https://arxiv.org/abs/2403.19963
ICLR 2024
1. INTRODUCTION
- ViT는 self-attention 덕분에 강력한 성능을 보이지만, 계산 복잡성이 높아 모바일 및 실시간 응용 프로그램에 적용하기 어려움
- 이를 해결하기 위해 self-attention를 지역적으로 적용하거나 중요 토큰만 선별하여 계산하는 등의 시도가 있었고, convolution과 self-attention를 결합하는 연구도 있었음
- 순수 convolutional 네트워크로도 ViT와 경쟁할 만한 성과를 얻을 수 있다는 연구 결과가 있었음. 그중 FocalNet과 VAN은 계산 효율성과 구현 용이성이 높으며 ViT를 크게 능가하는 성능을 보임
- FocalNet과 VAN은 공통적으로 대규모 convolution 블록을 통해 context를 모델링하고, 입력 feature를 element-wise multiplication으로 modulate하는 메커니즘을 사용
- 이를 Modulation 메커니즘이라 부르며, convolution의 효과와 self-attention의 역동성을 결합한 것이 특징임
- 그러나 Modulation 메커니즘은 계산 자원이 제한적일 때 추론 속도가 만족스럽지 않은데, 이는 중복 연산과 파편화된 context 모델링 연산 때문
- Main Contributions
- 본 논문에서는 Efficient Modulation을 제안 (EfficientMod)
- 이는 FocalNet, VAN에서의 방식을 개선한 버전
- 기존 Modulation 장점을 유지하면서 계산 복잡도를 선형적으로 낮춤
- EfficientMod-s는 EfficientFormerV2-S2보다 0.3 높은 top-1 정확도를 달성하면서 25% 더 빠른 GPU 추론 속도를 보임
- ADE20K 벤치마크에서도 EfficientFormerV2 대비 3.6 mIoU 더 높은 수치를 보임
