https://arxiv.org/abs/2406.07876
CVPR 2024
1. Introduction
- 컴퓨터 비전 응용 분야에서는 자원이 제한된 device에서 portable neural network를 학습하면서도 만족스러운 예측 정확도를 유지하는 것이 핵심 과제
- Knowledge Distillation (KD)는 large-scale의 사전 학습된 teacher network의 정보를 활용하여 작은 target Student network를 같은 학습 데이터에서 학습시키는 방식으로, 주류 솔루션이 됨
- 기존의 KD 방법은 원래 학습 데이터를 항상 사용할 수 있다는 가정을 하지만, teacher network가 학습된 source 데이터셋에 접근하는 것은 현실적으로 불가능할 때가 많음
- 이유: 프라이버시, 보안, 독점적 권리, 대규모 데이터 등 다양한 우려 때문
- 이러한 학습 데이터에 대한 제약을 완화하기 위해, 최근에는 Data-free Knowledge Distillation (D-KD)가 주목받고 있음
주요 개념과 연구 배경
- Data-free Knowledge Distillation (D-KD): 사전 학습된 teacher network를 조건으로 Knowledge Distillation을 위해 합성 샘플(synthesize sample)을 구성하는 방법
- 목표: 원래 학습 데이터의 기저 분포(underlying distribution)를 맞추는 것
- 기존 D-KD 방법 [4, 7, 8, 10, 24, 30, 31]은 일반적으로 Adversarial inversion 및 Distillation 패러다임을 채택
- Data inversion 과정: 생성기(generator)가 teacher network를 판별자(discriminator)로 삼고 학습
Data inversion?
- 사전 학습된 teacher network를 기반으로 합성 샘플을 생성하는 과정인데, generator가 teacher network를 discriminator로 삼아 학습되어, 원래 학습 데이터의 분포를 반영하는 pseudo sample을 만듦. 이 과정은 데이터 없는 환경에서 knowledge distillation을 가능하게 함
- KD 과정: 생성된 pseudo sample을 student network 학습에 사용
- Data inversion 과정: 생성기(generator)가 teacher network를 판별자(discriminator)로 삼고 학습
문제점
- Adversarial D-KD 방법은 신뢰할 수 있는 knowledge distillation을 보장하기 위해 대량의 합성 샘플을 생성해야 하며, 이는 학습 자원 소비에 큰 부담을 초래
- 최근 연구 [11]는 meta-learning strategy을 통해 생성기의 수렴(iteration steps)에 필요한 반복 횟수를 줄이는 방법을 제시했으나, 여전히 대량의 합성 샘플을 생성해야 효과적인 knowledge distillation이 가능
- Data inversion과 knowledge distillation 과정을 동시에 고려하여 D-KD의 전체 학습 효율성을 개선하려는 연구는 없음
제안된 접근법: SSD-KD
-
