https://ai.meta.com/research/publications/sam-2-segment-anything-in-images-and-videos/
1. Introduction
Segment Anything (SA) (2023.04)
- SA는 image에서 사용할 수 있는 segmentation model로 제안됨
- 하지만 image는 현실 세계의 static snapshot에 불과하며, video에서는 visual segment가 복잡한 동작을 할 수 있음
- 증강 현실(AR), 가상 현실(VR), 로봇 공학, 자율 주행차, video 편집 등에서 visual segmentation의 중요성이 대두되고 있음
- 저자들은 보편적인 visual segmentation 시스템이 image와 video 모두에 적용될 수 있어야 한다고 주장
Challenges of Video Segmentation
- Video에서의 segmentation은 entity의 시공간적 범위를 결정하는 것이 목표
- Entity는 동작, 변형, 가림, 조명 변화 등의 요인으로 인해 외형이 크게 변할 수 있음
- Video는 카메라 움직임, 블러, 낮은 resolution 등의 이유로 종종 image보다 품질이 낮음
- 많은 frame을 효율적으로 처리하는 것도 큰 challenge임
Introduction to Segment Anything Model 2 (SAM 2)
- SAM 2는 video와 image segmentation을 위한 통합 model로, image를 단일 frame video로 간주
- 본 논문의 연구에는 Promptable Visual Segmentation (PVS) task, model, 데이터셋이 포함됨
- PVS task는 video의 임의 frame에서 point, box 또는 mask를 input으로 받아 관심 있는 segment를 정의하고, 해당 segment의 시공간적 mask인 "masklet"을 예측
- 예측된 masklet은 추가 frame에서 prompt를 제공하여 반복적으로 수정 가능
Functions of the SAM 2
- SAM 2는 단일 image와 video frame에서 object의 segmentation mask를 생성
- Memory module을 갖추고 있어 object와 previous interaction에 대한 정보를 저장하며, 이를 바탕으로 video 전체에서 masklet 예측을 생성하고, 이전에 관찰된 frame의 문맥 정보를 기반으로 이를 효과적으로 수정
- 스트리밍 아키텍처는 video 도메인으로의 자연스러운 일반화를 제공하며, video frame을 하나씩 처리하고 target object의 previous memory에 주의를 기울임
Data Engine and SA-V Dataset
- Data engine을 사용하여 새로운 데이터를 interactive 하게 annotation 하기 위해 model을 루프(loop) 내에서 활용
- 대부분의 기존 VOS 데이터셋과 달리 특정 카테고리의 object에 제한되지 않으며, 유효한 경계를 가진 모든 object의 segmentation 학습 데이터를 제공하는 것을 목표로 함
- SAM 2를 루프에 포함한 data engine은 기존 model 보조 접근 방식보다 8.4배 빠르면서 유사한 품질을 제공
- 최종 SA-V 데이터셋은 50.9K개의 video에 걸쳐 35.5M개의 mask로 구성, 기존 VOS 데이터셋보다 53배 더 많은 mask를 포함
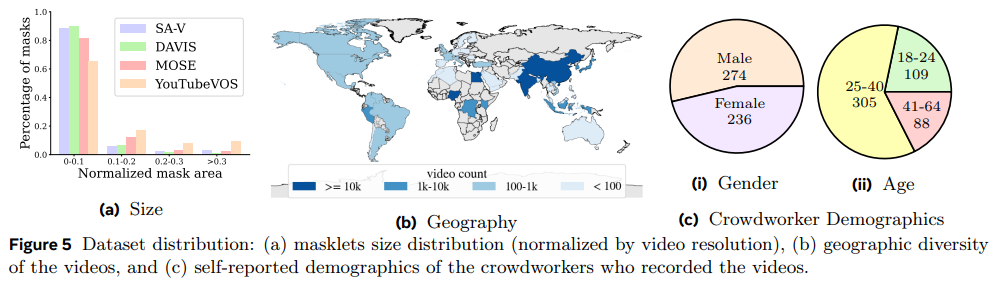
- SA-V는 지리적으로 다양한(geographically diverse) 데이터셋이며, 성별(gender) 및 나이(age) 그룹에 따른 성능 편차가 최소화된다는 평가를 받음
Experimental Results of SAM 2
- SAM 2는 기존 접근 방식보다 3배 적은 interaction으로 더 나은 segmentation 정확도를 제공
- 기존 VOS banchmark에서 여러 평가 설정 하에 SAM을 능가
- Image segmentation banchmark에서도 SAM 보다 더 나은 성능을 발휘하며, 6배 빠름
- 다양한 video 및 image 분포에서 효과적임을 입증
2. Related work
Image segmentation