3. METHOD
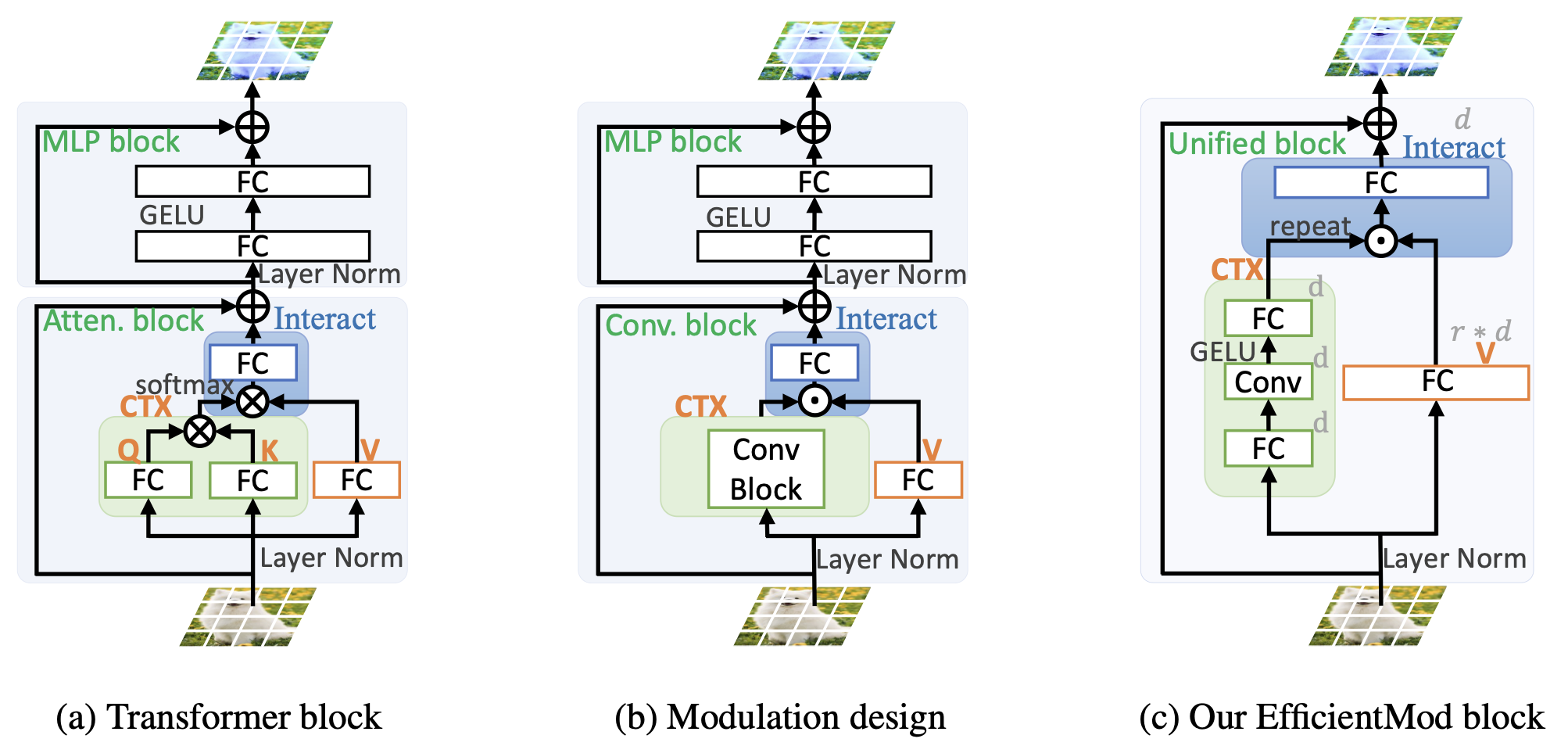
3.1. REVISIT MODULATION DESIGN
Visual Attention Networks
- VAN(Guo et al., 2023)에서는 convolution 기반 attention 메커니즘을 제안
- VAN 블록은 MetaFormer 설계 철학에 따라 token-mixer로 사용
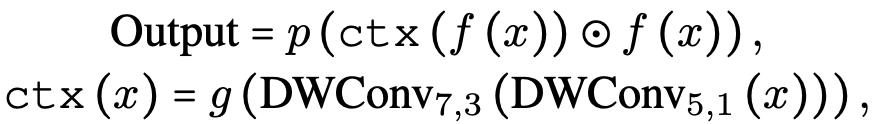
- f(⋅): fully-connected (FC) layer (with activation function)
- ctx(⋅): extracts the context information
- p(⋅): linear projection
- ⊙: element-wise multiplication
- DWConvk,d: depth-wise convolution with kernel size k and dilation d
- g(⋅): another FC layer in the context branch
- 수식을 간단히 요약하면, VAN은 입력 feature map을 두 branch로 나누어, 하나는 context information 추출에 활용하고, 다른 하나는 그대로 유지한 뒤 element-wise multplication으로 합치고 linear projection하는 구조
FocalNets
- FocalNet(Yang et al., 2022)에서는 Focal Modulation 메커니즘을 제안
- 이는 self-attention를 대체하면서도 dynamics와 large receptive fields를 누릴 수 있음
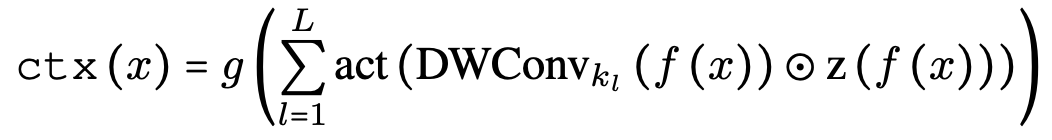
- ctx(·): 다양한 level의 context를 적응적으로 통합
