학습 내용
1 Stage Detectors
기존 2 Stage Detector(Fast R-CNN 시리즈 등)은 Localization, Classification으로 stage가 나뉘어 진행되었다. 이들은 공통적으로 속도가 느리다는 한계점이 존재하여, Real time detection에 활용하기는 불가능했다. 이를 위해 Real time detecting을 위해 1 Stage Detector에 대한 연구가 이루어지게 되었다.
1 Stage Detector의 특징은 CNN을 통과해 Feature map을 뽑아내는 데 까진 동일하지만, 이 후 RPN을 통과하지 않고 바로 객체의 위치와 종류를 찾아내는 작업을 한다는 것이다. 즉 Region proposal(특정 보고자 하는 영역)을 따로 추출하지 않고 전체 이미지에 대해 Localization과 Classification을 동시에 진행하여, 구조가 간단하고 속도가 빠르다.
YOLO v1
위에서 설명한 구조를 그대로 구현하였다.(Region proposal X, Localization과 Classification 동시 진행)
Backbone Network로 GoogLeNet의 변형을 사용하였다. 24개의 Conv layer를 통해 Feature extraction을 하고, 마지막 2개의 fully connected layer를 통해 bounding box의 좌표값 및 확률을 계산한다.
Pipeline
- 입력이미지를 SxS Grid 영역으로 나눈다.(S=7)
- 각 Grid 영역마다 B개의 Bounding box와 Confidence score를 계산한다. (B=2)
- 한 grid마다 2개의 Box를 예측, 7x7 Grid니까 총 98개의 box 예측
- Confidence score는 Box에 Object가 존재할 확률과 GT와의 IoU를 곱해 구한다.
- 각 Grid 영역마다 C개의 class에 대해, 해당 class일 확률을 계산한다.(C=20)
- Grid 영역마다 구한 위 정보들을 합쳐 최종적으로 Detection을 한다.
Backbone을 전부 통과하고 나면 최종 size가 7x7x30이 된다. 이 때문에 Grid가 7x7로 나뉘어진 것이다.
또 각 Grid는 30개의 Channel을 갖게 되는데, 앞의 10개는 2개의 Bounding box의 x,y,w,h, confidence score를 담고 있다.(한 box당 5개씩)
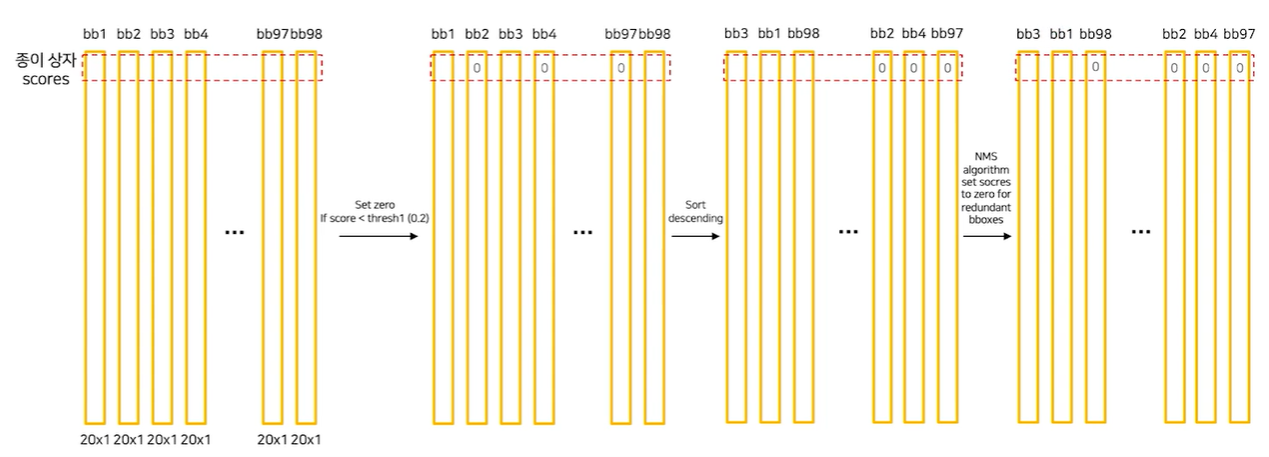
뒤의 20개는 class 수를 의미하며, 각 class의 probability를 의미한다. 각 Bbox의 Confidence score와 각 class probability를 모두 곱하고, 이를 모든 Grid cell에 대해 수행하면 총 98개의 20 class score 정보를 갖는 Bbox들을 얻을 수 있다.

