https://arxiv.org/abs/2312.10240
CVPR 2024
1. Introduction
-
Text-to-Image (T2I) 생성 모델은 엔터테인먼트, 예술, 디자인, 광고 등 다양한 분야에서 콘텐츠 제작의 핵심으로 빠르게 자리 잡고 있으며, 이미지 편집, 비디오 생성 등으로 확장되고 있음
-
최근 큰 진보에도 불구하고,
- 생성된 image에는 artifacts(인공물), implausibility(비현실성),
Text description과의 misalignment(불일치), 낮은 aesthetic quality(미적 품질) 등의 문제가 발생 - 아래 예시와 같이, Pick-a-Pic 데이터셋에서는 많은 image들이 왜곡된 인간/동물 몸체, 떠다니는 램프 등과 같은 비현실적인 요소를 포함

- Human evaluation 실험에서 데이터셋의 image 중 약 10%만이 artifacts와 implausibility가 없는 것으로 나타남
- Text-image misalignment 문제도 흔함 (예: "강에 뛰어드는 남자"라는 설명에 서 있는 남자가 등장)
- 생성된 image에는 artifacts(인공물), implausibility(비현실성),
-
기존 automatic evaluation metrics (IS, FID 등)는 개별 image의 세부사항을 반영하지 못함
-
최근 연구는 인간의 선호도(human preferences)를 수집하여 모델의 image 품질을 prediction
- Single numeric score로 요약하는 것은 한계가 있음
- CLIPScore, 질문 생성 및 답변 파이프라인 등은 비싸고 복잡하며, image의 misalignment 부분을 국소화하지 못함
제안된 개념
- Rich Human Feedback (RichHF-18K) 데이터셋과 Rich Automatic Human Feedback (RAHF) 모델 제안
- RichHF-18K는 18,000장의 image에 대한 세부적인 human feedback을 포함
- Image에서 implausibility/artifacts 부분을 강조하는 point annotation
- 누락되거나 잘못 표현된 개념을 표시하는 prompt의 단어 레이블
- Image의 현실성, text-image alignment, 미학 및 전체 평가에 대한 4가지 fine-grained score
- RAHF는 multi-modal transformer 모델로, 인간의 fine-grained feedback을 prediction
- Misalignment 영역, 잘못된 keyword, fine-grained score prediction 가능
- 신뢰할 수 있는 평가를 제공하며, 생성된 image의 품질에 대한 더 상세하고 explainable insight 제공
- 이는 T2I 생성 모델에 대한 첫 번째 풍부한 피드백 데이터셋 및 모델로, automatic explainable evaluation pipleline 제안
- RichHF-18K는 18,000장의 image에 대한 세부적인 human feedback을 포함
The main contributions
- RichHF-18K 데이터셋 제안
- 18K Pick-a-Pic image에 대해 fine-grained score, artifacts/misalignment image region, misalignment keyword를 포함시킴
- Multi-modal Transformer model (RAHF)
- 생성된 image에 대한 풍부한 feedback prediction
- Test set에서 human annotation과 높은 상관관계 보여줌
- RAHF의 prediction 피드백을 활용하여 image 생성 개선
- Prediction 된 heatmap을 마스크로 사용해 문제 영역을 복원 (inpaint)
- Prediction 된 score를 이용해 image 생성 모델(Muse 등)을 미세 조정
- e.g. via selecting/filtering finetuning data, or as reward guidance
- 두 경우 모두 원래 모델보다 나은 image 생성 가능
- Muse 모델의 개선
- RAHF 모델의 우수한 일반화 능력 증명
2. Related Works
-
Text-to-image generation
- Generative Adversarial Network (GAN)
- GAN은 image generator를 학습시키고, 생성된 image와 실제 image를 구분하는 discriminator를 함께 학습시킴
- Variational Auto-Encoders (VAEs)
- image 데이터의 우도(likelihood)를 최적화하는 ELBO를 사용해 학습됨
- Diffusion Models (DMs)
