https://arxiv.org/abs/2401.12233
ICLR 2024

1. INTRODUCTION
- 기존 연구들에 따르면 Self-supervised learning (SSL) 모델도 supervised learning (SL) 모델과 마찬가지로 일부 training data를 기억할 수 있음을 발견
- SSL에서 memorization 된 data point는 전형적인 data보다 비전형적(atypica)인 data일 가능성이 높음
- 그러나 SSL에서 memorization 되는 data point는 SL에서와 상당히 다름
- SSL 모델이 data를 기억하는 이유는 다양한 downstream task에 대한 generalization 성능을 향상시키기 때문
- Memorization은 SSL 모델이 한 분포의 data에서 기억한 정보를 다른 downstream task 분포에 generalization하는 데 도움이 됨
- 이는 SSL에서 memorization이 다양한 downstream task에 대한 SSL의 성공에 기여한다는 것을 시사
Contributions
- SSL encoder에 대한 memorization인 SSLMem을 제안했는데, 이는 training method, 구체적인 training loss에 독립적이며 representation에서 직접적으로 작동
- SSLMem을 경험적으로 평가했고, SSL에서 다양한 아키텍처와 training method을 사용할 때 상당한 memorization이 있음을 발견. 특히 비전형적인 data point에서 그런 경향이 있음
- SSL에서 encoder의 memorization은 다양한 downstream data 분포와 task에 대한 generalization을 향상시킴
2. BACKGROUND AND RELATED WORK
- SSL은 label 없는 input을 유용한 representation으로 변환하여 다중 downstream task에 대한 sample 효율적인 학습을 가능케 하는 encoder 모델을 학습
- 최근 비전 영역에서 대량의 label 없는 data로부터 학습하기 위한 많은 방법들이 제안
- 본 연구는 SSL에서 Memorization에 대한 범용 definition을 제공하는 데 중점을 두고 있으므로, 세 가지 다른 학습 목표에 의존하는 다양한 접근 방식을 고려
Contrastive learning
- SimCLR로 시작되어, 동일 input의 augmentation view(positive pair)는 서로 가깝게, 다른 input(negative pair)은 서로 멀어지게 encoder를 학습
Non-contrastive learning
- 기반은 SimSiam에 의해 시작되었는데, negative sample이 필요 없이 encoder 붕괴를 방지할 수 있음을 보임
Masked autoencoding
- MAE는 비대칭(asymmetric) encoder-decoder 구조를 사용하여 input 이미지의 무작위로 masking 된 patch를 재구성(reconstruction)하도록 학습
- MAE의 차별화 요인은 input masking에 의존하는 반면, 다른 SSL encoder는 random crop 또는 color jitter 등 강력한 data augmentation에 더 많이 의존한다는 점
Membership Inference Attacks
- ML 모델이 학습 data에 대한 개인정보를 누출하는지 측정하는 표준 방식은 "Membership Inference Attacks"
- 여기서 공격자는 특정 data point가 주어진 모델을 학습시키는 데 사용되었는지 여부를 판단
- EncoderMI(Liu et al., 2021)는 학습 data point의 alignment score가 학습에 사용되지 않은 point보다 높다는 점을 관찰하여 encoder Membership을 탐지
Memorization
- Memorization은 학습 알고리즘과 신경망의 중요한 특성으로, SL에서 활발히 연구되어 옴
- Memorization을 정량화하는 기본 아이디어는 단일 학습 data point가 결과 모델의 예측에 미치는 영향에 따름
- 더 큰 영향력은 더 높은 수준의 memorization을 나타냄