- v(⋅): linear project branch project x to a new space
- p(⋅): FC layer
- act(⋅): GELU activation function
- 수식을 간단히 요약하면, 다양한 커널 크기의 depth-wise convolution을 통해 계층적 context information을 추출하고, 이를 element-wise multiplication과 sum으로 통합한 후 FC layer를 거쳐 최종 context feature를 생성
Abstracted Modulation Mechanism
- VAN과 FocalNet의 공통적인 핵심 디자인 요소들을 통합하여, 연구진은 "추상화된 변조 메커니즘(Abstracted Modulation Mechanism)"을 제안
- 이 메커니즘은 아래 구조를 가짐
1) 두 개의 병렬 branch로 다른 feature space 추출
2) Large receptive field의 context 모델링
3) Element-wise multiplicaton 을 통한 feature fusion
4) Fusion 후 linear projection layer 적용
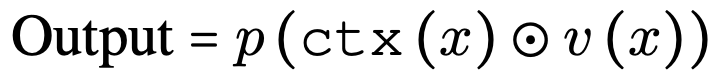
- 위 수식으로 표현 가능
- 이러한 메커니즘은 convolution과 self-attention의 장점을 모두 취하면서도 계산 효율성이 높고, feature를 초고차원 공간으로 투영할 수 있는 잠재력이 있음
3.2. EFFICIENT MODULATION
- Modulation Mechanism은 self-attention 메커니즘보다 효율적이지만 여전히 모바일 네트워크에 적용하기에는 이론적 복잡도와 추론 속도 측면에서 한계가 있음
- 이에 본 논문는 Efficient Modulation를 제안
