https://arxiv.org/abs/2404.15653
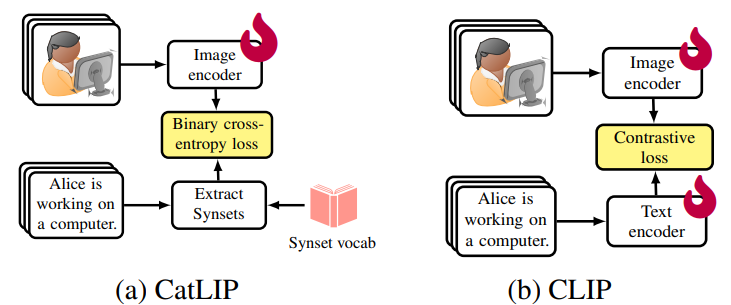
1. Introduction
- 컴퓨터 비전 모델을 대규모 데이터셋으로 사전 훈련하면 다양한 visual task에서 효과적으로 일반화 됨
- 완전 지도 학습 방법은 강력한 semantic representation을 학습하지만, 대규모 manually labeled 데이터셋 확보가 어려움
- 비지도 학습은 레이블 없이 대규모 데이터에 확장 가능하지만, 지도 학습만큼의 성능을 내기 위해서는 더 큰 모델이나 긴 훈련이 필요
- 약한 지도 학습은 noise label을 사용하면서도 확장성을 유지하며 균형을 잡음
- 약한 라벨 데이터에 대한 contrastive learning (예: CLIP)은 image-text 데이터 가용성 증가로 변혁적
- 하지만 CLIP은 pos/neg 샘플 간 모든 pair를 비교해야 해 계산 비용이 큼
- 반면 지도 학습은 CE loss 등 간단하고 계산 효율적인 objective function을 사용
- Zhai et al.(2023)은 배치 전체에 대한 loss 의존도를 줄여 CLIP의 계산 오버헤드를 줄였지만 여전히 pair similarity를 계산해야 함
- web-scale의 image-text 데이터셋과 이미지 분류 프레임워크의 장점을 빠른 학습 속도와 표현력 유지라는 측면에서 효과적으로 활용하는 것이 열린 문제
- 작고 큰 규모의 image-text 데이터셋에서 ImageNet-1k 클래스가 자주 등장하는 것을 발견
- 이에 기반하여, 본 논문에서는 약한 라벨이 달린 web-scale image-text 데이터셋에서 효율성과 확장성을 절충하는 CatLIP (Categorical Loss for Image-text Pre-training) 방법을 제안
Main contributions
-
image-text 데이터에서 비전 모델의 사전훈련을 가속화하는 새로운 접근법인 CatLIP을 제안
-
CatLIP은 데이터와 모델 규모가 커질수록 정확도가 향상. 특히 작은 image-text 데이터에서 CLIP에 비해 긴 훈련 시간에 따라 모델 성능이 크게 개선