- SL에서 memorization은 generalization 관련 특성이나 transfer learning 내 supervised downstream classifier에 중요한 것으로 나타났지만, SSL에 대해서는 연구되지 않음
- SSL에서 memorization을 고려한 유일한 task는 Déjà Vu memorization 개념을 제안
- SSL encoder가 학습 이미지의 foreground object와 특정 view(예: backround crop)를 연관시키는 정도를 정량화
3. TOWARDS FORMALIZING MEMORIZATION
- SSL에는 label이 없어 SL의 memorization definition을 직접 적용할 수 없으므로, SSL에 적합하고 특정 프레임워크에 독립적인 memorization을 새롭게 정의한 SSLMem을 제안
- 제안된 SSLMem은 모든 SSL 프레임워크에서 공통적인 data augmentation과 alignment 개념을 활용
- Data point의 다양한 augmentation view 간 representation alignment을 사용하여 memorization을 탐지
- Encoder f에 의한 data point의 alignment이 해당 point로 학습되지 않은 encoder g보다 현저히 높으면 f에 의해 높은 수준의 memorization으로 간주
- 이러한 직관을 형식화하여 SSL을 위한 SSLMem을 제안
3.1. PRELIMINARIES AND PROBLEM SETUP
- SSL training method 및 Memorization definition과 관련된 개념에 대한 공식 모델을 제시
- Encoder f는 SSL 알고리즘 A를 사용하여 random dataset S에서 학습
- 각 data point x에 대해 augmentation 집합 Aug(x)를 정의
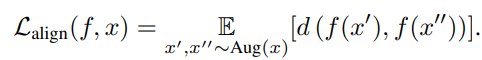
- 위 수식의 Alignment loss Lalign(f, x)은 x의 서로 다른 augmentation 간 representation의 거리로 측정
- SSL encoder의 표준 downstream task는 classification 이며, 이를 위해 linear layer Gf가 학습 (linear probing)
- Encoder f의 generalization error는 classifier Gf의 오류로 정의
- 모든 학습 data point에 대한 f의 낮은 alignment loss과 Gf의 downstream task 오류 간 주요 연결은 augmentation 집합의 중복에 기반
- 동일 클래스의 두 data point x1, x2는 augmentation 집합이 중복될 가능성이 높음
- Alignment loss가 감소하면 Aug(x1)과 Aug(x2) 간 차이가 줄어듦
- 이에 따라 d(f(x1), f(x2))도 삼각 부등식에 의해 감소하므로, Gf가 x1, x2에 동일한 클래스 label을 할당하기 쉬워짐
3.2. ALIGNMENT AND MEMORIZATION IN SSL
- SSL에서 Memorization definition은 SL의 leave-one-out Memorization definition를 따르지만, ground truth label(SSL에는 없음)을 중심으로 하는 대신 training data point의 alignment loss(1)에 기반
- Dataset S의 단일 data point x와 SSL 알고리즘 A를 사용하여 S, S\x에서 각각 학습된 encoder f, g에 대해 SSLMem을 사용한 Memorization score m(x)를 정의
- 여기서 Aug(x)의 집합뿐만 아니라 가능한 모든 encoder f, g로 구성된 두 가지 다른 function 클래스에 대한 기대값도 고려
- 직관적으로, 본 눈문에서 제안한 definition은 Aug(x)에서 f와 g 간 representation의 alignment 변화를 정량화
- Memorization score는 x가 학습에 사용되었는지 여부에 따라 f와 g 사이에 alignment 변화가 크면 x에 대해 높아짐
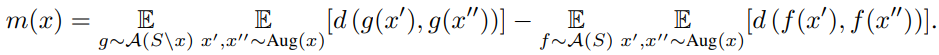
- 위 수식을 통해 x가 학습 data에 포함되었는지 여부에 따라 alignment loss가 어떻게 변화하는지 측정할 수 있음
- 차이가 클수록 x에 대한 memorization 정도가 높다고 판단
