https://arxiv.org/abs/2405.07992
1. Introduction
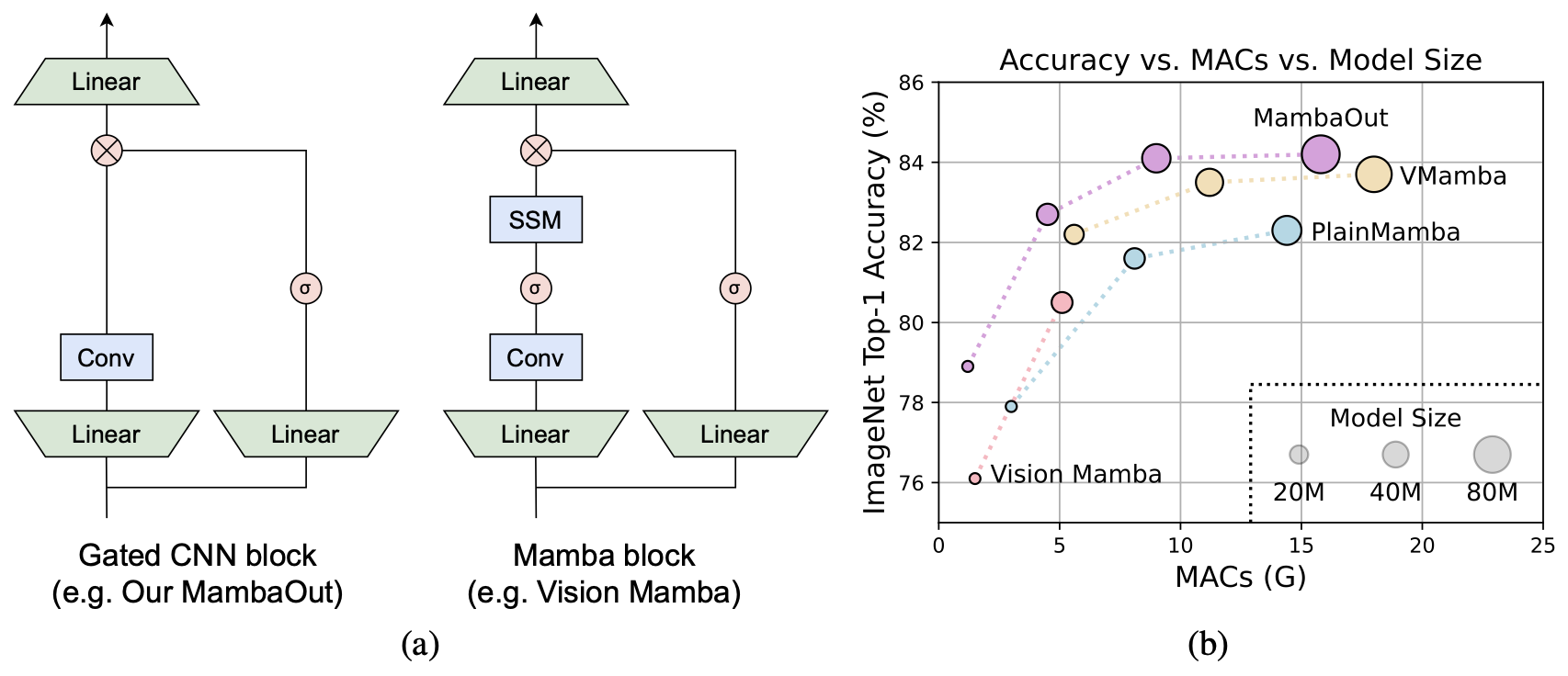
- Transformer는 BERT, GPT 시리즈, ViT 등의 주요 model의 backbone이 되었으나, attention 메커니즘의 복잡성 문제로 long sequence 처리에 어려움을 겪음
- 선형 복잡성을 가진 다양한 token mixer들이 제안되었으며, 최근에는 병렬 학습과 효율적인 추론이 가능한 RNN-like model들이 주목받고 있음
- RWKV, Mamba ...
