https://arxiv.org/abs/2403.19588
Introduction
- "ImageNet moment"는 ConvNet의 등장, 특히 AlexNet으로 시작
- 이후 VGG와 GoogLeNet은 ConvNet에서 다층 구조의 장점을 드러냄
- 동시에 등장한 ResNet은 additive skip connections 라는 혁신적 개념을 도입
- 이를 통해 기울기 소실 문제를 해결하고 깊은 신경망 구축이 가능해짐
- ResNet의 개념은 EfficientNet, ConvNeXt 등 후속 모델의 발전을 이끌었고, Transformer, ViT 등 다음 세대 모델의 등장에도 큰 영향을 미침
- 한편 DenseNet은 concatenation을 통한 shortcut 연결을 제안했는데, 이는 feature reuse와 더 compact한 모델 설계를 가능하게 함
- 하지만 DenseNet은 훈련 방식과 설계상의 한계로 인해 ResNet에 비해 주목받지 못함
- 본 논문에서는 DenseNet의 잠재력을 재조명하고, 보다 개선된 DenseNet 모델을 제시
3. Methodology: Revitalizing DenseNets
3.1. Preliminary
- ResNet과 DenseNet의 특징과 장단점을 비교
- ResNet은 Xl+1 = Xl + f(XlW)라는 간단한 수식을 가지고 있으며, 여기서 additive shortcut(+)이 핵심적인 역할을 함
- 반면 DenseNet은 Xl+1 = [Xl, f(XlW)]로, concatenation을 통한 dense connection을 사용. 이는 파라미터 효율성이 높지만, 특징 차원 증가로 인한 메모리 문제가 발생
- DenseNet은 초기에 ResNet을 능가했지만, 적용성의 한계로 인해 대세로 자리잡지 못함. 특히 width의 확장이 어려운 문제가 있음
- 본 논문에서는 concatenation의 강점과 전략적 설계를 통해 DenseNet의 한계를 극복할 수 있다고 판단
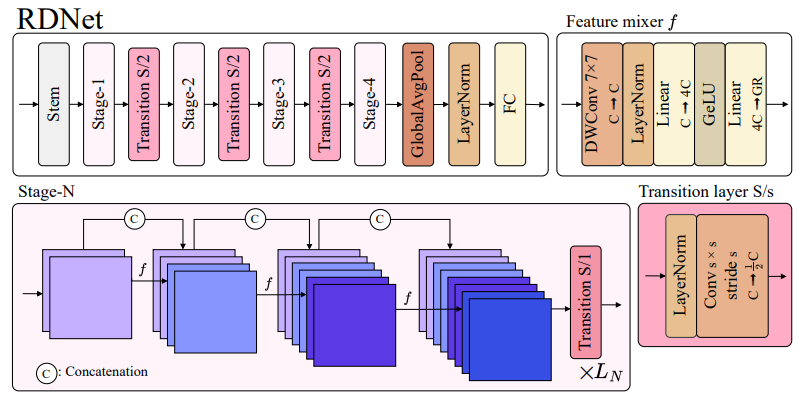
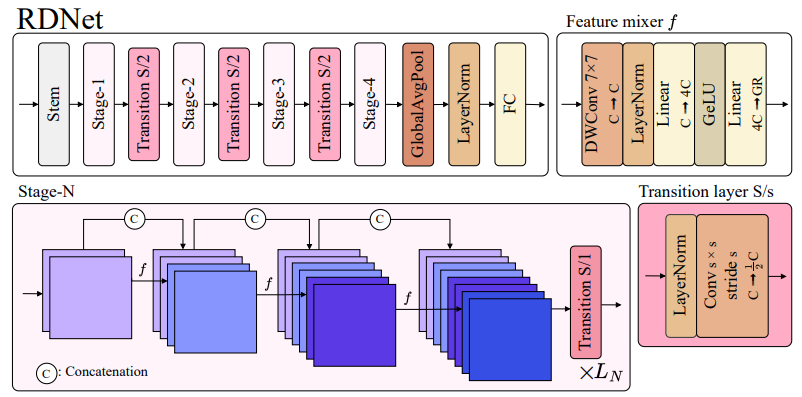
3.2. Revitalizing DenseNets
Baseline
- ResNet 모델에 대한 최근 연구들은 훈련 방식의 개선이 큰 성능 향상을 가져옴
- 이에 저자들도 DenseNet-201을 현대적인 훈련 방식으로 fine-tuning하여 baseline 모델로 사용
- Label Smoothing, RandAugment, Random Erasing, Mixup, Cutmix, Stochastic Depth
- AdamW
- Cosine LR 스케줄링 및 linear warmup
- 300 epoch의 large epoch training
Going wider and shallower