- Segment Anything (SA)은 prompt를 통해 유효한 segmentation mask를 출력하는 task으로, input prompt로 관심있는 object를 나타내는 bounding box 또는 point 등을 사용
- SA-1B 데이터셋에서 학습된 SAM은 유연한 prompt로 zero-shot segmentation을 가능하게 하여 다양한 application에 적용이 가능
- 최근까지도 다양한 분야에서 SAM을 활용한 연구들이 있었음
- Real-time Applications and Use on Mobile Devices
- EfficientSAM (Xiong et al., 2023)
- MobileSAM (Zhang et al., 2023a)
- FastSAM (Zhao et al., 2023)
- Medical imaging
- Ma et al., 2024; Deng et al., 2023; Mazurowski et al., 2023; Wu et al., 2023a
- Remote sensing
- Chen et al., 2024; Ren et al., 2024
- Motion segmentation
- Xie et al., 2024
- Camouflaged object detection
- Tang et al., 2023
- Real-time Applications and Use on Mobile Devices
Interactive Video Object Segmentation (iVOS)
- iVOS는 user guidance를 통해 video에서 masklet을 효율적으로 얻는 중요한 task
- Scribble(낙서), click 또는 bounding box 형태로 prompt input
- 초기 접근 방식은 graph-based optimization을 사용하여 segmentation annotation 과정을 제안
- Wang et al., 2005; Bai & Sapiro, 2007; Fan et al., 2015
- 최근 접근 방식은 modular design을 채택하여 사용자 input을 단일 frame에서 mask representation 으로 변환한 후 다른 frame으로 확장
- Heo et al., 2020; Cheng et al., 2021b; Delatolas et al., 2024
- DAVIS interactive benchmark는 여러 frame에 scribble input을 통해 object를 interactive 하게 segmentation 할 수 있도록 함
- Caelles et al., 2018
- 본 논문에서는 DAVIS interactive benchmark에서 영감을 받아, prompt가 가능한 VOS task에 대한 interactive evaluation 설정을 채택
- Click-based input은 interactive video segmentation을 위한 수집이 더 쉬움
- Homayounfar et al., 2021
- SAM에서는 mask 또는 point input을 기반으로 사용
- Cheng et al., 2023b; Yang et al., 2023; Cheng et al., 2023c; Rajič et al., 2023
- 그러나 이러한 접근 방식은 tracker가 모든 object에 대해 작동하지 않을 수 있으며, video의 image frame에서 SAM의 성능이 좋지 않거나, model의 실수를 interactive 하게 수정할 수 있는 메커니즘이 없는 등의 한계가 있음
Semi-supervised Video Object Segmentation (VOS)
- Semi-supervised VOS는 일반적으로 첫 frame에서 object mask를 input으로 받아 video 전반에 걸쳐 정확히 tracking 해야 함
- 첫 frame에 대한 input mask가 object appearance에 대한 supervision signal로 볼 수 있기 때문에 "semi-supervised"라고 불림
- 이 task는 video 편집, 로봇 공학, 자동 배경 제거 등 다양한 응용 분야에서 중요함
- Early neural network-based 접근 방식은 첫 번째 video frame 또는 모든 frame에서 model을 target object에 맞추기 위해 online fine-tuning을 사용