- 구체적인 개선 사항은 다음과 같음:
- Sliming Modulation Design:
- Modulation 블록 내 여러 분리된 연산을 통합하여 MBConv 블록과 유사한 구조로 만듦
- MLP 블록을 Modulation 블록에 통합하되 채널 확장/축소 비율을 유연하게 조절
- Simplifying Context Modeling:
- 입력을 새로운 feature 공간으로 투영한 뒤, 단일 대규모 depth-wise convolution으로 local spatial information 모델링
- 채널 수를 일정하게 유지하여 복잡도를 낮춤
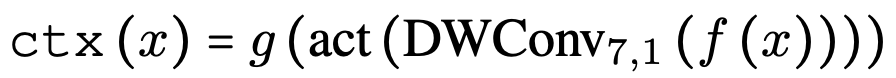
- 이와 같은 설계로 이론적 효율성과 실제 추론 속도를 모두 개선하면서도 Modulation 메커니즘의 장점을 유지할 수 있음
3.3. NETWORK ARCHITECTURE
- 앞서 제안한 Modulation 메커니즘을 기반으로 아래와 같은 Efficient Modulation (EfficientMod) 블록을 설계
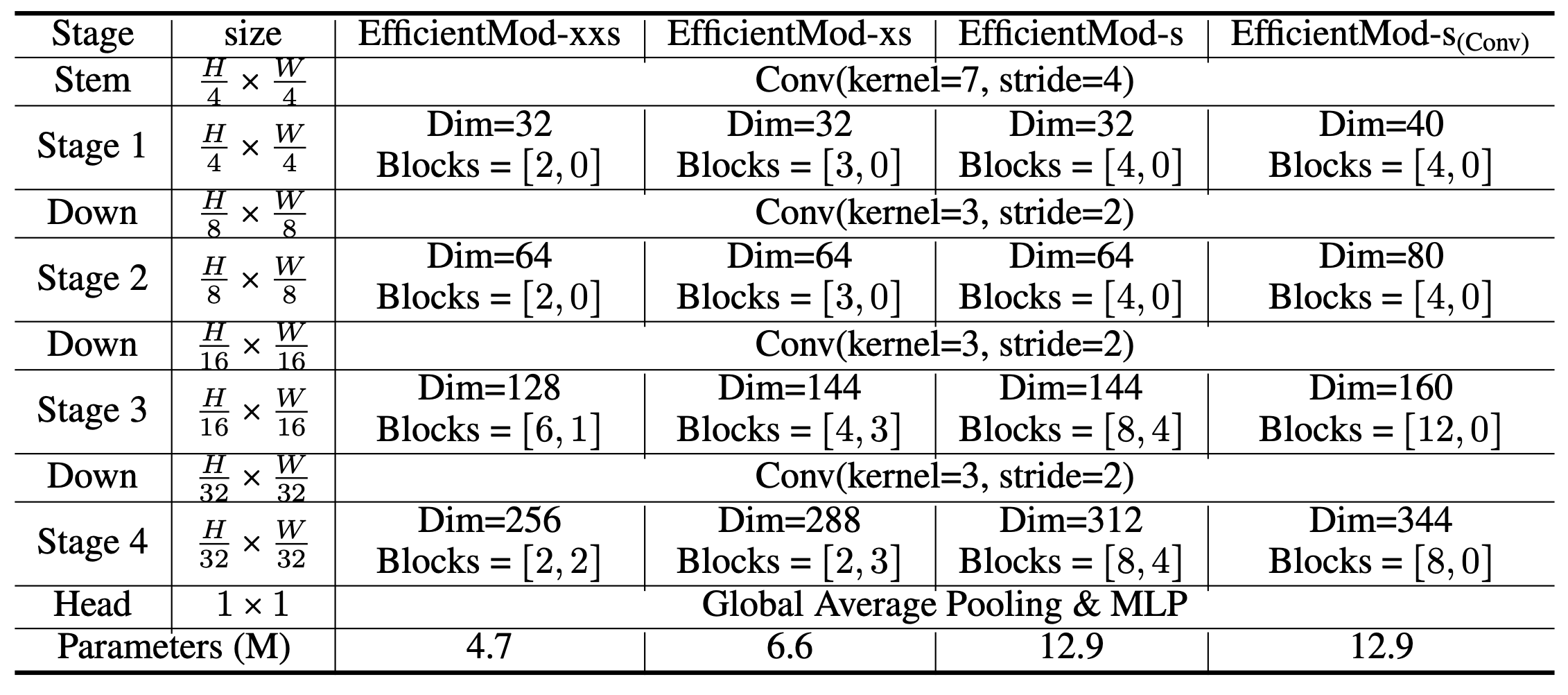
- EfficientMod 블록만으로 이루어진 순수 convolution 네트워크와, attention 블록과 결합한 하이브리드 네트워크 두 가지 버전을 제안
- 순수 convolution 버전은 4단계 계층 구조로 각 단계에 EfficientMod 블록과 residual connection이 있음
- 하이브리드 버전은 마지막 2단계에서만 attention 블록을 추가
- 파라미터 수를 4M~13M 범위로 다양화하여 EfficientMod-xxs, -xs, -s 3가지 규모의 모델을 설계
- 순수 convolution 버전과 하이브리드 버전 모두를 제안하여 공정한 비교 평가가 가능하도록 함
3.4. COMPUTATIONAL COMPLEXITY ANALYSIS