- Random noise에서 점진적으로 image를 생성하며, GAN보다 더 다양한 샘플을 생성 가능
- Latent Diffusion Models는 압축된 잠재 공간에서 확산(diffusion) 과정을 수행해 효율성을 높임
- Generative Adversarial Network (GAN)
-
Text-to-image evaluation and reward models
- Xu et al. [55]
- User에게 여러 image를 순위 매기도록 요청해 인간 선호도 데이터셋 수집
- ImageReward 모델을 이용해 보상 피드백 학습(ReFL) 제안
- Kirstain et al. [31]
- 웹 애플리케이션을 통해 인간 선호도를 수집하여 Pick-a-Pic 데이터셋 구축
- CLIP 기반의 PickScore를 사용해 인간 선호도 prediction
- Huang et al. [26]
- Text-image 모델 평가를 위한 T2I-CompBench 벤치마크 제안
- 다양한 평가 지표 계산을 위해 여러 사전 학습된 vision-language 모델 사용
- Wu et al. [52, 53]
- 생성된 image에 대한 대규모 인간 선택 데이터셋 수집 및 Human Preference Score (HPS) prediction을 위한 classifier 학습
- Lee [32]
- Multiple fine-grained metrics를 포함한 T2I 모델에 대한 holistic evaluation 제안
- Xu et al. [55]
-
Limitations 및 contributions
- 기존 연구들은 binary human evaluation 또는 선호도 순위에만 의존하여 feedback/reward를 구성
- 생성된 image의 misaligned regions, implausible regions, 또는 잘못된 keyword와 같은 상세하고 실행 가능한 feedback을 제공하지 못함
- 본 논문에서는 artifacts 영역뿐만 아니라 misalignment 영역, 잘못된 keyword, 4가지 fine-grained score를 포함한 rich feedback을 수집
- Text-image 모델에 대한 이질적인 rich human feedback에 대한 첫 번째 연구임을 주장
3. Collecting Rich Human Feedback
3.1. Data Collection Process
-
RichHF-18K 데이터셋 구성 요소
- 두 개의 heatmap
- Artifacts/implausibility, misalignment
- 네 가지 fine-grained score
- Plausibility, alignment, aesthetics, overall score
- Text sequence
- Misaligned keywords
- 두 개의 heatmap
-
Procedure
- 생성된 image를 검토하고, 사용된 text prompt를 읽음
- Prompt에 비추어 implausibility/artifacts 또는 misalignment 위치를 표시하는 포인트를 image에 마킹
- 마킹된 각 포인트는 "유효 반경(effective radius)"을 가지며, 이는 포인트 중심에 가상의 원판을 형성
- 이 방식으로 적은 수의 포인트로 결함이 있는 image 영역을 커버 가능
- Misalignment keyword와 plausibility, image-text alignment, aesthetic, overall quality에 대한 4가지 score를 5-point Likert scale로 평가
- 데이터 수집을 위해 웹 UI를 디자인하여 사용
3.2. Human Feedback Consolidation
- Multiple annotation 통합을 통해 신뢰성 향상
- 각 image-text 쌍은 세 명의 annotator가 annotation
- Score는 여러 annotator의 score를 평균하여 최종 score로 사용
- Misalignment keyword annotation은 다수결 투표로 가장 빈번한 레이블을 선택하여 최종 misalignment keyword 시퀀스 생성
- 포인트 annotation은 heatmap으로 변환한 후 annotator 별로 평균 heatmap을 계산하여 최종 heatmap 생성
3.3. RichHF-18K: A Dataset of Rich Human Feedback
- Pick-a-Pic 데이터셋에서 image-text 쌍의 하위 집합 선택
- 주요 데이터셋은 photo-realistic image를 포함하며, 이는 중요성과 application의 넓은 범위 때문
- Balanced category 확보를 위해 PaLI 시각 질문 응답(VQA) 모델 사용
- image-text 쌍에 대해 두 가지 질문을 통해 기본 기능 추출
- Image가 photo-realistic 한가?