- 기존 DenseNet 모델은 매우 깊은 아키텍처(예: DenseNet-265)를 제안했지만, 자원 제약 하에서 depth와 width를 동시에 늘리기는 어려웠음
- 선행 연구들에 따르면, 효율성 향상을 위해 더 얕은 네트워크를 설계하는 것이 중요 -> 이를 적용
- 구체적으로는
- Growth Rate(GR)을 32에서 120으로 크게 늘림
- Block 수를 (6, 12, 48, 32)에서 (3, 3, 12, 3)으로 줄임

- 위 Table 1의 (b) 처럼, 이를 통해 추론 속도와 메모리 사용량이 각각 35%, 18% 감소
Improved feature mixers
- ConvNeXt 모델의 기본 블록 구조를 사용 -> DenseNet의 특성을 고려하여 기존 블록 설계를 수정
- DenseNet은 additive shortcuts을 사용하지 않았고, 기존 블록 설계는 차원을 점진적으로 줄이는 것을 목표로 했기 때문에, 이를 DenseNet에 그대로 적용하기에는 적절하지 않을 수 있음
- 따라서 다음과 같이 블록을 재설계
- Layer Normalization 사용
- Post-activation 구조
- Depthwise convolution 활용
- 정규화와 activation 함수 사용 감소
- 커널 크기 7 적용
- Table 1의 (c) 처럼, 이러한 설계 변경을 통해 정확도가 0.9%p 이상 향상되었고, 계산량도 약간 증가
Larger intermediate channel dimensions
- 저자들은 DenseNet 모델의 블록 내 확장 비율(Expansion Ratio, ER) 설계를 재고하여 feature 표현력과 효율성 간 균형을 잡고자 함
- 선행 연구들에서는 ER을 큰 값으로 설정하여(예: ER=6) 블록 내 중간 feature의 차원을 입력 차원보다 크게 만들었고, 이를 통해 성능 향상을 달성
- DenseNet도 이 ER 개념을 도입했지만, GR(Growth Rate)에 비례하여 적용. 이는 입력과 출력 차원을 줄이는 것이 목적
- 하지만 저자들은 이 방식이 비선형 변환을 통한 feature 표현력 향상을 제한한다고 판단
- 따라서 저자들은 ER을 입력 차원에 비례하도록 재설계. 이로 인해 계산량이 증가하여, GR을 절반으로 줄임
- 이러한 변경을 통해 21% 빨라진 훈련 속도와 0.4%p 향상된 정확도를 달성 (Table 1 참고)
- 추가 실험을 통해 GR을 4로 설정하는 것이 가장 좋은 성능을 보인다는 것을 확인
More transition layers
- Transition layer 설계와 단계별 GR 설정을 개선함으로써 DenseNet의 효율성과 성능을 향상시킴
- DenseNet에서 Transition layer는 채널 수를 줄이는 것이 목적이었지만, 매 블록마다 dense connection으로 인해 feature가 축적되면서 높은 GR을 사용하기 어려웠음
