https://arxiv.org/abs/2403.10516
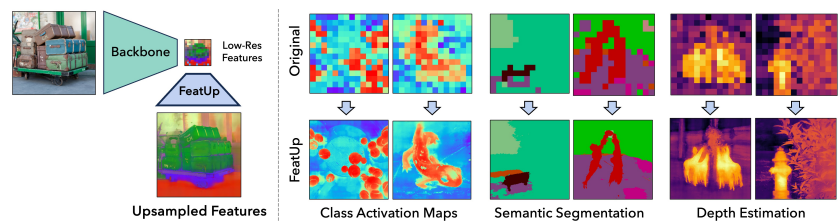
1. INTRODUCTION
- Deep feature들은 semantic quality을 위해 종종 공간 해상도를 희생
- 예를 들어 ResNet-50은 224×224 픽셀 입력에서 7×7 deep feature를 생성
- ViT 조차도 상당한 해상도 감소가 발생하기 때문에 이러한 feature만으로는 segmentation이나 depth estimation 같은 dense prediction 작업을 수행하기 어려움
- 이러한 문제를 완화하기 위해, 본 논문에서는 FeatUp이라는 프레임워크를 제안
- 모델의 출력에서 여러 "jittered" 이미지에 걸쳐 저해상도 뷰를 aggregate 함으로써 고해상도 정보를 학습
- 본 논문에서는 upsampling을 위한 두 가지 아키텍처를 탐구
1) 이미지에 걸쳐 일반화되는 single guided upsampling feedforward network
2) 단일 이미지에 overfit 된 implicit representation - 본 논문의 Contribution은 아래와 같음
- FeatUp: 빠른 up-sampling feedforward network를 이용해 feature를 좋은 품질로 up-sampling 시키는 방법
- 표준 PyTorch 구현보다 수천 배 더 효율적이며 대규모 모델에서 guided upsampling을 허용하는 Joint Bilateral Upsampling의 고속 CUDA 구현
- FeatUp feature가 dense prediction 작업 및 모델 설명력 향상을 위해 일반 feature의 drop-in replacement로 사용될 수 있음을 보여줌
3. METHOD
- FeatUp의 핵심 아이디어는 저해상도 feature의 다양한 "뷰"를 관찰함으로써 고해상도 feature를 계산할 수 있다는 것
- NeRF (Mildenhall et al., 2020)의 아이디어에서 고안, NeRF는 2D 사진 여러 장으로 3D 장면의 암시적 표현을 구축, FeatUp은 다양한 저해상도 feature map에 걸쳐 일관성을 강제하여 up-sampler 구축
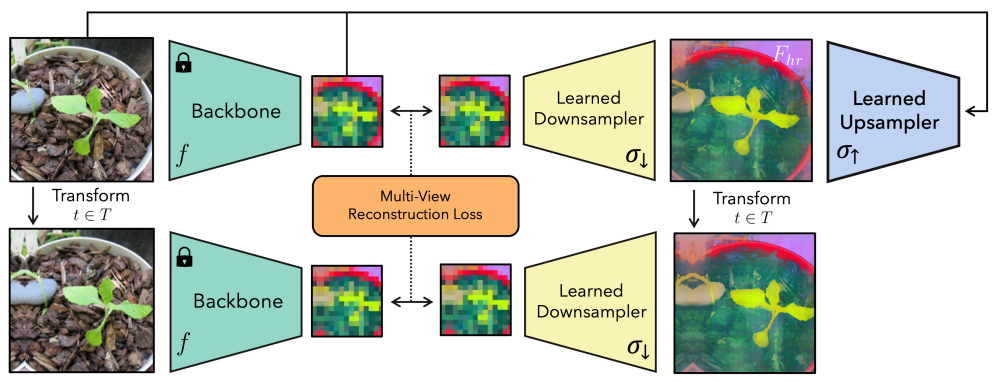
