https://arxiv.org/abs/2404.10518
1. Introduction
Efficient on-device neural networks
- 빠르고 실시간 및 상호작용 경험을 가능하게 하고, 공용 인터넷을 통해 개인 데이터를 스트리밍하지 않아도 됨
- 그러나 mobile device의 computational constraints는 정확도와 효율성의 균형을 맞추는 데 큰 어려움이 있음
UIB and Mobile MQA
- NAS를 통해 통합된 두 가지 빌딩 블록으로, 주로 Pareto-optimal mobile 모델을 생성
- 추가로, 정확도를 향상시키는 distillation 기술을 도입
Universal Inverted Bottleneck (UIB)
- 두 개의 optional depthwise convolutions를 통합하여 Inverted Bottleneck 블록을 개선
- UIB는 spatial 및 channel mixing에서의 유연성, receptive field expansion의 옵션, 계산 효율성을 제공함
Mobile MQA block
- Multi-Head Attention 대비 39% 이상의 추론 속도 향상을 달성
Two-phase NAS approach
- Search efficiency를 크게 향상시키고, 이전 state-of-the-art 모델보다 훨씬 더 큰 모델을 생성
- Offline distillation dataset을 통합하여 NAS reward 측정의 noise를 줄여 모델 품질을 향상
MNv4 model series
- UIB, MQA, improved NAS recipe를 통합하여 다양한 hardware 플랫폼(CPUs, DSPs, GPUs, specialized accelerators)에서 대부분 Pareto optimal 성능을 달성
- MNv4-Conv-S 디자인에서 MNv4-Hybrid-L 고급 variation까지 포함하며, Pixel 8 EdgeTPU에서 3.8ms의 시간으로 작동하고, ImageNet-1K에서 87%의 top-1 정확도를 달성
2. Related Work
Mobile Convolutional Networks
MobileNetV1, MobileNetV2, MnasNet, MobileOne
- 이들은 depthwise-separable convolutions, linear bottlenecks, inverted residuals 등을 사용하여 효율성을 높임
Efficient Hybrid Networks
- CNN과 ViT의 강점을 결합한 MobileViT
- MobileNet과 Transformer를 결합한 MobileFormer
- Self-attention을 초기 단계에서 대신하는 large convolutional kernels을 사용하는 FastViT
