https://arxiv.org/abs/2305.00729
ICLR 2023
ABSTRACT
-
이 논문에서는 contrastive learning (CL)과 masked image modeling (MIM)이 표현과 downstream task의 성능에서 어떻게 그리고 왜 다른지에 대한 비교 연구를 제시
-
특히, self-supervised Vision Transformers (ViTs)가 다음과 같은 특성을 가지고 있음을 보여줌
(1) CL은 MIM보다 더 긴 범위의 전역 패턴, 특히 ViT 아키텍처의 후반부에서 물체의 모양과 같은 것을 캡처하기 위해 self attention을 학습
(2) CL은 표현의 저주파 신호를 활용하지만, MIM은 고주파 신호를 활용. 저주파와 고주파 정보는 각각 모양과 질감을 나타내므로, CL은 더 모양 중심적이고 MIM은 더 질감 중심적
(3) CL은 후반부에서 중요한 역할을 하며, MIM은 주로 초기 레이어에 중점을 둠 -
이러한 분석을 통해 CL과 MIM이 서로 보완될 수 있으며, 심지어 가장 간단한 조화로운 조화도 두 방법의 장점을 활용하는 데 도움이 될 수 있다는 것을 관찰
1 INTRODUCTION
- 최근까지 contrastive learning (CL) (He et al, 2020; Chen et al, 2020a;b; 2021)은 가장 인기 있는 self-supervised learning 방법 중 하나였음
- CL은 두 가지 무작위 뷰의 불변한 의미론(invariant semantics)을 학습하기 위해 positive sample에 대한 표현의 전역적인 투영을 유사하게 만들고, negative sample에 대해서는 유사하지 않도록 하는 것을 목표로 함
- 따라서 CL은 "이미지 수준"의 self-supervised learning 접근 방식으로 볼 수 있음
- masked image modeling (MIM) (Bao et al, 2022; Xie et al, 2022b; He et al, 2022)은 Vision Transformers 시대에 CL의 강력한 경쟁자로 부상
- Downstream task에서의 인상적인 성과를 보여주고 있음
- MIM은 mask 된 입력 패치의 올바른 semantic을 재구성함으로써 ViTs를 학습시킴
- CL과 달리 MIM은 패치 토큰의 semantic을 학습하며, 이는 "토큰 수준"의 self-supervised learning 접근 방식으로 볼 수 있음
- MIM은 fine-tuning 정확도에서 CL을 능가하므로, CL보다 효과적인 사전 학습 방법으로 보일 수 있음
- 그러나 CL이 MIM보다 linear probing 정확도에서 우세함을 볼 때, 다른 추세가 관찰됨

2. How do self-attentions behave?
- CL이 주로 전역적인 관계를 포착하고, 반면 MIM은 지역적인 관계를 포착한다는 것을 발견
- 이는 CL의 표현이 MIM의 것보다 더 많은 전역적인 패턴을 포함한다는 것을 의미
- 예를 들어, 물체 모양과 같은 전역적인 패턴이 포함
- 이러한 특성은 한편으로는 CL이 물체를 인식하고 이미지를 구별하는 데 도움이 됨
- 그러나 반대로, 이것은 CL이 지역 정보를 보존하는 데 어려움을 겪을 수 있다는 것을 시사
- 특히, CL의 self-attention을 후반 레이어에서 모든 쿼리 토큰과 헤드에 대해 동질적인 어텐션 맵으로 붕괴하는 것을 관찰
- 이러한 경우 대부분의 self-attention 맵이 물체 경계에 집중되므로 물체 모양을 포착할 수 있지만, 토큰 간 상호 작용 다양성을 상실할 수 있음
- 결과적으로 CL과 MIM은 각각 다른 작업에서 이점을 가지고 있음
- CL은 작은 모델로 linear probing과 classification task에 적합
- 반면 MIM은 큰 모델로 fine tuning 및 dense prediction task에서 CL을 능가