- 위 그림은 FeatUp training의 구조
- 먼저 단일 고해상도 출력으로 정제할 저해상도 feature 뷰를 생성
- 이를 위해 입력 이미지에 small pads, scales, horizontal flip 적용
- 이러한 작은 이미지 jitter를 통해 출력 feature의 미세한 차이를 관찰하고 업샘플러 학습을 위한 sub-feature 정보를 제공
- 다음으로 이 뷰들로부터 일관된 고해상도 feature map을 구성
- Downsampling 시 저해상도 jitter feature를 재현하는 잠재 고해상도 feature map을 학습할 수 있다고 가정
- NeRF와 달리 각 뷰를 생성하는 매개변수를 추정할 필요는 없음
- 대신 각 이미지를 "jitter"하는 데 사용된 매개변수를 추적하고, 동일한 변환을 학습한 고해상도 feature에 downsampling 전에 적용
- 그런 다음 gaussian likelihood loss를 사용하여 downsampling된 feature와 실제 모델 출력을 비교
- 좋은 고해상도 feature map은 다양한 뷰에 걸쳐 관측된 feature를 재구성할 수 있어야 함
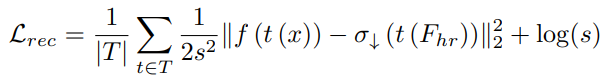
- 위 수식에서 t ∈ T는 pad, zoom, crop, h-flip과 같은 transform
- x는 입력 이미지, f는 backbone, σ↓는 학습된 downsampler, σ↑는 학습된 upsampler
- 이 때, Fhr = σ↑(f(x), x)를 평가하여 예측된 고해상도 feature인 Fhr을 생성할 수 있음
- ∥·∥은 표준 제곱 l2 norm
- s = N (f (t(x))) 는 소규모 linear network N에 의해 매개변수화된 공간적으로 변화하는 adaptive uncertainty 임
- s를 통해 MSE loss의 불확실성을 처리할 수 있는 적절한 likelihood로 변환
- 이 추가적인 flexibility를 통해 네트워크가 특정 outlier feature들이 근본적으로 업샘플링될 수 없다는 것을 학습할 수 있음
3.1 CHOOSING A DOWNSAMPLER
- 학습된 downsampler인 σ↓를 선택하는 두 가지 옵션이 있음
- 빠르고 간단한 학습된 blur kernel
- 더 유연한 attention 기반 downsampler