- Mamba를 visual recognition task에 도입하려는 시도들이 있었으나, 실험에서는 기존의 convolution 및 attention 기반 model들에 비해 성능이 미흡했음
- Mamba는 long sequence와 autoregressive 특성을 지닌 task에는 적합하지만, 많은 visual recognition task는 이러한 특성을 가지지 않기 때문임
- 본 논문에서는 Mamba의 특성과 visual recognition task에의 적합성을 조사하며, 두 가지 가설을 제시함:
가설 1: SSM은 image classification task에 적합하지 않음
가설 2: SSM은 detection 및 segmentation task에는 잠재적으로 유용할 수 있음 - 실험적으로 가설을 검증하기 위해 Gated CNN block을 쌓아 MambaOut model을 개발
- 실험 결과, MambaOut은 image classification에서 기존의 Mamba model을 능가했으나, detection 및 segmentation에서는 기존의 Mamba model에 미치지 못함
Three main contributions
- 1
- SSM의 RNN-like 메커니즘을 분석하고, 개념적으로 Mamba가 long sequence와 autoregressive 특성을 지닌 task에 적합하다고 결론지음
- 2
- Vision task의 특성을 보았을 때, image classification task는 두 가지 특성을 모두 만족하지 않아 SSM이 불필요하다고 가정
- 하지만 detection 및 segmentation task는 long sequence 특성을 지녀 SSM의 잠재적 탐구가 가치 있다고 가설을 세움
- 3
- SSM이 없는 Gated CNN block 기반의 MambaOut model 시리즈를 개발
- 실험 결과, MambaOut이 ImageNet classification에서는 기존 Mamba vision model을 능가했지만, detection 및 segmentation 에서는 최신 Mamba model의 성능에 미치지 못하였음
2. Related work
- Transformer는 다양한 분야에서 널리 사용되고 있으며, NLP의 BERT와 GPT 시리즈, computer vision의 ViT 등이 대표적
- 하지만 Transformer의 attention 모듈은 sequence 길이에 따라 복잡도가 제곱으로 증가해 큰 계산 부담을 줌
- 이를 해결하기 위해 아래와 같은 다양한 전략이 연구되어옴
- Low rank approaches
- Kernelization
- Token mixing range limitation
- History memory compression
- 최근에는 RNN-like 방법, 특히 RWKV와 Mamba가 large scale model에서 유망한 결과를 보여 주목받고 있음
- SSM과 Mamba를 visual recognition task에 빠르게 도입하기 위한 아래와 같은 기존 연구가 있음
- Vision Mamba는 ViT와 유사한 isotropic vision model을 개발
- VMamba는 AlexNet과 ResNet과 유사한 계층적 vision model을 개발
- LocalMamba는 local inductive biases를 통합해 vision Mamba model을 향상
- PlainMamba는 isotropic Mamba model의 성능을 더욱 향상시키기 위해 시도
- EfficientVMamba는 lightweight vision Mamba model을 위해 atrous selective scan을 도입해 효율성을 강조
- 본 논문에서는 새로운 vision Mamba model을 설계하려는 것이 아닌, visual recognition에서 Mamba의 필요성에 대한 중요한 연구 질문을 탐구
3. Conceptual discussion
3.1. What tasks is Mamba suitable for?
- Mamba의 token mixer는 selective SSM으로, 네 가지 input dependent parameter 를 정의하고 로 변환
SSM의 sequence-to-sequence 변환
- SSM의 sequence-to-sequence 변환은 다음과 같이 표현
- 는 time step을, 는 input, 는 hidden state, 는 output을 나타냄
- Equation 2의 recurrent 특성은 RNN-like SSM을 causal attention과 구별
Hidden state 설명
- Hidden state 는 고정된 크기의 memory로 볼 수 있으며, 모든 historical 정보를 저장
- Equation 2를 통해, 이 memory는 크기를 유지하면서 업데이트
- Memory의 크기가 고정되어 있어서, 현재 input과 memory를 통합하는 계산 복잡도가 일정하게 유지
Memory 크기 변화에 따른 영향
- 반면, causal attention은 모든 key와 value을 memory로 사용하며, 각 새로운 input마다 현재 token의 key와 value을 추가하여 memory를 확장
- 이 이론상 memory는 손실이 없음
- 그러나 input token이 추가될수록 memory 크기가 커지면서, 현재 input과 memory를 통합하는 복잡도가 증가
RNN-like model과 causal attention의 memory 메커니즘 차이
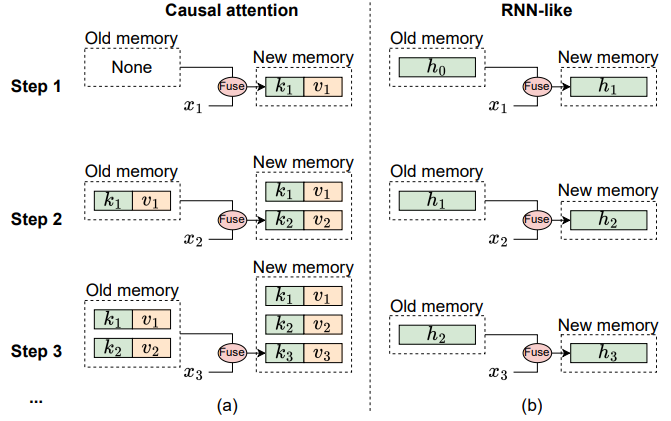
- RNN-like model과 causal attention 사이의 memory 메커니즘 차이는 아래 그림에 자세히 설명
-
Causal Attention의 메커니즘 (위 그림 a)
