https://arxiv.org/abs/2403.13043
1. Introduction
AI model size의 증가
- 최근 인공지능 분야에서 model size의 증가는 language modeling, image 및 비디오 생성 등 다양한 분야에서 발전을 이끌어온 주요 요소였음
- 특히, 시각적 이해를 위해 larger model은 충분한 pre-training 데이터를 제공할 때 다양한 downstream task에서 일관되게 개선된 성능을 보여줌
- 이러한 경향은 수십억 개의 파라미터를 가진 거대 model을 추구하는 것으로 이어짐
Larger model이 항상 더 나은 visual understanding을 위한 필수 조건인가?
- 본 논문에서는 model size를 키우는 대신, image scale 차원에서 scaling을 고려하는 "Scaling on Scales (S²)"라는 개념을 제안
- S²는 pre-trained fixed small vision model(예: ViT-B 또는 ViT-L)을 여러 image scale에서 실행하여 multi-scale representation을 생성
S² 방법론
- Single image scale(예: 224²)에서 pre-training된 model을 여러 scale(예: 224², 448², 672²)로 interpolation 하고, larger image를 정규 size(224²)로 잘라 각각의 feature를 extraction한 후 이를 pooling 하고 원래의 feature와 연결하여 새로운 representation을 만듦 (아래 그림 참고)
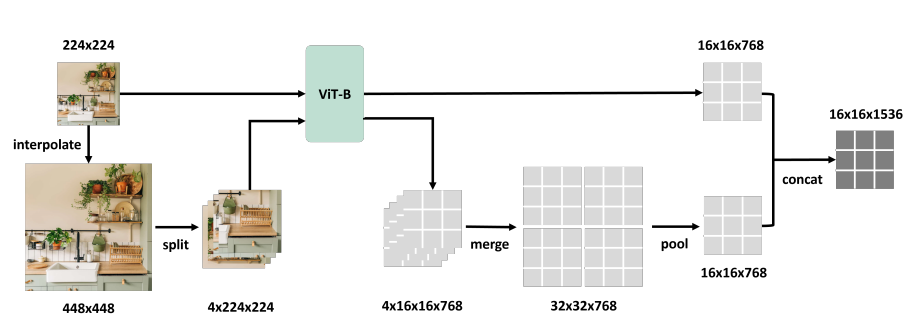
결과
- 다양한 pre-training된 model들(e.g., ViT, DINOv2, OpenCLIP, MVP)에 대한 평가에서, S² scaling을 사용한 smaller model이 larger model보다 classification, semantic segmentation, depth estimation, MLLM benchmarks, robotic manipulation 등에서 일관되게 우수한 성능을 발휘
- 이 model들은 훨씬 적은 파라미터 수(0.28×에서 0.07×)와 비슷한 GFLOPS로 동작
- 특히, image scale을 1008²로 확장함으로써 V∗ 벤치마크에서 MLLM visual detail understanding에 있어 SOTA 달성
추가 연구
- S²가 model size scaling보다 더 나은 접근 방식인 상황을 조사
- S² scaling을 사용한 smaller model이 larger model보다 여러 시나리오에서 더 나은 downstream 성능을 달성하지만, 어려운 예제에서 larger model이 여전히 더 뛰어난 일반화 능력을 보임
- 그러나 실험을 통해 smaller model도 single linear transform을 통해 larger model의 feature를 잘 근사할 수 있음을 발견, 이는 smaller model이 larger model과 비슷한 학습 능력을 가질 수 있음을 의미
- Smaller model의 일반화 능력이 약한 이유는 single image scale에서만 pre-training되었기 때문이라고 가정
