https://arxiv.org/abs/2404.16030
1. Introduction
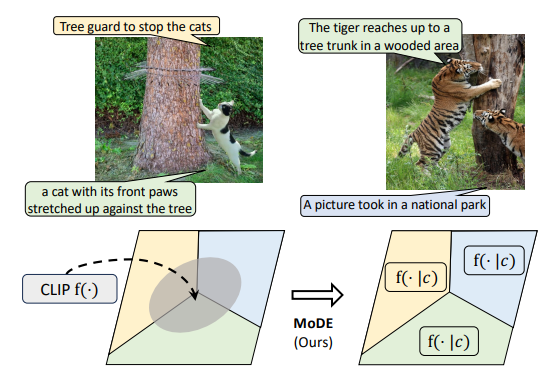
- CLIP (Contrastive Language-Image Pretraining)은 다양한 downstream task에 전이 가능한 vision-language representation을 학습
- CLIP, OpenCLIP, Meta-CLIP은 대규모 web crawling image-caption pair을 사용하여 학습
- 각 image에 대해, pairing 된 caption은 positive sample로, 다른 모든 image의 caption은 negative sample로 간주
Contrastive Vision-Language Representation
- 성공 요소는 quality 높은 negative sample을 만드는 데 있음
- 단일 image는 여러 의미를 가진 text로 설명될 수 있음
- 같은 batch에서 image-caption pair가 sampling될 때 다른 image의 caption은 false negative sample이 될 수 있음
- 이 때, 'Hard negatives'를 포함하는 것이 성능 향상에 도움이 됨
Mixture of Data Experts (MoDE):
- MoDE는 clustering을 통해 false negative sample을 분리하고 유사한 의미를 가진 pair를 그룹화
MoDE는 아래 두 단계로 구성
1) 학습 데이터를 caption에 따라 여러 disjoint subset으로 clustering하여 각 cluster를 사용해 모델을 학습
2) Downstream task에 적용될 때, 클래스 이름을 각 데이터 cluster의 중심과 비교하여 어느 data expert가 활성화될지 결정. 최종적으로, 가장 높은 similarity을 가진 클래스가 classification 결과로 출력
Empirical Performance
- MoDE는 여러 표준 벤치마크에서 SOTA vision-language 모델보다 우수한 성능을 보임
- image classification에서 +3.7%
- COCO 데이터셋에서 image-text retrieval에서 +3.3%, text-image retrieval에서 +2.7%
- MoDE의 우수성은 개별 data expert 모델의 더 나은 학습 때문
- Cluster 내 sample이 의미론적으로 유사하지만 본래 pair가 아닌 image를 사용할 때 더 어려운 negative sample이 됨
- MoDE는 수십억 개의 image-caption pair을 사용할 수 있어 대규모 학습에 적합
Benefits of MoDE
- 다양한 ViT 모델에서, OpenAI CLIP 및 OpenCLIP의 단일 모델보다 더 적은 (<35%) training cost로 더 나은 성능을 보임
Contributions
- 대규모 web crawling image-caption pair에서 negative sample의 품질과 false negative의 noise를 조사
- MoDE framework를 제안하여 CLIP data expert 시스템을 clustering 및 adaptive ensemble로 학습
- 낮은 training cost로 zero-shot transfer 벤치마크에서의 성능 향상을 입증
2. Related Work
Contrastive Language Image Pretraining (CLIP)
- 대규모 데이터에서 강력하고 transfer 가능한 visual representation을 학습
- 데이터 curation, image masking, simple caption 등을 통해 메모리 요구를 줄임
- Negative sample에 대한 연구가 주로 image에 집중되고 caption의 noise는 간과됨
Mixture-of-Experts (MoE)
- Sub model과 routing module을 학습
- Deep Mixture of Expert를 통해 레이어 출력을 weighted sum으로 soft하게 ensemble
- 모든 expert model을 동일한 데이터로 학습하여 높은 training cost 초래
- MoDE는 task meta data를 통해 task-level adaptation을 generalization
Inference-Time Adaptation
- Pre-training 된 모델을 새로운 task에 빠르고 효과적으로 adaptation
- Transductive learning이 초기 연구, test-time training이 각 입력에 대한 개별 모델 생성
Transductive learning이란?
