https://arxiv.org/abs/2407.08083
1. Introduction
Transformer
- 컴퓨터 비전, 자연어 처리 등 다양한 분야에서 표준 아키텍처로 자리 잡음
- Attention mechanism 덕분에 Multi-modal 학습 task에 적합
- Quadratic complexity로 인해 훈련 및 배포에 많은 계산 비용이 소요됨
Mamba Model
-
Mamba는 선형 시간 복잡성을 가진 새로운 State Space Model (SSM)을 제안
-
효율적인 Input dependant selection 메커니즘으로 긴 시퀀스를 처리
-
Mamba in Vision Tasks
- Mamba 기반 backbone이 Image Classification 및 Semantic Segmentation에 사용
- 그러나 autoregressive formulation은 이미지 데이터 처리에 비효율적
-
Vision Mamba (Vim)
- Global context와 spatial understanding 부족을 해결하기 위해 bidirectional SSMs를 제안
- 그러나 이로 인해 Latency가 발생하고 학습이 어려워질 수 있음
- ViT와 CNN 아키텍처가 여전히 Mamba 기반 모델을 능가
-
Proposed Hybrid Architecture
- Mamba 블록을 비전 task에 적합하게 재설계
- Hybrid 아키텍처는 MambaVision Mixer, MLP, Transformer 블록으로 구성
- 최종 단계에서 self-attention 블록을 활용하면 Global context와 long-range spatial dependency를 향상
-
MambaVision Model
- Multi resolution 아키텍처로 CNN 기반 residual blocks를 사용하여 빠르게 feature 추출
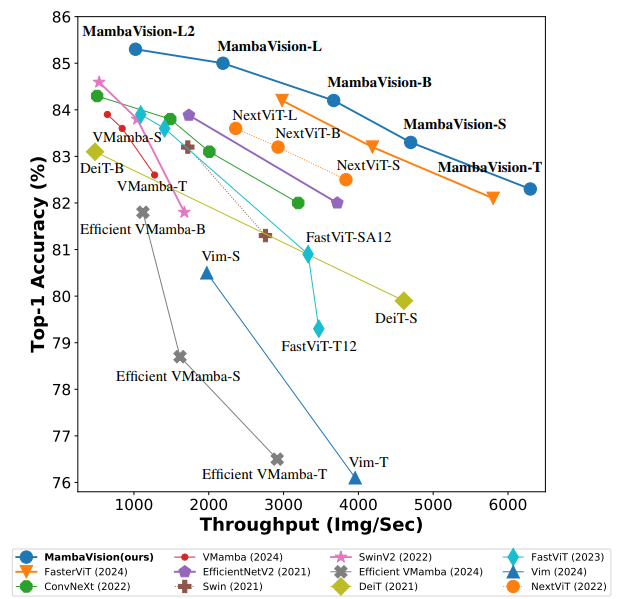
- ImageNet-1K Top-1 정확도와 이미지 처리량에서 새로운 SOTA Pareto front를 달성
- MS COCO와 ADE20 데이터셋에서 우수한 성능을 보임
-
Contributions
- Vision friendly Mamba 블록 재설계
- Mamba와 Transformer 블록 통합 pattern 조사
- 새로운 Hybrid Mamba Transformer 모델인 MambaVision 소개
3. Methdology
3.1 Macro Architecture
- MambaVision은 ImageNet-1K 데이터셋에서 SOTA 성능을 달성한 새로운 아키텍처
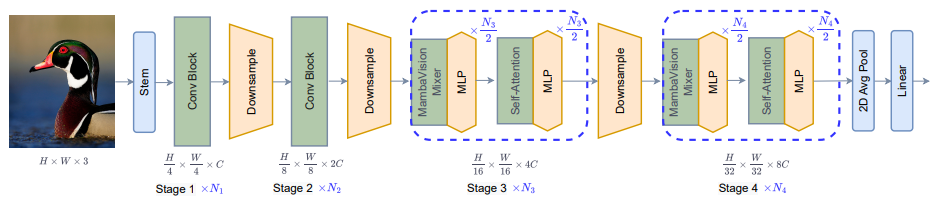
- MambaVision은 위 그림과 같이 4단계로 구성된 계층적 아키텍처로, 초기 두 단계는 높은 해상도의 feature extraction을 위한 CNN 기반 레이어로 구성