이 후 Bbox 들의 같은 class에 대해, 임의로 정한 threshold 이하 값을 0으로 만들고, 내림차순으로 정렬하고, NMS 과정을 거치고 나서 남은 box들을 Object에 그려주면 inference가 완료된다.
Loss
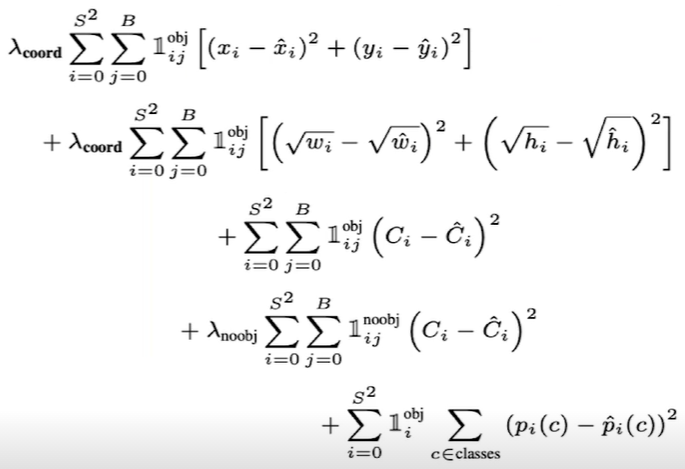
YOLO는 R-CNN 종류보다 훨씬 빠른 편이고, Background error가 적다. 특이점으론 단일 YOLO는 Fast R-CNN보다 mAP가 낮은데, 이 둘을 Ensemble 했을 때 큰 성능 향상을 보인다. 따라서 1 Stage와 2 Stage를 Ensemble 하는 것이 성능에 좋은 영향을 미칠 수 있다는 점을 알아두는 게 좋다.
또 이미지 전체를 보기 때문에 맥락적 정보를 잘 가지고 있고, 새로운 domain의 dataset에도 좋은 성능을 보인다.
SSD
YOLO는 7x7 Grid로 나눴기 때문에 이 보다 작은 물체는 검출이 불가능하고, Network의 마지막 feature만 사용해서 정확도가 낮다는 단점이 있다.
SSD는 Fully connected layer를 없애고 1x1 conv를 활용하여 속도를 향상시켰고, 마지막 layer뿐만 아니라 VGG를 통과해 나온 마지막 feature map으로부터 추가적으로 convolution을 진행해 몇 개의 feature map을 더 만든다. 이를 모두 detection에 활용하는데, 총 6개의 다른 scale의 feature map중 큰 것은 작은 물체 탐지, 작은 것은 큰 물체를 탐지한다.

Anchor box는 Default box, 즉 서로 다른 scale과 비율을 가진 미리 계산된 box를 사용하였다.
SSD는 Real time detection이 가능할 정도의 FPS를 가졌으면서, mAP 또한 faster R-CNN보다 높은 값을 가지는 모델이다.
YOLO v2
정확도 향상, 속도 향상, 더 많은 class 예측을 목표로 제안되었다.
정확도 향상을 위해 Batch normalization을 활용하였고, mAP가 2%정도 향상되었다.
그리고 Backbone을 dataset의 image size에 맞게 finetuning하였고, 이를 통해 mAP를 4% 올렸다.
SSD와 유사하게 FC layer를 없애고 Anchor box를 도입했다.
또 Fine-grained feature라는 기술을 도입하였다. 크기가 작은 feature map은 low level 정보가 부족하기 때문에, low level 정보를 포함하고 있는 early feature map을 한 줄로 concatenate시켜 두 feature map을 결합시켰다.(ex.2626512 -> 13132048 변환 후 13*13 feature map과 결합)
속도 향상을 위해, backbone을 GoogLeNet에서 Darknet으로 바꿨다.
