https://arxiv.org/abs/2311.17049
CVPR 2024
1. Introduction
- CLIP과 같은 대규모 이미지-텍스트 기반 모델은 다양한 하향 작업에서 우수한 zero-shot 성능과 향상된 robustness를 보여주었음
- 그러나 이러한 모델을 모바일 장치에 배포하는 것은 size가 크고 latency가 높은 문제로 인해 어려움이 있음
- 이 논문의 목표는 모바일 장치에 적합한 새로운 이미지-텍스트 인코더를 설계하는 것
- 이 목표를 실현하기 위한 두 가지 주요 도전이 있음
- 첫째, 런타임 성능(예: Latency)과 다양한 아키텍처의 정확도 사이에는 trade-off가 있으므로, 다양한 아키텍처 디자인을 빠르고 철저하게 분석할 수 있어야 함
- 둘째, 작은 아키텍처의 용량이 축소되면서 낮은 정확도가 발생하며, 이를 개선할 수 있는 더 나은 학습 방법이 필요
본 논문의 contribution은 다음과 같음:
- 새로운 mobile-friendly CLIP 모델 패밀리인 MobileCLIP을 설계. MobileCLIP의 변형은 하이브리드 CNN-Transformer 아키텍처를 사용하여 이미지 및 텍스트 인코더의 size와 latency을 줄이기 위한 구조 reparametrization을 채택
- Multi-modal reinforced training이라는 새로운 학습 전략을 소개. 이는 사전 학습된 이미지 캡션 모델과 강력한 CLIP 모델 앙상블로부터의 knowledge transfer를 통해 학습 효율성을 향상시킴
- Reinforced dataset의 두 가지 변형인 DataCompDR-12M과 DataCompDR-1B를 소개. DataCompDR을 사용하여 DataComp에 비해 10배에서 1000배의 학습 효율성을 보여줌
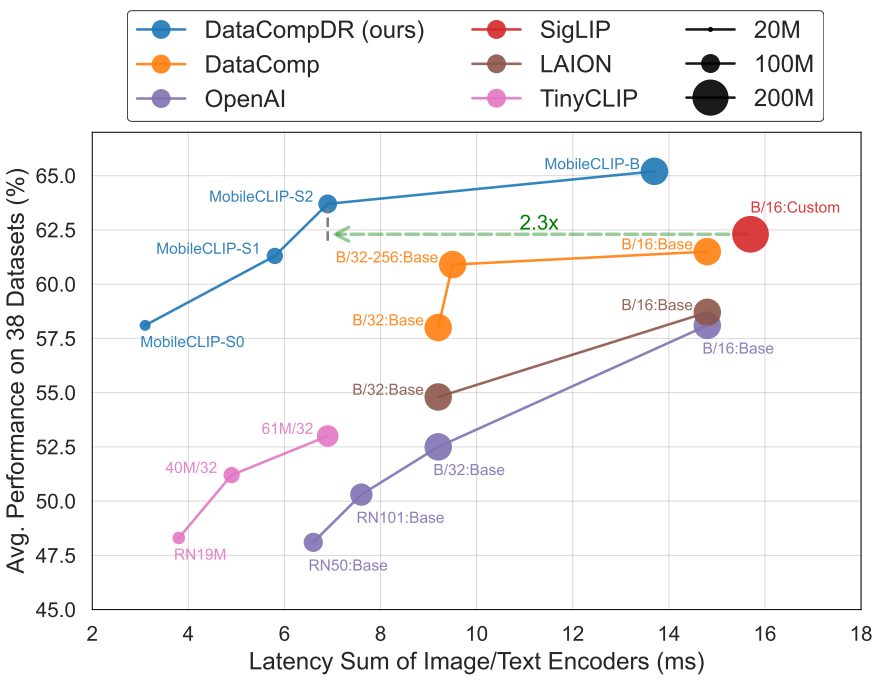
- MobileCLIP 패밀리는 zero-shot task에서 SOTA의 latencyaccuracy tradeoff를 달성하며, 이 중에서 ViT-B/16 기반의 새로운 최고 성능 CLIP 모델을 제공
3. Multi-Modal Reinforced Training
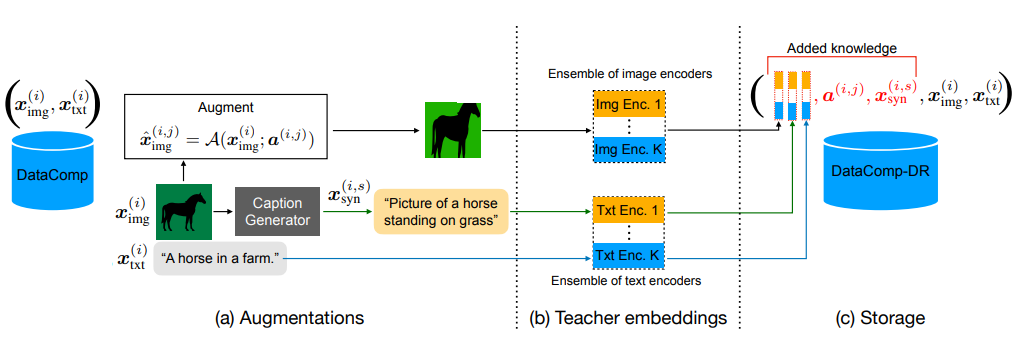
- Multi-modal reinforced training 전략은 두 가지 주요 구성 요소로 구성