- label이 없는 test data를 사용하여 모델을 업데이트
- 이는 test data에 대해 더 나은 성능을 얻기 위해, test data의 정보를 최대한 활용하는 것
- 이러한 방식은 새로운 데이터 분포에 빠르게 적응할 수 있지만, overfitting이 발생 할 수도 있음
- Meta-learning은 별도의 meta-learner를 도입하여 각 task에 adaptation
- MoDE는 annotation이나 parameter 업데이트 없이 추론 시 task adaptation 제공
3. CLIP Data Experts
- Contrastive image-language pre-training에서, 모델은 visual contents를 설명하는 caption과 정확히 일치하도록 학습됨
- 하나의 cluster에서 각 CLIP data expert를 학습하여 mini batch 내의 false negatives 수를 줄이고 hard negatives를 증가시킴
- 이를 통해 web crawling된 image-caption pair의 noise를 줄이고 모델 학습을 더 효과적으로 만듦
- MoDE framework는 caption을 기반으로 clustering을 수행하여 data expert의 조건을 결정
- Unsupervised clustering을 통해 각 data expert를 학습시키며, 다른 cluster의 noise에 덜 민감하게 만듦
- Evaluation 에서는 task metadata와 조건의 상관관계를 측정하여 여러 data experts가 공동으로 출력을 결정
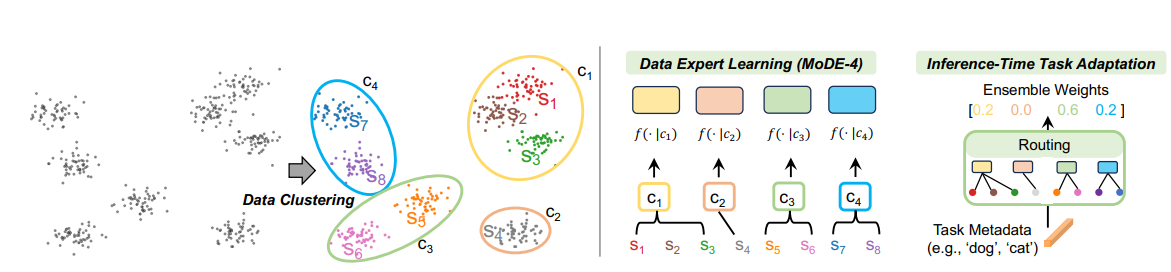
- 위 그림에서 볼 수 있듯이, caption을 통한 두 단계 clustering을 수행하여 data experts의 조건을 결정
- cluster는 fine-grained과 coarse-grained로 나뉘며, 각 cluster는 독립적으로 학습됨
- 추론 시, task metadata와 cluster centers의 similarity을 사용하여 data experts의 routing을 결정
- 합리적인 training cost를 유지하기 위해, 모든 data experts는 clustering 없이 전체 데이터로 부분적으로 학습된 모델로 초기화될 수 있음
3.1. Background: Vanilla CLIP Training
- CLIP은 vision과 language 인코더를 학습하고, joint vision-language embedding space를 사용
- 동일한 batch 내에서 positive pairs와 negative samples를 대조하여 image와 caption의 similarity을 모델링
- 단일 CLIP 모델 대신, 다양한 조건에 따라 독립적으로 CLIP data expert 모델을 학습하는 것을 제안
3.2. Clustering
- Data expert의 조건을 공식화하고, pre-training set에서 clustering을 통해 자동으로 조건을 발견
- 조건은 대표적이고, 적절한 수여야 하며, 이를 통해 신뢰할 수 있는 data expert 선택이 가능해짐
- Fine-grained clustering과 coarse-grained clustering의 두 단계를 통해 대표적인 cluster를 식별하고 그룹화
- 이를 통해 조건을 상징하는 fine-grained cluster centers를 사용하여 더 적은 수의 data expert로 효과적으로 학습할 수 있음
Step 1: Fine-grained Clustering
- 대규모 pre-training 데이터로 인해 모든 데이터를 대상으로 K-means를 학습하는 것은 비효율적임
- 대신, pre-training set에서 일부 sample을 무작위로 추출한 후 K-means 학습을 수행
- 이렇게 학습된 cluster 중심 set 는 각 cluster가 일관된 의미 정보를 잘 표현하도록 구성
Step 2: Coarse-grained Clustering
- Data expert의 학습/추론을 효율적으로 할당하기 위해, fine-grained cluster 중심를 대상으로 두 번째 K-means clustering을 수행
- 각 coarse-grained cluster 중심 는 data expert의 조건이 됨
- Data expert의 수 은 fine-grained cluster의 수 보다 훨씬 적음
- 각 data expert는 할당된 fine-grained cluster 집합 로부터 학습
3.3. Data Experts Training
-
각 data expert에 대한 학습 데이터를 공식화
-
각 fine-grained cluster 에 할당된 데이터를 수집하여 해당 cluster 중심에 가장 가까운 데이터 sample를 선택
여기서 와 는 각각 학습 sample 와 fine-grained cluster center 의 embedding을 나타냄
-
각 data expert 는 해당 cluster의 데이터 를 사용하여 학습
3.4. Inference Time Task-Adaptation
- Framework는 cluster를 기반으로 data experts를 학습시키며, 추론 시 다양한 data experts를 다양한 downstream tasks에 adaptation 시킴
- 간단한 접근법을 사용하여 주어진 task metadata에 따라 data experts를 효율적으로 routing
- CLIP data experts의 출력을 weighted sum으로 구성하여, 주어진 evaluation task 에 대해 data experts의 출력을 ensemble
Zero-Shot Classification
- 정확한 routing을 위해 fine-grained cluster centers를 사용하여 task을 data experts에게 routing
- 클래스 이름 을 meta data로 취급하고, 클래스와 data experts 간의 similarity matrix 를 정의여기서 는 similarity을 강화하는 온도(temperature)를 나타냄.