- EfficientMod 블록의 이론적 계산 복잡도를 분석
- 입력 해상도에 대해 선형 복잡도를 가지며, MBConv보다 효율적
Practical guidelines for design
- 후반부 단계에서 더 많은 파라미터를 사용하여 FLOPs를 절감
- Self-attention의 계산 복잡도를 고려하여 마지막 2단계에만 attention 블록을 도입
- Repeat 연산을 사용하여 CPU 시간을 절약하되 GPU 오버헤드는 경미함
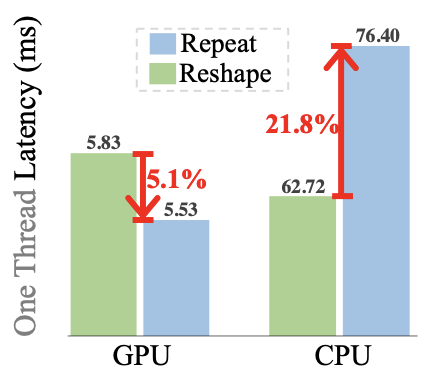
- 위 그림에서 처럼 Repeat 연산을 선택하면 GPU에서는 다소 오버헤드가 있지만, CPU 시간을 대폭 절약할 수 있음을 알 수 있음
- 전체적인 GPU-CPU latency 비율을 고려했을 때, Repeat 연산이 21.8%로 Reshape의 5.1%보다 효율적임을 보여줌
- EfficientMod는 이론적으로 효율적이며, 실제 설계 지침을 통해 계산 효율성을 높일 수 있음
4. EXPERIMENTS
EfficientMod의 성능을 검증하기 위해 4가지 task에 대해 평가
- ImageNet-1K image classification
- MS COCO object detection 및 instance segmentation
- ADE20K semantic segmentation
모든 네트워크는 PyTorch로 구현되었고, 다음 두 가지 하드웨어에서 ONNX 모델로 변환
- GPU: P100 GPU를 사용하여 최근 기기들의 컴퓨팅 파워를 모방
- CPU: Intel Xeon E5-2680 CPU 사용
- Latency 벤치마크에서는 배치 크기를 1로 설정하여 실제 애플리케이션을 시뮬레이션
- 각 모델에 대해 4000회 반복 실행하여 평균 추론 시간을 측정했으며, 4개 스레드를 사용