더 많은 Class를 예측하기 위해 Coco dataset과 ImageNet dataset을 같이 사용하였다. 둘을 합쳐서 9418개의 class를 만들어 학습에 사용하였다.
YOLO v3
backbone의 darknet이 upgrade되고, FPN을 활용하였다.
RetinaNet
1 Stage detector의 한계로, 모든 grid에 대해 Bbox를 예측하게 하므로 배경(Negative sample)이 압도적으로 많게 되어, class imbalance 문제가 생긴다는 점이 있다.
이를 해결하기 이해 새로운 loss function인 focal loss를 도입하였다. 쉬운 예제에 적은 가중치, 어려운 예제에 큰 가중치를 둬 어려운 예제에 집중하도록 한다.
이를 통해 성능 향상이 큰 폭으로 이루어졌다.
EfficientDet
모델을 깊이 쌓으면 성능이 좋아진다는 것이 ResNet을 통해 알려졌지만, 모델을 깊이 쌓으면 쌓을수록 모델이 무거워지고 느려지는 것에 비해 성능 향상 폭은 점점 작아졌다. 이를 해결하기 위해 모델을 잘 쌓는 방법이 있을 것이라 생각하고 연구해왔고, 모델을 쌓는 방법론을 Model scaling이라 한다.
Model scaling의 종류
- width scaling : channel을 크게 준다.
- resolution scaling : 큰 image를 사용한다.
- depth scaling : layer를 깊게 쌓는다.
- compound scaling : width, resolution, depth scaling을 종합하여 scaling한다.
EfficientNet 팀은 compound scaling 과정에서, width, depth, resolution을 균형을 맞추고 각각을 일정 비율로 확장하며 균형을 계속 맞추는 것을 통해 더 높은 정확도와 효율성을 갖게 할 수 있었다고 한다.
EfficientNet
큰 모델을 압축시킬 때 어떤 식으로 압축시켜야 efficiency를 유지할 수 있을 지 연구하는 과정에서, model scaling을 통해 이를 해결하였다.
model scaling 중 channel을 늘리는 방법을 width scaling이라 한다. 이는 작은 모델에서 주로 사용되며(MobileNet), 미세한 특징을 잘 잡아내고 학습도 쉽지만, 넓은 대신 얕은 모델은 high level feature를 잘 잡지 못한다는 단점이 있다.
Depth scaling은 대부분의 ConvNet에서 사용되며, high level feature를 잘 잡아내고 일반화가 잘 되어 새로운 task에 적용하기도 쉽지만, gradient vanishing 문제 때문에 학습이 어렵다는 단점이 있다.
Resolution scaling은 image size를 키우는 것을 의미하는데, 이를 ConvNet에 적용하면 미세한 패턴을 잘 잡아낼 수 있다.
실험을 통해 width, depth, resolution을 키우면 accuracy가 향상되는 것을 확인할 수 있었다. 하지만 더 큰 model에 대해서는 정확도 향상 정도가 감소했다.
EfficientNet에서는,
로 두고, 'α x $ ^2$ x = 2' 라는 제약 조건 하에 조건에 맞는 α, β, γ를 찾았다. 실험 결과 α=1.2, β=1.1, γ=1.15 일 때 성능이 가장 좋았다. 여기서 Φ를 1부터 크기를 늘려가며 model scaling해서 나온 모델들이 EfficientNet B1~B7이다.
EfficientDet
Detection 분야에서 속도를 잡기 위해 1 Stage detector 등 여러 시도가 있었지만, 결국 성능을 좋게 얻지는 못했다. 이를 위해 EfficientNet과 똑같이 compound scaling을 통해 성능과 속도 두 마리 토끼를 다 잡은 모델이 EfficientDet이다.
EfficientDet 이전엔 level이 다른 feature를 섞기 위해 FPN, PANet 등을 활용했는데, 대부분은 resolution 구분 없이 feature map을 단순 합했다. EfficientDet에서는 단순 합 대신 가중합을 하는 BiFPN 구조를 제안하였다.