i) 합성 캡션을 통한 이미지 캡션 모델의 knowledge를 활용
ii) 사전 학습된 CLIP 모델 앙상블로부터의 이미지-텍스트 정렬의 knowledge distillation
3.1. Dataset Reinforcement
Synthetic captions
-
CLIP 모델을 학습하는 데 사용되는 이미지-텍스트 데이터셋은 대부분 웹에서 가져온 것으로, 본질적으로 noise가 많음
-
최근의 연구로는 DataComp 및 data filtering networks와 같은 웹 소스 데이터셋의 품질을 향상시키기 위해 광범위한 필터링 메커니즘을 사용
-
이러한 필터링된 데이터셋은 더 낮은 noise을 가지고 있지만, 캡션은 여전히 충분히 기술적이지 않을 수 있음
-
캡션의 시각적 설명력을 강화하기 위해 본 논문에서는 인기 있는 CoCa 모델을 사용하여 각 이미지에 대해 여러 개의 합성 캡션 x를 생성
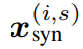
-
각 이미지 당 생성된 합성 캡션의 수에 대한 실험은 5.1절에서 제공

-
위 그림은 CoCa 모델에 의해 생성된 합성 캡션의 몇 가지 예시
-
실제 캡션과 비교하여 합성 캡션은 일반적으로 보다 구체적이지만 noise가 많음
-
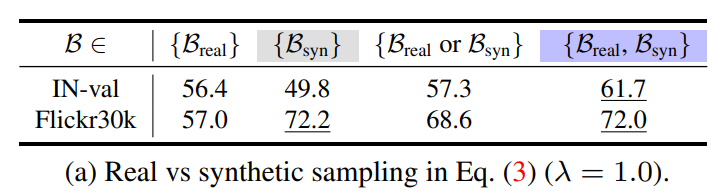
위 테이블과 같이, 실제 캡션과 합성 캡션을 모두 사용하는 것이 최고의 zero-shot 검색 및 분류 성능을 얻기 위한 중요성을 보여줌
Image augmentations
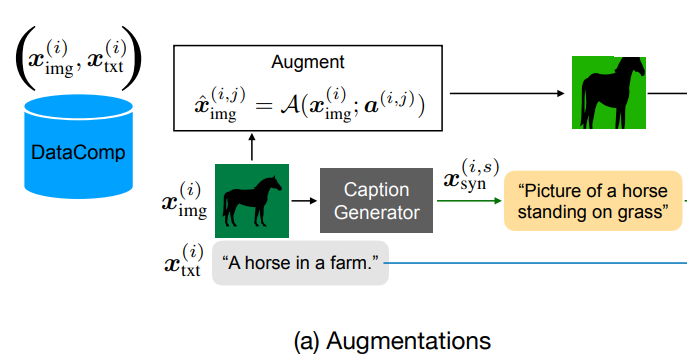
- 각 이미지 x에 대해 parametrized augmentation function "A"를 사용하여 여러 개의 augmented 이미지 xˆ를 생성
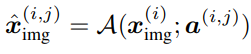
Ensemble teacher
- 모델 앙상블링은 독립적으로 학습된 모델 집합에서 더 강력한 모델을 만들기 위한 널리 사용되는 전략
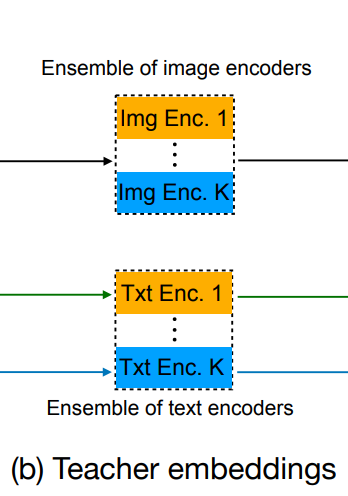
- 이 전략을 multi-modal 설정으로 확장하고 K개의 CLIP 모델 앙상블을 강력한 teacher로 사용
Reinforced dataset
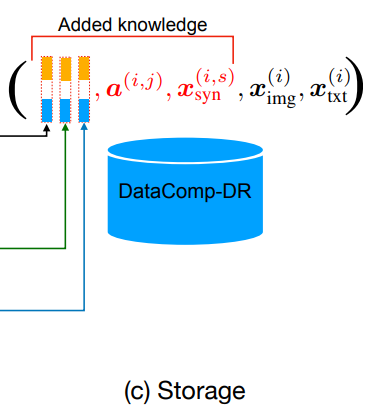