- Caelles et al., 2016; Perazzi et al., 2016; Yoon et al., 2017; Maninis et al., 2017; Hu et al., 2018a; Bhat et al., 2020; Robinson et al., 2020; Voigtlaender & Leibe, 2017
- 빠른 추론은 offline-trained model로 달성
- Multi-conditioning 방식은 RNN과 cross-attention으로 모든 frame에 확장
- 최근 접근 방식은 하나의 ViT로 현재 frame과 이전 frame 및 관련 예측을 공동 처리하여 단순한 아키텍처를 제공하지만 inference cost가 과도하게 발생
- Zhang et al., 2023b; Wu et al., 2023b
- Semi-supervised VOS는 첫 video frame에 mask prompt를 제공하는 것과 동일하기 때문에 Promptable Visual Segmentation (PVS) task의 special case로 볼 수 있음
- 하지만 첫 번째 frame에서 high-quality object mask를 annotation 하는 것은 실질적으로 어려움
Video segmentation datasets
- 많은 데이터셋이 VOS task를 해결하기 위해 제안
- 초기 VOS 데이터셋, 예를 들어 DAVIS는 high-quality annotation을 포함하지만 그 크기가 제한적이어서 딥러닝 기반 접근 방식 학습에 적합하지 않음
- YouTube-VOS는 94개의 object 카테고리를 포함하여 4천 개의 video를 포함하는 VOS task의 첫 large-scale 데이터셋
- 알고리즘 성능이 향상됨에 따라 연구자들은 occlusions(가림), long videos, extreme transformations, object diversity 또는 long scene diversity에 초점을 맞추어 VOS task 난이도를 높이는 연구를 진행
- 현재의 VOS 데이터셋은 "video에서 모든 것을 segment" 할 수 있는 능력을 달성하기에는 충분한 범위를 포함하지 않음
- 주로 whole object에 대한 annotation이 포함되며, 사람, 차량, 동물과 같은 특정 object 클래스에 집중됨
- 이에 비해 본 논문에서 제시한 SA-V 데이터셋은 whole object 뿐만 아니라 object parts도 광범위하게 커버하며, 기존 데이터셋보다 훨씬 더 많은 mask를 포함
3. Task: promptable visual segmentation
Promptable Visual Segmentation (PVS) task
- PVS task는 video의 임의 frame에 model에 prompt를 제공할 수 있도록 함
- Prompt는 object를 정의하거나 model이 예측한 것을 수정하기 위해 사용할 수 있는 positive/negative click, bounding box 또는 mask 일 수 있음
- Interactive experience를 제공하기 위해, 특정 frame에서 prompt를 받으면 model은 즉시 해당 frame에서 object의 유효한 segmentation mask를 제공해야 함
- Ininital prompt를 single 또는 multiple로 받은 후, model은 이를 전체 video에 걸쳐 object의 masklet을 얻기 위해 diffusion 해야 하며, 이는 video의 모든 frame에서 target object의 segmentation mask를 포함

- Additional prompt는 video 전체에 걸쳐 segment를 수정하기 위해 임의의 frame에서 model에 제공될 수 있음 (위 그림 참고)
The Role of SAM 2
- SAM 2는 SA-V 데이터셋을 구축하기 위한 PVS task의 데이터 수집 도구로 사용됨
- Model은 여러 frame에 걸친 annotation을 포함하는 interactive video segmentation 시나리오를 시뮬레이션하여 online 및 offline 설정에서 평가됨
- 이는 아래와 같은 내용을 포함
- Conventional semi-supervised VOS setting
(첫 번째 frame에 대한 annotation이 제한된 경우) - SA banchmark에서의 image segmentation
- Conventional semi-supervised VOS setting
4. Model
Overview of SAM 2