4.1. IMAGE CLASSIFICATION ON IMAGENET-1K
- DeiT의 표준 훈련 전략을 따랐으며, 강력한 훈련 기법(Re-parameterization, Distillation 등)은 사용하지 않아 공정한 비교가 가능하도록 함
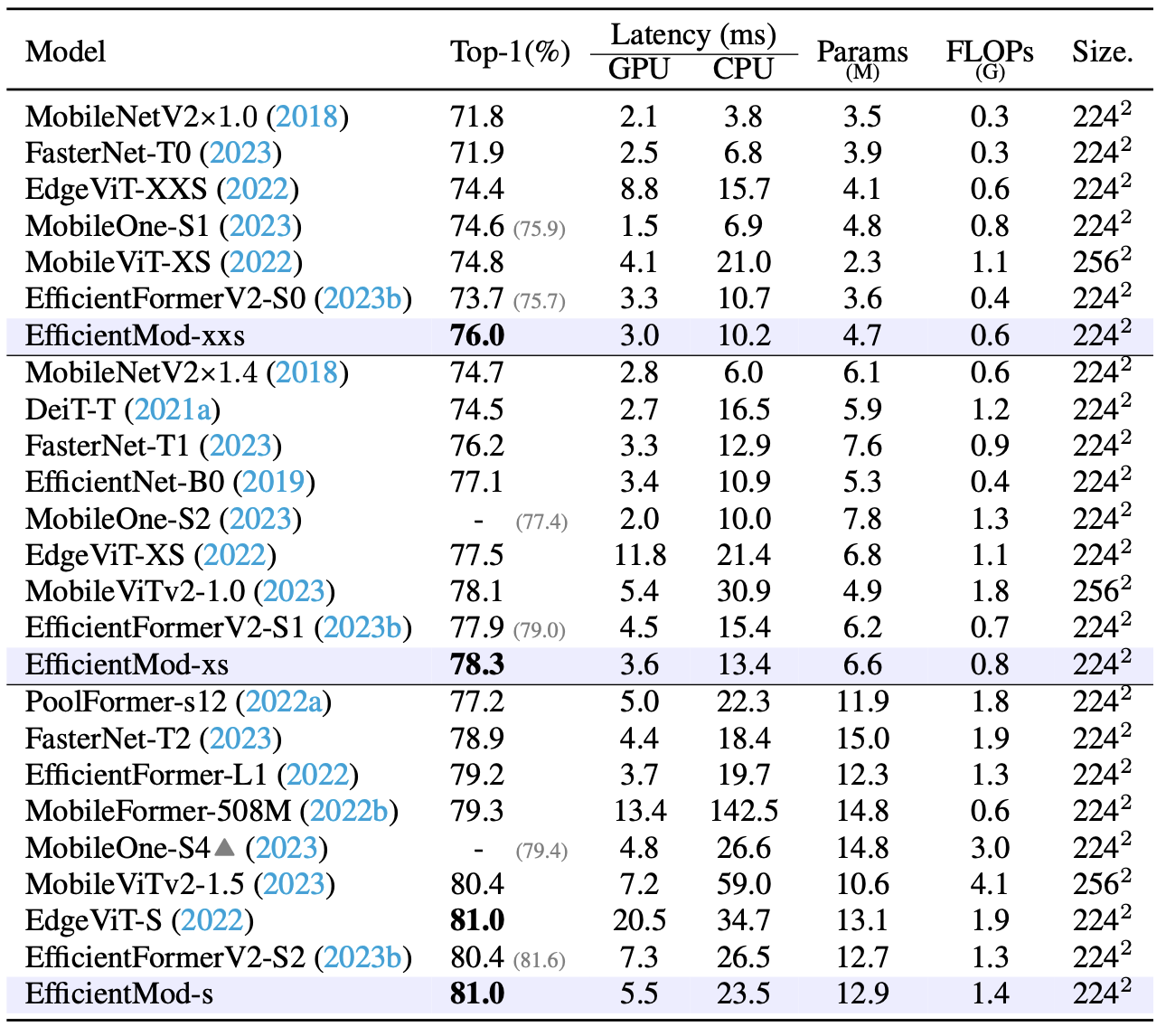
- 위 테이블에서 다른 효율적인 디자인들과 비교했을 때, EfficientMod가 분류 accuracy와 GPU/CPU 추론 latency 측면에서 매우 뛰어난 성능을 보임
- EfficientMod-s는 EdgeViT와 비슷한 정확도지만 GPU에서 73%, CPU에서 32% 더 빠른 속도를 보임
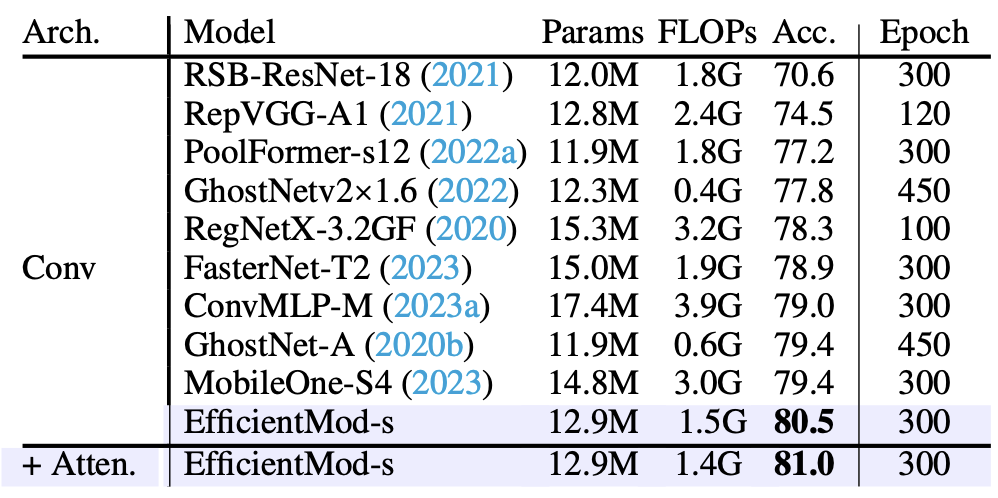
- 위 테이블에서는 EfficientMod-s를 사례로 각 수정 사항의 개선 효과를 보여줌
- 순수 convolution 버전에서 시작하여 attention 통합 하이브리드 모델로 나아가며 점진적인 성능 향상을 보임
- 일부 방법론들은 Re-parameterization, Distillation 등 강력한 전략을 사용했지만, EfficientMod는 기본 설정에서도 높은 성능을 달성
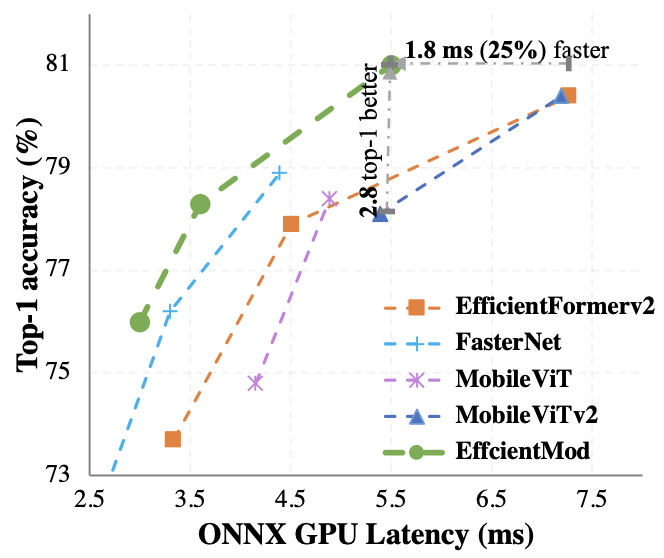
- 위 그림은 ONNX GPU latency와 accuracy 간의 trade-off를 보여줌
4.2. ABLATION STUDIES

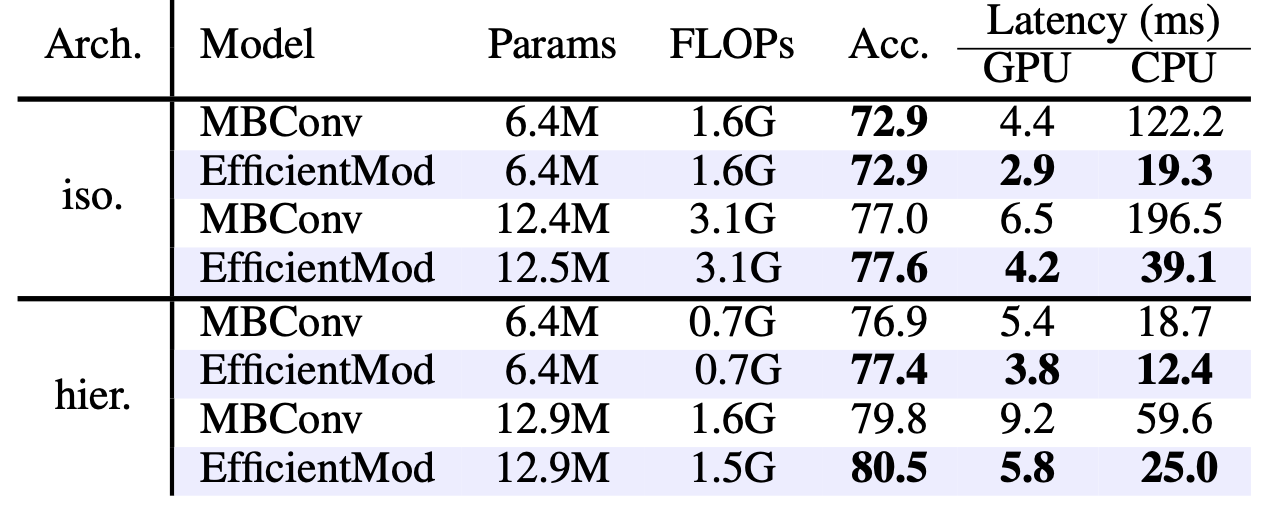
- 위 테이블에선 유사한 파라미터 수를 가진 FocalNet, VAN-B0 모델과 EfficientMod-xxs를 비교
- EfficientMod가 accuracy와 latency 측면에서 우수한 성능을 보임

- 위 테이블에선 디자인의 각 구성요소가 미치는 영향을 분석
- 모든 요소가 최종 성능에 중요한 역할을 함을 확인