- 이에 저자들은 Transition layer을 각 stage가 아닌, 3개의 블록마다 1 stride로 삽입하는 방식을 제안. 이는 차원 축소만을 담당
Patchification stem
- 최근 연구에 따르면, 이미지를 패치 단위로 입력으로 사용하는 것이 효과적
- 저자들은 패치 크기 4, stride 4의 패치 분할 방식을 사용했으며, 이후 Layer Normalization을 적용
- 이러한 패치화 기법을 적용하면 계산 속도가 크게 향상되면서도 정확도 손실은 없었음 -> Table 1 (f)
Refined transition layers
- Transition layer의 역할과 구조를 개선함으로써 DenseNet의 성능과 효율성을 균형있게 향상시킴
- DenseNet의 전이층은 차원 감소와 다운샘플링 역할을 수행. 추가로 평균 풀링을 사용
- 이를 개선하여, average pooling을 제거하고 컨볼루션의 커널 사이즈와 stride를 조정. 또한 Batch Norm 대신 Layer Norm을 사용
- 따라서 Transition layer은 1) 차원 감소, 2) 다운샘플링의 두 가지 역할을 하게 됨
Channel re-scaling
- DenseNet의 feature concatenation 과정에서 channel 간 다양성을 고려하기 위해 channel 재조정 메커니즘을 도입했고, 이를 통해 소폭의 성능 향상을 얻을 수 있었음 -> Table 1 (h)
3.3. Revitialized DenseNet (RDNet)
- 이러한 사항들을 적용한 "Revitalized DenseNet(RDNet)"을 아래의 Scale에 따라 제안
- RDNet-T: GR=(64, 104, 128, 224), B=(3, 3, 12, 3)
- RDNet-S: GR=(64, 128, 128, 240), B=(3, 3, 21, 6)
- RDNet-B: GR=(96, 128, 168, 336), B=(3, 3, 21, 6)
- RDNet-L: GR=(128, 192, 256, 360), B=(3, 3, 24, 6)
4. Experiment
4.1. Image Classification
- RDNet 모델들은 Swin Transformer, ConvNeXt와 동일한 훈련 설정을 사용하여 공정한 비교가 가능하도록 설계
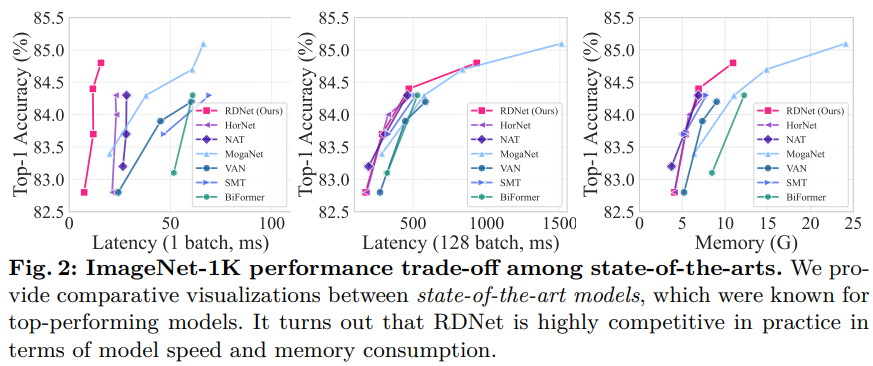
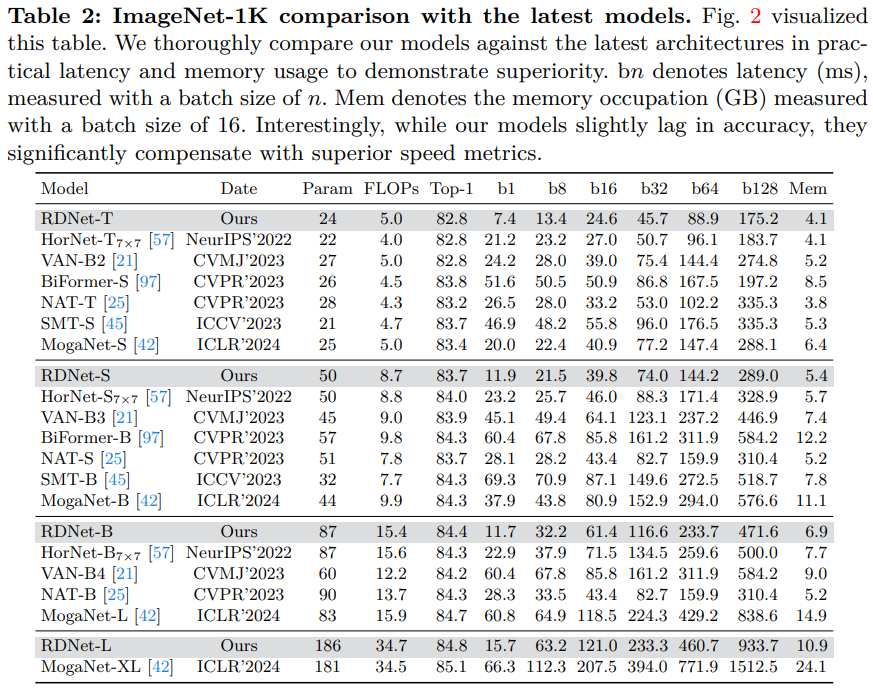
- 기존 최고 성능 모델들과 비교했을 때, RDNet이 우수한 결과를 나타냄 -> Fig. 2와 Table 2에서 확인
- RDNet은 정확도 측면에서는 약간 뒤쳐지지만, 속도 지표에서 크게 앞섬. 예를 들어 RDNet-S는 SMT-S, MogaNet-S와 견줄 만한 성능을 보임
- 또한 RDNet은 메모리 사용량도 적어 효율성이 높음

- Table 4에서 다른 인기 모델들과 비교한 결과, RDNet은 더 높은 정확도와 메모리 효율, 빠른 속도를 달성