- Alignment과 memorization은 다른 개념. 전자는 주어진 encoder의 직접적인 특성이며, 후자는 다른 encoder 계열 간 상대적 비교 결과
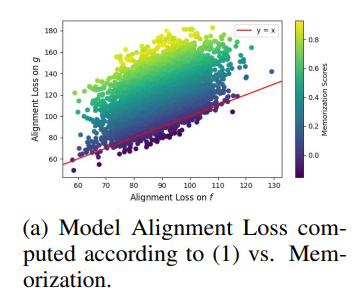
- 낮은 alignment loss가 반드시 높은 memorization을 의미하지는 않음 (위 그림 하단 왼쪽 모서리 참조)
- g에 비해 f가 x에 대해 낮은 alignment loss을 가질 수 있지만 memorization score는 낮을 수 있음
- g보다 f에 대한 term을 뺌으로써 양의 memorization score를 얻으며, 일반적으로 x없이 학습된 g가 f보다 x에 대한 alignment loss가 높기 때문
4. EXPERIMENTAL EVALUATION
- SSLMem memorization score를 실험적으로 근사하기 위해 다섯 가지 random augmentation을 평균화
- Training data를 세 개의 분리된 파티션으로 나눔:
- 80%는 공유 training data Ss로 사용 (40000개 sample, CIFAR10 기준)
- 10%는 memorization 후보 Sc로 사용 (5000개 sample, CIFAR10 기준)
- 나머지 10%는 독립 세트 SI로 사용 (5000개 sample, CIFAR10 기준)
- 추가로 testset에서 5000개의 sample을 SE로 사용하여 f나 g의 학습에 사용되지 않음
- Encoder f는 SS ∪ SC로 학습되고, g는 SS ∪ SI로 학습
- SC의 memorization을 측정하고 평균 memorization score를 집계하여 report
- CIFAR10, SVHN, STL10은 각각 50000개의 training sample, ImageNet은 100000개의 training sample을 사용
- 모든 실험에서 batch size는 1024, CIFAR10, SVHN, STL10은 600 epoch, ImageNet은 300 epoch 동안 학습
- ℓ2 distance를 사용하여 representation alignment 측정
- Memorization score를 -1에서 1 사이로 normalization하여 다른 SSL 방법 간 비교 가능하게 함
- 모든 실험은 세 개의 독립적인 seed로 반복하고 평균 SSLMem memorization와 표준 편차를 계산
4.1. MEMORIZATION OVER DIFFERENT ARCHITECTURES, SSL METHODS AND DATASETS
- 다양한 encoder architecture, SSL training method, dataset에 따른 memorization을 평가

- 위 테이블에서, downstream task 정확도와 평균 기억 score 사이에 상관관계가 있음을 보여줌
- CIFAR10, SVHN, STL10에서 SimCLR, ImageNet에서 DINO가 가장 높은 정확도와 가장 큰 평균 SSLMem score를 기록
- MAE는 모든 data셋에서 가장 낮은 score를 기록
- 전반적으로 더 큰 평균 SSLMem memorization는 더 우수한 downstream 성능과 연관
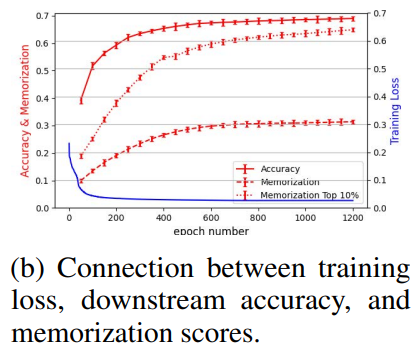
- 위 그림에서 alignment와 정확도는 별개의 지표임을 보여줌
- Training loss와 정확도는 몇 백 epoch 후에 평탄해지지만, memorization은 학습이 길어질수록 계속 증가
- 이는 전체 후보 세트와 특히 가장 많이 기억된 10% sample에서 두드러짐
- 더 많은 epoch은 더 높은 memorization을 가져오며, 이는 학습 역학 측면에서 정확도와 memorization의 측정을 분리
4.2. INSIGHTS ON THE MEMORIZATION SCORE
- 아래 그림의 결과는 memorization score가 예상대로 동작함을 보여줌
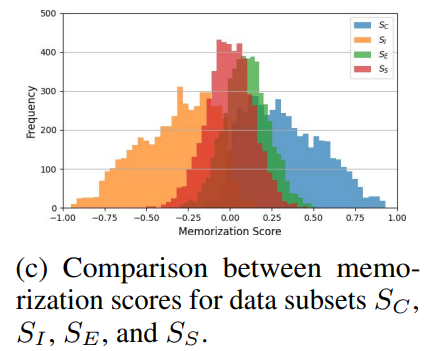
- Encoder f의 학습에 사용된 후보 sample SC는 memorization score가 0 이상으로 크게 증가
- Encoder g의 학습에 사용된 독립 sample SI는 memorization score가 0 이하로 크게 감소