-
전이학습 시 기본 접근법은 사전훈련 가중치로 backbone을 초기화하고 classifier는 무작위 초기화. CatLIP의 어휘에 대상 레이블이 포함되므로, 사전훈련 모델의 분류기 층에서 target label embedding을 추출할 수 있음. 이 embedding을 target task의 classifier 초기화에 활용하여 데이터 효율적인 전이학습이 가능해짐
-
Object detection, semantic segmentation 등 다양한 downstream task에 대한 광범위한 실험을 통해 CatLIP이 학습한 representation의 효과를 입증했으며, CLIP와 유사한 수준의 성능을 보임. 주목할 점은 DataComp-1.3B 데이터셋에서 CatLIP이 CLIP에 비해 2.7배 더 빠른 사전훈련이 가능하다는 것
3. CatLIP: Contrastive to Categorical Learning
- 주어진 image-text 데이터셋 D에 대해, CLIP은 독립적인 영상 및 텍스트 인코더에서 얻은 image와 text embedding을 contrastive loss를 통해 정렬
- 이는 image-text embedding 간 모든 pair의 similarity를 계산해야 하므로 계산 비용이 큼
- 이 논문에서는 기존과는 다르게 image-text 사전훈련을 "classification task"로 다룸
- 텍스트 캡션에서 명사를 추출하여 WordNet 개념 (synset)에 매핑
- CC3M 데이터셋에서 ViT 모델을 사전훈련하고, ImageNet-1k에서 linear probing 정확도로 성능을 평가
- 제안된 방법은 CLIP과 달리 훈련 시간이 길어질수록 성능이 계속 향상되는 비포화 (non-saturation) 현상을 보임
3.1. Caption-derived classification labels
- 웹에서 수집한 노이즈 image-text 데이터의 풍부함 덕분에 대규모 contrastive 사전훈련이 가능해져 visual recognition task에서 모델의 일반화 성능이 향상