본 논문은 최초의 fully efficient D-KD 접근법인 Small Scale Data-free Knowledge Distillation (SSD-KD)를 제안
- 주요 개념: Small data scale 관점에서 adversarial inversion 및 distillation 패러다임의 전체 학습 효율성을 향상시키는 것
- "Data scale": Training epoch 동안 knowledge distillation에 사용된 전체 inverted sample의 수를 의미
-
SSD-KD의 구성 요소
- Novel modulating function:
- Diversity-aware term과 difficulty-aware term을 정의하여 합성 샘플의 클래스 분포를 균형 있게 조정
- Priority sampling function:
- 강화 학습 전략을 사용하여 knowledge distillation을 위한 적절한 합성 샘플을 선택, dynamic replay buffer에서 후보를 선택해 전체 학습 효율성을 향상
- Novel modulating function:
-
SSD-KD의 두 가지 장점
- 극히 적은 양의 합성 샘플로도 knowledge distillation을 수행할 수 있어 주요 D-KD 방법보다 10배 빠른 전체 학습 효율성을 보여줌
- Student 모델의 성능 향상 및 합성 샘플의 데이터 규모를 상대적으로 크게 완화할 수 있는 능력
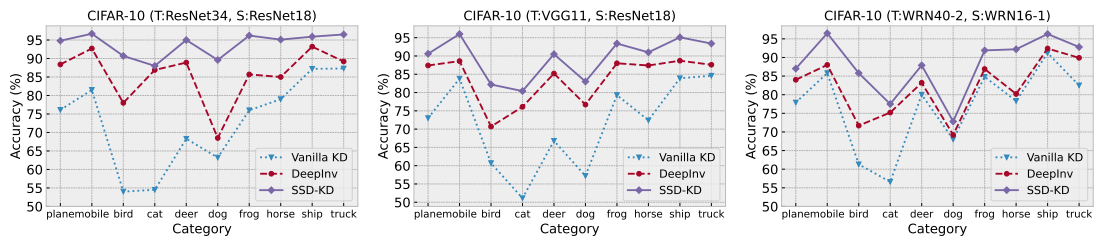
- 위 그림에서 볼 수 있듯이, 원래 학습 데이터와 합성 샘플의 데이터 규모가 10%로 동일할 때, student network가 합성 샘플로 학습한 경우 더 나은 성능을 보임
- 이 논문에서는 SSD-KD가 adversarial inversion 및 distillation 패러다임을 통해 전체 학습 효율성을 크게 향상시킬 수 있음을 다양한 image classification 및 semantic segmentation 벤치마크 실험을 통해 검증
3. Method
3.1. Preliminaries: D-KD
-
D-KD의 Objective와 개념
- Teacher Model: Original task 데이터셋으로 사전 학습된 모델로, 더 이상 접근할 수 없는 상태임. 이 모델을 로 표기
- Target Student Model: Objective 모델로, 이를 로 표기
- D-KD의 Objective: Teacher model이 학습한 데이터 분포 정보를 활용하여 합성 학습 샘플 를 생성하고, 이 샘플로 student model이 teacher model의 기능을 모방하도록 학습시키는 것
-
기존 D-KD 방법
- Generative Adversarial Network (GAN): 주로 사용되는 방법으로, 이는 latent noise input 로부터 합성 학습 샘플 를 생성
- Teacher Model을 Discriminator로 사용: GAN에서 teacher model이 discriminator로 사용됨
-
D-KD의 최적화
- Distillation Regularization: Teacher-Student 모델 간 function discrepancy 차이를 최소화하기 위해 사용되며, KL-divergence를 기반으로 함