- 학습에 사용되지 않은 공유 sample SS와 추가 data SE는 0 근처에 머무름
- SC(SI) data point는 SS와 SE보다 통계적으로 유의미하게 높은(낮은) SSLMem memorization score를 가짐
- T-test를 통해 5000개의 memorization score로 각 data subset의 평균을 테스트
- SC: 0.30723
- SS: -0.00136
- SE: 0.09958
- SI: -0.31182
- 귀무 가설 H0: m(SC) ≤ m(SS)를 테스트하고, p-값 < 0.01로 H0를 기각하여 SC의 memorization score가 SS보다 유의미하게 높음을 확인
- 통계적 테스트 결과는 SC(SI)가 SS와 SE보다 더 많이(적게) 기억된다는 주장을 지지
- SE와 SS의 memorization score는 0 근처에 피크를 가짐
- SE와 SS의 평균 score 차이는 SE data point는 f나 g의 학습에 사용되지 않은 반면, SS data point는 둘 다 학습에 사용되었기 때문
4.3. MEMORIZED DATA POINTS
- Data point의 memorization 유형을 분석
- Figure 1에서 SL과 유사하게 비정형 예제가 표준 data point보다 더 높은 memorization을 경험함을 시각적으로 보여줌
- Figure 9와 Table 13 (부록 B.4)에 따르면 SSL과 SL은 가장 높은 memorization score를 부여하는 data point에서 눈에 띄게 다름
- 동일한 training method이나 encoder 아키텍처를 공유하는 SSL 설정은 가장 일관
4.4. MEMORIZATION IN SSL IS REQUIRED FOR DOWNSTREAM GENERALIZATION
Classification
- Memorization이 downstream generalization에 미치는 영향을 분석하기 위해 encoder의 training data에서 가장 많이 기억된 data point를 제거하고 linear probing 정확도를 평가
- CIFAR10 training data에서 서로 다른 25k data point로 ViT-tiny 아키텍처를 사용하여 MAE encoder f와 g를 학습
- Encoder f의 memorization score를 측정하고, 가장 높은 memorization score를 가진 [500, 1k, 2k, 4k, 8k, 16k] data point를 제거
- 임의로 선택한 [500, 1k, 2k, 4k, 8k, 16k] data point를 제거한 경우와 비교하여 여러 downstream task에서 linear probing 정확도를 평가
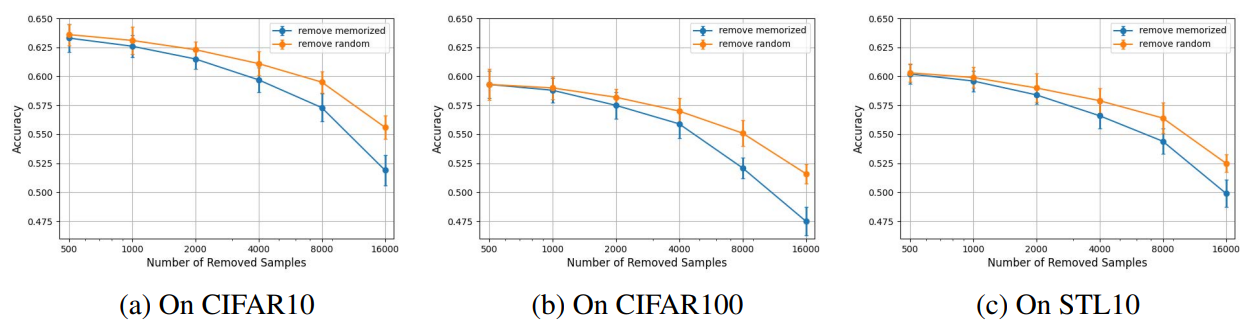
- 위 그림에서처럼, 기억된 data point를 제거하는 것이 임의의 data point를 제거하는 것보다 downstream 정확도에 더 큰 영향을 미침
- 이 경향은 동일한 data셋(CIFAR10)뿐만 아니라 다른 분포(STL10) 또는 다른 클래스 수(CIFAR100)를 가진 downstream task에서도 나타남
Semantic Segmentation
- ImageNet에서 MAE로 ViT-base를 pre-training하고, memorization을 평가한 후 encoder의 pre-training data에서 가장 많이 memorize 된 [10k, 20k] data point와 임의의 data point를 제거
- 결과 encoder를 ADE20K data셋에서 UperNet으로 end-to-end fine tuning
- ImageNet에서 linear probing을 통해 fine tuning된 encoder의 downstream 정확도와 mIoU로 semantic segmentation 성능을 측정
- Memorized sample을 제거하는 것이 임의의 sample을 제거하는 것보다 semantic segmentation의 downstream 성능에 더 큰 영향을 미침
Core Result
- SSL에서 memorization과 다양한 downstream task 성능 간의 상호 작용은 encoder의 generalization에 중요한 결과
- Alignment limiting을 통한 학습 중 memorization와 downstream 정확도에 미치는 영향을 조사