- 이를 증명하기 위해 ImageNet-21k로 ViT를 pre-training한 실험을 통해, S² scaling을 사용한 pre-training이 smaller model의 일반화 능력을 향상시키고 larger model의 장점을 맞추거나 능가할 수 있음을 보여줌
2. Related Work
Multi-scale representation
- Object를 scale-invariant way로 인식하는 데 일반적인 기술로, feature engineering 시대부터 사용
- 이후 CNN에도 도입되어 high-level semantic과 low-level detail을 모두 포함하는 feature를 extraction
- Multi-scale representation은 detection 및 segmentation과 같은 task에서 기본적인 test time augmentation 방법이 되었으나, 이는 크게 느려진 추론 속도와 제한된 image scailing (최대 2배)이라는 단점이 있음
- 최근 ViT에서의 발전과 함께 multi-scale ViT와 hierarchical ViT 변형이 제안되었으나, 이 연구들은 일반적인 pre-training된 vision model에 적용하기 어려운 특수한 아키텍처 설계에 집중
Scaling Vision Models
- Visual pre-training은 더 강력한 representation을 얻기 위해 파라미터 수를 증가시키는 것이 기본 접근 방식이었음
- 이전 연구에서는 model의 width, depth, input resolution을 균형 있게 확장하는 방법을 연구하였으나, 이는 주로 CNN이나 ResNet과 같은 특정 아키텍처에 한정
- 최근에는 다양한 설정에서 ViT의 model size scaling도 탐구
- 또 다른 연구에서는 고해상도 image를 pre-training에 통합하였으나, 최대 해상도가 512²를 초과하지 않음
- Hu et al.은 Masked Autoencoder(MAE)에서 patch size를 조정하여 image scale을 조정하는 연구를 진행하였으나, 이는 pre-training에만 적용되었으며 downstream task에는 적용되지 않았음
3. The Power of Scaling on Scales
3.1 Scaling Pre-Trained Vision Models to Multiple Image Scales
- -Wrapper 제안
- Pre-trained vision model에 multi-scale의 feature extraction을 가능하게 하는 매커니즘
- 기존 model은 single scale의 이미지로 학습 (예: )
- -Wrapper는 여러 이미지 scale(예: , )로 확장
- e.g. 이미지를 크기의 4개의 하위 이미지로 split하여 원래 이미지와 함께 같은 pre-trained model에 입력
- 4개의 하위 이미지의 feature를 합쳐서 이미지의 큰 feature map을 생성 후, 이미지의 feature map 크기와 동일하게 average-pooling
- 출력은 여러 scale의 feature map을 연결하여 생성