- Similarity matrix 는 클래스 의 embedding 과 fine-grained cluster center 의 similarity로 구성
Zero-Shot Retrieval
- Text retrieval과 image retrieval로 구성
- Text retrieval에서는 대규모 corpus 에서 text 를 retrieval 하기 위해 를 meta data로 사용하여 similarity matrix 를 만듦여기서 각 항목 는 다음과 같이 계산됨여기서 는 text 의 embedding을 나타냄
- Image retrieval에서는 text 를 독립된 task 로 처리하여 data experts를 routing
4. Experiment
4.1. Data
- MetaCLIP에서 수집된 데이터셋을 사용하여 image-caption pair에 대한 실험을 수행
- 두 가지 규모로 실험
- 400M (OpenAI CLIP과 유사)
- 2.5B (MoDE 확장)
- 모든 image는 face-blurring 및 de-duplication를 통해 전처리
4.2. Training Setup
Clustering Setup
- SimCSE를 사용하여 caption의 embedding을 추출하고, 두 단계의 균형 잡힌 K-means를 사용하여 clustering 수행
fine-grained cluster 수 (m = 1024)
Data Experts Training Setup
- OpenAI CLIP의 hyperparameter를 따름
- 32,768의 global batch size로 3가지 scale(ViT-B/32, ViT-B/16, ViT-L/14)에서 MoDE 학습
- ViT-B/32와 ViT-B/16: 64개의 Nvidia V100 GPUs, 각 GPU batch size 512
- ViT-L/14: 128개의 GPUs, 각 GPU batch size 256
- 부분적으로 학습된 MetaCLIP 모델을 seed 모델로 사용하여 27번째 epoch 부터 MoDE 학습 시작