Efficient Attention
- MHSA의 효율성을 향상시키는 연구
- EfficientViT, MobileViTv2, EfficientFormerV2, CMT, NextViT 등이 있으며, Q, K, V의 downsampling을 통해 효율성을 높임
Hardware-aware Neural Architecture Search (NAS)
- NetAdapt, MnasNet, FBNet, MobileNetV3, MobileNet MultiHardware 등의 연구가 있으며, target latency constraint, reinforcement learning, multi-task NAS 등을 사용하여 hardware 효율성을 최적화
3. Hardware-Independent Pareto Efficiency
Roofline Model
- 주어진 작업의 성능을 예측하고, 메모리 병목인지 계산 병목인지 예측
- 이는 hardware의 특정 세부 사항을 추상화하고 작업의 operational intensity와 hardware의 이론적 한계를 비교
- 모델 추론 latency (ModelTime)을 계산하기 위해 다음 수식을 사용
- 모델 추론 latency (ModelTime)을 계산하기 위해 다음 수식을 사용
Ridge Point (RP)
- Hardware의 PeakMACs와 PeakMemBW의 비율을 의미
- 최대 성능을 달성하기 위해 필요한 최소한의 operational intensity를 나타냄
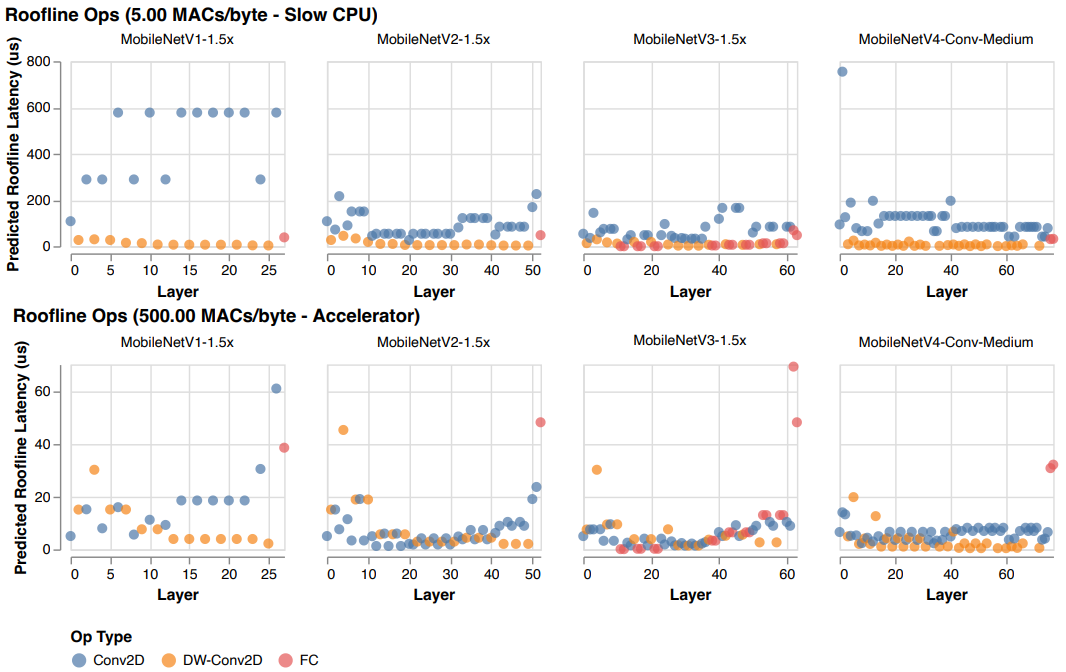
Ridge Point Sweep Analysis
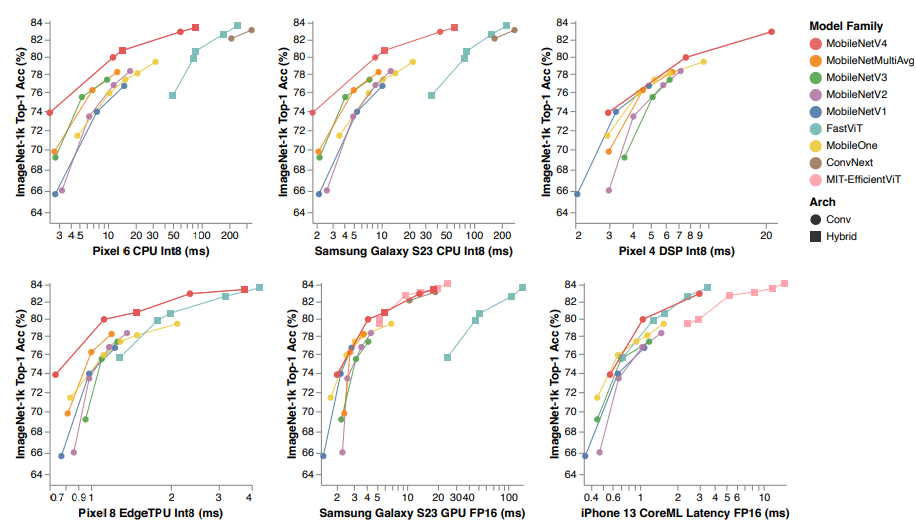
- MobileNetV4 모델이 다른 MobileNet들과 비교하여 hardware 독립적인 Pareto-optimal 성능을 달성하는 방법을 설명
- 낮은 RP hardware에서는 계산 병목 현상이 더 빈번하게 발생하므로 MACs 수를 최소화해야 latency를 줄일 수 있음
- 높은 RP hardware에서는 데이터 이동이 병목 현상이므로 MACs 수가 모델을 느리게 하지 않지만 모델 용량을 증가시킬 수 있음
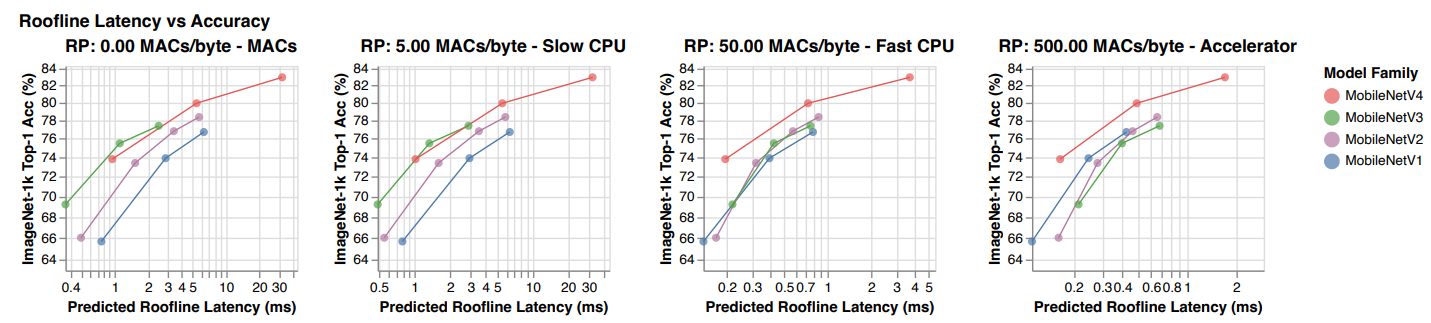
- 위 그림은 메모리 대역폭과 연산량 간의 관계를 의미
- MobileNetV4 모델이 Ridge Point 0에서 500 MACs/byte의 범위 내에서 Pareto-optimal 성능을 달성하는 모습을 보여줌
- 위 그림은 알고리즘의 latency를 다양한 Ridge Point 값에서 분석한 결과
- 이는 MobileNetV4 모델이 다양한 병목 현상을 가진 hardware에서 최적의 성능을 발휘할 수 있도록 도움
MobileNetV4 Design