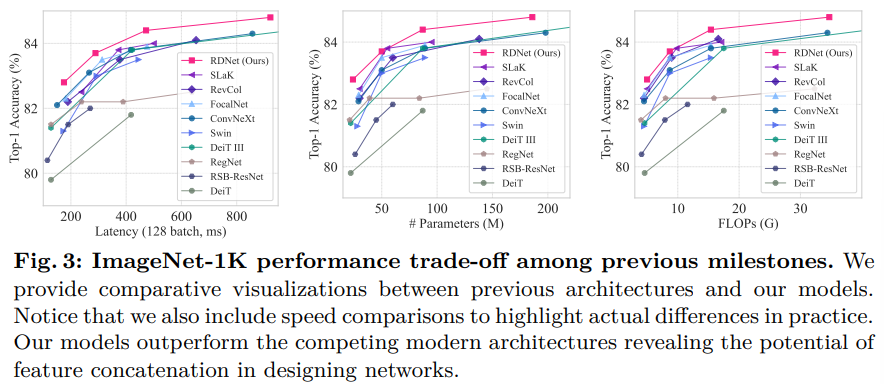
- Fig. 3에서는 RDNet이 주요 모델들과 견줘도 경쟁력 있는 성능을 보임
4.2. Zero-shot Image Classification
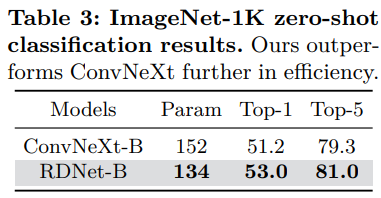
- CLIP 모델을 사용하여 RDNet의 제로샷 성능을 검증
4.3. Semantic Segmentation
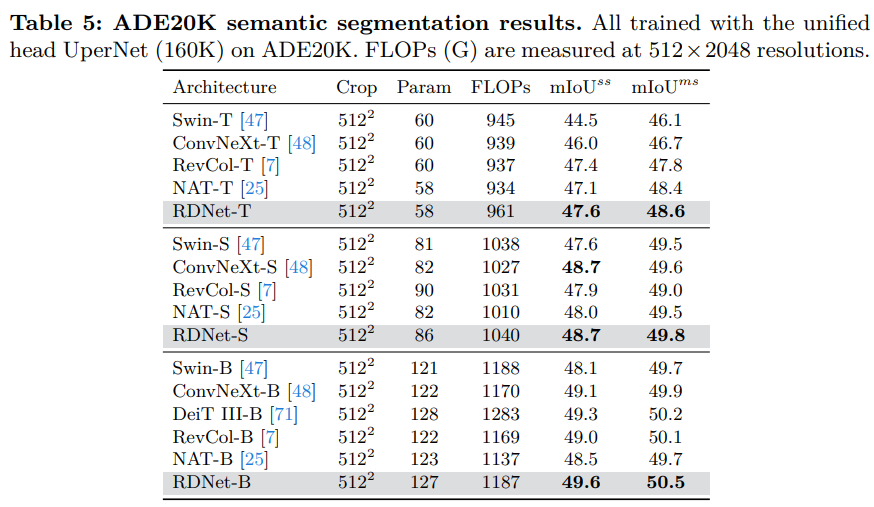
- RDNet이 ImageNet뿐만 아니라 semantic segmentation 등 다른 작업에서도 우수한 성능을 발휘한다는 것을 입증
5. Discussions
- 본 논문은 residual connection보다 dense connection의 효과성을 입증하고자 함. 주요 내용은 다음과 같음:
- 다양한 규모의 네트워크, 기본 블록 유형, 구조 요소, 훈련 설정에서 수많은 랜덤 네트워크를 학습
- 파라미터 수, FLOPs, 활성화 등 비용 제약 하에서 실험을 진행
- PreNorm, PostNorm, PostNorm(w/o act) 등 3가지 다른 기본 블록 유형을 사용
- 실험 결과, 모든 구성에서 concatenation 기반 아키텍처가 additive shortcuts보다 우수한 성능을 보임
- 이를 통해 저자들은 dense connection의 효과성을 입증하고자 함
- 즉, 이 논문은 residual connection 대신 dense connection을 사용하는 것이 더 효과적임을 실험적으로 검증하고자 한 것이 핵심
6. Conclusion
- 저자들은 ResNet, ConvNeXt, ViT 등 덧셈 기반의 shortcuts을 사용하는 모델들이 지배적인 시대에서 DenseNet의 과거 성공을 재조명
- 파일럿 연구를 통해 DenseNet의 concatenation shortcuts이 ResNet 스타일의 additive shortcuts 보다 표현력이 뛰어나다는 점을 새롭게 발견
- 하지만 DenseNet은 낡은 훈련 방식과 전통적인 매크로 블록 설계로 인해 현대 아키텍처에 밀린 것으로 판단
- 저자들은 DenseNet을 현대적인 요소로 확장하여 DenseNet의 근본 원리가 강력한 모델링 성능을 달성할 수 있음을 증명
- 제안한 모델은 최신 현대 아키텍처에 필적하는 강력한 성능을 보였으며, concatenated 특징의 활용이 additive shortcuts 모델보다 dense prediction task에서 우수한 결과를 보여줌
- 이를 통해 저자들은 네트워크 설계에서 concatenation의 장점을 부각하고, DenseNet 스타일 아키텍처에 대한 관심을 촉구
- 한계점으로는 자원 제약으로 인해 더 큰 규모의 모델까지 확장하지 못함

AI Research Engineer
상세한 리뷰 감사합니다 ㅎㅎ