https://arxiv.org/abs/2403.07392
CVPR 2024
1. Introduction
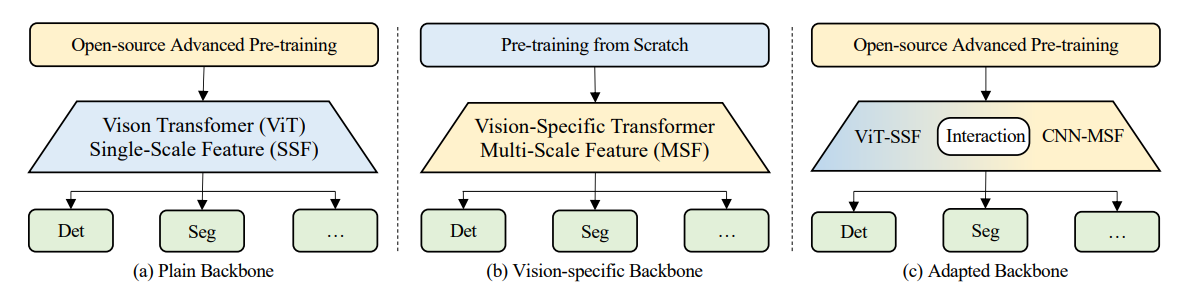
- 현재 Dense prediction task를 위한 트랜스포머 기반 네트워크 구조는 위 그림과 같이 Plain backbone, Vision-specific backbone, Adapted backbone과 같이 세 가지 패러다임으로 나뉨
- Plain backbone은 ViTDet과 같이 ViT 프레임워크를 변경하지 않고 ViT feature를 최적화
- Vision-specific backbone (e.g. Swin, CMT, MPViT, PVT)은 CNN과 트랜스포머의 장점을 결합하여 네트워크 구조를 재설계
- Adapted backbone은 일반 ViT를 기반으로 additional branch를 도입하여 다양한 오픈소스 및 강력한 사전 학습된 ViT weight를 직접 로드하여 ViT 성능을 개선
- 본 논문에서는 다양한 오픈소스 및 고급 사전 학습 weight를 직접 로드할 수 있는 plain, pretraining-free, feature-enhanced ViT backbone인 ViT-CoMer를 제안
- 주요 Contribution은 다음과 같음
- Plain ViT와 CNN feature를 결합하여 새로운 dense prediction backbone을 제안. 이를 통해 다양한 오픈소스 사전 학습된 ViT weight를 효과적으로 활용
- Multi-receptive field feature pyramid module과 CNN-Transformer bidirectional fusion interaction module을 설계
- 제안한 ViT-CoMer를 object detection, instance segmentation, semantic segmentation 등 여러 dense prediction benchmark에 적용하여 평가하여 제안된 방법이 일반 ViT의 능력을 크게 향상시켰음을 보여줌
3. The ViT-CoMer Method
3.1. Overall Architecture
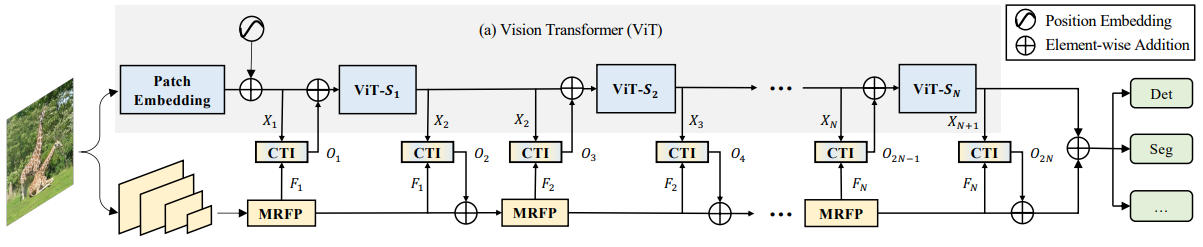
- ViT-CoMer의 전체 구조는 아래와 같이 세 부분으로 이루어져 있음
1) Plain ViT
2) Multi-receptive field feature pyramid module (MRFP)
3) CNN-Transformer bidirectional fusion interaction module (CTI) - 입력 이미지는 ViT branch와 CNN branch의 두 갈래로 전달
- ViT branch서는 패치 임베딩을 통해 해상도가 1/16로 축소된 feature를 얻고, CNN branch에서는 다양한 스케일(1/8, 1/16, 1/32)의 feature pyramid를 얻음
- 이후 N개의 stage에 걸쳐 두 branch feature가 상호작용
- 각 stage에서 MRFP를 통해 feature pyramid가 강화되고, CTI를 통해 ViT feature와 양방향 fusion이 이루어져 semantic multi-scale feature를 생성