- MobileNetV4는 MACs와 메모리 대역폭을 최적의 비용으로 최대한 활용할 수 있는 곳에 집중
- 네트워크의 시작과 끝에 주로 집중
- 시작 부분에서 대형 초기 layer를 사용하여 모델의 용량과 정확도를 크게 향상시킴. 이 layer는 낮은 RP hardware에서만 expensive
- 네트워크 끝 부분에서는 모든 MobileNetV4 variation이 동일한 크기의 최종 FC layer를 사용하여 정확도를 최대화함. 이는 낮은 RP hardware에서는 expensive
- 결과적으로, MNv4 모델은 정확도를 적절히 향상시키는 expensive layer를 사용할 수 있으며, 동시에 모든 ridge points에서 주로 Pareto-optimal 성능을 유지
4. Universal Inverted Bottlenecks
Universal Inverted Bottleneck (UIB)
- 효율적인 네트워크 설계를 위한 적응 가능한 빌딩 블록으로, search 복잡성을 증가시키지 않고 다양한 최적화 대상에 맞출 수 있는 유연성을 가짐
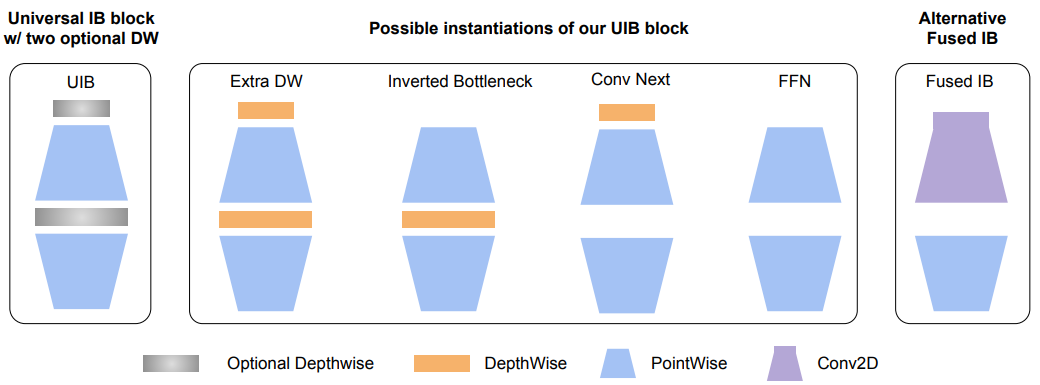
- 아래와 같은 MobileNet의 성공적인 요소들을 기반으로 UIB 블록을 설계
- Depthwise convolution (DW)
- Pointwise (PW) expansion
- Projection inverted bottleneck
- 이 블록은 두 개의 optional DW를 도입하여 expansion layer 전과 expansion 및 projection layer 사이에 위치시킴
- UIB는 기존의 여러 중요한 블록들을 통합하여 ConvNext 블록 및 ViT의 FFN 블록과 같은 새로운 variation을 설계
UIB Instantiations
-
Inverted Bottleneck (IB)
- Expanded feature activation에서 spatial mixing을 수행하여 모델 용량을 증가시킴
-
ConvNext
- Expansion 전 더 큰 커널 크기로 spatial mixing을 수행하여 더 저렴한 spatial mixing을 가능하게 함
-
ExtraDW
- Network depth와 receptive field를 크게 증가시키는 새로운 variation을 도입하여 ConvNext와 IB의 결합된 이점을 제공
-
FFN
- 두 개의 1x1 pointwise convolution (PW)와 그 사이의 activation 및 normalization 레이어로 구성
- 다른 블록들과 함께 사용될 때 가장 잘 작동
-
각 네트워크 단계에서 UIB는 유연성을 제공
- Channel mixing 균형을 맞춤
- 필요한 경우 receptive field를 expansion함
- 계산 활용도를 최대화함
5. Mobile MQA