- 그러나 image-text 사전훈련은 이미지 분류를 위한 지도학습 사전훈련에 비해 계산 비용이 크다는 점을 주목해야 함
- 긍정적인 점은 web-scale의 image-text 데이터 수집이 레이블 데이터 수집보다 비용 효율적이라는 점
- Web-scale image-text 데이터셋과 이미지 분류 프레임워크의 장점을 빠른 학습과 표현력 유지 측면에서 효과적으로 활용하는 것이 열린 문제
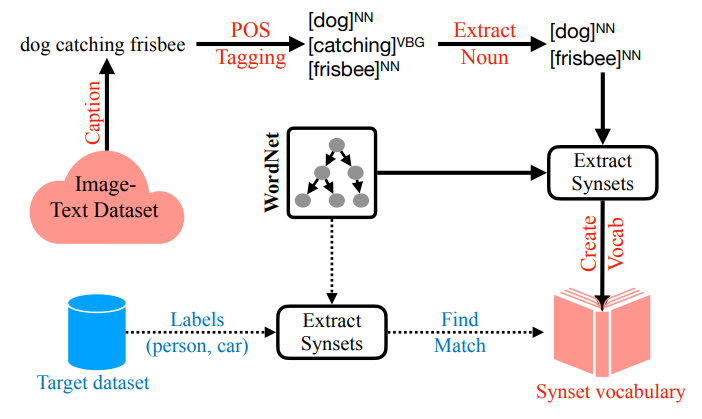
- 위 그림과 같은 방식으로 간단한 분석 결과, 대규모 image-text 데이터셋에는 downstream 분류 데이터셋(예: ImageNet-1k)의 레이블이 많이 포함되어 있고, 각 레이블에 해당하는 샘플 수도 많아짐
- 이는 사전훈련 데이터가 downstream task와 연관성이 높아 zero-shot 정확도 향상으로 이어질 수 있음을 시사
- 따라서 image-text 사전훈련을 classification 문제로 다룰 수 있는지에 대한 의문이 제기
3.2. CatLIP pre-training
- 위 문제에 답하기 위해 WordNet 개념 (synset) 지도 학습에 기반한 약한 지도 사전훈련 방법인 CatLIP을 제안
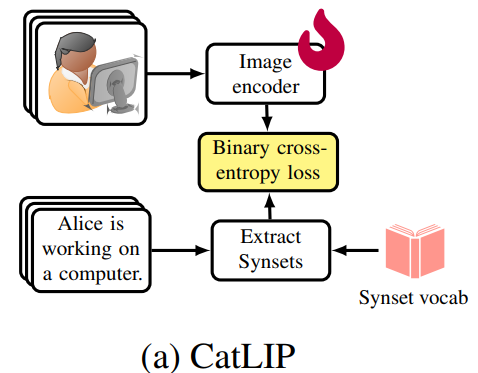
- 위 그림에서 보는 바와 같이, CatLIP은 입력 텍스트 캡션에서 다중 개념을 추출한 후, BCE loss를 사용하여 이미지 분류 모델을 사전훈련
- 이를 통해 문제를 noise image-text 정렬에서 noise 이미지 분류로 전환시킴
Synset vocabulary
-
Image-text 데이터셋에서 개념 (synset)의 분포는 long-tail 분포를 따름
(아래 그림)
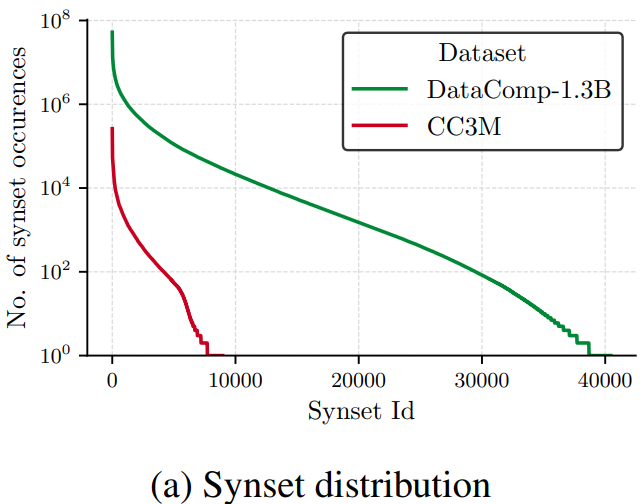
-
주어진 image-text 데이터셋에서 개념 S의 출현 횟수 C를 계산하여 어휘 V: S → C를 생성
-
일부 개념은 빈도수가 낮으므로, 사전 정의한 vocabulary pruning threshold Vτ보다 큰 개념만 V에 저장
-