- 위 그림은 두 방법을 나타내는데, 모두 feature의 "space" 또는 "semantics"를 변경하지 않고 오직 small neighborhood 내에서만 feature를 interpolation
- Blur 기반 downsampler는 효율적이지만, dynamic receptive fields, object salience 또는 기타 nonlinear effects를 포착할 수 없음
- Attention 기반 downsampler는 공간적으로 적응되는 downsampling 커널을 사용하는 더 유연한 attention downsampler를 도입
- 간단히 말해, 1x1 컨볼루션을 사용하여 고해상도 feature에서 saliency map을 예측
3.2 CHOOSING AN UPSAMPLER
- 핵심은 σ↑의 매개변수화

- 위 그림처럼 두 가지 변형이 있음
- JBU (Joint Bilateral Upsampler) -> 이미지 집합에 걸쳐 일반화되는 upsampling 전략을 학습
- Implicit -> implicit 네트워크로 매개변수화하며, 단일 이미지에 과적합되면 매우 선명한 feature를 생성할 수 있음
Joint Bilateral Upsampler
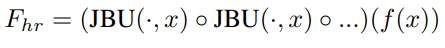
- ◦ 는 function composition
- JBU는 저해상도 feature map Flr을 고해상도 신호 G를 guidance로 사용하여 upsampling
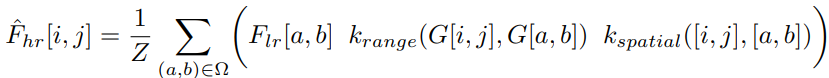
- 위 수식은 joint bilateral upsampling을 나타낸 것
- Fˆ hr[i, j]는 최종 고해상도 feature map의 (i, j) 좌표에 대한 값
- Ω는 (i, j) 좌표의 주변 픽셀 영역(예: 3x3 정사각형)
- (a, b)는 Ω 내부의 각 픽셀 좌표
- Flr[a, b]는 저해상도 feature map의 (a, b) 좌표 값
- krange(G[i, j], G[a, b])는 고해상도 가이드 신호 G의 (i, j)와 (a, b) 좌표 간 유사도를 나타내는 범위 커널
- kspatial([i, j], [a, b])는 (i, j)와 (a, b) 좌표 간 거리에 기반한 공간 커널
- 이 모든 값을 더하고 정규화 상수 Z로 나누어 최종 Fˆ hr[i, j]를 계산
- 즉, 저해상도 feature와 고해상도 가이드 신호간의 feature를 결합하여 고해상도 feature를 생성하는 과정
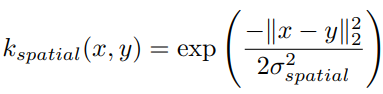
- 위 수식은 kspatial은 공간적인 근접성을 반영하여 저해상도 feature와 고해상도 가이드 신호 간의 관계를 모델링
- kspatial은 좌표 벡터 간 유클리드 거리에 기반한 학습 가능한 가우시안 커널
- σ_spatial은 가우시안 커널의 폭 parameter
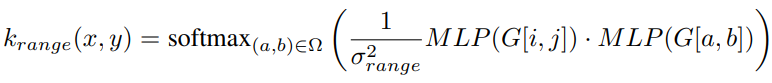
- 위 수식은 krange는 고해상도 가이드 정보를 활용하여 범위 정보를 모델링하는 역할
- (a,b) 는 주변 픽셀 영역 Ω 내의 좌표
- MLP는 다층 퍼셉트론 네트워크로, G[i,j]와 G[a,b]를 입력받아 feature를 추출
- 이 MLP 출력 벡터간 내적을 계산하고, 이를 온도 σ_range^2로 나누어 소프트맥스 함수를 적용
Implicit
- 이 방법은 NeRF와 유사한 아이디어를 사용하여 단일 이미지의 고해상도 feature를 implicit 함수 Fhr = MLP(z)로 매개변수화
- DIP(Ulyanov et al., 2020)와 LIIF(Chen et al., 2021) 등의 기존 upsampling 솔루션도 이와 같은 추론 시간 학습 접근법을 사용
- 입력 이미지의 좌표와 픽셀 강도를 이용하여 작은 MLP를 통해 고차원 feature를 생성
- 공간 해상도 향상을 위해 Fourier feature를 사용하며, 색상 정보를 포함하는 Fourier color feature을 추가로 사용
- Fourier color feature를 사용하면 수렴 속도가 빨라지고 CRF 등의 추가 기술 없이도 고해상도 이미지 정보를 효과적으로 활용할 수 있음
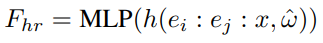
- 위 수식에서
- ei, ej는 [-1, 1] 범위의 2차원 픽셀 좌표 필드
- x는 입력 이미지
- ω̂는 discrete Fourier transform에 사용되는 주파수 벡터
- h(·)는 입력 신호에 대한 성분별 discrete Fourier transform
- : 는 채널 차원으로의 연결 연산
- 이렇게 계산된 입력 (ei, ej, x)에 대한 Fourier feature가 MLP의 입력으로 들어가며, MLP는 이를 통해 최종 고해상도 feature map Fhr을 출력
4. EXPERIMENTS
4.1. QUALITATIVE COMPARISONS
Visualizing upsampling methods