- 왼쪽 (MoCo): CL의 self-attention은 전역적인 패턴과 물체 모양을 포착. 그러나 모든 어텐션 맵은 쿼리 토큰에 관계없이 동일한 모양 정보를 포착
- 오른쪽 (SimMIM): MIM의 self-attention은 지역적인 패턴을 포착하며 쿼리와 관련이 있음
1) CL mainly captures global relationships
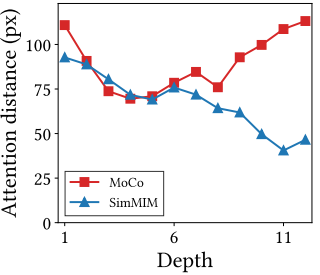
- attention distance는 쿼리 토큰과 키 토큰 간의 평균 거리를 고려하여 self-attention 가중치를 고려한 것으로, 개념적으로 CNNs의 receptive field 크기에 해당
- CL (MoCo)의 attention distance가 MIM (SimMIM)의 attention distance보다 특히 후반 레이어에서 상당히 높은 것을 보여줌
- CL은 ViTs가 이미지의 물체를 구별하는 데 도움을 줄 수 있음
- 반면, MIM의 self-attention은 주로 지역적인 관계를 포착
- 즉, MIM은 전체 물체와 그 모양을 인식하는 데 어려움을 겪을 수 있음
2) Self-attentions of CL collapse into homogeneity
- CL의 self-attention은 놀랍게도 두 가지 다른 쿼리 토큰에 대해 거의 동일한 물체 모양을 나타냄
- 이는 MIM의 경우와 비교할 때, self-attention의 동질성(homogeneity)으로 붕괴된 현상으로 설명됨
- 반면, MIM의 self-attention은 예상대로 두 가지 다른 쿼리 토큰에 더 충실함
3) Attention collapse reduces representational diversity
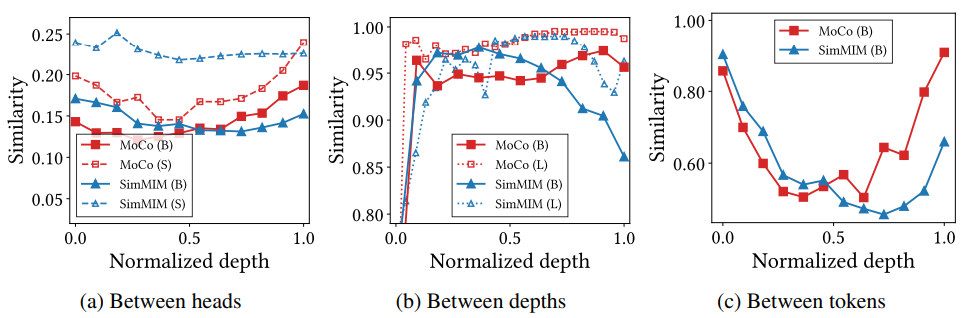
- Self-attention에서 표현의 코사인 유사성(cosine similarity)을 측정
- 모든 결과에서 CL의 후반 self-attention의 표현 유사성이 MIM보다 높은 것을 나타냄
- 그림에서 예상대로 CL의 유사성은 특히 후반 레이어에서 MIM보다 높으며, 이는 CL의 표현이 상당한 동질성을 가지고 있다는 것을 나타냄
- 모델 크기를 늘리는 것은 CL이 가지는 문제를 해결하지 못하고 오히려 악화시킬 수 있음
- 헤드 수를 늘리는 것 (ViT-S에서 ViT-B로)은 MIM의 표현 다양성을 향상시키지만 CL의 다양성을 거의 향상시키지 않음
- CL의 깊이를 늘리는 것 (ViT-B에서 ViT-L로)은 중복 모듈만 추가하는 결과를 가져옴
Self-attention layers of CL and MIM transform representations differently