적절한 Vτ 값을 결정하기 위해 CC3M 데이터셋에서 ViT B/16 백본으로 CatLIP를 훈련하고 ImageNet-1k에서 linear probing 정확도를 평가
-
실험에서는 Vτ = 500을 사용
CatLIP vs. CLIP
- Image-text 데이터셋에 대한 사전훈련을 분류 문제로 다룰 때, CatLIP이 CLIP 사전훈련의 실용적인 대안이 될 수 있는지 평가
- 이를 위해 작은 규모의 image-text 데이터셋인 CC3M에서 ViT B/16 백본으로 CatLIP와 CLIP를 사전훈련하고 비교실험을 수행
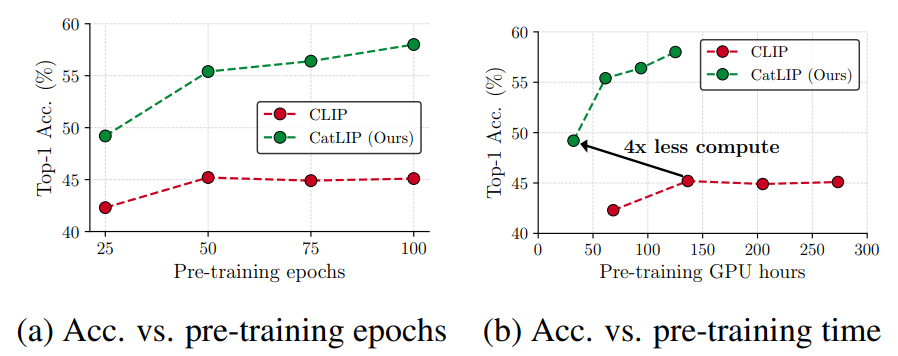
- 위 그림의 결과에서 다음과 같은 관찰을 할 수 있음
- CatLIP로 사전훈련된 ViT B/16 모델의 ImageNet-1k linear probing 정확도는 훈련 시간이 길어질수록 계속 향상. 반면 CLIP의 정확도는 특정 시점 이후 계속 유지. 이는 CLIP이 최적의 성능을 내기 위해서는 대규모 사전훈련 데이터가 필요하다는 기존 연구와 일치
- CatLIP는 CLIP에 비해 빠른 사전훈련 속도를 보임. 이는 CatLIP가 사전훈련 중 이미지 백본만 최적화하는 반면 CLIP는 image-text 백본을 모두 최적화하기 때문. 따라서 CatLIP는 다음과 같은 훈련 효율성 측면에서 CLIP보다 이점이 있음
(1) 최적화할 네트워크 파라미터가 적어 step time (forward and backward)이 빠름
(2) 동일 배치 크기에서 GPU 메모리 요구량이 적음
(3) GPU 최적화된 loss function 구현의 이점을 누림
(4) 다중노드 훈련 시 contrastive loss의 global pair-wise 유사도 계산을 동기화할 필요가 없어 communication 오버헤드가 적음
4. Data and Model Scaling in CatLIP
4.2. Model scaling
Representation quality improves with model size
- 모델 규모를 확장하면 표현 품질이 향상
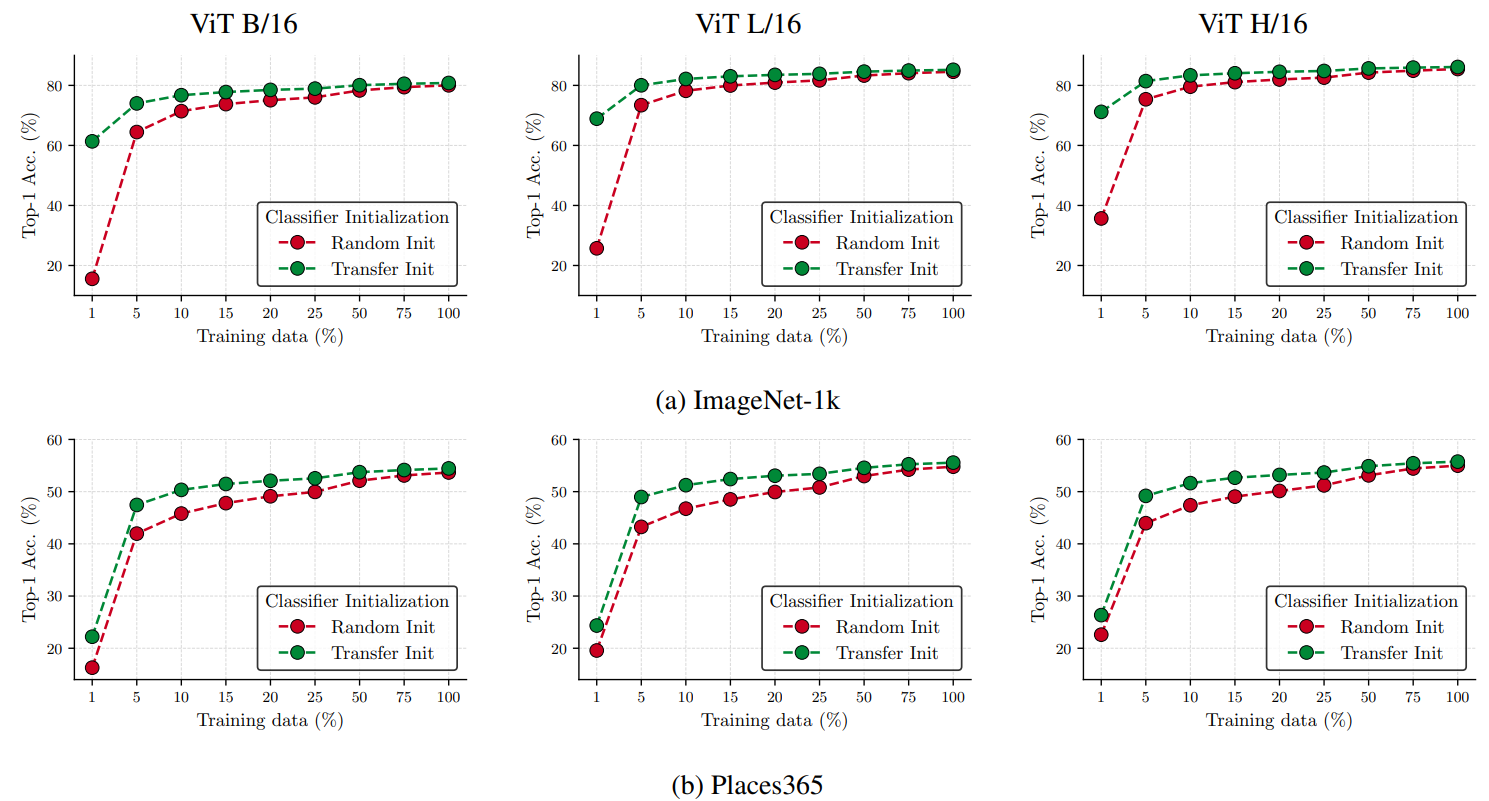
Figure 5