Mobile MQA
- Edge TPU 및 Samsung S23 GPU에서 39% 이상의 추론 속도 향상을 제공하는 새로운 attention block
Importance of Operational Intensity
- 최근 비전 모델 연구는 효율성을 높이기 위해 MACs를 줄이는 데 중점을 둠
- 그러나 실제 병목은 계산이 아닌 메모리 접근임
- 따라서 MACs를 최소화하는 것만으로는 성능을 높일 수 없음
- 대신, 연산 강도 (산술 연산과 메모리 접근의 비율)를 고려해야 함
MQA는 Hybrid model에서 효율적
- MHSA는 정보의 다른 측면을 포착하기 위해 queries, keys, values를 여러 search에 projection
- MQA는 모든 heads에서 shared keys와 values를 사용하여 이를 단순화함
- 이렇게 하면 메모리 접근 요구가 크게 줄어들고, 연산 강도가 크게 향상
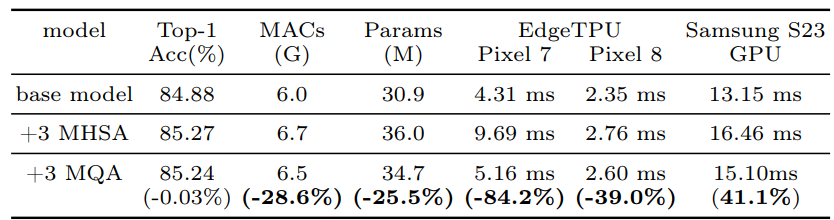
- 위 테이블에서, MQA가 MHSA에 비해 달성한 가속도와 품질 손실을 수치적으로 비교
- MQA를 사용하여 MHSA 대비 상당한 성능 향상을 이루었음
- MQA를 mobile 비전 모델에 최초로 적용하여 성능을 크게 향상시킴
Asymmetric Spatial Down-sampling
-
MQA에서 영감을 받아, keys와 values의 해상도를 축소하되, 고해상도 queries를 유지하는 Spatial Reduction Attention (SRA)을 통합
-
이는 입력과 출력 사이의 동일한 토큰 수를 유지하여 attention의 고해상도를 유지하면서 효율성을 크게 향상
- Mobile MQA block 수식여기서 SR은 spatial reduction, stride가 2인 DW 또는 spatial reduction이 사용되지 않을 경우 identity function을 나타냄
- Mobile MQA block 수식
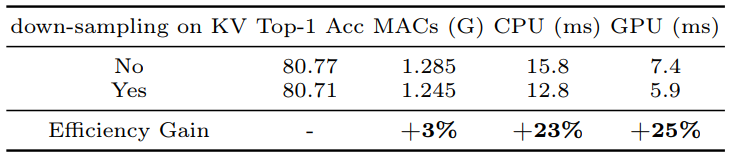
- Asymmetric Spatial Down-sampling을 통해 달성된 효율성 향상과 정확도 손실을 위 테이블에서 수치적으로 비교
- 이러한 결과는 Asymmetric Spatial Down-sampling이 모델의 효율성을 크게 향상시키면서도 정확도에 거의 영향을 미치지 않음을 입증
- 이는 MNv4 모델이 다양한 hardware 플랫폼에서 우수한 성능을 발휘하는 데 기여
6. Design of MNv4 Models
Design of MNv4 Models
- 최신 MobileNets를 개발할 때 주요 목표는 다양한 mobile 플랫폼에서 Pareto optimality를 달성하는 것