- 위 수식은 KD에서 student 의 출력과 Teacher 의 출력 간의 차이를 측정하는 loss function을 의미
- 여기서 는 두 확률 분포 사이의 거리 또는 유사성을 측정하는 지표를 나타냄
- Task-Oriented Regularization: 해당 term은 주로 cross-entropy loss를 사용하며, teacher model의 예측값을 ground truth로 사용
- Distillation Regularization: Teacher-Student 모델 간 function discrepancy 차이를 최소화하기 위해 사용되며, KL-divergence를 기반으로 함
-
Batch Normalization (BN) regularization
- Teacher model이 사전 학습 후 원본 데이터 분포를 잘 캡처했다고 가정하여, 최근 D-KD 방법들은 data inversion 과정 동안 학습 데이터 분포의 통계치를 규제하는 추가 loss term을 도입
- BN regularization 수식:
- 위 수식은 batch normalization에서 각 레이어의 평균과 분산이 모델의 기대값과 얼마나 차이나는지를 측정하는 loss function
- : -번째 레이어의 배치 평균 (batch-wise mean)
- : -번째 레이어의 배치 분산 (batch-wise variance)
- : BN 통계치의 기대값을 나타내며, 대략적으로 running mean이나 variance로 대체 가능
-
D-KD의 효과
- 합성 샘플의 품질에 크게 의존함
- Data inversion과 knowledge distillation 과정으로 구성됨
- Student 모델의 최적화 성능에 영향을 미치며, knowledge distillation의 학습 시간 비용이 전체 학습 효율에 중요한 제약이 됨
3.2. Our Design: SSD-KD
-
SSD-KD의 목표
- "Small-Scale inverted Data for Knowledge Distillation"에 중점을 둔 새로운 D-KD 방식
- Pre-trained teacher와 knowledge distillation 과정의 피드백을 사용하여 data inversion 프로세스를 개선하여 전반적인 학습 효율을 크게 향상
-
SSD-KD의 최적화 목표
-
구성 요소
- ϕ(x): Diversity-aware modulating function으로, teacher model이 예측한 카테고리에 따라 각 합성 샘플에 다른 priority를 할당
- BN Regularization: ϕ(x)에 의해 생성기가 가능한 어려운 합성 샘플을 탐색하도록 장려
- Priority sampling function δ: priority sampling을 기반으로 샘플을 resampling하는 전략 사용
-
데이터 Sampling 전략
- Priority re-sampling: ϕ(x)로 샘플의 priority를 정하고, 중간 값도 ϕ(x)를 기준으로 재사용
-
SSD-KD의 효율성
- 매우 작은 규모의 합성 데이터로 기존 D-KD 방법과 비교하여 경쟁력 있는 성능을 발휘

- SSD-KD 파이프라인은 위 psuedo code 참고