- 마지막으로 두 branch의 feature가 각 스케일에서 결합되어 dense prediction task에 사용
3.2. Multi-Receptive Field Feature Pyramid
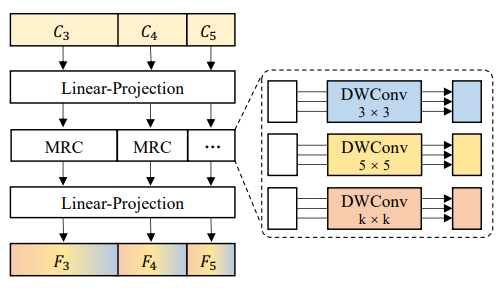
- MRFP는 multi-scale feature와 다양한 multi-receptive fields convolution을 결합하여 CNN feature의 표현력을 높이는 역할을 함
- MRFP는 다음과 같이 구성
-- 두 개의 Linear projection layer (FC)
-- Depth-wise separable convolutions with multi-receptive fields (DWConv) - 이는 아래 수식과 같이 표현할 수 있음
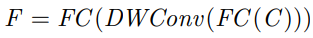
3.3. CNN-Transformer Bidirectional Fusion Interaction
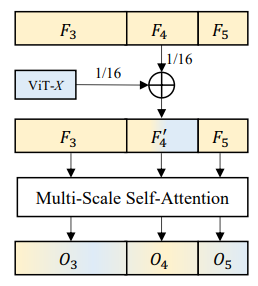
- CTI는 ViT 구조를 변경하지 않고 CNN의 multi-scale feature를 도입하는 cross-architecture feature fusion method
- 양방향 상호작용을 통해 ViT의 패치 내 정보 상호작용 부족 문제와 non-hierarchical feature 문제를 완화하면서, CNN의 long-range 모델링 능력과 semantic representation 능력도 더욱 향상
- 이는 아래 수식과 같이 표현할 수 있음
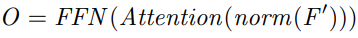
- norm(·)은 LayerNorm, Attention(·)은 multi-scale deformable attention, FFN(·)은 feedforward network
- 최종적으로 O3와 O5의 feature map 크기를 O4에 맞추기 위해 bilinear interpolation을 사용하고, X를 다음 ViT 계층의 입력으로 추가
- Multi-scale CNN과 Transformer feature를 효과적으로 fusion 함으로써 모델의 모델링 능력이 향상
- 구조 간 fusion 된 feature에 대해 양방향 상호작용이 적용되어 ViT와 CNN branch의 feature가 업데이트 됨
- 구체적으로 i번째 stage의 시작 부분에서 두 branch의 feature가 fusion되고, ViT branch에 주입
- 이 과정은 다음과 같이 표현될 수 있음
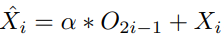
- X^i는 ViT branch의 업데이트된 feature이고, α는 0으로 초기화된 학습 가능한 변수
- α는 초기 학습 과정에서 무작위로 초기화된 CNN 구조가 ViT에 미치는 영향을 최소화
- stage i의 끝에서는 이 과정이 반복되어 feature가 CNN branch에 주입되는데, 이는 다음과 같이 표현
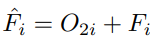
- F^i는 CNN bracnh의 업데이트된 feature
- Stage i의 수는 ViT의 depth에 따라 결정