- '인간', '동물', '사물', '실내 장면', '실외 장면' 중 어느 카테고리가 image를 가장 잘 설명하는가?
- PaLI의 답변을 바탕으로 Pick-a-Pic에서 다양한 하위 집합 샘플링, 결과적으로 17K image-text 쌍 도출
- 17K 샘플을 학습 세트(16K)와 검증 세트(1K)로 무작위 분할
- Pick-a-Pic 테스트 세트의 고유한 prompt와 해당 image에 대한 풍부한 human feedback 수집
- 최종적으로 RichHF-18K 데이터셋은 18K image-text 쌍에 대한 풍부한 human feedback을 포함하며, 16K train, 1K validation, 1K test 샘플로 구성
3.4. Data Statistics of RichHF-18K
-
Score 통계 요약 및 annotator agreement 분석
-
Score standardization
- 를 (s−smin) / (smax−smin) 수식을 사용해 [0, 1] 범위로 표준화 (smax = 5, smin = 1)
-
Score distribution
- 히스토그램 플롯은 대체로 gaussian distribution와 유사
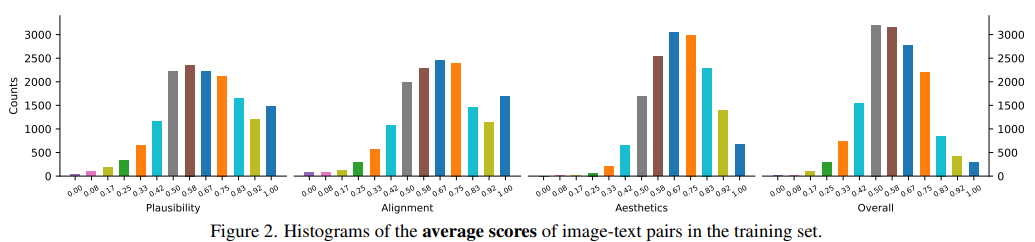
- Plausibility와 text-image alignment score는 1.0 score가 약간 더 높은 비율을 가짐
- 수집된 score의 분포는 positive 및 negative 샘플을 적절히 포함해 좋은 reward model 학습을 가능하게 함
-
-
Annotator 간 agreement 분석
-
Image-text 쌍에 대한 annotator 간 평가의 일치도를 분석하기 위해, score 간 최대 차이 계산
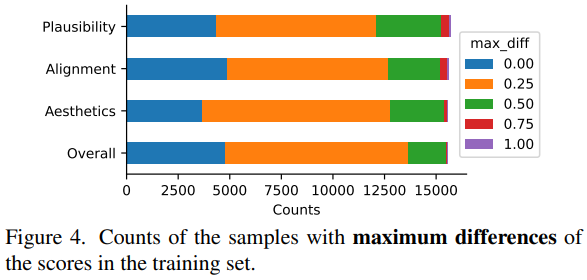
- 는 image-text 쌍에 대한 3개의 score 레이블 간의 최대 차이
-
의 히스토그램 플롯에 따르면 약 25%의 샘플에서 annotator 간의 perfect agreement를 보였으며, 약 85%의 샘플에서 good agreement를 보임
-
4. Predicting Rich Human Feedback
4.1. Models
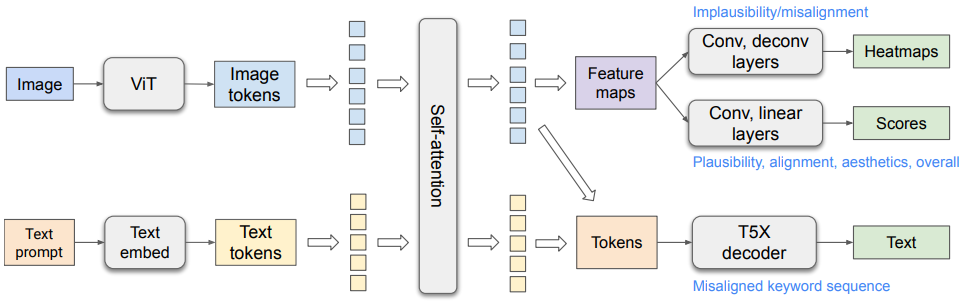
4.1.1. Architecture
-
ViT [14]와 T5X [41]를 기반으로, Spotlight 모델 아키텍처 [34]에서 영감을 받아 일부 수정
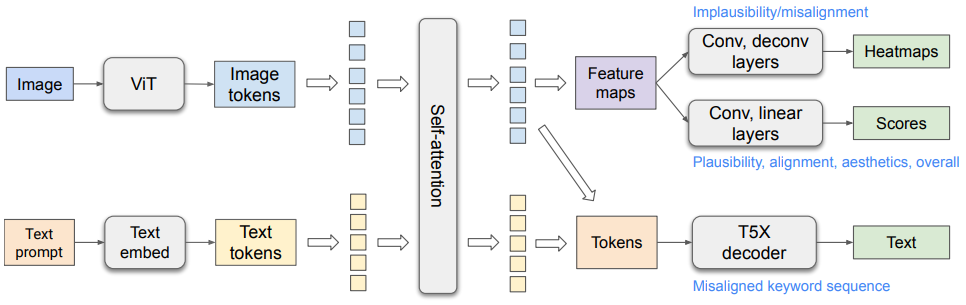
-
Self-attention module
- Image 토큰과 text 토큰을 연결하여 사용, PaLI [7]와 유사하게 bidirectional information propagation 필요
-
Text information
- Image 토큰에 전달되어 text misalignment score 및 heatmap prediction에 사용
-
Vision information
- Text 토큰에 전달되어 vision-recognition text encoding을 개선하여 text misalignment 시퀀스를 decoding
-
Pre-training dataset
- WebLI 데이터셋 [7]에서 natural image caption task을 추가하여 다양한 image에 대해 pre-training 수행
-
작동 원리
- ViT가 생성된 image를 입력으로 받아 image 토큰을 high-level representation으로 출력
- Text prompt 토큰은 dense vector로 embedding
- Image 토큰과 embedding 된 text 토큰을 연결한 후, T5X의 Transformer self-attention encoder를 통해 encoding