4.3. Evaluation
Zero-Shot Image Classification
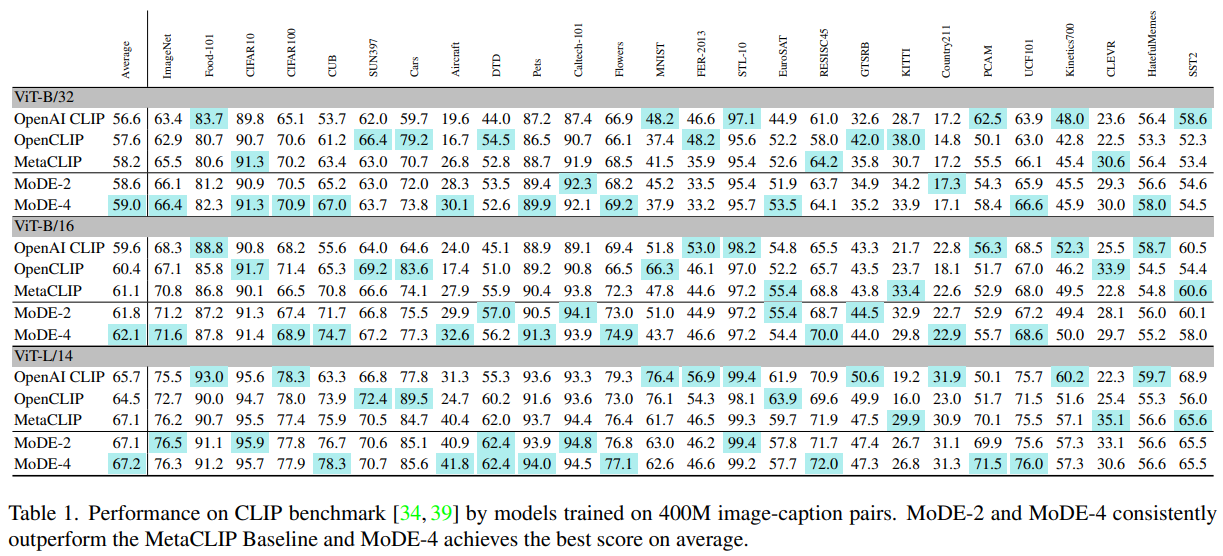
- 400M scale 데이터셋에서 성능 비교, MoDE는 data expert 수를 늘리면 성능이 향상
- MoDE-2와 MoDE-4는 MetaCLIP Baseline을 일관되게 능가하며, 평균적으로 가장 높은 성능을 보임
- MoDE-4는 대부분의 평가 지표에서 최고 성능을 달성
- MoDE는 모델 scale과 데이터 scale 전반에 걸쳐 일관된 성능 향상을 보여줌
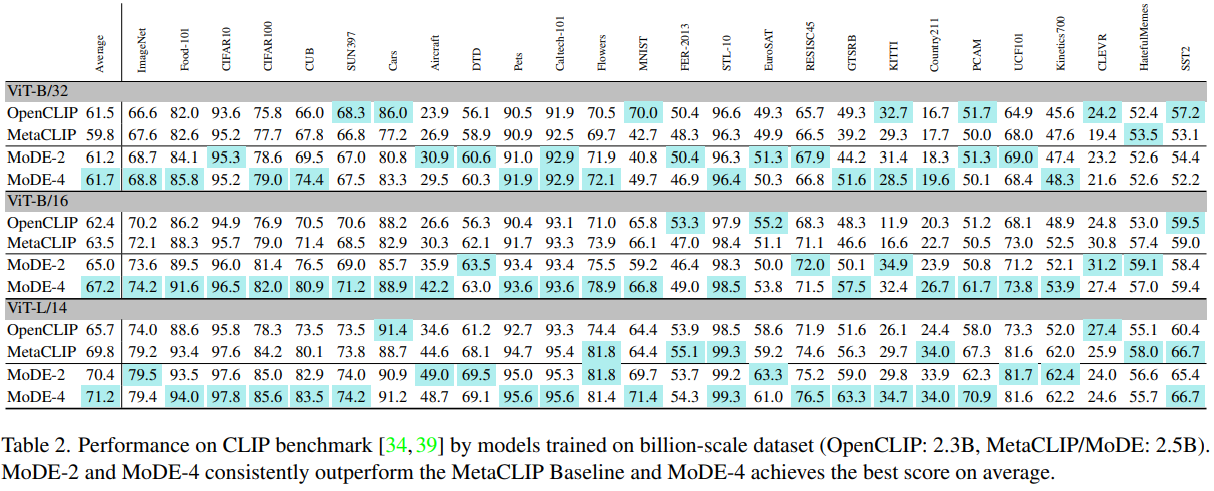
- 2.5B image-text pair에서 MoDE의 확장성을 연구
- MetaCLIP과 비교하여 data expert 학습이 더 나은 성능을 보임
Zero-Shot Robustness
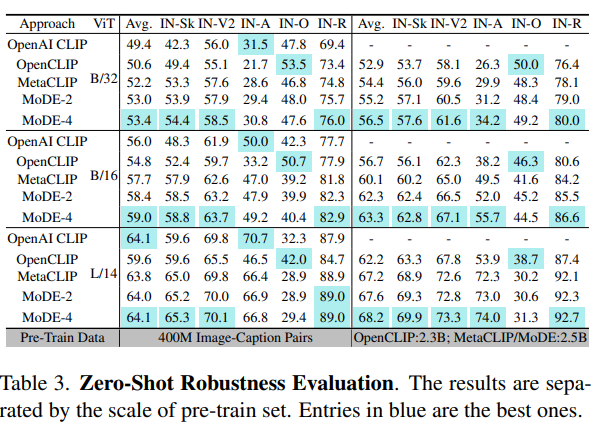
- 다양한 ImageNet variation에서 일관된 성능 향상을 보여줌
- Data expert 수를 늘리면 성능이 continual 하게 향상
Zero-Shot Retrieval
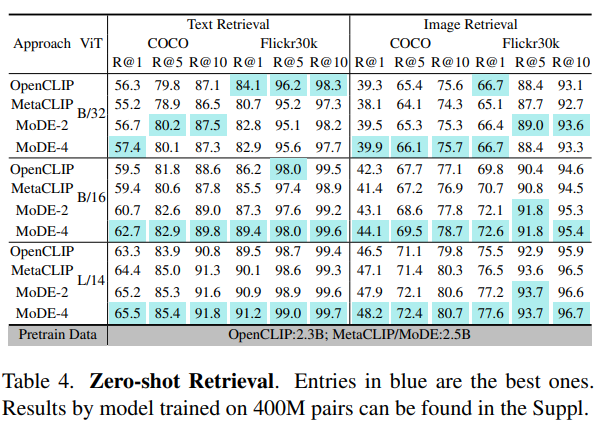
- COCO 및 Flickr30k 데이터셋에서 image/text retrieval
- Data expert 학습이 모든 모델 크기에서 일관되게 성능을 향상
5. Discussion
5.1. Effectiveness of Clustering
- Clustering의 중요성을 분석
- MoDE는 다양한 cluster에서 학습된 data experts를 ensemble하여 사용
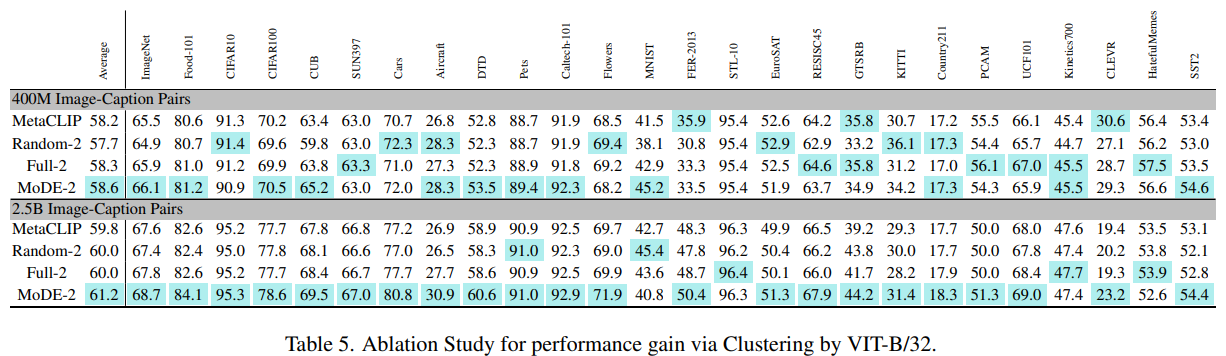
- 위 테이블에서, clustering 없이 모델을 ensemble할 경우 성능이 저하