- Causal attention은 모든 이전 token의 key 와 value 를 memory로 저장
- Memory는 현재 token의 key와 value을 계속 추가하여 업데이트되며, 이로 인해 memory가 손실 없이 유지
- 하지만 sequence가 길어질수록 이전 memory와 현재 token을 통합하는 계산 복잡도가 증가
- 따라서 attention은 짧은 sequence를 효과적으로 처리할 수 있지만, long sequence에서는 어려움을 겪을 수 있음
-
RNN-like model의 메커니즘 (위 그림 b)
- 반면, RNN-like model은 이전 token을 고정 크기의 hidden state 로 압축하여 memory로 사용
- 이 고정 크기는 RNN memory가 본질적으로 손실을 동반함을 의미하며, attention model의 손실 없는 memory 용량과 직접적으로 경쟁할 수 없음
- 그럼에도 불구하고, RNN-like model은 sequence 길이에 상관없이 이전 memory와 현재 input을 통합하는 복잡도가 일정하게 유지되므로 long sequence 처리에 distinct한 장점을 보일 수 있음
Lossy Memory의 특성
- SSM의 memory는 본질적으로 손실이 발생하며, 이로 인해 손실이 없는 memory인 attention에 비해 short-term sequence 처리에서 약점을 가짐
- 따라서 Mamba는 attention이 쉽게 잘 수행하는 짧은 sequence 처리에 강점을 보이지 않음
- 그러나 long sequence의 경우, attention의 quadratic complexity로 인해 성능이 저하되며, 이때 Mamba는 현재 input과 memory를 효율적으로 통합할 수 있어 long sequence를 부드럽게 처리할 수 있음
- 따라서 Mamba는 long sequence 처리에 특히 적합
Causal Mode와 Fully-visible Mode
- SSM의 recurrent 특성 (Equation 2)은 Mamba가 long sequence를 효율적으로 처리할 수 있게 하지만, 이는 가 이전 및 현재 time step의 정보에만 접근할 수 있는 제한을 가짐
- 이는 causal mode로 표현되며, 다음과 같이 수식화
- 여기서 와 는 각각 t번째 token의 input과 output을 나타냄
- Causal mode는 autoregressive generation tasks에 적합
- 반면, fully-visible mode는 각 token이 모든 이전 및 이후 token의 정보를 집계할 수 있는 모드로, 이는 각 token의 output이 모든 token의 input에 의존함을 의미
- 여기서 는 총 token 수를 나타냄
- Fully-visible mode는 model이 한 번에 모든 input을 접근할 수 있는 understanding task에 적합
Attention과 RNN-like model의 모드 차이
- Attention은 기본적으로 fully-visible mode에서 동작하지만, attention maps에 causal masks를 적용하여 causal mode로 쉽게 전환 가능
- RNN-like model은 본질적으로 recurrent 특성 때문에 causal mode에서 동작하며, 이는 Mamba의 Equation 2로 나타남
- 이러한 본질적 특성 때문에, RNN-like model은 fully-visible mode로 전환할 수 없음
- RNN은 양방향 구조를 통해 fully-visible mode를 근사할 수 있지만, 각 분기는 여전히 causal mode에 있음
- 따라서 Mamba는 recurrent 특성의 제한으로 인해 causal token mixing이 필요한 task에 적합
3.2. Do visual recognition tasks have very long sequences?
Analysis of Visual Recognition Tasks and Sequence Length
- 이 섹션에서는 visual recognition tasks가 long sequence model링을 필요로 하는지 여부를 탐구
- 분석을 돕기 위해 Transformer model을 사례 연구로 사용
- 일반적인 MLP 비율이 4인 Transformer block을 고려할 때, input 의 token 길이 과 채널(임베딩) 차원 가 주어진 경우, 해당 block의 FLOPs는 다음과 같이 계산
Quadratic Term과 Linear Term의 비율 ()
- 여기서, 에 대한 quadratic 항과 linear 항의 비율은 다음과 같이 도출
- 일 경우, 에 대한 quadratic 항의 계산 부하가 linear 항을 초과
- 이는 task이 long sequence를 포함하는지 여부를 판단하는 간단한 기준을 제공
예시: ViT model에서의 Threshold 계산
- ViT-S에서 384개의 채널을 가지는 경우, threshold
- ViT-B에서 768개의 채널을 가지는 경우,
Image Classification vs. Object Detection & Segmentation
- Image Classification on ImageNet
- 일반적인 input 이미지 크기가 일 때, patch size가 이면 token의 수는
- 196은 과 모두보다 훨씬 작아 ImageNet에서의 이미지 분류는 long sequence task으로 간주되지 않음
- Object Detection & Instance Segmentation on COCO
- 추론 이미지 크기가 일 때, patch size가 이면 token의 수는 약 4K
- 이고 이므로 COCO에서의 detection과 ADE20K에서의 segmentation은 long sequence task으로 간주될 수 있음