- Encoding 된 text 및 image 토큰을 사용하여 아래 세 가지를 prediction
- Heatmap prediction
- Image 토큰을 feature map으로 재구성하고, convolution layer, deconvolution layer, sigmoid activation을 거쳐 implausibility 및 misalignment heatmap을 출력
- score prediction
- Feature map을 convolution layer, linear layer, sigmoid activation을 거쳐 fine-grained score scalar로 변환
- keyword misalignment sequence prediction
- Image 생성을 위해 사용된 원본 prompt를 text 입력으로 사용
- Heatmap prediction
- Modified prompt
- Misalignment 토큰에 특수 접미사(' 0')를 추가하여 prediction 목표 설정
- e.g. Image에 "black cat"이 포함되었으나 'yellow'라는 단어가 misalignment 할 경우 "a yellow 0 cat"
- Evaluation 시, 특수 접미사를 사용하여 misalignment keyword 추출
- Misalignment 토큰에 특수 접미사(' 0')를 추가하여 prediction 목표 설정
4.1.2. Model Variants
-
Multi-head prediction
- 여러 heatmap 및 score를 prediction하기 위해 여러 prediction head를 사용하는 방식
- 각 score 및 heatmap 유형에 대해 하나의 head 사용
- 총 7개의 prediction head 필요
- 여러 heatmap 및 score를 prediction하기 위해 여러 prediction head를 사용하는 방식
-
Augmented Prompt
- 각 prediction 유형에 대해 single head를 사용하는 방식
- 각 prediction 유형에 대해 세 가지 head(heatmap, score, misalignment sequence) 사용
- Prompt에 출력 유형을 추가하여 모델에 세부 heatmap 또는 score 유형을 전달
- e.g. 특정 task에 대해 'implausibility heatmap'이라는 task 문자열을 prompt에 추가
- 추론 시, prompt에 해당 task 문자열을 추가하여 단일 heatmap(score) head로 다양한 heatmap(score) prediction 가능
- 실험 결과, 이 방식은 특정 task에서 더 나은 성능을 발휘
- 각 prediction 유형에 대해 single head를 사용하는 방식
4.1.3. Model Optimization
- Loss function
- heatmap prediction
- Pixel-level MSE loss 사용
- Score prediction
- MSE loss 사용
- Misalignment sequence prediction
- Teacher-forcing cross-entropy loss 사용
- Final loss function
- 위 세 가지 loss의 weighted combination
- heatmap prediction
4.2. Experiments
4.2.1. Experimental setup
-
Model training and hyperparameter tuning
- RichHF-18K 데이터셋의 16,000개 샘플을 사용하여 모델을 학습하고, 1,000개 샘플의 validation set를 통해 hyperparameter를 tuning
- Hyperparameter 설정에 대한 세부 내용은 Appendix 참고
-
Evaluation metrics
- Score Prediction