- Alignment limiting을 하면 memorization score가 감소하고 downstream 정확도도 감소
- 이 alignment limiting을 구현하기 위해 학습 중 loss function에 normalization term을 추가
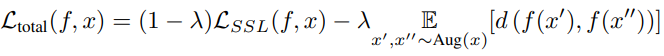
- Additional term은 data point와 그 augmentation 세트의 representation이 너무 가까워지는 것을 직접적으로 패널티를 줌
- Normalization 강도 λ는 alignment 강도를 조절하며, 값이 작을수록 약한 normalization를 나타냄
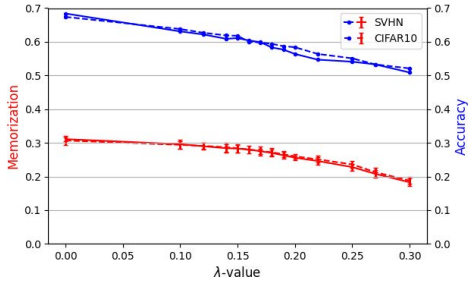
- 위 그림에서 처럼, λ 값이 증가할수록 모델 memorization이 감소하고, downstream 정확도도 감소
- 이전 연구 결과와 일치하게 더 나은 alignment이 downstream task에서 더 나은 generalization을 가능하게 함을 보여줌
- Memorization limiting이 encoder 성능에 부정적인 영향을 미침을 강조
4.5. COMPARISON TO PRIOR WORK
- Dej́a Vu memorization와 본 논문의 memorization score는 다른 현상을 포착하고 각기 다른 방식으로 memorization을 측정
- Dej́a Vu memorization: label 일관성 기반, 기억된 data point 비율 측정
본 논문에서의 방법
Data point별 memorization score 측정, 후보들에 대한 평균 score 계산
- 두 memorization score가 CIFAR10에서 ImageNet보다 높음
- CIFAR10은 차원이 낮고 training data가 적어 memorization이 더 쉬움
MAE encoder에 대한 두 score의 차이
- Dej́a Vu: MAE에 대해 높은 score
- SSLMem: MAE에 대해 낮은 score
- MAE의 학습 방식(patch masking)으로 인한 차이 발생
- 특정 augmentation은 SSLMem에 유의미한 영향을 미치지 않음
4.6. DIFFERENTIAL PRIVACY
- Differential Privacy (Dwork, 2006)는 개별 data point가 전체 dataset 분석에 미치는 영향을 최소화하는 수학적 보호를 제공
- DP-SGD 알고리즘은 다양한 SSL 패러다임과의 호환성이 제한적
- 최근에는 MAE encoder에 대한 차등적 개인 정보 보호 학습 프레임워크가 제안
- 이 연구에서는 Yu 등(2023)의 프레임워크를 사용하여 SSL encoder를 학습
- Differential Privacy는 memorization을 감소시키지만 동시에 downstream 정확도를 크게 감소시킴
5. CONCLUSION
- SSL은 풍부한 unlabeled data를 활용하여 고품질의 feature extractor를 생성할 수 있기 때문에 encoder 학습의 주요 패러다임으로 부상
- 그러나 self-supervised encoder의 memorization 속성은 이전에 탐구되지 않았음
- Label이 없기 때문에 SL에서 흔히 수행되는 memorization의 체계적 평가를 이전에 수행할 수 없었음
- 본 논문에서는 SSL에서의 encoder memorization을 분석하여 이 간극을 메움
- 먼저 SSL 방법에서 자주 사용되는 augmentation과 positive pair의 alignment를 기반으로 memorization을 정의
- SSLMem 정의는 SL의 label 부재를 반영하며, 다양한 encoder 아키텍처와 SSL 학습 알고리즘에 걸쳐 generalization되며, 어떠한 downstream task에도 독립적
- 중요한 점은 self-supervised encoder가 training data point를 기억한다는 것을 증명
- 더 나아가, 우리는 memorization이 다양한 downstream task에서 generalization을 향상시키는 것을 경험적으로 보여줌
- 이는 memorization을 self-supervised feature 학습의 주요 속성으로 확립

AI Research Engineer