- 이를 위해 기존 모델과 hardware에 대한 광범위한 상관 분석을 통해 비용 모델(latency 예측)과의 높은 상관관계를 보장하는 구성 요소와 매개 변수를 발견
Multi-path efficiency concerns
- Group convolutions 및 multi-path 설계는 낮은 FLOPs에도 불구하고 메모리 접근 복잡성으로 인해 덜 효율적일 수 있음
Hardware support matters
- Squeeze and Excite (SE)와 같은 고급 모듈은 DSP에서 잘 지원되지 않음. SE는 accelerator에서 느림
The Power of Simplicity
- Depthwise와 pointwise convolutions, ReLU, BatchNorm, 간단한 attention (예: MHSA)은 뛰어난 효율성과 hardware 호환성을 보여줌
Enhanced Search Strategy
-
UIB 블록을 효과적으로 구현하기 위해 TuNAS를 사용하여 성능을 향상
-
Coarse-Grained Search
- 최적의 필터 크기를 결정하고 고정 매개 변수를 유지
- 기본 expansion factor가 4인 inverted bottleneck 블록과 3x3 depthwise 커널을 사용
-
Fine-Grained Search
- Initial search 결과를 바탕으로 UIB의 두 개의 depthwise 레이어(포함 여부 및 커널 크기 3x3 또는 5x5)를 search 하며 expansion factor는 4로 유지

-
Two stage search를 통해 향상된 효율성과 모델 품질을 위 테이블에서 수치적으로 비교
-
이러한 search 전략을 통해 single stage search 보다 우수한 성능을 발휘함을 입증
-
Enhancing TuNAS with Robust Training
- ImageNet에서의 모델 성능은 data augmentation, normalization, hyperparameter tuning 등에 의해 크게 영향을 받음
- TuNAS [3] 의 진화하는 architecture sampling 때문에 안정적인 hyperparameter set를 찾는 것이 어려움

- JFT distillation dataset을 TuNAS의 training set으로 사용하여 위 테이블에서 보여주는 것처럼 성능 향상을 달성
- Depth-scaled 모델이 width-scaled 모델보다 extended training session에서 더 나은 성능을 발휘
- TuNAS training을 750 epoch으로 expansion하여 더 깊고 높은 품질의 모델을 생성
Optimization of MNv4 Models
- NAS-optimized UIB 블록에서 MNv4-Conv 모델을 구축하여 특정 리소스 제약에 맞춤화