- Prediction된 score의 정확성을 측정하기 위해 Pearson 상관 계수(PLCC)와 Spearman 순위 상관 계수(SRCC)를 사용
- Heatmap Prediction
- Standard saliency heatmap 평가 지표(NSS/KLD) 사용
- Empty ground truth가 있을 수 있어 모든 샘플에 대해 MSE를 보고하고, non-empty ground truth 샘플에 대해서는 NSS/KLD/AUC-Judd/SIM/CC 지표를 사용
- Misaligned Keyword Sequence Prediction
- Token-level에서 정밀도, 재현율, F1-score를 사용하여 평가. mismatched keyword의 정밀도, 재현율, F1-score를 계산
- Score Prediction
-
Baselines
- ResNet-50 모델을 여러 fully connected layers와 deconvolution heads로 fine-tune하여 score와 heatmap prediction
- PickScore 모델과 CLIP 모델을 사용하여 각각 score와 text-image alignment 지표를 계산
- CLIP gradient map을 baseline으로 사용하여 misalignment heatmap prediction
4.2.2. RichHF-18K test set에 대한 prediction 결과
-
Quantitative analysis
- 아래 표에서 볼 수 있듯이, 제안된 두 모델 변형(multi-head와 augmented prompt 버전)은 모두 ResNet-50보다 우수한 성능을 보임
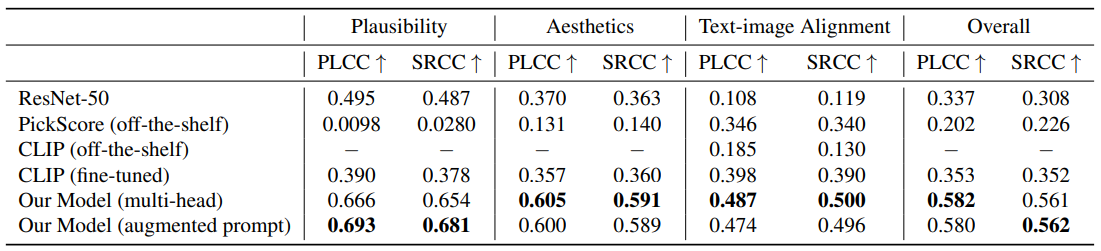
- 특히 아래 표와 같이, augmented prompt 버전은 multi-head 버전보다 더 좋은 결과를 보임. 이는 각 prediction task을 별도의 prompt로 명시하여 task 별 vision feature map과 text encoding을 생성한 덕분

- Misalignment heatmap prediction은 artifact/implausibility heatmap prediction보다 성능이 떨어짐. 이는 misalignment 지역이 잘 정의되지 않아 annotation이 더 noise가 많을 수 있기 때문

- 위 표는 test set에서 artifact/implausibility heatmap prediction 결과를 나타냄
- GT = 0은 ground truth가 empty implausibility heatmap을 의미
- 즉 artifact나 implausibility가 없음을 의미 (995개의 테스트 샘플 중 69개가 empty heatmap을 가짐)
- GT > 0은 ground truth가 artifact/implausibility가 있는 heatmap을 의미
-
Qualitative examples
- 모델이 prediction한 implausibility heatmap과 misalignment heatmap의 예시

- 위 예시의 prompt는 "슬림한 아시아계 어린이 발레리나가 하얀 타이츠를 입고 해변에서 뛰는 사진 (photo of a slim asian little girl ballerina with long hair wearing white tights running on a beach from behind nikon D5)" 으로, 이 image에서 비현실적인 부분이 heatmap으로 강조

- 위 예시의 prompt는 "A snake on a mushroom"

- Artifact/implausibility가 있는 영역과 prompt와 일치하지 않는 객체를 식별
5. Learning from rich human feedback
RAHF 모델 활용