- 구조 간 feature fusion과 양방향 상호작용을 통해 multi-scale, multi-level의 feature를 활용할 수 있음
- 이를 통해 모델의 표현력과 일반화 능력이 향상
4. Experiment
4.1. Object Detection and Instance Segmentation
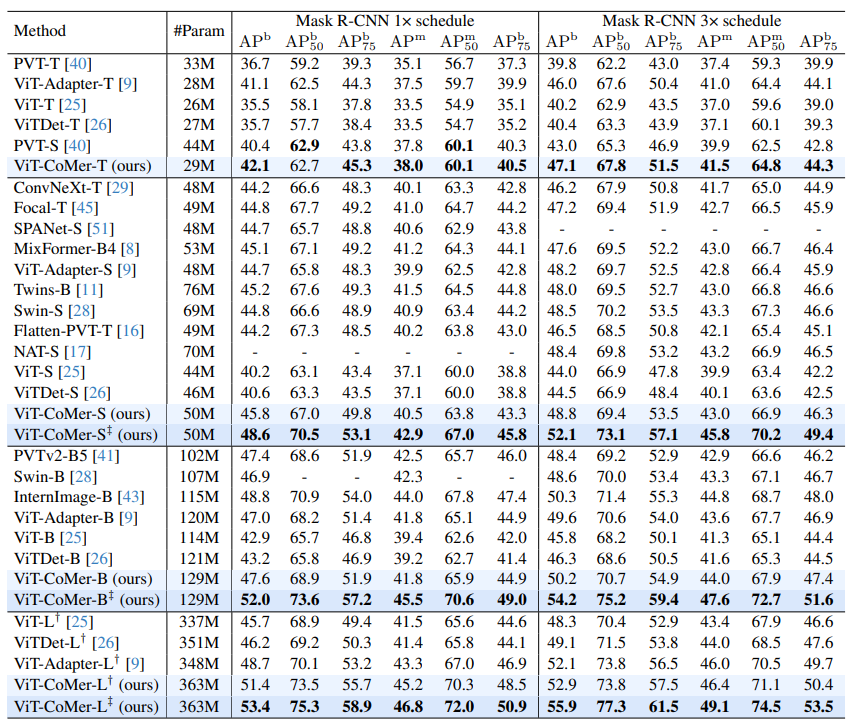
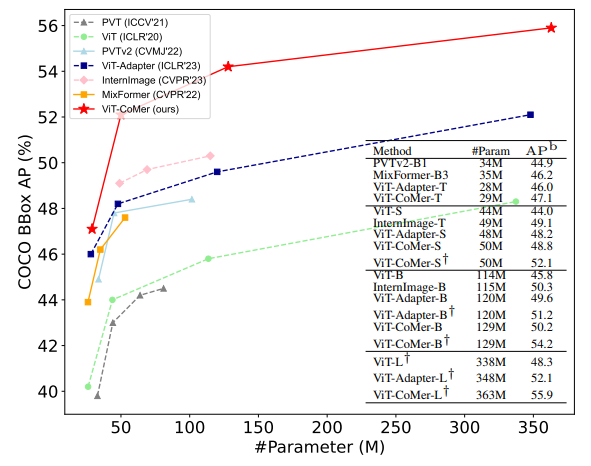
- 위 테이블은 Mask R-CNN 1x 및 3x 스케줄에서 ViT-CoMer와 다양한 규모의 Plain backbone, Vision-specific backbone, Adapted backbone을 비교
- 유사한 모델 크기에서 ViT-CoMer가 COCO object detection 및 instance segmentation과 같은 두 가지 전형적인 dense prediction task에서 다른 backbone을 능가하는 것을 볼 수 있음
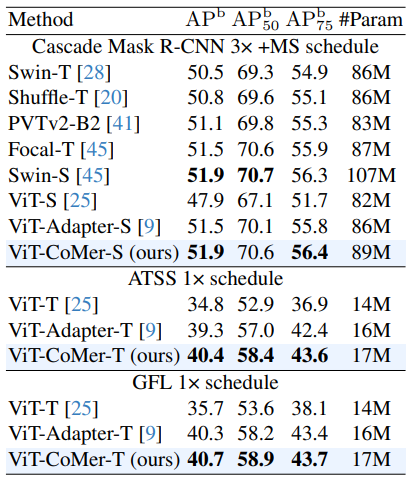
- 위 테이블은 ViT-CoMer를 다양한 Detection 프레임워크에 적용한 결과
- 여러 프레임워크, 모델 크기, 구성에 걸쳐 ViT-CoMer가 일관되게 다른 backbone을 능가하는 것으로 나타남
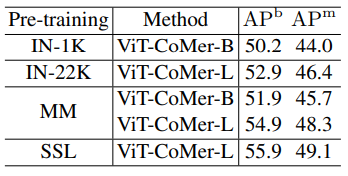
- 다양한 사전 학습 weight를 사용하여 Mask R-CNN (3x 스케줄)에 대한 실험을 진행
- ViT-CoMer-B에 multi-modal 사전학습을 적용하면 ImageNet-1K 대비 box AP에서 +1.7%, mask AP에서 +1.7% 향상
- ViT-CoMer-L에 대해서는 더 높은 수준의 사전학습을 비교했는데, 특히 self-supervised 사전학습에서 큰 성과를 얻음
- 이러한 결과는 사전학습의 효과적인 transfer learning 능력을 입증

- 성능을 더욱 높이기 위해 Co-DETR 프레임워크에 ViT-CoMer backbone을 적용하고, multi-modal 사전학습 BEiTv2로 모델을 초기화한 실험을 진행
- 위 테이블에 나타난 결과처럼, 추가 학습 데이터 없이 COCO val 2017 데이터셋에서 기존의 SOTA 알고리즘을 능가하는 성능을 보임
5. Conclusion
- 본 논문에서는 ViT-CoMer라는 새로운 ViT backbone을 제안
- CNN과 Transformer의 장점을 효과적으로 활용
- ViT 구조를 변경하지 않으면서, multi-scale convolutional feature interaction module을 통합하여 fine-grained hierarchical semantic feature를 재구성
- Object detection, instance segmentation, semantic segmentation 등 다양한 dense prediction task에서 ViT-CoMer는 우수한 성능을 달성
- 또한 고급 ViT 사전 학습 weight를 쉽게 활용할 수 있으며, SOTA backbone과 대등하거나 능가하는 성능을 냄

AI Research Engineer