- 하지만 가장 큰 모델(ViT H/16)의 성능은 CatLIP에서 포화 상태 도달 (ViT B/16 vs ViT L/16 vs ViT H/16: 80.8 vs 85.2 vs 86.1, Figure 5a)
- ImageNet-1k에 대한 이 결과는 대규모 지도학습 데이터셋에서의 ViT 확장 법칙과 일치
- Places365 데이터셋에서도 유사한 경향을 관찰할 수 있음 (Figure 5b)
Better transfer learning with bigger models
- Task-specific 데이터셋에 대한 linear probing에서 큰 모델이 작은 데이터 영역에서 전이학습 능력이 더 좋음 (Figure 5의 빨간색 곡선)
- 예를 들어 ImageNet-1k 데이터 1%로 훈련 시, ViT B/16, L/16, H/16의 Top-1 정확도는 각각 16%, 26%, 36%
- 이는 큰 모델이 기존 지식을 효과적으로 활용하고 소량 데이터에 대해 일반화할 수 있는 능력이 큼을 시사
Data efficient transfer learning
Figure 5의 결과에서 두 가지 관찰을 할 수 있음
(1) ImageNet-1k의 경우, 모든 downstream 레이블이 V의 부분집합임. 따라서 Transfer Init는 특히 소량 데이터 영역에서 현저히 높은 정확도를 보임 (Figure 5a). 이는 대규모 코퍼스 사전훈련으로 모델이 유사 객체 이미지에 노출되었기 때문
(2) Places365의 경우에도 Transfer Init가 정확도 향상을 가져오지만, (1)에 비해 이득이 작음
4.3. Comparison with existing pre-training methods
- 약한 지도학습 방법인 CatLIP를 state-of-the-art 방법들과 아래 테이블에서 비교
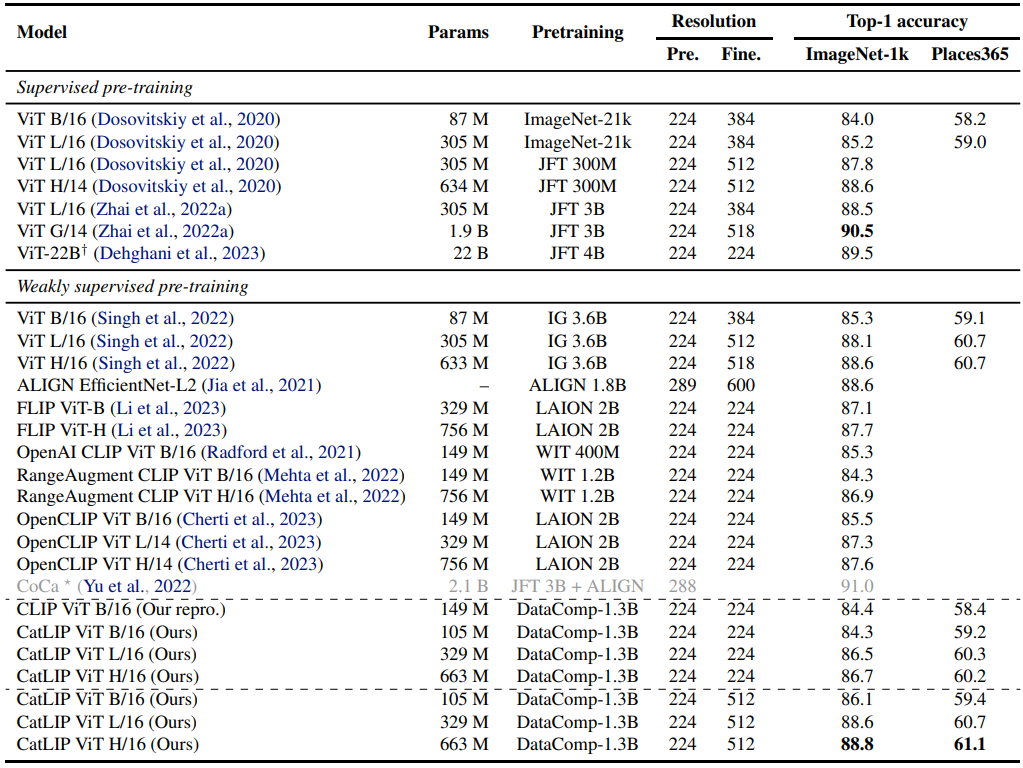
- 위 테이블에 따르면, CatLIP는 기존 사전훈련 방법과 대등한 성능을 냄
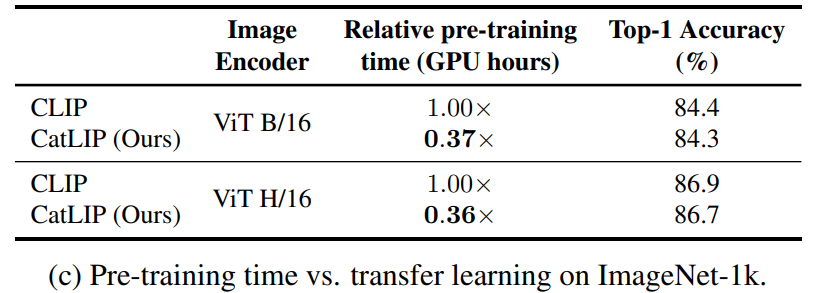
- 주목할 점은 CatLIP 사전훈련이 CLIP보다 2.7배 빠르다는 것
- 이 결과는 CatLIP가 대규모 image-text 데이터에 대한 대비 사전훈련의 효율적이고 효과적인 대안이 될 수 있음을 시사