- 기존 D-KD 방법(전통적인 방법 및 효율적인 방법)과 SSD-KD의 최적화 파이프라인 비교는 아래 그림을 참고
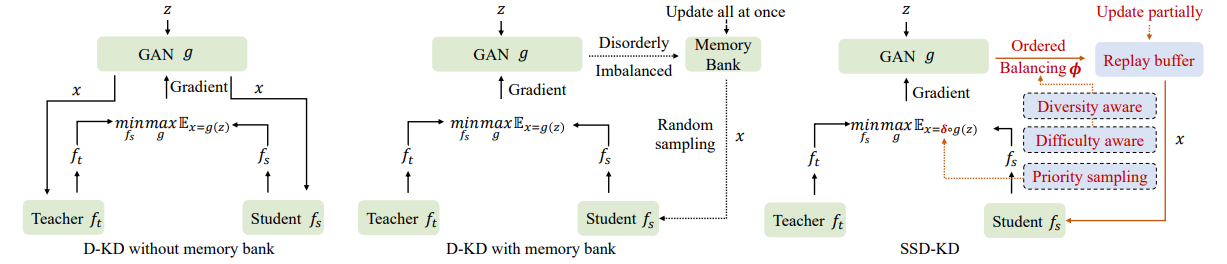
-
SSD-KD는 강화 학습 전략을 활용하여 dynamic replay buffer에서 기존 샘플의 일부를 업데이트
-
이 과정에서 샘플의 diversity과 difficulty 분포를 명시적으로 측정하여 적절한 합성 샘플을 유연하게 찾음
-
그래서 SSD-KD는 샘플의 priority를 명확히 측정하여 샘플의 diversity와 difficulty를 균형 잡히게 조정함으로써, 기존 방법들보다 더 효과적으로 샘플을 선택하고 업데이트
3.3. Data Inversion with Distribution Balancing
-
D-KD의 데이터 불균형
- 아래 그림에서 D-KD의 데이터 불균형 문제를 시각적으로 표현
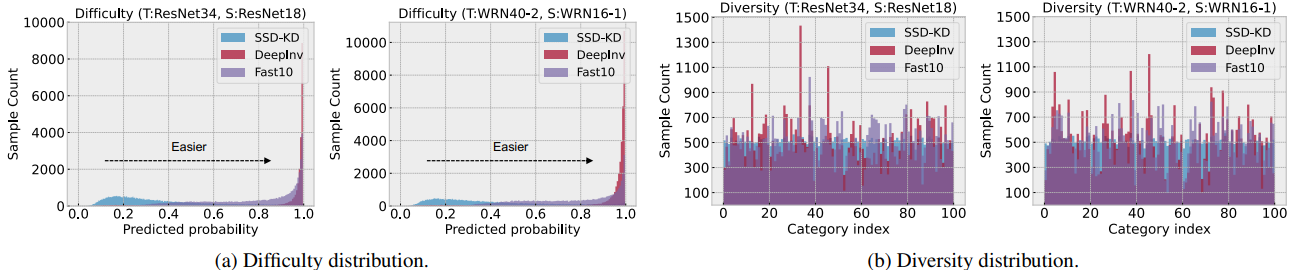
- 아래 그림에서 D-KD의 데이터 불균형 문제를 시각적으로 표현
-
Diversity-aware Balancing
- Data inversion 과정에서 샘플 difficulty의 불균형 문제 해결
- 상수 크기의 합성 데이터 샘플을 저장하는 replay buffer B 유지
- 같은 예측 카테고리를 가진 샘플 수를 penalize 하여 생성기가 드문 카테고리의 샘플을 생성하도록 유도
-
Difficulty-aware Balancing
- Focal loss 개념에서 영감을 받아 예측 확률 이 낮은, 즉 teacher model이 low-confidence 합성 샘플을 더 생성하도록 유도
-
Modulating function ϕ(x)
- ϕ(x) 도입: Teacher model의 prediction feedback에 따라 생성기의 최적화를 조정
- ϕ(x)의 계산:
- : 예측 카테고리 인덱스
- : 예측 확률 (Confidence)
- : x와 x'의 예측 카테고리가 동일하면 1, 그렇지 않으면 0인 function
- : Hyperparameter
-
ϕ(x)의 특성
- 예측 확실성이 높은 샘플에는 ϕ(x)가 낮은 값을 가짐, task-oriented loss 에 미치는 영향 적음
- 카테고리 분포가 불균형할 경우, 많은 샘플을 가진 카테고리는 페널티를 받아 가 약화됨
3.4. Distillation with Priority Sampling
-
Original prioritized experience replay method 와의 차이점
- 기존 방법은 중요한 전환(transition)을 더 자주 재사용하여 효율적으로 학습
- Data-free knowledge distillation 환경에서 보상을 받는 대신, 프레임워크 자체로부터 피드백을 받음
- SSD-KD는 균일 sampling 대신 highly prioritized 샘플에 집중하여 학습 속도를 높임
-
Priority sampling function
- Sampling 확률 조정: 현재의 replay buffer B에서 합성 데이터 를 sampling
- 를 통해 샘플의 중요도를 측정
- 정의:
- KL: Teacher model과 student model의 softmax 출력 간의 KL-divergence