- Random으로 데이터를 두 부분으로 나누어 각 부분에 대해 data expert를 학습(Rand-2)했을 때, clustering이 없는 경우 성능이 더 낮아짐
5.2. Clustering Strategy
- MoDE는 Two stage clustering 전략을 사용하여 fine-grained cluster 중심 를 발견
- Single stage clustering 대안과 비교하여, Two stage clustering이 더 나은 성능을 보임
- 첫 stage에서 fine-grained cluster 수 을 변경하여 실험한 결과, 아래 테이블에서 볼 수 있듯이 이 증가할수록 성능이 향상
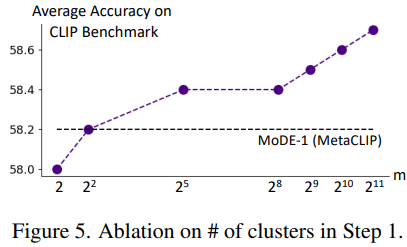
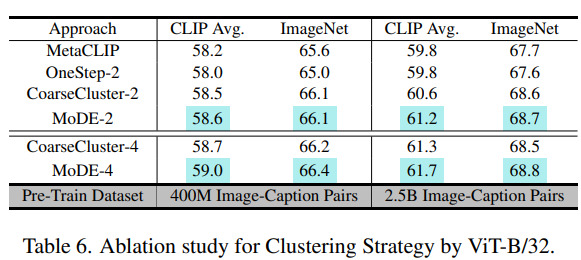
- Coarse-grained cluster 중심을 ensemble weight 결정에 사용했을 때 성능 향상은 미미했음
5.3. Embeddings for Clustering
- Language embedding 사용의 중요성을 검증
- SimCSE language embedding 외에도 여러 embedding을 clustering에 사용하여 비교
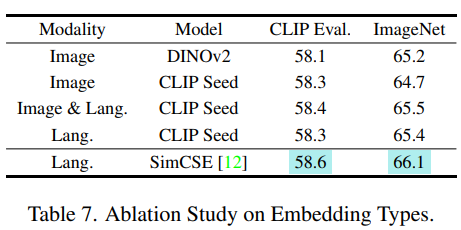
- Image embedding을 사용한 경우, 모델 성능이 떨어짐
- Seed 모델에서 language embedding을 사용하는 경우, 성능 향상이 미미함

- SimCSE text embedding을 사용한 경우, high-level semantic correlation을 이해할 수 있어 더 나은 성능을 보임
5.4. Application of Vision Encoders
- Zero-shot generalization 외에도, vision encoders set를 downstream application에서 직접 ensemble 할 수 있음
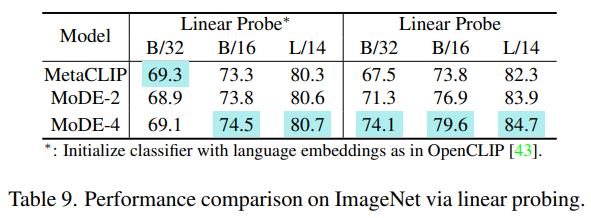