- SAM 2는 video 및 image 도메인으로 확장된 model로,
개별 frame에 point, box, mask prompt를 통해 object의 공간적 범위를 정의할 수 있음
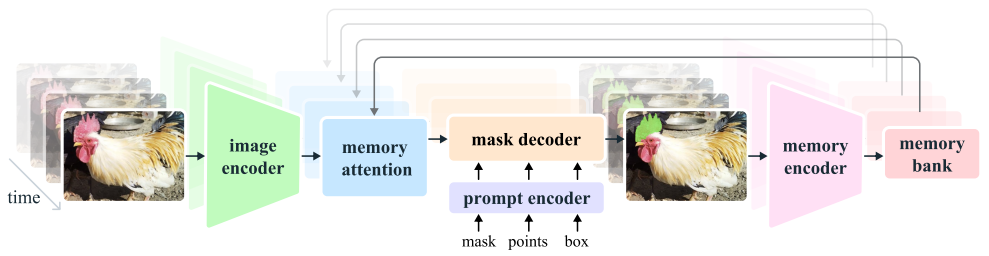
- Image input에서는 SAM과 유사하게 동작
- Light-weight mask decoder가 frame embedding과 현재 frame의 prompt(있는 경우)를 받아 해당 frame의 segmentation mask를 출력
- Prompt는 mask를 refine 하기 위해 반복적으로 추가 가능
Frame embeddings and memory utilization
- SAM 2 decoder의 frame embedding은 image encoder에서 직접 나오는 것이 아니라, 과거의 예측과 prompt 된 frame들의 memory에 따라 조건화됨
- Prompt 된 frame은 현재 frame이 아닌 "future" 에서 올 수도 있음
- Memory encoder는 현재 예측을 기반으로 frame의 memory를 생성하여 memory bank에 저장, 이후 frame에서 사용
- Memory attention 연산은 image encoder에서 얻은 frame embedding을 memory bank에 조건화하여 mask decoder에 전달될 embedding을 생성
Image encoder
- 실시간으로 임의의 길이의 video를 처리하기 위해 streaming approach 채택
- Video frame을 사용 가능해지는 대로 처리
- Image encoder는 전체 interaction 동안 "한 번만 실행"
- 각 frame을 나타내는 조건이 없는 토큰(feature embedding)을 제공
- Hierarchical을 갖춘 Hiera image encoder 사용, decoding 시 multi-scale feature 사용 가능
Memory attention
- Memory attention의 역할은 현재 frame들의 feature를 과거 frame들의 feature와 예측할 뿐만 아니라 새로운 prompt 들에 기반하여 'conditioning'하는 것
- L개의 transformer block을 쌓아 첫 번째 block은 현재 frame의 image encoding을 input으로 사용
- 각 block은 self-attention을 수행한 후, memory bank에 저장된 (prompted/unprompted) frame과 object pointer에 대해 cross-attention을 수행한 후 MLP를 수행
- Self 및 cross-attention에는 vanilla attention 연산 사용, 최근 효율적인 attention kernel의 발전을 활용
Prompt encoder and mask decoder
- SAM의 prompt encoder와 동일하며 click (positive or negative), bounding box 또는 mask로 prompt 가능
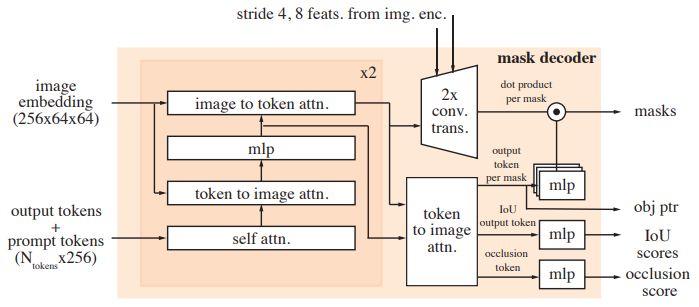
- 위 그림의 설계는 대체로 SAM을 따르며, 추가적으로 up-sampling 과정에서 image encoder의 stride 4와 stride 8 특성을 포함
- 또한 output mask에 해당하는 mask token을 object pointer로 사용하고, 현재 frame에서 interest object가 보이는지를 나타내는 occlusion score를 생성
- Sparse prompt는 각 prompt 유형에 대해 학습된 embedding과 더해진 positional encoding 으로 표현
- Mask는 convolution을 사용하여 embedding 되며 frame embedding과 더해짐(summed)
- SAM과 유사한 decoder 디자인을 따르며, prompt와 frame embedding을 업데이트하는 "two-way" transformer block을 쌓음
- Video에서 ambiguity(모호성)가 여러 frame에 걸쳐 확장될 수 있는 경우, 각 frame에서 여러 mask를 예측
- Additional prompt로 ambiguity가 해소되지 않으면, 현재 frame에서 가장 높게 예측된 IoU를 가진 mask만 propagation
Memory encoder