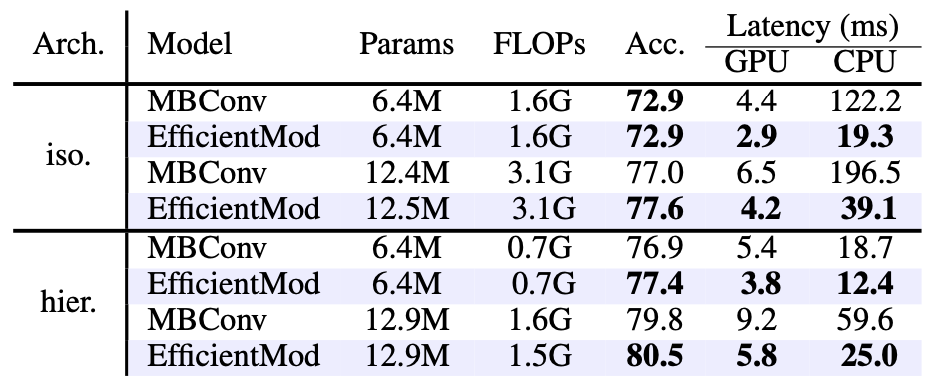
- 위 테이블에선 MBConv 블록과의 비교
- EfficientMod가 GPU/CPU 모두에서 큰 폭으로 더 빠른 추론 속도를 보였고, 실증적 성능도 우수

- 위 그림에선 context modeling 시각화를 비교
- EfficientMod가 정보가 있는 객체를 효과적으로 포착하고 배경을 제한함을 확인
5. CONCLUSION
- EfficientMod는 convolution과 attention 메커니즘의 장점을 통합하여, spatial context 추출과 입력 feature projection을 동시에 수행하며, 이를 element-wise multiplication으로 fusion
- 우아한 디자인으로 계산 효율성을 보장하면서, 내재된 디자인 철학을 통해 강력한 representation 능력도 갖춤
- EfficientMod를 기반으로 다양한 규모의 효율적인 모델 시리즈를 구축
- 광범위한 실험을 통해 EfficientMod의 효율성과 효과를 입증했으며, 기존 SOTA 방법론보다 실증적 결과와 실제 latency 측면에서 우수한 성능을 보임
- Dense prediction task에도 적용하여 인상적인 결과를 달성
- 추가 연구를 통해 EfficientMod가 효율적인 응용 분야에서 큰 잠재력을 지녔음을 확인
Limitations and Broader Impacts
- 효율적 디자인의 확장성은 흥미로우나 연구가 부족한 주제임
- 큰 커널이나 attention 블록 도입이 receptive field 확장의 가장 효율적인 방법은 아닐 수 있음
- EfficientMod가 부정적인 사회적 영향은 아직 관찰되지 않았으며, 오히려 제한된 계산 자원 환경에서 계산량 감소와 애플리케이션 단순화 연구를 권장

AI Research Engineer