3.3. Do visual recognition tasks need causal token mixing mode?
Causal Mode vs. Fully-visible Mode
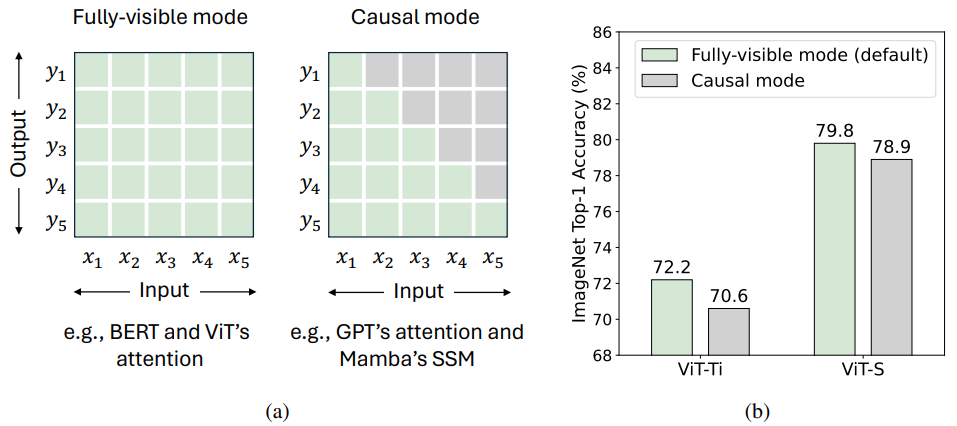
- Section 3.1과 아래 그림에서 논의된 바와 같이, fully-visible token mixing mode는 제한 없는 token mixing이 가능하지만, causal mode는 현재 token이 이전 token의 정보에만 접근할 수 있도록 제한
-
Two Modes of Token Mixing (위 그림 a)
- Fully-visible Mode
- 총 개의 token이 있을 때, fully-visible mode는 token 가 모든 token 의 input을 집계하여 output 를 계산할 수 있도록 허용
- 기본적으로 attention은 fully-visible mode에서 동작하지만, causal attention masks를 사용하여 causal mode로 조정 가능
- Causal Mode
- 반면, causal mode는 token 가 이전 및 현재 token 의 input만 집계할 수 있도록 제한
- Mamba의 SSM과 같은 RNN-like model은 그들의 recurrent 특성 때문에 본질적으로 causal mode에서 동작
- Fully-visible Mode
-
ViT의 성능 변화 (위 그림 b)
- ViT의 attention을 fully-visible mode에서 causal mode로 수정한 결과, ImageNet에서 성능 저하가 관찰
- 이는 causal mixing이 understanding task에 불필요함을 나타냄
-
Visual recognition은 model이 전체 이미지를 한 번에 볼 수 있는 understanding task으로 분류되며, 이로 인해 token mixing에 제한이 필요 없음
-
Token mixing에 추가적인 제약을 가하면 model 성능이 저하될 가능성이 있음
Vision Transformers (ViT) 성능 저하
- 위 그림 b에서, ViT에 causal 제약을 적용했을 때 성능 저하가 눈에 띄게 나타남
- 일반적으로, fully-visible mode는 understanding task에 적합하고, causal mode는 autoregressive task에 더 적합
- BERT와 ViT (BEiT 및 MAE)가 understanding task에 더 많이 사용되는 반면, GPT-1/2 및 image GPT는 그렇지 않다는 점도 이를 뒷받침