- KL-divergence는 두 확률 분포 간의 차이를 측정하여 정보 손실이나 불일치를 나타냄
- : 샘플을 정규화하기 위한 보정 항, 특히 일 때
- 이 수식은 샘플 𝑥의 priority를 Kullback-Leibler divergence와 중요도 가중치를 사용해 계산
-
Importance sampling (IS) 가중치
- Priority sampling이 데이터 분포를 변경하여 bias를 유도할 수 있으므로, 이를 보정하기 위해 중요도 sampling(IS) 가중치 를 도입
- 정의:
- : sampling 확률, 정의:
- : Hyperparameter
- : 작은 양수, priority가 0인 transition이 선택되지 않는 경우 방지
-
priority sampling function 의 주요 특성
- 값이 클수록, 현재 B에서의 합성 샘플에 대해 teacher와 student 모델 간 정보 격차가 큼을 반영
- Student model은 정보 격차가 큰 샘플로부터 최적화되어 teacher model의 성능을 더 빠르게 습득
- 는 student 및 generative model의 각 업데이트 반복마다 동적으로 변화
- Student model이 특정 샘플에서 teacher model의 능력을 습득한 경우, 새로운 샘플 분포에서 teacher model과의 차이가 큰 샘플로부터 계속 학습함
- 이는 student model의 성능을 더욱 향상시킴
4. Experiment
4.1. Experimental Details
-
Datasets
- Image Classification: CIFAR-10, CIFAR-100
- Semantic Segmentation: NYUv2
-
Training Setups
- 기본 설정: [11]의 설정을 따름
- CIFAR-10/CIFAR-100: 5개의 다른 teacher-student 모델 쌍 사용 (Table 1, 2 참고)
- NYUv2: 두 개의 Deeplabv3 모델 사용 (Table 3 참고)
-
Evaluation Metrics
- 성능 평가: Student model의 정확도 (image classification은 top-1 accuracy, semantic segmentation은 mean Intersection over Union (IoU))
- 총 학습 시간 비용: 각 D-KD 방법 및 SSD-KD의 전체 학습 시간 기록
-
실험 환경
- GPU: NVIDIA V100, CPU: Intel Xeon Gold 6240R
- 구현: PyTorch 라이브러리 사용
- 각 teacher-student 모델 쌍에 대해 독립적인 세 번의 실험을 수행하고 평균 결과 보고
4.2. Experimental Results
-
Image Classification Task 결과
-
SSD-KD vs Fast2 (CIFAR-10/CIFAR-100)
- CIFAR-10: SSD-KD는 매우 적은 데이터 규모 (5000개의 합성 샘플, 원본 학습 데이터의 10%)에서도 Fast2 대비 최소 1.90배, 최대 3.92배의 학습 속도 향상 및 5개의 teacher-student 모델 쌍 중 4개에서 더 나은 student 모델 성능