- 표현 공간에서 한 예제 검증 이미지에 대한 196개의 공간 표현 토큰을 시각화
- 파란색과 빨간색 데이터 포인트는 self-attention 변환 이전과 이후의 토큰을 나타냄
- 왼쪽: CL의 self-attention은 모든 토큰을 동일하게 이동시키므로 이미지의 토큰 간 거리가 증가하지 않음
- 가운데: 그러나 CL은 "표현의 중심 (x로 표시)"을 서로 멀리 움직임. 따라서 이미지는 선형 분리 가능. 원과 삼각형 데이터는 서로 다른 이미지의 토큰을 나타냄
- 오른쪽: MIM의 self-attention은 쿼리 토큰에 따라 표현을 다르게 변환하여 토큰 간 거리를 증가시킴
3. How are representations transformed?
- CL은 주로 이미지 수준의 정보를 기반으로 표현을 변환하며, 그 self-attention은 전체 토큰을 통해 물체 모양 정보를 수집
- 이 과정은 토큰을 다양하게 만들기보다는 유사하게 만듦
- 결과적으로 CL은 이미지를 잘 구별하지만 토큰을 구별하는 데 어려움을 겪음
- 반면, MIM은 토큰 수준의 정보를 보존하고 확장시킴
- 따라서 각 토큰에 대한 self-attention은 상당히 다르며 각 토큰이 중복 정보를 포함하지 못하게 함
- Fourier analysis에서도 이러한 일관된 특성을 관찰:
- CL은 주로 저주파 신호를 활용하지만, MIM은 고주파를 활용
- 이 관찰은 CL이 모양 중심적이고 MIM이 질감 중심적이라는 것을 시사
- 요약하면, CL과 MIM으로 학습된 self-supervised 모델은 표현을 서로 다른 세부 수준에서 학습
4. Which components play an important role?
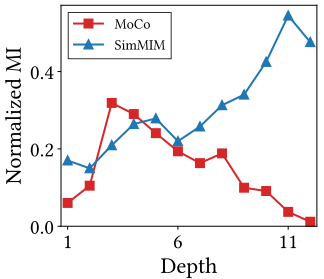
- 각 CL 및 MIM 레이어의 중요성을 분석한 결과, CL의 후반 레이어와 MIM의 초기 레이어가 주요 역할을 하는 것으로 나타남
- 이것은 초기 레이어가 일반적으로 저수준 기능을 캡처하는 데 사용되는데, 예를 들어 지역적 패턴, 고주파 신호 및 질감 정보를 포함
- 그리고 후반 레이어는 전역적 패턴, 저주파 신호 및 모양 정보를 캡처
- 이러한 분석과 통찰력을 토대로 CL과 MIM은 서로 보완될 수 있으며, 심지어 CL과 MIM 목표의 선형 조합과 같은 가장 간단한 구현도 두 방법 모두의 장점을 활용할 수 있다는 것을 5장에서 보여줌
- 놀랍게도, 혼합 모델은 fine-tuning 및 linear probing 정확도 측면에서 CL 또는 MIM 중 하나로 사전 학습된 모델을 능가
5. ARE THE TWO METHODS COMPLEMENTARY TO EACH OTHER?
- CL과 MIM이 상호 보완적임을 보여주기 위해, 두 가지 Loss를 선형으로 결합하는 가장 간단한 방법을 소개

- λ는 CL의 중요도 가중치
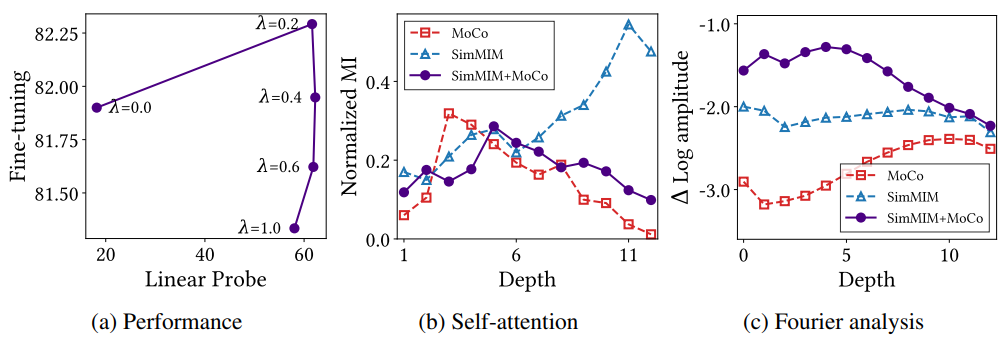
- 왼쪽: "CL + MIM"은 linear probing 및 fine-tuning 정확도 모두에서 CL과 MIM을 능가
- 가운데: "CL + MIM"의 상호 정보(Mutual information)는 모델의 끝에서 감소하며, 이는 나중 레이어의 self-attention가 균일성(homogeneity)으로 수렴하고 동일한 객체 모양 정보를 포착한다는 것을 제안
- 오른쪽: Fourier analysis은 "CL + MIM"이 시작 부분에서 고주파수를 증폭하고 끝에서 그것을 감소시킨다는 것을 보여줌
6. CONCLUSION
- 비전 트랜스포머를 위한 두 가지 널리 사용되는 자기 지도 학습 방법인 contrastive learning (CL)과 masked image modeling (MIM)의 다양한 측면을 강조하는 비교 연구를 수행
- 두 방법에서의 이점만을 활용하는 가능한 응용 프로그램을 제안하고, 결합된 모델이 개별 방법보다 우수한 성능을 낼 수 있는 방법을 보여줌
Future directions
- CL과 MIM 목표의 간단한 선형 결합보다 나은 방법이 있다고 믿음
- 예를 들어, CL을 나중 레이어에서 적용하고 MIM을 초기 레이어에서 적용하는 혁신적인 self-supervised learning 접근법을 고려할 수 있음
- 또 다른 흥미로운 방향은 CL과 MIM의 개별적인 특성을 향상시키는 것

AI Research Engineer