- 주로 hybrid model에서 마지막 단계의 convolution 모델에 attention을 추가하는 것이 가장 효과적
- MNv4-Hybrid 모델에서는 Mobile MQA 블록과 UIB 블록을 결합하여 성능을 향상
7. Results
ImageNet classification
-
ImageNet-1K dataset을 사용하여 모델 아키텍처 성능을 평가
-
다양한 mobile hardware에서 Top-1 accuracy를 측정
-
Experimental Setup
- ARM Cortex CPUs, Qualcomm Hexagon DSP, ARM Mali GPU, Qualcomm Snapdragon, Apple Neural Engine, Google EdgeTPU 등의 hardware에서 테스트
-
Results
- MNv4 모델은 다양한 정확도 목표와 hardware platform에서 대부분 Pareto-optimal 성능을 달성
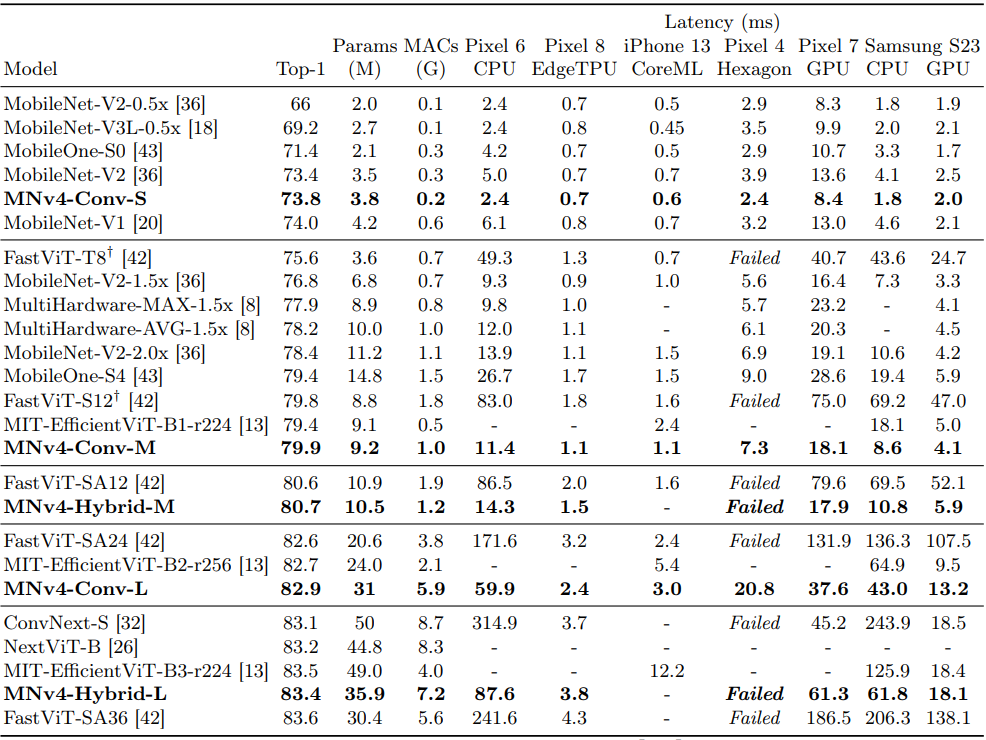
- 특히 CPU에서 MNv4 모델은 MobileNetV3보다 두 배 빠르고, 동일한 정확도 목표에서 다른 모델보다 여러 배 빠름
- EdgeTPUs에서는 MNv4 모델이 동일 정확도 수준에서 MobileNet V3의 두 배 성능을 보여줌
-
COCO Object Detection
-
COCO 17 dataset을 사용하여 MNv4 backbone의 object detection 성능을 평가
-
Experimental Setup
- RetinaNet framework를 사용하여 object detector를 구축하고, FPN과 convolutional layers를 포함
- 600 epoch 동안 모든 모델을 훈련
- 모든 이미지 크기를 384px로 조정하고 다양한 augmentation을 사용
-
Results
- 중간 크기의 convolution-only MNv4-Conv-M detector는 32.6% AP를 달성하며, MobileNet Multi-AVG 및 MobileNet v2와 유사한 성능을 보임
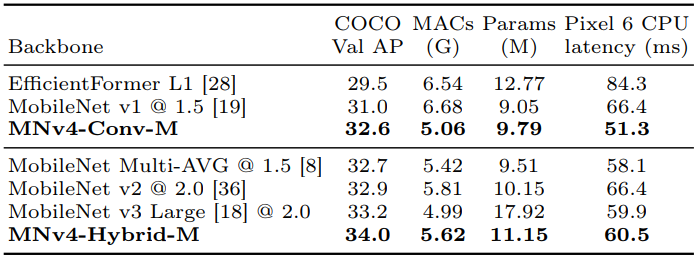
- Pixel 6 CPU latency는 MobileNet Multi-AVG보다 12%, MobileNet v2보다 23% 낮음
- Mobile MQA 블록을 추가하면 AP가 1.6% 증가하여 MNv4의 효율성을 입증
8. Enhanced distillation recipe
Dynamic Dataset Mixing
- 데이터 augmentation은 distillation 성능에 중요
- 고정된 augmentation sequence를 사용하는 기존 방법과 달리, 다양한 augmentation 전략을 사용하여 여러 데이터셋을 dynamic mixing 함으로써 더 나은 distillation 결과를 얻음