- CIFAR-100: Fast2 대비 최소 3.29%, 최대 10.19%의 top-1 accuracy 개선
-
SSD-KD vs 다른 D-KD 방법들
- SSD-KD vs DeepInv, CMI, DAFL, DFQ, ZSKT, Fast5, Fast10 (Table 2 참고)

- SSD-KD는 모든 teacher-student 모델 쌍에서 효율적인 학습 성능 및 경쟁력 있는 student 모델 정확도 달성
-
-
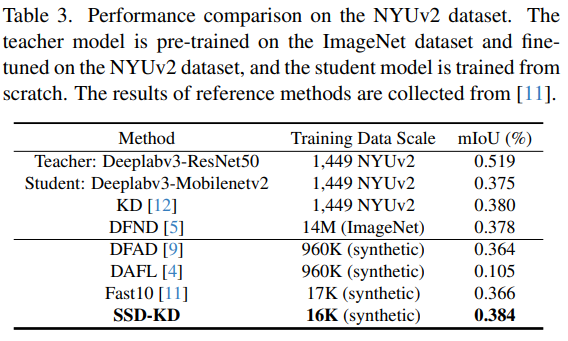
Semantic Segmentation Task 결과
- NYUv2 데이터셋 결과: SSD-KD는 기존 D-KD 방법보다 학습 데이터 규모와 학습 시간 측면에서 훨씬 효율적
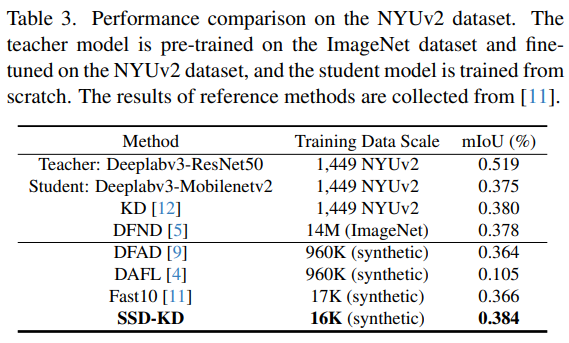
- SSD-KD와 Fast10의 전체 학습 시간 비용: 각각 8.9시간, 9.5시간
- SSD-KD로 학습된 student 모델은 원본 학습 데이터로 학습된 baseline 모델보다 우수한 성능
4.3. Ablation Studies
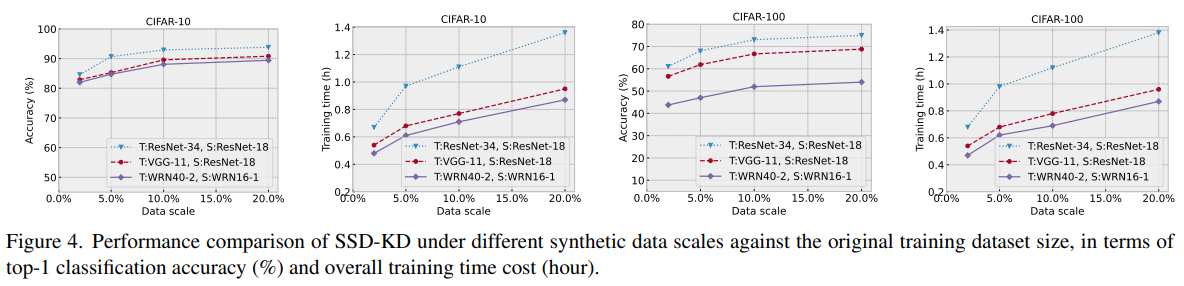
- Effect of the synthetic data scale
- SSD-KD가 적은 양의 합성 데이터 샘플로도 효과적이고 효율적인 knowledge distillation 학습이 가능함을 보여줌
- 실험 설정: 세 가지 teacher-student 모델 쌍
- ResNet34→ResNet18, VGG11→ResNet18, WRN40-2→WRN16-1에서
- 합성 데이터 크기를
- 50,000 (100%)에서 {10,000 (20%), 5,000 (10%), 2,500 (5%), 500 (1%)}로 감소
- 아래 그림에서 처럼, student 모델의 정확도는 합성 데이터 크기 범위에서 안정적, 학습 시간 비용은 거의 선형적으로 감소, 정확도 하락은 10% 미만
-
Effect of the core modules
- SSD-KD의 주요 module (diversity-aware 및 difficulty-aware, priority sampling function)의 중요성 검토 (아래 Table 4 참고)
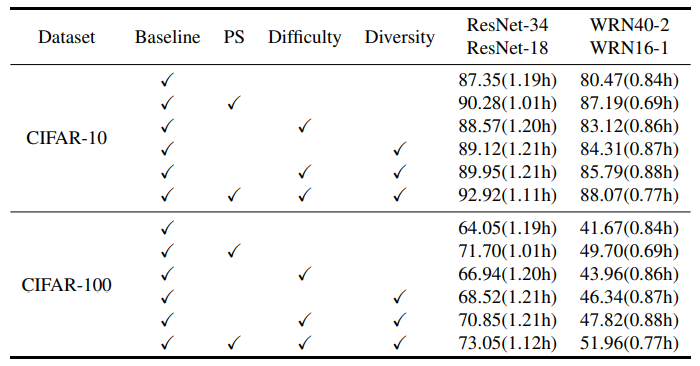
- 두 module의 조합이 모델 정확도와 학습 효율성 간의 균형을 잘 맞춤
-
Visualization of data inversion

-
위 그림은, Fast10과 SSD-KD로 생성된 NYUv2 데이터셋의 합성 이미지 비교
- SSD-KD는 texture 정보를 더 잘 복원하고 noise가 적음
5. Conclusion
- SSD-KD는 소규모 data inversion 및 sampling 메커니즘을 통해 data-free knowledge distillation 연구를 발전시킨 첫 번째 완전 효율적인 방법
- Modulation function 및 priority sampling function를 기반으로 합성 샘플의 diversity과 difficulty를 균형 있게 조절
- Image classification 및 semantic segmentation 벤치마크에서 SSD-KD의 효과 입증