- CLIP teacher들의 이미지 augmentation parameter a(i,j), 합성 캡션 x(i,s)syn, 특성 임베딩 ψ(i,j,k)img, ψ(i,s,k)syn 및 ψ(i,k)txt를 원본 이미지 x(i)img와 캡션 x(i)txt와 함께 데이터셋에 추가적인 knowledge로 저장
3.2. Training
Loss function
- Loss function은 여러 이미지-텍스트 teacher 인코더들 간의 이미지-텍스트 쌍 간의 유사성 행렬(affinity matrix)을 training target 이미지-텍스트 인코더로 distillation
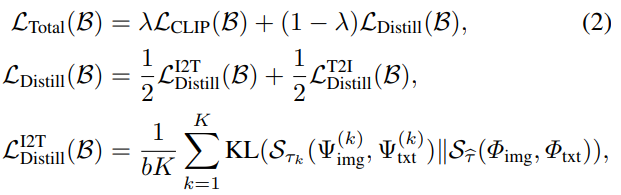
- B를 b개의 (이미지, 텍스트) 쌍으로 이루어진 batch로 표시하고, Ψ(k)img, Ψ(k)txt ∈ Rb×dk를 batch B에 대한 k번째 모델의 dk-dimension 이미지 및 text embedding matrix로 각각 나타냄
- 이에 대응하여, target 모델의 이미지 및 text embedding matrix를 Φimg, Φtxt ∈ Rb×d로 표시
- 주어진 U 및 V 행렬에 대해, UV⊤/τ에 row-wise Softmax 작업을 적용하여 얻은 affinity matrix을 Sτ(U,V) ∈ Rb×b로 나타냄
- 여기서 τ는 temperature parameter
- Training loss는 standard CLIP loss LCLIP(B)와 knowledge distillation loss LDistill(B) 두 가지 요소로 구성
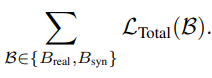
- 앞서 말한대로, teacher embedding은 데이터셋의 일부로 이미 준비되어 있으므로, knowledge distillation loss를 계산하기 위해 필요한 teacher 관련 계산을 추가로 수행할 필요 없이 student 모델의 forward pass 후에 전체 loss을 계산할 수 있음
4. Architecture
4.1. Text Encoder
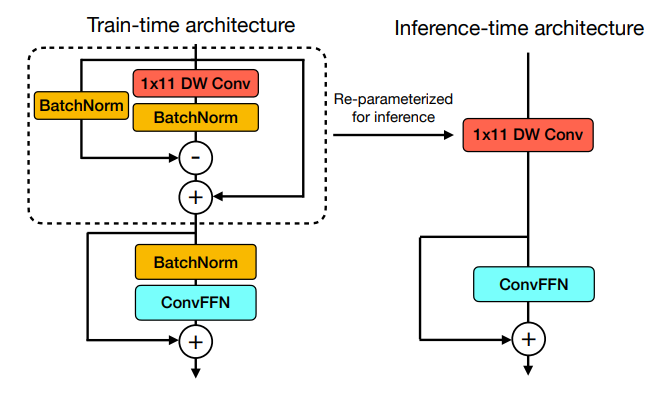
- 텍스트 인코딩을 위해 fully convolutional architecture 대신 1-D convolutions and self-attention layer를 사용하는 hybrid text encoder를 소개