- 3단계와 4단계는 제안된 MambaVision과 Transformer 블록을 포함
- 기본적인 Residual block 수식은 다음과 같음:
3.2 Micro Architecture
3.2.1 Mamba Preliminaries
-
1D sequence Input을 변환하여 학습 가능한 hidden state로 변환
-
Sequence parameter A, B, C는 계산 효율성을 위해 Discrete parameter로 변환
-
Discrete parameter를 사용한 새로운 식
-
크기가 T인 Input sequence의 경우, Kernel K를 사용한 Global convolution 적용
3.2.2 Layer Architecture
-
Sequence length 와 Embedding dimension 를 갖는 Input 를 가정할 때, 3단계와 4단계에서 레이어 의 출력은 다음과 같이 계산 가능
-
Norm과 Mixer는 각각 Layer normalization과 Token mixing 블록의 Selection을 나타냄
-
일반적으로 Layer normalization은 Norm으로 사용됨
-
레이어가 주어졌을 때, 처음 레이어는 MambaVision mixer 블록을 사용하며 나머지 레이어는 Self-attention을 사용
MambaVision Mixer
- 아래 그림에서 보이듯이, 원래 Mamba mixer를 Vision task에 적합하도록 재설계
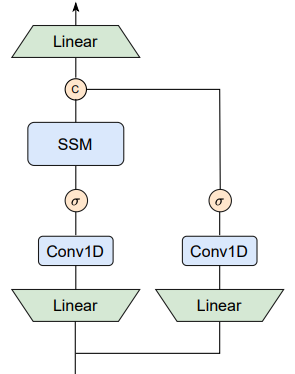
- Sequence 제약으로 인해 손실된 Contents를 보상하기 위해 추가적인 Convolution과 SiLU activation으로 구성된 Symmetric branch를 추가
- 각 Branch의 출력을 결합하고 최종 레이어로 Projection 하여 Global context와 Long-range spatial dependency를 강화
- MambaVision mixer의 출력 은 다음과 같이 계산
- 여기서 는 Input과 출력 Embedding dimension이 각각 과 인 Linear layer를 나타냄
- 은 Selective scan task, 는 SiLU activation function
- 와 은 각각 1D Convolution과 결합 task을 나타냄
Self-attention
- 일반적인 Multihead self-attention 메커니즘 사용
- 여기서 , , 는 각각 Query, Key, Value를 나타내며 는 Attention heads의 수
- Attention 수식은 이전 연구들처럼 Window 방식으로 계산 가능
5. Results
Image Classification
- 아래 테이블에서는 ImageNet-1K Classification 결과를 제시
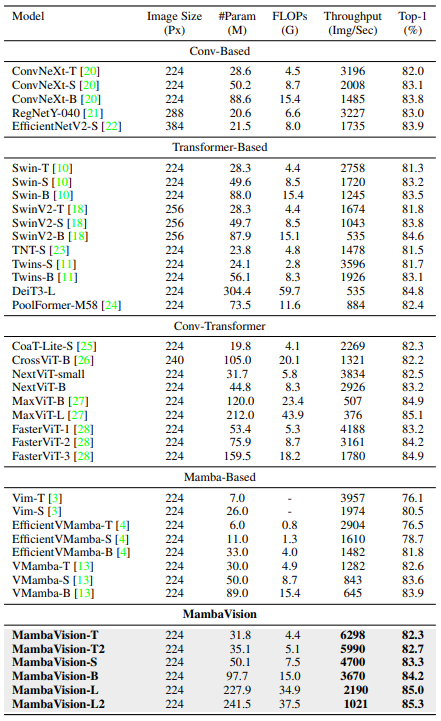