- 또한 CatLIP로 훈련된 ViT 변형은 다른 CLIP 변형 (OpenCLIP, RangeAugment CLIP)과 대등한 수준이지만, 다른 데이터셋으로 사전훈련되었다는 점
- Singh et al. (2022)과의 비교도 재미있는데, 이는 해시태그를 레이블로 사용해 Instagram 이미지에 대해 multi-label classifier로 훈련되었기 때문
- 특히 CatLIP는 Singh et al. (2022)와 유사한 성능을 내지만, 사전훈련 데이터 규모는 약 2.8배 작음
5. Task Generalization
5.1. Multi-label object classification

- 위 테이블에 따르면 CatLIP는 CLIP와 유사한 수준의 성능을 냄
- 주목할 만한 점은 CatLIP가 단순한 BCE loss로 훈련되었음에도 불구하고, 비대칭 loss function 등 더 복잡한 기술을 사용하는 기존 방법과 대등한 정확도를 달성
6. Conclusion
- 본 논문은 공개된 Web-scale image-text 데이터를 사용하여 비전 모델에 대한 약한 지도 사전훈련 방법인 CatLIP을 제안
- 사전훈련을 분류 문제로 재정립함으로써 제안된 방법은 contrastive learning의 계산 문제를 해결하고, web-scale 데이터에서 2.7배 빠른 훈련 속도를 달성하면서도 object detection 및 segmentation을 포함한 다양한 시각 인식 task에서 전이학습 정확도를 유지
- 비전 모델의 효율적이고 효과적인 사전훈련에 기여
- Web-scale noise 데이터에 대한 효율적인 사전훈련 연구를 촉진하기를 기대
Broader Impact
- 대규모 image-text 데이터셋에 대한 사전훈련은 컴퓨터 비전 및 관련 분야에서 일련의 획기적인 성과를 이룸
- 그러나 대규모 사전훈련은 여전히 상당한 computing resource가 필요한 task
- 이 논문은 image-text 사전훈련의 효율성에 대한 통찰력을 제공
- 다양한 visual recongintion task에서 전이 정확도를 유지하면서 훈련 효율성이 향상되는 것을 보임