- Output mask를 convolution module을 사용해 down-sampling 하고, image encoder에서 얻은 unconditioned frame embedding과 element-wise 하게 더한 다음, 경량화된 convolution layer를 통해 정보를 confusion
Memory bank
- FIFO queue로 N개의 최근 frame과 M개의 prompt 된 frame의 memory를 유지
- 예를 들어 VOS task에서 initial mask가 유일한 prompt인 경우
- Memory bank는 항상 첫 번째 frame의 memory와 최근 N개의 frame의 memory를 유지
- 두 세트의 memory는 spatial feature map으로 저장
- Object pointer라는 high-level semantic information을 lightweight vector로 저장하며, 각 frame의 mask decoder output token을 기반으로 함
- Memory attention은 spatial memory feature와 object pointer 모두에 cross-attention 수행
Training
- Model은 image와 video 데이터를 함께 학습
- 이전 연구들과 유사하게(SAM etc.), model의 interactive prompt를 시뮬레이션
- 8개의 frame sequence를 샘플링하고 최대 2개의 frame을 무작위로 선택하여 prompt 하고, model 예측과 함께 corrective click(교정 클릭)을 확률적으로 받음
- 학습은 GT masklet을 순차적으로(interactive 하게) 예측하는 것
- Model에 대한 initial prompt는 GT mask일 확률이 0.5, GT mask에서 샘플링된 positive click일 확률이 0.25, bounding box input일 확률이 0.25
5. Data
- Video에서 작동하는 "segment anything"을 개발하기 위해, 본 논문에서는 data engine을 구축하여 대규모의 다양한 video segmentation 데이터를 수집
- 이 데이터 수집 과정은 세 가지 Phase로 구분되며, 각 Phase는 annotation task에 제공되는 model의 지원 수준에 따라 분류
5.1. Data engine
Phase 1: SAM per frame
- Process
- 초기 단계에서는 image 기반의 interactive SAM을 사용하여 annotation task을 지원
- Annotator는 매 frame 마다 target object의 mask를 annotation
- 1초당 6frame(FPS) 속도로 진행하며, brush 및 eraser와 같은 수동 편집 도구를 사용
- Characteristic
- 시간적인 mask tracking을 지원하지 않으며, 매 frame에서 mask를 처음부터 annotation 해야 함
- 이 방법은 느리지만, 각 frame에서 높은 품질의 spatial annotation을 생성
- Collected data
- 1.4K video에서 16K masklet을 수집
- Average annotation time
- Frame 당 37.8초
- Note
- SAM 2의 evaluation에서 잠재적인 bias를 완화하기 위해, SA-V의 검증 및 테스트 세트를 annotation 할 때 이 접근법을 사용
Phase 2: SAM + SAM 2 Mask
- Process
- SAM 2를 추가하여 mask를 prompt로 받아들임
- SAM과 같은 도구로 첫 frame에서 spatial mask를 생성한 후, SAM 2 Mask를 사용하여 나머지 frame에 temporally(시간적으로) mask를 propagation
- Characteristic
- SAM 2 Mask는 initial Phase 1 데이터와 오픈 데이터셋으로 학습됨
- SAM 2 Mask를 재학습 및 업데이트하며, annotation 시간을 크게 단축시킴
- Collected data
- 63.5K masklet 수집
- Average annotation time
- Frame당 7.4초
- Note
- 중간 frame의 mask를 처음부터 annotation 해야 함
Phase 3: SAM 2
- Process
- SAM 2는 다양한 prompt(point, mask 등)를 수용함