- 학습 시간과 추론 시간 아키텍처를 분리하는 합성곱적인 토큰 믹서인 Text-RepMixer를 소개
- Text-RepMixer는 "Fastvit"에서 소개된 reparameterizable convolutional token mixing(RepMixer)에서 영감을 받음
- 아래 그림처럼, 추론 시에 skip connection이 parameterize 됨
- FFN에서는 추가적인 depthwise 1-D convolution으로 보강하여 ConvFFN 블록을 구성하고 Kernel size는 11로 설정
4.2. Image Encoder
- FastViT 아키텍처를 기반으로 한 개선된 하이브리드 vision transformer MCi를 도입
- FastViT에서는 FFN 블록에 대해 MLP expansion ratio는 4.0으로 사용
- 최근 연구들 [38, 67]은 FFN 블록의 선형 레이어에서 상당한 중복성(redundancy)이 드러남. 따라서 parameter efficiency를 향상시키기 위해 expansion ratio을 단순히 3.0으로 낮추고 아키텍처의 depth를 증가
- 이를 통해 이미지 인코더의 동일한 parameter 수를 유지
5. Experiments
Small Scale Regime
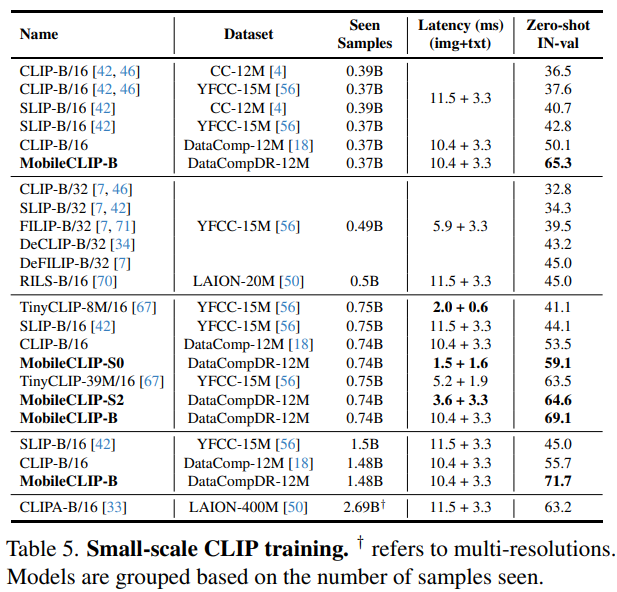
- Table 5에서는 12-20M 샘플을 사용하여 학습된 방법들을 비교
- 이는 빠른 탐색 (예: 아키텍처 검색)을 위한 비교적 작은 범위
- DataCompDR-12M에서 학습된 MobileCLIP-B는 370M 개 미만의 샘플로 매우 우수한 성능을 보여 다른 모든 방법보다 최대 4배 더 긴 학습을 거쳤음에도 불구하고 현저히 뛰어남
- MobileCLIP-B는 SLIP [42] (42.8 → 45.0%)에 비해 본 샘플 수에 따라 크게 확장되는 것을 보여줌
- TinyCLIP-39M/16은 MobileCLIP-S2에 비해 더 높은 latency와 덜 정확하며, TinyCLIP-8M/16은 MobileCLIP-S0 (41.1% 대 59.1%)보다 크게 정확도가 낮으며 latency가 거의 같음
Learning Efficiency
- Knowledge distillation을 사용한 더 긴 학습은 분류 모델의 성능을 지속적으로 향상시킨다고 알려져 있음