- 전체 파이프라인은 아래 그림 참고
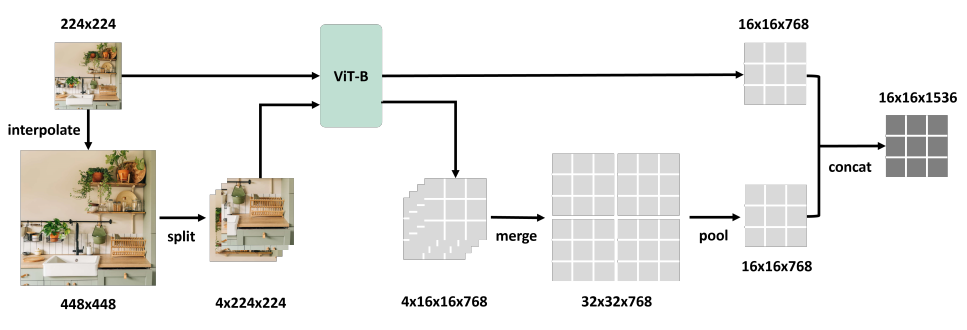
-
주의사항
- 고해상도 정보를 추가하지 않기 위해 이미지에서 이미지를 interpolation 하여 생성
- 실제 application에서는 고해상도 이미지를 직접 사용하는 것이 권장됨
-
효율성과 확장성
- 큰 이미지를 작은 하위 이미지로 split 하여 Self-Attention 계산 복잡도 감소
- Window attention을 사용하지 않고 개별 하위 이미지를 처리하여 추가 매개변수 학습 방지
- 큰 feature map을 보통 크기로 interpolation하여 출력 토큰 수를 동일하게 유지
3.2 Scaling on Image Scales Can Beat Scaling on Model Size
-
-Wrapper의 -scaling
- Model size를 유지하면서 더 강력한 feature를 추출할 수 있는 multi-image scale 사용
- Model size를 키우는 대신, 더 많은 image scale에서 실행하여 강력한 성능 달성 가능
- 세 가지 대표적인 task (image classification, semantic segmentation, depth estimation)에서 model size scaling와 -scaling의 비교 실험 수행
- 실험 데이터셋: ImageNet, ADE20k, NYUv2
- Model: ViT, DINOv2, OpenCLIP
- 세 가지 scale set로 테스트: (1x), (1x, 2x), (1x, 2x, 3x)
- 예: ViT의 경우, (224²), (224², 448²), (224², 448², 672²) set 사용
- 대부분의 경우에서 -scaling이 model size scaling 보다 우수한 결과를 보임
-
Multi-modal LLMs 사례 연구
- -scaling과 model size scaling의 비교
- 실험 model: Vicuna-7B LLM, OpenCLIP
- Model size scaling: large, huge, giant
- -scaling: (224²), (224², 448²), (224², 448², 896²) 테스트
- 세 가지 벤치마크 유형으로 평가: visual detailed understanding, VQA Benchmarks, MLLM Benchmarks
- -scaling이 모든 벤치마크에서 larger model보다 더 나은 성능을 보여줌
- 특히, 896² 크기로 scaling할 때 detailed understanding 정확도가 약 6% 증가
Case study: image classification, semantic segmentation, and depth estimation
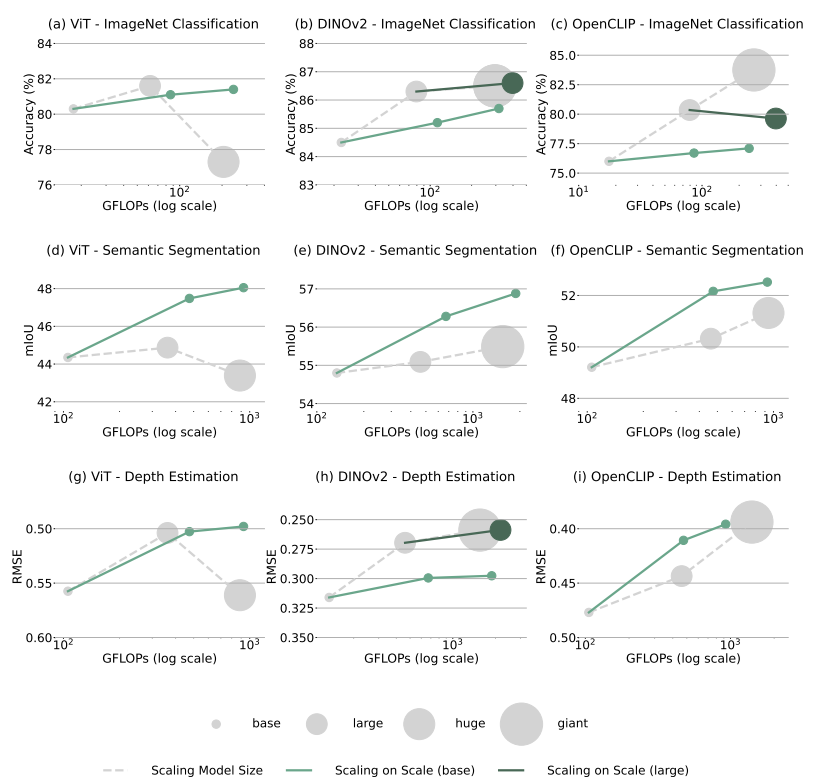
- 위 그림에서 scaling curve를 확인할 수 있음
- (a), (d), (e), (f), (g), (i)에서 S² scaling을 적용한 base model이 이미 유사한 GFLOPs를 가진 larger model들과 비슷하거나 더 나은 성능을 보여주고 있음. 이는 훨씬 smaller model size로 달성된 결과