- 위 그림에서는 FeatUp 모델이 다양한 baseline 모델들에 비해 큰 성능 향상을 보여주고 있음
- 저해상도 ViT feature에 대해 3차원 PCA 분석을 수행하고, 이를 통해 업샘플링된 feature를 RGB 공간에 매핑하여 시각화
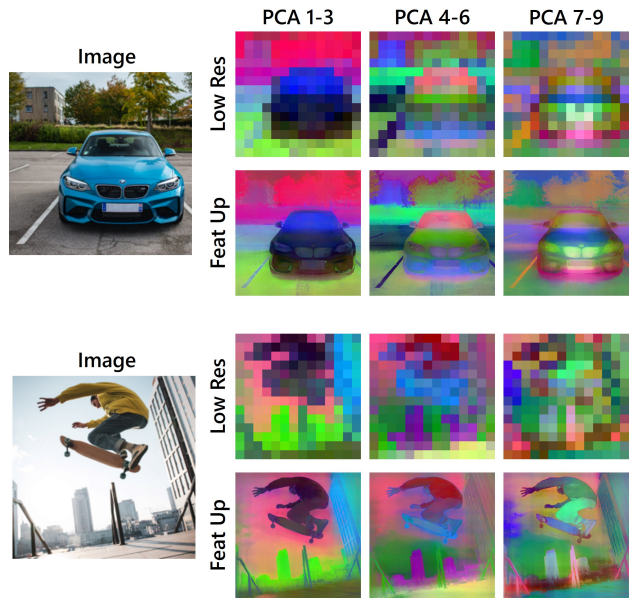
- 보충 자료인 위 그림에서는 이러한 고품질 업샘플링 성능이 higher PCA 성분에서도 유지됨을 보여줌

- 또한 위 그림에서는 FeatUp이 작은 객체 검색 성능 향상에도 도움이 된다는 것을 보여줌
- 위 실험 결과들을 통해 FeatUp 모델의 탁월한 업샘플링 성능을 정성적으로 입증
Robustness across vision backbones

- 위 그림에서는 FeatUp 모델이 다양한 최신 비전 backbone들에 적용될 수 있음을 보여줌
- ResNet-50과 같이 큰 receptive field로 인해 객체 위치를 정확히 파악하지 못하는 backbone에서도, FeatUp은 합리적으로 feature를 올바른 객체에 연관시킬 수 있음
- 이를 통해 FeatUp이 다양한 vision 모델 backbone에 적용 가능하며, feature 업샘플링 측면에서 효과적이라는 점을 보여줌
4.2. TRANSFER LEARNING FOR SEMANTIC SEGMENTATION AND DEPTH ESTIMATION

- 두 가지 FeatUp 변형 모두가 모든 실험에서 모든 baseline을 능가했으며, 이를 통해 FeatUp이 기존 feature를 효과적으로 대체할 수 있음을 보여줌

- 정성적으로도 위 그림에서 볼 수 있듯이, FeatUp은 두 작업 모두에서 더 깨끗하고 일관된 예측 결과를 보여줌
4.3. CLASS ACTIVATION MAP QUALITY
- 기존 Class Activation Map (CAM) 해석 방법은 깊은 feature map의 저해상도로 인해 한계가 있어 작은 객체를 해결하지 못함
- FeatUp feature를 기존 CAM 분석에 적용하면 보다 강력하고 정확한 설명을 얻을 수 있음
- 요약하자면, FeatUp이 모델 설명력 향상에 도움을 줄 수 있음
5. CONCLUSION
- FeatUp은 multiview consistency을 활용하여 심층 feature를 업샘플링하는 새로운 접근법
- 심층 모델은 고품질 feature을 학습하지만 공간 해상도가 매우 낮다는 문제를 해결
- JBU 기반 업샘플러는 강력한 공간 사전 지식을 활용하여 Joint Bilateral Upsampling의 새로운 일반화를 통해 신속한 feedfoward network로 손실된 공간 정보를 정확히 복원
- Implicit FeatUp은 임의의 해상도에서 고품질 feature를 학습할 수 있음
- 두 가지 변형 모두 linear probe transfer learning, 모델 해석성, end-to-end 의미 분할 등 다양한 측면에서 광범위한 baseline을 크게 능가
- 즉, FeatUp은 심층 모델의 feature 업샘플링 문제를 효과적으로 해결하는 혁신적인 접근법이라고 요약할 수 있음

AI Research Engineer