- RichHF-18K 데이터셋을 통해 학습된 RAHF 모델의 prediction 결과(score, heatmap 등)를 사용하여 image 생성 모델 개선을 탐구
- Muse 모델을 주요 타겟으로 하여 실험, 이 모델은 masked transformer 아키텍처 기반
Finetuning generative models with predicted scores
- Muse 모델을 대상으로 prediction 된 RAHF score를 사용하여 finetuning
- 12,564개의 prompt로부터 생성된 image를 대상으로 RAHF score를 prediction
- 각 prompt의 image 중 최고 score가 일정 기준 이상인 경우, 그 image를 데이터셋에 포함하여 모델을 finetuning
- Muse 모델을 RAHF score 기반으로 finetuning한 후, 새롭게 생성된 image의 plausibility(개연성)에 대한 평가 진행

- 결과적으로, fine-tuned Muse 모델이 원본 모델보다 더 적은 artifact와 더 높은 개연성을 가짐
Region inpainting with predicted heatmaps and scores
- Prediction 된 implausibility heatmap을 사용하여 특정 영역을 inpainting하여 image 품질을 향상

- 위 예시의 prompt: "A baseball with the parthenon on its cover, sitting on the pitcher’s mound"

-
위 예시의 prompt: "A photograph of a beautiful, modern house that is located in a quiet neighborhood. The house is made of brick and has a large front porch. It has a manicured lawn and a large backyard."
-
Heatmap을 thresholding 및 dilating 처리하여 마스크 생성
-
위의 두 예시에서 처럼, Muse inpainting을 적용하여 text prompt에 맞는 새로운 image를 생성
-
RAHF가 prediction한 plausibility score를 기준으로 최종 image를 선택
6. Conclusions and limitations
Contributions and model performance
- RichHF-18K는 image 생성에 대한 첫 번째 rich human feedback 데이터셋
- Multi-modal Transformer를 설계하고 학습하여 rich human feedback을 prediction
- Prediction 된 rich human feedback을 사용하여 image 생성을 개선할 수 있음을 증명
Limitations
- Misalignment heatmap의 성능이 낮음
- 이는 일부 misalignment 케이스(e.g. image에 없는 객체) 라벨링의 애매모호함 때문일 수 있음
- Pick-a-Pic (Stable Diffusion) 모델 외의 생성 모델에 대한 데이터 수집 필요성
- RAHF 모델을 개선하고 T2I(text-image) 생성에 활용할 다양한 방법 탐구 필요
Future works
- Reinforcement learning
- Prediction 된 heatmap이나 score를 reward signal로 활용하여 생성 모델을 강화 학습으로 finetuning 하는 방법 탐구
- Weighting map
- Prediction 된 heatmap을 가중치 지도(weighting map)로 활용
- Misaligned sequences
- Prediction 된 misaligned sequences를 통해 image 생성 개선
- 이와 같은 내용을 통해 RichHF-18K와 초기 모델들이 미래 연구 방향에 영감을 주기를 기대