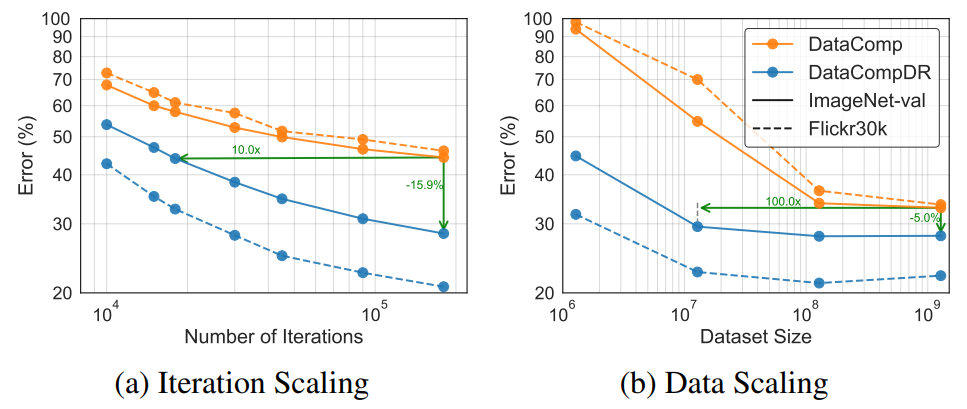
- 위 그림 (a)에서는 12M의 DataComp-1B 하위 집합만 사용하여 120 epoch 후에도 71.7%의 ImageNet 검증 세트 zero-shot 정확도를 달성하는 것을 보여줌
- (b)에서는 데이터셋 크기에 따른 스케일링을 보여줌
- DataCompDR에서의 학습은 1.28M 샘플에서 55.2% 이상의 정확도에 도달하는 반면, DataComp-1B에서의 학습은 약 6% 정도에 머무름
- 이 설정에서, DataCompDR을 사용하여 100배 이상의 데이터 효율성을 관찰
- 더불어, Flickr30k에서의 성능에서는 1000배 이상의 데이터 효율성을 관찰
Comparison with State-of-the-art
- Large scale training을 한 모델들과 비교
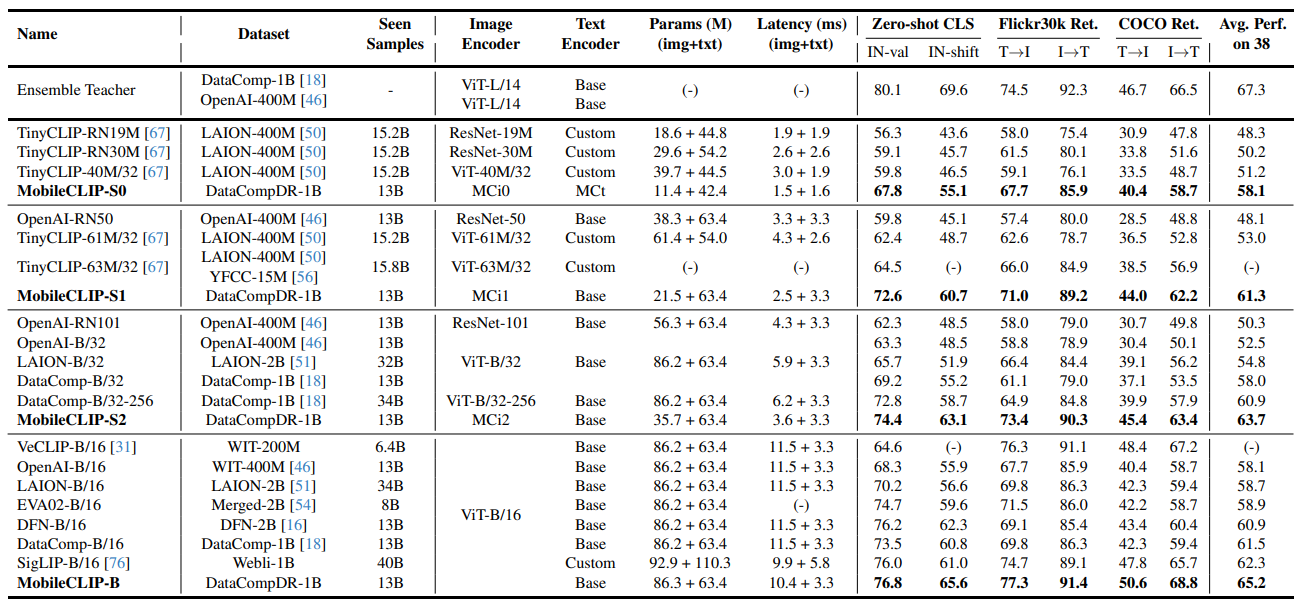
- DataCompDR-1B에서 학습된 MobileCLIP-S0는 TinyCLIP과 같은 최근 작업보다 훨씬 우수한 성능을 보이며, DataComp에서 학습된 ViT-B/32 모델과 유사한 성능을 보임
- 그런데 MobileCLIP-S0는 2.8배 작고 3배 빠름. MobileCLIP-S2는 38개의 데이터셋에서 평균 성능이 2.8% 더 우수하며, DataComp에서 2.6배 더 긴 학습을 거친 ViT-B/32-256 모델과 비교했을 때 retrieval performance이 훨씬 우수
6. Conclusion
- 이 연구에서는 low latency and size의 device에서 CLIP 추론을 위해 설계된 MobileCLIP에 맞춰진 이미지-텍스트 backbone을 제안
- 사전 학습된 이미지 캡션 모델과 강력한 CLIP 모델 앙상블에서 얻은 knowledge로 DataComp를 강화한 DataCompDR을 제안
- 강화된 데이터셋으로 10배에서 1000배까지의 학습 효율성(learning efficiency)을 입증
- DataCompDR에서 학습된 MobileCLIP 모델은 이전 작업과 비교했을 때 latency-accuracy tradeoff에서 최고의 성능을 달성
- MobileCLIP 모델은 또한 ARO 벤치마크에서 더 나은 robustness와 성능을 보임

AI Research Engineer