- 따라서 visual recognition tasks는 causal token mixing mode를 필요로 하지 않음
3.4. Hypotheses regarding the necessity of Mamba for vision
가설 1
- ImageNet에서의 이미지 분류에는 SSM을 도입할 필요가 없으며, 이는 해당 task가 Characteristic 1이나 Characteristic 2를 충족하지 않기 때문
가설 2
- Detection 및 segmentation task의 경우, 비록 Characteristic 2를 충족하지는 않지만, Characteristic 1에 부합하기 때문에 SSM의 잠재력을 더욱 탐구할 가치가 있음
4. Experimental verification
4.1. Gated CNN and MambaOut
- 가설을 실험적으로 검증하기 위해 Gated CNN block 기반의 MambaOut model 시리즈를 개발
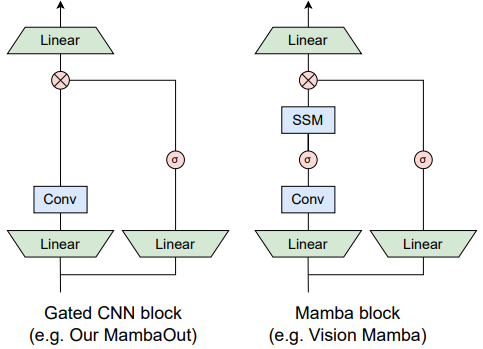
- 위 그림에서 볼 수 있듯이 Mamba block은 Gated CNN block을 기반으로 하며, 주요 차이점은 SSM의 존재 여부
- Gated CNN과 Mamba의 meta architecture는 MetaFormer의 token mixer와 MLP를 단순화한 것과 유사 (Equation 9)
- Token mixer 부분에서 Gated CNN은 Conv 연산 (Equation 10)
- Mamba는 SSM (Equation 11)을 사용
- 이에 착안하여 SSM 없는 Gated CNN block 기반의 MambaOut model을 개발
- MambaOut을 통해 vision task에서 Mamba의 필요성을 평가할 수 있음
- 구체적으로 Gated CNN의 token mixer는 ConvNeXt를 따라 7x7 depthwise conv를 사용하고, InceptionNeXt를 따라 일부 채널에만 적용
Algorithm 1: PyTorch Code of Gated CNN Block
Gated CNN block 구현
import torch
import torch.nn as nn
from functools import partial
class GatedCNNBlock(nn.Module):
def __init__(self, dim, expension_ratio=8/3, kernel_size=7, conv_ratio=1.0,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
