https://arxiv.org/abs/2310.07699
1. Introduction
- Large-scale vision-language representation learning은 CLIP를 통해 주목받았는데, 이는 image-text 쌍에서 학습된 지식을 제로샷 이미지 분류, image-text retrieval 등 다양한 downstream 작업에 전이시킬 수 있기 때문
- CLIP 학습은 image-text 대비 손실을 통해 간단하지만, 웹에서 크롤링한 4억 개의 이미지-텍스트 쌍으로 이루어진 대규모 데이터셋이 필요
- CLIP는 두 가지 확장 가능한 패러다임을 통해 성공을 거둠
- 웹에서 크롤링한 방대한 데이터로 학습을 확장할 수 있어 데이터 기반 백본(e.g. ViT)의 요구사항을 충족시킴
- 간단한 image-text contrastive loss로 컴퓨팅 자원의 유리한 확장성을 얻음. 그러나 웹에서 크롤링한 대규모 데이터의 품질이 낮거나 노이즈가 있을 수 있음
대체텍스트(AltTexts)에는 두 가지 주요 문제가 있음:
1) 노이즈가 있거나 무의미하거나 이미지와 관련이 없을 수 있음
2) 이미지의 모든 시각적 내용을 설명하지 않을 수 있음. 예를 들어 아래 그림에서 보는 바와 같이, 첫 번째 이미지에는 "흰 지붕과 현관이 있는 집"이 있지만 해당 캡션은 주소만 설명하고 있어 효과적인 비전-언어 정렬을 위한 학습에 너무 추상적임

-
자연스러운 방향 중 하나는 대규모 언어 모델(LLM)을 배포하여 캡션을 바꾸는 것
-
그러나 이러한 방법의 주요 한계점은 LLM이 새로운 이미지 특정 세부 정보를 생성하고 도입할 수 없다는 것임. 이 시나리오에서 LLM은 문장 구문만 수정할 수 있음
-
위 그림에서 볼 수 있듯이 LLM rewrite는 새로운 정보를 도입하지 못하므로 새 캡션이 AltTexts와 비슷함. 즉, 원래 AltTexts에 노이즈가 있다면 LLM rewrite으로 얻을 수 있는 이점은 사소한 개선에 그칠 것임
-
본 논문에서는 CLIP 성능을 개선하기 위해 raw 및 노이즈가 있는 웹 크롤링 데이터에 특화된 확장 가능하고 비용 효율적인 파이프라인 구축에 중점을 둠
-