- : Inception Crop + RandAugment를 500개의 ImageNet-1k 복제본에 적용
- : Inception Crop + extreme Mixup을 1000개의 ImageNet-1k 복제본에 적용
- : 학습 중 과 를 dynamic mixing
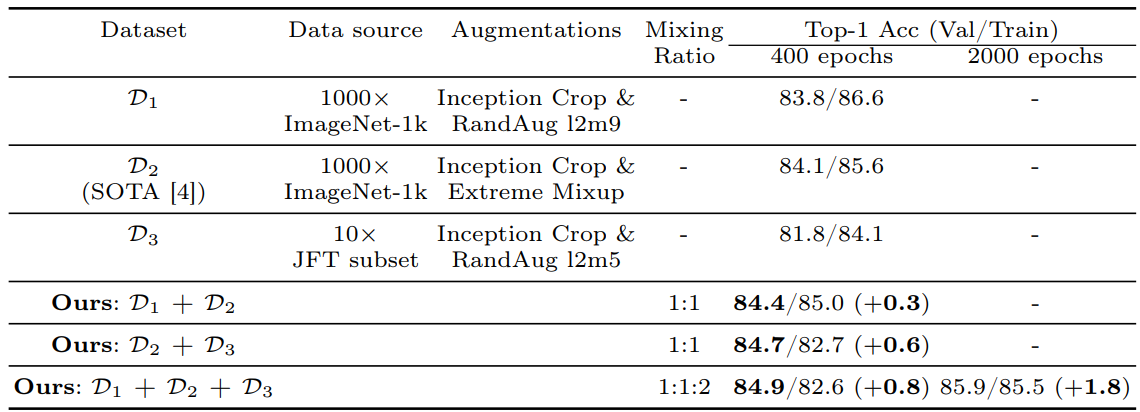
- 위 테이블에서, 가 보다 더 높은 student 정확도(84.1% vs. 83.8%)를 보임
- 그러나, 과 를 dynamic mixing하면 정확도가 84.4%로 상승 (+0.3%)
- 이는 데이터셋 혼합이 augmentation 이미지 공간을 expansion하고, 난이도와 다양성을 증가시켜 student 성능을 향상시킴을 시사
JFT Data Augmentation
- 훈련 데이터 볼륨을 늘리기 위해, JFT-300M 데이터셋을 사용하여 클래스 균형 데이터를 추가함
- Weak augmentation(Inception Crop + RandAugment)을 적용하여 JFT 데이터셋()을 생성
- 만 사용하면 2% 정확도 하락
- 그러나 ImageNet 데이터와 결합하면 0.6% 향상
Our distillation recipe
- , , 를 dynamic mixing 하여 다양한 augmentation과 class balanced JFT 데이터를 활용
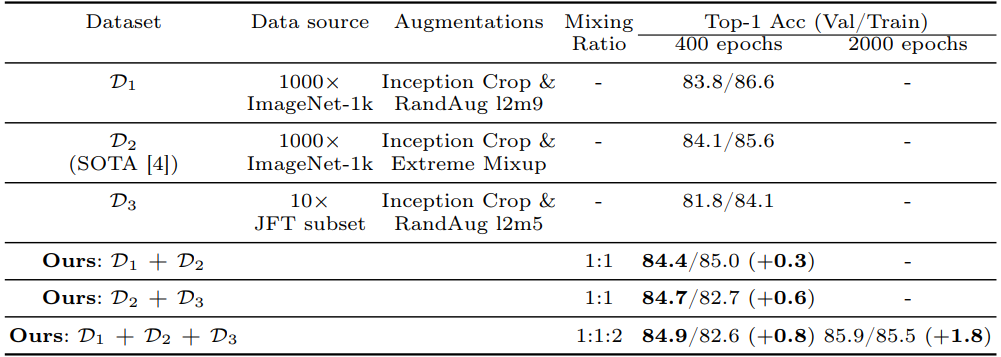
- 위 테이블에 따르면, 이 방법은 이전 SOTA보다 0.8% 이상 top-1 정확도 향상을 달성
- 2,000 epoch 동안 MNv4-Conv-L student 모델을 훈련하여 85.9% top-1 정확도를 달성
- 이는 EfficientNet-L2 teacher 보다 parameter는 15배 작고, MACs는 48배 적지만 1.6% 정확도 하락만 있음
- JFT로 pre-training 된 distillation으로 MNv4-Conv-Hybrid는 87.0% top-1 정확도를 달성
9. Conclusion
MobileNetV4 series
- MobileNetV4는 다양한 mobile 환경에서 효율적으로 작동하도록 tuning 된 고효율 모델 시리즈
- 여러 가지 발전을 통해 MobileNetV4를 모든 mobile CPU, GPU, DSP, 특수 accelerator에서 대부분 Pareto-optimal하게 만듦
Main contributions
- 새로운 Universal Inverted Bottleneck과 Mobile MQA 레이어를 도입하고 개선된 NAS 레시피와 결합
- SOTA distillation method를 사용하여 Pixel 8 EdgeTPU에서 3.8ms의 latency로 ImageNet-1K에서 87% 정확도를 달성

AI Research Engineer