act_layer=nn.GELU,
drop_path=0.):
super().__init__()
self.norm = norm_layer(dim)
hidden = int(expension_ratio * dim)
self.fc1 = nn.Linear(dim, hidden * 2)
self.act = act_layer()
conv_channels = int(conv_ratio * dim)
self.split_indices = (hidden, hidden - conv_channels, conv_channels)
self.conv = nn.Conv2d(conv_channels, conv_channels, kernel_size=kernel_size, padding=kernel_size//2,
groups=conv_channels)
self.fc2 = nn.Linear(hidden, dim)
def forward(self, x):
shortcut = x # [B, H, W, C] = x.shape
x = self.norm(x)
g, i, c = torch.split(self.fc1(x), self.split_indices, dim=-1)
c = c.permute(0, 3, 1, 2) # [B, H, W, C] -> [B, C, H, W]
c = self.conv(c)
c = c.permute(0, 2, 3, 1) # [B, C, H, W] -> [B, H, W, C]
x = self.fc2(self.act(g) * c + i)
x = x + shortcut
return x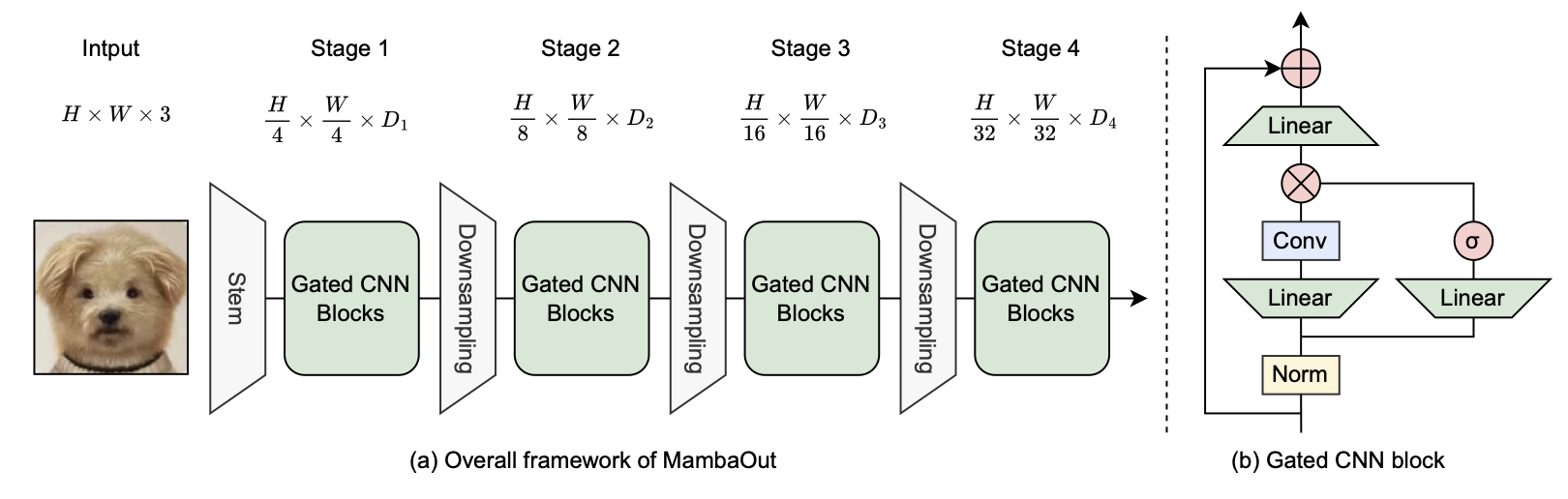
- 위 그림에서 처럼 ResNet과 유사하게 4단계 framework로 Gated CNN block을 쌓아 MambaOut을 구축
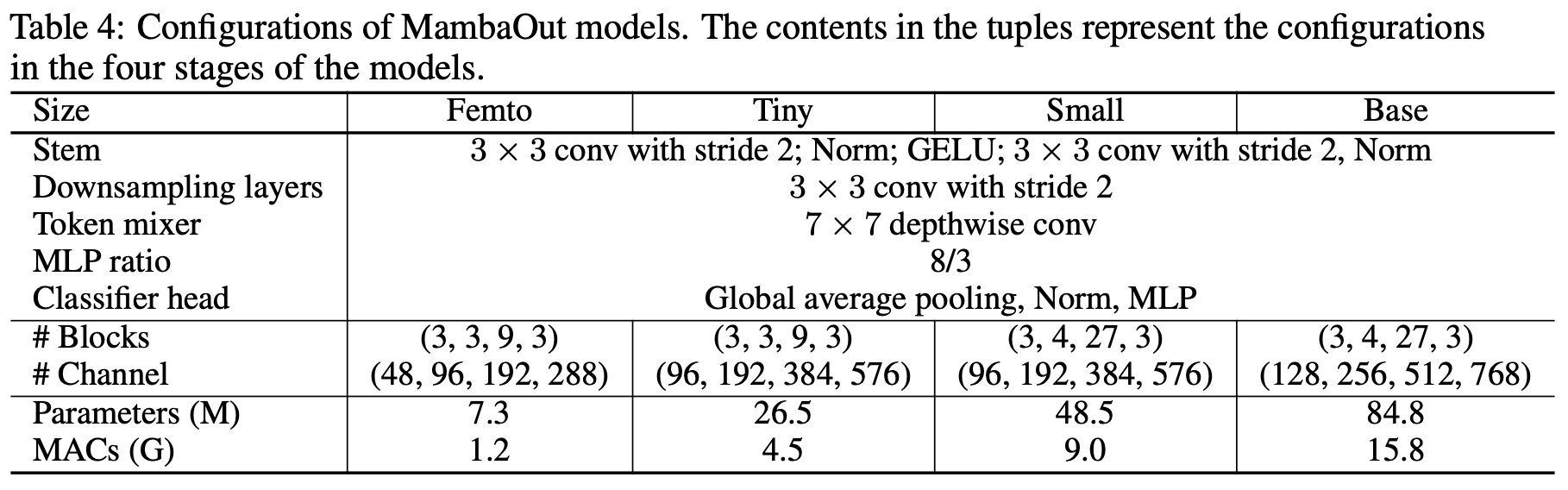
- 각 model 크기에 대한 구성 세부 사항은 아래 테이블에서 확인
4.2. Image classification on ImageNet
Setup
- ImageNet은 1,000개 클래스, 약 130만 장의 학습 이미지로 구성된 classification 벤치마크
- DeiT를 따라 데이터 augmentation, regularization 기법을 적용하고 AdamW로 TPU v3에서 학습
Results