- (b), (h)에서 larger model에 S² scaling을 적용한 결과가 giant model과 비슷한 성능을 보여주고 있음. 이 경우에도 유사한 GFLOPs를 사용하면서 더 적은 파라미터를 가짐
- 유일한 실패 사례는 (c)임. 여기서는 base나 larger model에 S² scaling을 적용해도 model size scaling과 경쟁하지 못함
Case study: Multimodal LLMs
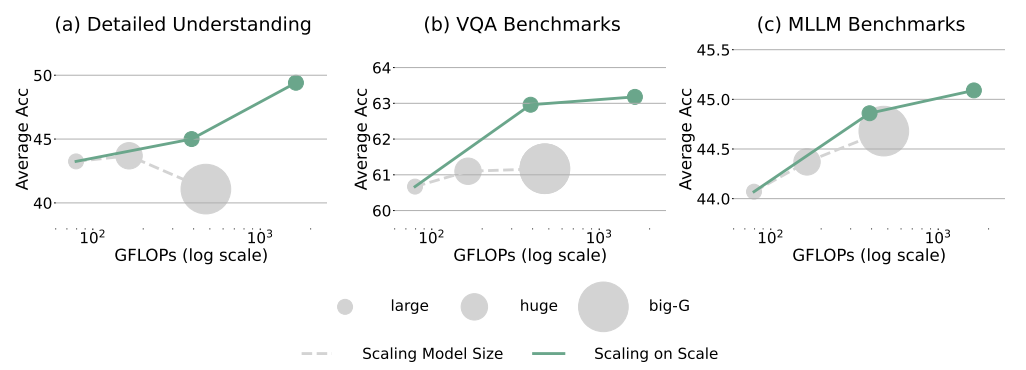
- MLLMs에서 S² scaling과 model size scaling을 비교
- LLM은 Vicuna-7B 이고, vision backbone은 OpenCLIP, 동일한 LLM을 유지하고 vision backbone만 변경
- 위 그림에서 세 가지 유형의 모든 벤치마크에서 larger size model에서의 S² scaling이 유사한 GFLOPs 및 훨씬 smaller model size를 사용하여 더 나은 성능을 제공함을 볼 수 있음
- 모든 벤치마크에서 larger image scale이 일관된 성능 향상을 가져오는 반면, larger model은 때로는 성능 향상에 실패하거나 심지어 성능을 저하시킬 수 있음
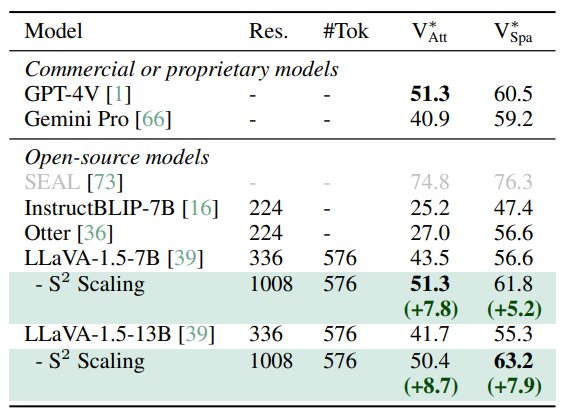
- S² scaling을 적용한 LLaVA-1.5가 이미 SOTA 오픈소스 및 상용 MLLM을 대등하거나 능가
- Visual detail understanding 결과는 위 테이블에 표시
- 한편, GPT-4V와 LLaVA-1.5는 올바른 답변을 제공하지 못함
- 이전 실험과는 달리, 여기서는 SOTA와 비교하기 위해 저해상도 image에서 interpolation 하는 대신 고해상도 image를 직접 사용
Case study: robotic manipulation
- 큐브를 집는 robotic manipulation task에서 S²와 model size scaling을 비교
- 이 작업은 로봇 팔을 사용하여 탁자 위의 큐브를 집는 것을 요구
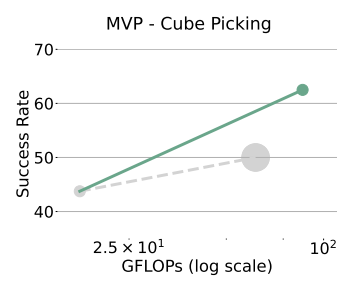
- 위 그림에서, base에서 larger model로의 scaling은 성공률을 약 6% 향상시키는 반면, larger image scale로의 scaling은 성공률을 약 20% 향상시킴
- 이는 robotic manipulation task에서 S²의 model size scaling에 비해 이점을 보여주는 것을 나타냄
3.3. The Sweet Spot Between Model Size Scaling and S² Scaling
- Scaling이 다양한 downstream task에서 model size scaling 보다 우월한 성능을 보이지만, 어떤 model size에서 S² scaling을 수행해야 적절할지 의문이 발생

- 위 그림처럼, 이는 pre-training 된 model에 따라 달라짐
- 특정 model의 경우, larger model에서의 S² scaling이 base model에서의 S² scaling이 이미 larger model을 능가할 때 더 나은 scaling curve를 제공