데이터 품질 외에도 데이터의 다양성이 VLM 사전학습에 큰 영향을 미침 [2, 27]
-
LLM 기반 rewrite 방법은 LLM이 문장을 바꿀 때 균일한 스타일을 적용하는 경향이 있기 때문에 데이터 다양성이 줄어들 수 있음
-
따라서 VLM 사전학습에 대한 모델 성능과 데이터 효율성을 개선하기 위해서는 데이터 품질, 다양성 및 학습 방법론을 향상시킬 수 있는 확장 가능한 접근법을 구축할 필요가 있음
-
본 논문의 Contribution은 다음과 같음
CLIP training을 위한 시각적으로 강화된 re-captioning 기법을 제시. 이는 이미지에서 추출한 시각적 개념을 captioning 과정에 주입하려는 최초의 시도
파이프라인이 비용 효율적이며 3억 개가 넘는 규모의 데이터를 처리할 수 있음 (VeCap). 그리고 VeCLIP를 제안하고 VeCap을 사용하여 CLIP training을 개선하는 mixed training scheme을 도입
VeCLIP는 retrival task에서 CLIP 대비 최대 25.2% 개선 효과를 보임. 학습 데이터 효율성 측면에서는 5%의 데이터만으로 image-text retrival task에서 경쟁력 있는 결과를 얻음
VeCap 데이터는 다른 잘 정제된 데이터셋과도 보완적임. VeCap과 DFN의 조합으로 학습한 CLIP-H/14 모델은 image-text retrival과 zero-shot classification task 모두에서 강력한 성능을 발휘하며, ImageNet에서 놀라운 83.1%의 zero-shot 정확도 @1을 기록
3. Methodology
3.1 Preliminary
CLIP
- 각 training iteration 중 학습 데이터에서 N개의 이미지-텍스트 쌍 {xI, xT}을 샘플링
- 이미지에 augmentation을 적용한 후에는 비전 인코더로 입력
- 비전 및 텍스트 인코더에 의해 추출된 정규화된 특징을 각각 fI 및 fT로 표시
- 모델을 학습하기 위해 contrastive loss를 사용하며, 여기서 페어링된 이미지와 텍스트는 positive pair로 처리되고 나머지는 negative sample로 처리