- MambaOut model(SSM 미포함)이 SSM을 포함한 기존 Mamba vision model들보다 일관되게 높은 정확도를 보임

- 위 테이블에서, MambaOut-Small이 LocalVMamba-S보다 0.4% 높은 84.1% 정확도를 79% MACs로 달성
- 이는 가설 1을 강력히 지지하며, ImageNet 분류에 SSM을 도입할 필요가 없음을 시사
- 또한 Mamba vision model들은 최신 Conv+Attn model에 비해 상당한 성능 격차가 있음
- 예를 들어 Conv+Attn을 사용하는 CAFormer-M36이 동급 Mamba model보다 1% 이상 높은 정확도를 보임
- 따라서 향후 연구에서 가설 1에 대한 도전을 위해서는 ImageNet 수준의 최고 성능을 내는 Conv+SSM 기반 Mamba model이 필요할 것
4.3. Object detection & instance segmentation on COCO
Setup
- COCO 2017 데이터셋을 벤치마크로 사용
- MambaOut을 Mask R-CNN의 backbone으로 사용 (with ImageNet pretrained init weight)
- Standard 1x schedule (12 epoch training), input 이미지 Reshape, AdamW 사용
- PyTorch, mmdetection 활용, FP16, NVIDIA 4090 GPU 4개 사용
Results
- MambaOut은 일부 Mamba vision model보다 높은 성능을 보였지만, VMamba, LocalVMamba와 같은 최신 Mamba model에 미치지 못함
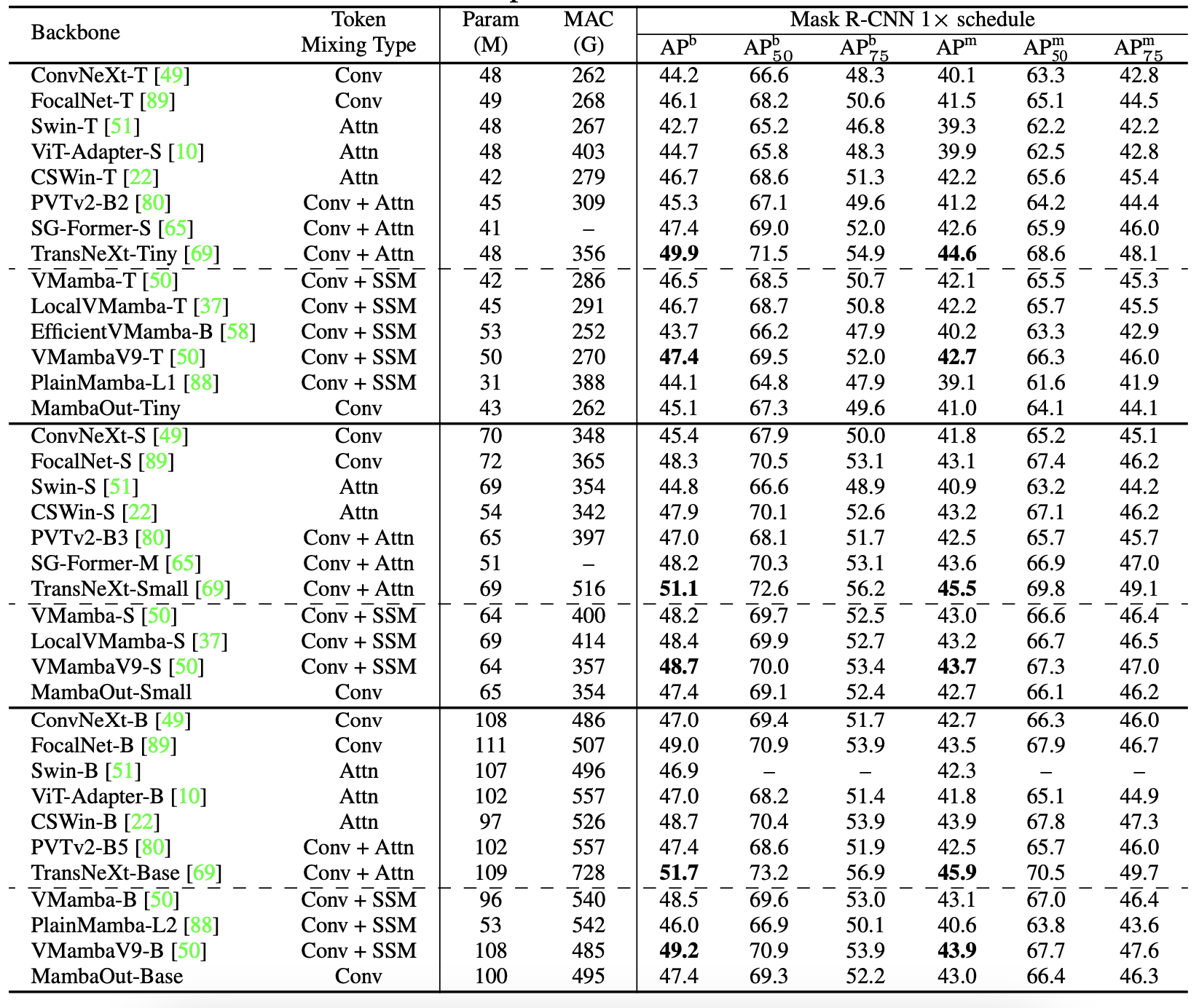
- 위 테이블에서, MambaOut-Tiny가 VMamba-T보다 1.4 APb, 1.1 APm 낮은 성능을 보임
- 이는 long sequence vision task에서 Mamba의 잠재력을 시사하며 가설 2를 뒷받침
- 그러나 Mamba vision model도 Conv+Attn hybrid model인 TransNeXt에 비해 상당한 성능 격차가 있음
- 향후 Mamba vision model이 다른 최신 model보다 우수한 detection 성능을 보여 효과를 입증할 필요가 있음
4.4. Semantic segmentation on ADE20K
Setup
- ADE20K는 150개 class를 포함하는 semantic segmentation 벤치마크 데이터셋