4.1 Larger Models Generalize Better on Hard Examples
- 첫 번째 유형은 드문 예제. 예를 들어, "조각상 형태의 텔레비전 또는 플루트"와 같은 일반적이지 않은 예제
- Larger model은 pre-training 중에 이러한 드문 예제를 분류하는 데 더 많은 용량을 가지고 있음
- 두 번째 유형은 애매한 예제. 예를 들어, "로션과 비누 디스펜서" 처럼 객체가 어느 카테고리에 속할 수 있는지 확실하지 않은 경우
- 여러 올바른 label에도 불구하고, larger model은 pre-training 중에 데이터셋에 표시된 label을 기억할 수 있음
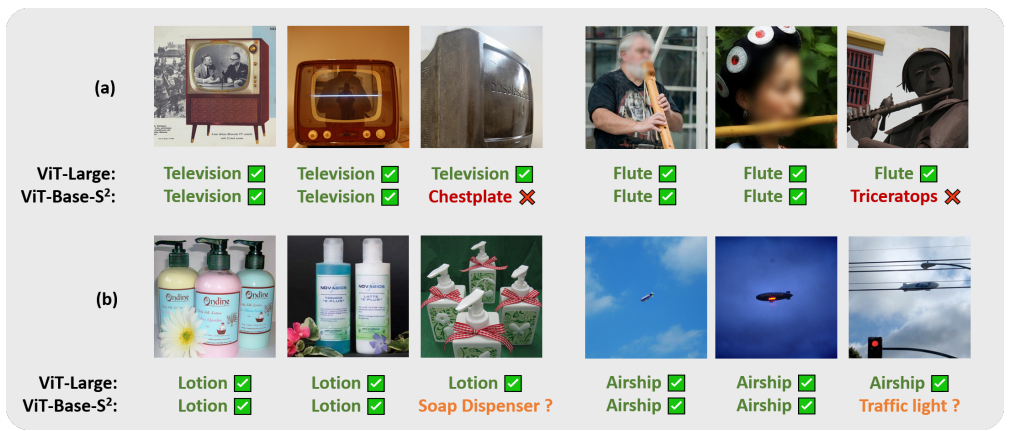
- ImageNet 데이터셋에서 ViT-L이 ViT-B보다 개선이 됨
- 하지만 위 그럼처럼 ViT-B-S² 에서는 개선되지 않음
4.2 Can Smaller Models Learn What Larger Models Learn?
실험 목적
- Larger model이 학습한 고유한 representation을 smaller model은 학습할 수 없는지 여부를 조사
- Multi-scale smaller model이 larger model의 representation을 얼마나 학습할 수 있는지 연구
Reconstruction 기반 평가 방법
- Larger model (e.g. ViT-L)의 representation을 multi-scale smaller model (e.g. ViT-B-S2)로 reconstruction하는 선형 변환 학습
- Reconstruction loss가 낮을수록 multi-scale smaller model이 larger model의 representation을 잘 학습했음을 의미
- Reconstruction loss를 MSE로 계산
- Mutual Information ()
- 는 reconstruction loss
- 는 dummy vector로 reconstruction한 loss (Appendix B 참조)
Mutual Information?
두 확률 변수 사이의 상호 의존성을 측정하는 값으로, 하나의 변수가 다른 변수에 대해 제공하는 정보량을 나타냄. 두 변수의 상호 정보가 높을수록 하나의 변수를 통해 다른 변수에 대한 예측 정확도가 높아짐
- Linear Transform을 사용하는 이유:
- Channel permutation 등의 representation 동등성을 유지하는 연산 반영
- 가벼운 모듈(e.g. single linear layer)을 사용하는 downstream task에 유용한 정보 측정
Reconstruction loss 분석
- Reconstruction loss는 대개 0에 가깝지 않음
- 특정 feature는 본질적으로 reconstruction 불가능
- Randomness in weight initialization, optimization dynamics ... 때문
- Larger model (e.g. ViT-G)을 사용하여 larger model feature를 reconstruction하여 비교
