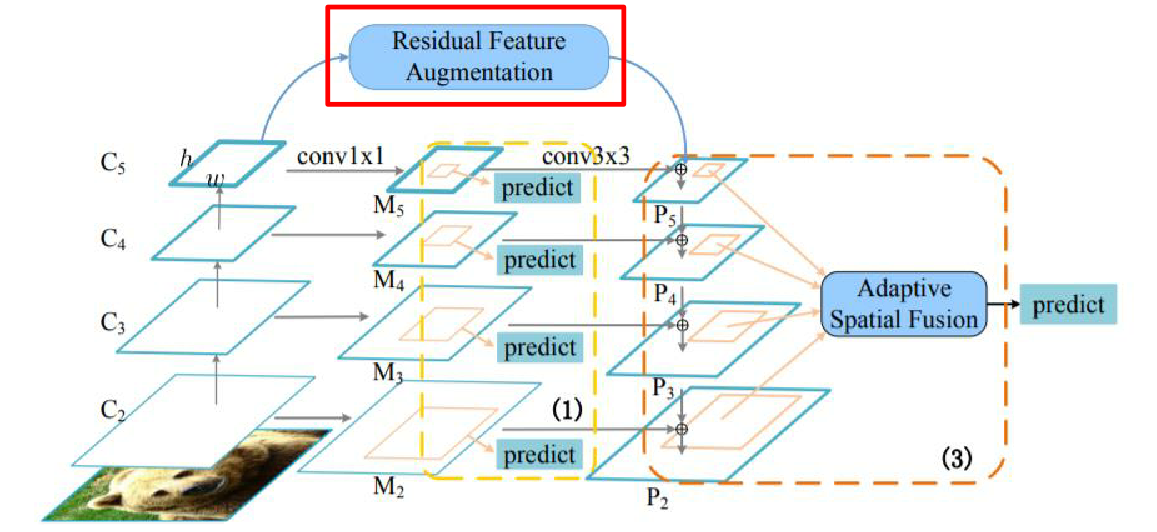
Soft RoI Selection
- PANet과 비슷하게 RoI를 모든 feature map을 이용하여 계산하는데, PANet은 이 과정에서 maxpooling을 사용하여 정보 손실 가능성이 있다. 이를 해결하기 위해 Soft RoI를 사용한다.
- PANet의 maxpooling을 학습 가능한 weighted sum으로 대체했다.

{kind=link}