- MambaOut을 UperNet의 backbone으로 사용 (with ImageNet pretrained init weight)
- AdamW, lr 0.0001, batch size 16으로 160,000 iteration training
- PyTorch, mmsegmentation 활용, FP16, NVIDIA 4090 GPU 4개 사용
Results
- Semantic segmentation task에서의 성능 추세는 COCO object detection과 유사
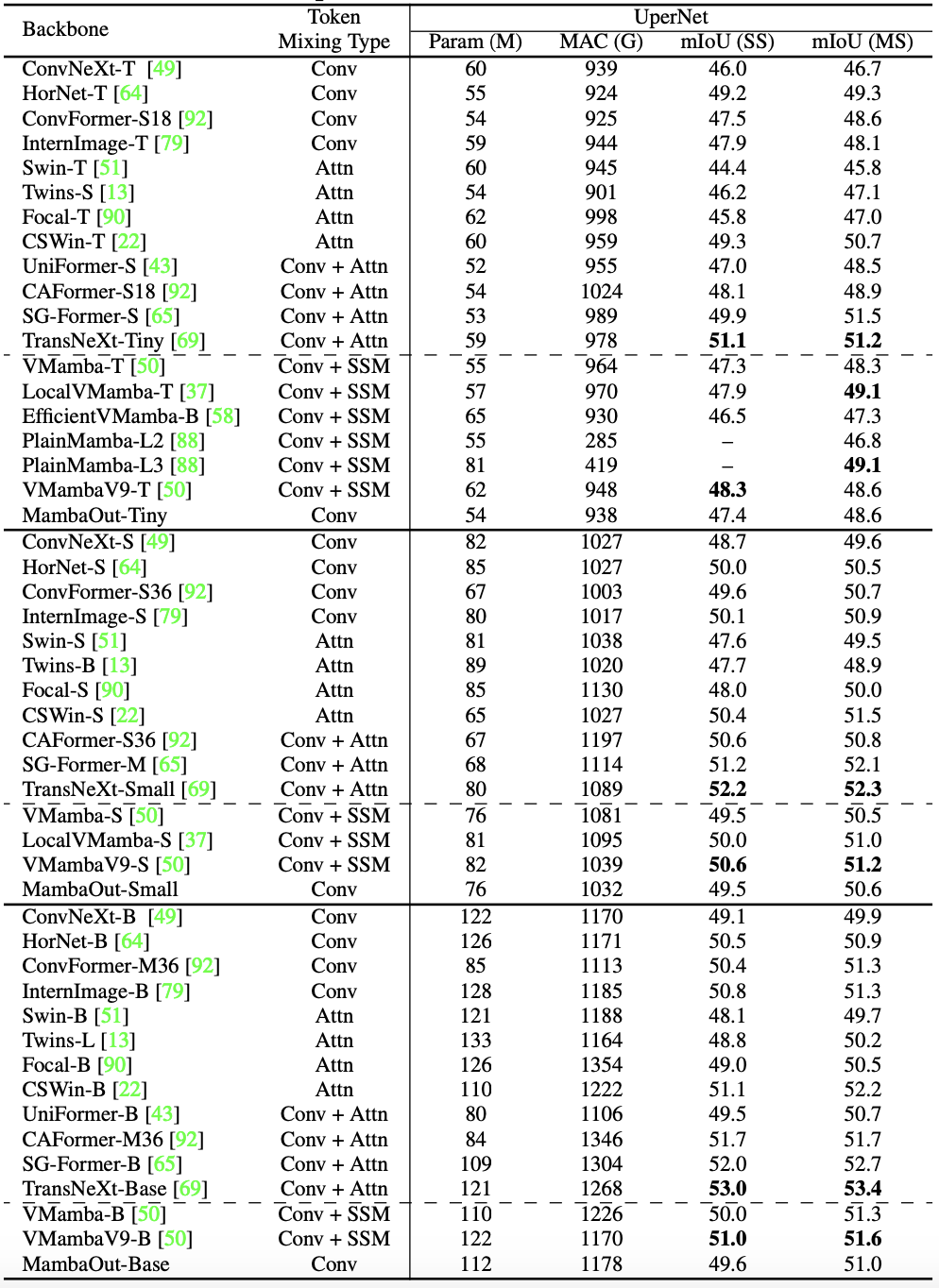
- MambaOut은 일부 Mamba vision model보다 우수하지만 최신 model에는 미치지 못함
- 위 테이블에서, LocalVMamba-T가 MambaOut-Tiny보다 0.5 mIoU 높은 성능을 보임
- 이는 가설 2를 경험적으로 뒷받침
- 또한 Mamba vision model은 Conv+Attn인 SG-Former, TransNeXt 등 hybrid model에 비해 여전히 성능 격차가 있음
- Mamba vision model은 long sequence model링 강점을 입증하기 위해 segmentation task에서 더 우수한 성능을 보여야 함
5. Conclusion
- 본 논문에서는 개념적으로 Mamba 메커니즘을 논의하고, long sequence와 autoregressive 특성을 지닌 task에 Mamba가 이상적임을 주장
- 이를 기준으로 일반적인 vision task를 분석한 결과, long sequence와 autoregressive 특성을 모두 만족하지 않는 ImageNet 분류에는 Mamba를 도입할 필요가 없다고 주장
- 하지만 long sequence 특성을 가진 detection 및 segmentation 에서는 Mamba의 잠재력을 더 탐구해 볼 가치가 있음
- 이를 실증적으로 입증하기 위해 Mamba의 핵심 token mixer인 SSM을 제외한 MambaOut model을 개발
- MambaOut은 ImageNet에서 기존 Mamba vision model보다 우수한 성능을 보였지만, 최신 Mamba model에 비해서는 성능 격차가 있어 주장을 뒷받침
- 본 연구에서는 컴퓨팅 자원 제약으로 vision task에 대해서만 Mamba 개념을 검증
- 향후에는 Mamba와 RNN 개념, 그리고 RNN과 transformer의 통합을 대규모 언어 model과 멀티모달 model에 적용하는 연구를 수행할 수 있을 것을 기대

AI Research Engineer