- Training loss는 아래와 같이 정의:
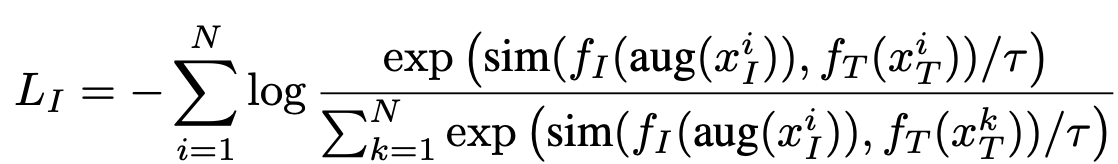
3.2 Recaptioning with Visual Concept Exploitation
- 웹 크롤링된 캡션(AltTexts)은 이미지에 대해 noise가 많고 정보가 없을 수 있음
- LaCLIP는 캡션을 재작성하기 위해 LLM을 사용
LLaVA and image captioning for Visual-enriched Cap- tions (VeCap)
- LLaVA는 CLIP의 오픈셋 비전 인코더와 LLM(예: LLaMA)을 연결한 다중 모달 모델로, 시각 지시어 튜닝 데이터셋에서 그들을 세밀하게 조정
- AltText의 영향을 줄이기 위해, LLaVA에 대한 AltText에 독립적인 프롬프트를 개발하여 시각적 개념을 완전히 활용
- "이미지를 간결하게 설명하십시오, 20단어 미만"이라는 간단하지만 강력한 프롬프트를 채택하여 LLaVA가 이미지로부터 직접 시각적 개념을 생성
3.3. Scalable LLM Rewrite for Concept Fusion
- LLM을 사용하여 AltTextxT에서 유도된 지식과 xTv에서 도출된 새로운 시각적 개념을 융합하여 캡션을 정제하게 되는데, 이 단계에는 세 가지 주요 장점이 있음:
- 1) AltText에 기술된 정보의 유지를 보장하여 캡션의 정보를 강화
- 2) 문장 구문의 깊은 재구성을 특징으로 하는 텍스트 데이터의 "strong augmentation" 형태로 작용할 수 있음
- 3) 대규모 비전-언어 모델(LLaVA 등)에서 발생하는 "hallucination" 문제를 완화하여 최종 캡션에 설명된 개체가 이미지에 실제로 존재하는지 확인할 수 있음
Scalable batch-inference process
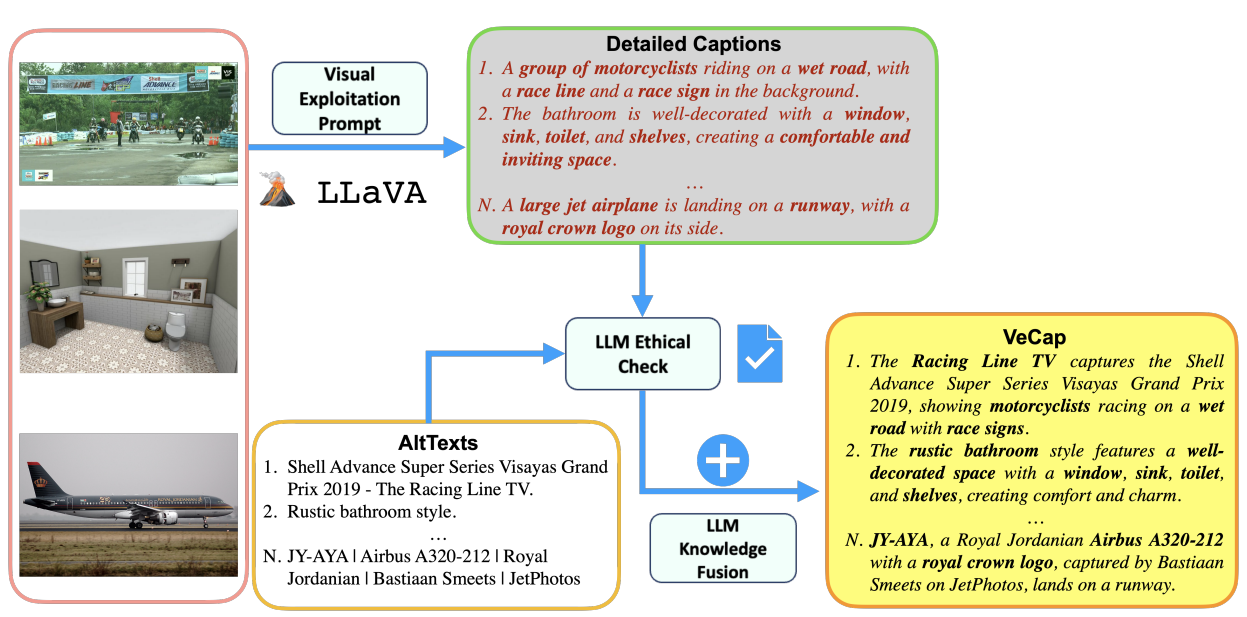
- 위 그림과 같이, AltText와 독립적인 디자인된 프롬프트를 사용하여 이미지의 시각적 개념을 활용하기 위해 Multi modal LLM (LLaVA)을 활용하여 시각적으로 풍부한 캡션 (VeC)을 생성
- AltText와 VeC에서 개념을 융합하여 최종 캡션을 생성하기 위해 LLM을 활용 -> VeCap