- 모든 vision encoders는 동일한 가중치를 가지며, cluster 중심을 필요로 하지 않음
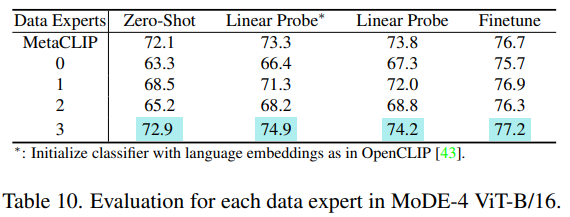
- ImageNet classification를 위해 ensemble된 인코더 출력을 사용
- MoDE는 MetaCLIP Baseline 대비 일관된 성능 향상을 달성
5.5. Training Priority of Data Experts
- Data expert의 학습 순위를 정하는 것이 중요
- Coarse-level cluster 조건을 기반으로 학습 우선순위를 정함
- Fine-grained cluster의 다양성을 참고하여 가장 큰 범위를 가진 조건부터 모델을 학습
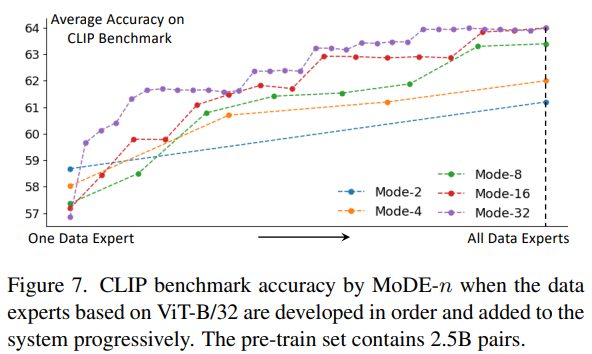
-
Ex. ViT-B/32 data expert의 수를 2에서 32까지 다양하게 설정하고, CLIP 벤치마크에서의 성능을 평가
-
Data expert를 점진적으로 포함하면 성능이 계속 향상
-
모든 데이터를 동시에 학습하는 대신, MoDE는 새로운 data expert를 점진적으로 통합하여 동적 업데이트를 가능하게 함
-
이는 online 및 continual training에 유용
-
새로운 데이터가 도입될 때, 기존 시스템에 통합하여 효과적으로 적응할 수 있음
6. Conclusion
- CLIP의 성공은 양질의 negative samples에 의존
- Web crawling pair의 false negative noise가 학습 효과를 저하
- MoDE는 data expert 그룹을 비동기적으로 학습하여 이러한 문제를 해결
- 각 data expert는 유의미한 fine-grained cluster에서 학습
- MoDE는 OpenCLIP 및 OpenAI CLIP을 능가하며, 35% 미만의 training cost로 표준 벤치마크에서 우수한 성능을 보임
- 향후 MoDE를 generative models에 적용 계획