- Conv 기반, Transformer 기반, Conv-Transformer 및 Mamba 기반과 같은 다양한 모델 군집과 비교하였으며, 제안한 모델이 이전 연구들을 크게 능가하는 것을 보임
- 예를 들어, ConvNeXt 및 Swin Transformer와 비교할 때, MambaVision-B (84.2%)가 ConvNeXt-B (83.8%) 및 SwinB (83.5%)보다 우수한 결과를 보였으며, 이미지 처리량도 상당히 개선
- Mamba 기반 모델들과의 비교에서도 유사한 경향을 관찰. 특히, MambaVision-B (84.2%)가 VMamba-B (83.9%)를 능가
- 또한, 정확도와 처리량 간의 Trade-off를 고려한 주요 설계 목표임을 언급하며, MambaVision 모델 변형들이 유사한 크기의 모델들에 비해 상당히 낮은 FLOPs를 가지고 있다는 점을 지적
Object Detection and Segmentation
- 다양한 검출 크기의 모델을 훈련하여 MambaVision의 효과를 더욱 검증
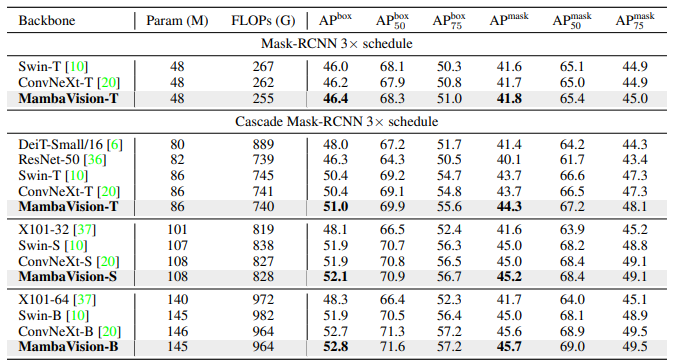
- Mask-RCNN Detection head를 사용하여 사전 훈련된 MambaVision-T backbone은 Box AP와 Mask AP에서 각각 46.4와 41.8의 결과를 보여주며, ConvNeXt-T와 Swin-T 모델을 능가
- Cascade Mask-RCNN 네트워크를 사용할 경우에도, MambaVision-T, MambaVision-S, MambaVision-B는 경쟁 모델들을 능가
- MambaVision 모델들이 다른 유사 크기의 경쟁 모델들을 능가하는 결과를 관찰할 수 있음
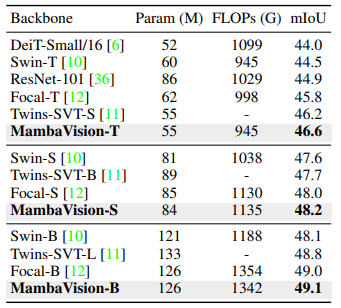
- 예를 들어, MambaVision-T, MambaVision-S, MambaVision-B는 각각 mIoU에서 Swin-T, Swin-S, Swin-B를 +0.6, +0.6, +1.0의 결과로 능가
- Downstream task의 hyperparameter tuning에 대한 철저한 최적화를 수행하지 않았음에도 불구하고, 이러한 결과들은 MambaVision이 다양한 Vision task에서 효과적인 backbone으로서의 가능성을 입증
6. Conclusion
- 본 연구에서는 MambaVision을 제안
- MambaVision은 Vision application에 특화된 최초의 Mamba-Transformer Hybrid backbone
- Global context representation learning 능력을 향상시키기 위해 Mamba 수식을 재설계하고, Hybrid 디자인 통합 패턴에 대한 종합적인 연구를 제시
- MambaVision은 Top-1 정확도와 이미지 처리량 측면에서 Transformer 및 Mamba 기반 모델을 큰 차이로 능가하며 새로운 SOTA Pareto를 달성

AI Research Engineer