- Reconstruction loss 및 해당 Mutual Information
- Multi-scale smaller model의 representation을 통한 larger model reconstruction 정보는 larger model이 reconstruction 할 수 있는 최대 정보를 나타내야 함
- Reconstruction ratio 로 larger model representation을 multi-scale smaller model이 얼마나 학습했는지 측정
실험 결과
- Model: ViT (ImageNet-21k), OpenCLIP (LAION-2B), MAE (ImageNet-1k)
- Reconstruction loss는 ImageNet-1k에서 평가됨
- 결과
- Multi-scale base model은 일반 base model보다 일관되게 더 낮은 loss를 보이며, larger model의 representation을 더 많이 reconstruction
- 대부분의 경우에서 multi-scale base model은 huge model과 유사한 정보를 reconstruction
- 예: OpenCLIP-Base는 92.7%의 정보를 reconstruction하지만, multi-scale base model은 99.9% reconstruction
- Larger model이 multi-scale smaller model에 비해 reconstruction 가능한 정보를 더 많이 학습하지 않음
- OpenCLIP-Huge의 경우 reconstruction 비율이 88.9%로 다소 낮지만, 여전히 base model보다는 훨씬 높은 reconstruction 비율을 보임
결론
- Multi-scale smaller model은 larger model이 학습하는 대부분의 representation을 학습할 수 있는 능력이 있음
- 학습 및 테스트 세트 간의 차이가 존재
- 테스트 세트에서의 reconstruction 비율이 학습 세트보다 낮을 수 있음
- 이는 pre-training 후 multi-scale을 적용했기 때문에, single image scale로 학습된 base model representation의 일반화 능력이 약하기 때문일 가능성 있음
5. Discussion
- 본 논문에서는 'Visual understanding을 위해 larger model이 항상 필요한가' 라는 질문을 던지고 있음
- 결과적으로, model size를 늘리는 대신 image scale(Scaling on Scales, S²)을 조정하는 것이 다양한 downstream task에서 더 나은 성능을 내는 것으로 나타남
- 또한 S²를 적용한 smaller model도 larger model에서 학습한 것과 거의 동등한 수준의 representation을 학습할 수 있으며, S²로 pre-training 한 smaller model이 larger model의 장점을 따라잡거나 더 좋은 성능을 낼 수 있음

AI Research Engineer