4. Experiments
- VeCap이라는 데이터셋의 네 가지 규모에서 사전 학습 실험을 진행
- 작은 규모로 3M, 중간 규모로 12M, 대규모로 100M 이상을 설정
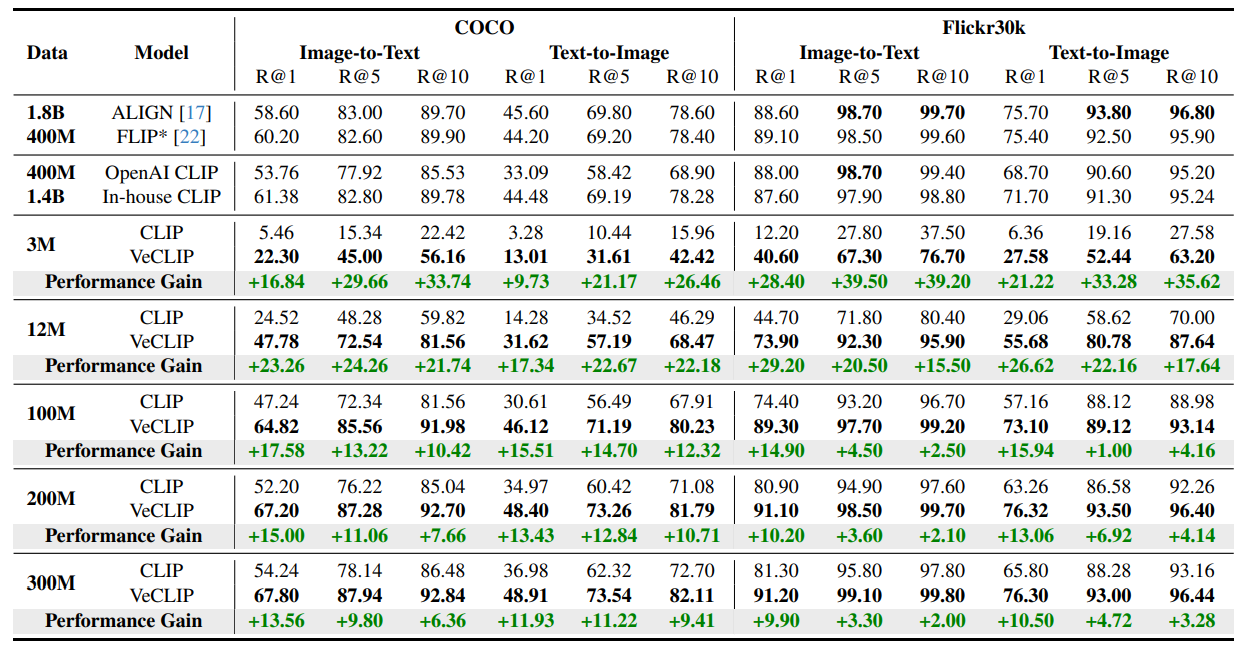
- COCO 및 Flickr30k 데이터셋에서 I2T 및 T2I retrieval 작업 모두에서 일관된 개선을 보여줌
- 작은 규모와 중간 규모 (3M/12M)에서 각각 COCO image-text retrieval의 Recall@1에서 +16.84%/+23.26%의 개선을 달성
- 처음에는 3M 데이터셋을 사용하여 Flickr30k의 image-text retrieval에서 상당한 28.40%의 개선을 달성
- 그러나 200M 데이터셋을 사용할 때 이는 10.20%로 감소
- 이러한 결과는 제안한 파이프라인이 CLIP 사전 학습을 개선하는 데 장점을 보여줌
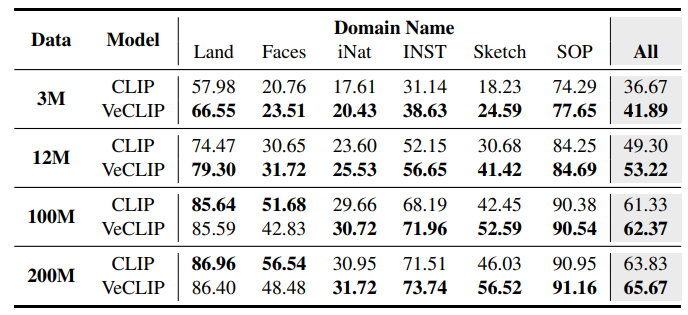
- 주요 성능 향상은 Sketch 도메인에서 나오며, zeroshot transferability에서 시각적 개념의 중요한 역할을 강조
- 결과적으로, 시각적으로 풍부한 캡션은 downstream task로의 transferability을 학습하는 데 중요한 역할을 함
5. Discussion
- LLaVA와 LLM을 활용하여 캡션을 더 시각적으로 풍부한 개념으로 재작성하여 CLIP pre-training을 개선하는 간단하면서도 효과적인 방법을 제시
- VeCLIP는 웹 크롤링을 통해 얻은 광범위한 image-text 데이터셋을 처리할 수 있도록 확장 가능하고 적응 가능하게 고안
- VeCLIP을 다양한 raw 및 noise 데이터셋에 대해 철저히 평가하였으며, 작은, 중간 및 대규모 규모를 아우르는 결과를 보여줌
- 결과는 큰 규모의 VLM pre-training을 향상시키는 우리의 전략의 효과를 강력하게 입증하는 상당한 성능 향상을 나타냄
- VeCLIP은 대규모 모델의 학습 데이터의 계산 비용과 크기를 크게 줄일 수 있어 기본적인 CLIP과 유사한 결과를 얻을 수 있게 됨