- 시간적 차원에서 object의 memory를 이용하여 mask prediction을 생성
- Annotation 작업자는 중간 frame에서 예측된 masklet을 fine-tuning 할 때 occasional refinement click만 제공하면 됨
- Characteristic
- SAM 2는 수집된 annotation을 사용해 다섯 번 재학습 및 업데이트됨
- Task 시간 및 효율성이 크게 향상됨
- Collected data
- 197.0K masklet 수집
- Average annotation time
- Frame당 4.5초
- Note
- Phase 1보다 약 8.4배 빠름
Quality verification
- Procedure
- 별도의 annotation 작업자가 각 masklet의 품질을 "satisfactory" 또는 "unsatisfactory"로 평가함
- "unsatisfactory"로 평가된 masklet은 annotation 파이프라인으로 다시 보내져 refine 됨
- Condition
- 명확한 경계를 가진 target object가 잘 추적되지 않은 masklet은 reject 됨
Auto masklet generation
- Objective
- Annotation의 다양성을 보장하고 model의 failure case를 식별하기 위해 자동 생성된 masklet을 추가
- 이러한 auto masklet은 model이 실패하는 경우를 식별하는 데도 도움을 줌
- Procedure
- SAM 2를 첫 frame에서 일정한 grid의 point로 prompt하고 후보 masklet을 생성
- 이후, 검증 단계를 통해 필터링 후 "satisfactory"로 태그된 auto masklet을 SA-V 데이터셋에 추가
- "unsatisfactory"로 식별된 auto masklet은 정교화 단계로 보내짐
Analysis
- 아래 Table 1에서, 각 data engine 단계에서의 annotation protocol을 비교
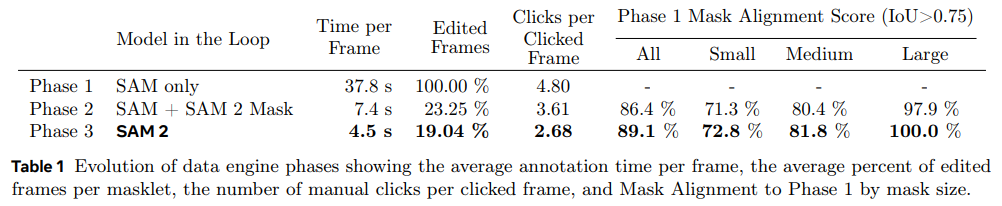
- 평균 annotation 시간, masklet 당 평균 수동 edited frame 비율, click 된 frame 당 평균 click 수 등을 평가
- Phase 1의 Mask Alignment Score는 Cross entropy가 0.75를 초과하는 mask의 비율로 정의
- Phase 3의 SAM 2는 효율성과 품질이 크게 개선
- Phase 3는 Phase 1보다 8.4배 빠르고, edited frame 비율이 가장 낮으며, click 수가 적고, alignment가 더 높음
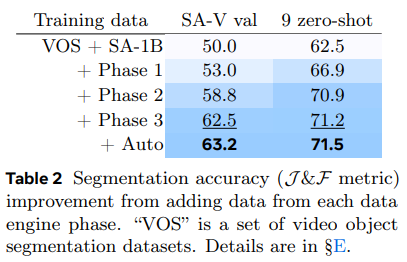
- Table 2에서는 각 단계의 데이터를 이용해 학습된 SAM 2의 성능을 비교
- 여기서 iteration을 고정하여 추가 데이터의 영향만을 측정
- J&F 정확도(metric)를 기준으로 평가 -> J&F 정확도는 높을수록 좋음
J&F 는 segmentation 성능 평가 지표 중 하나 (아래 두 값을 결합)
- Jaccard Index (J)
- True 값과 Prediction 값 간의 겹치는 부분을 평가
- Boundary F-measure (F)
- Segmentation 된 boundary의 quality를 측정
- Boundary가 얼마나 잘 일치하는지를 평가
- Jaccard Index (J)
- 각 Phase에서 추가 데이터를 포함할수록 성능이 일관되게 개선됨
- 이는 SA-V val set뿐만 아니라, 9개의 zero-shot banchmark에서도 확인
5.2. SA-V dataset
- SA-V 데이터셋은 data engine을 사용하여 수집한 50.9K개의 video와 642.6K개의 masklet으로 구성
Comparison
- 아래 Table 3에서 SA-V 데이터셋을 다른 일반적인 VOS (Video Object Segmentation) 데이터셋과 비교
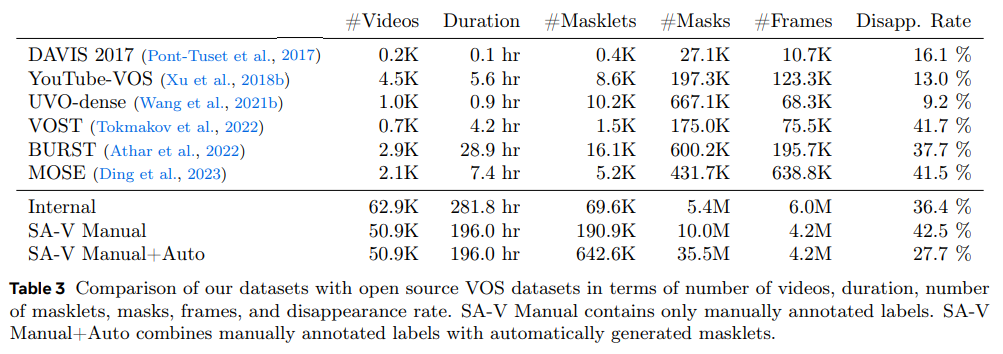
- SA-V는 기존 VOS 데이터셋 중 가장 큰 데이터셋보다 53배 많은 mask를 포함, 향후 연구에 중요한 자원 제공
Videos
- Composition
- Crowdworker가 capture 한 50.9K개의 video 수집
- Video의 54%는 실내, 46%는 실외 장면으로 구성되며, 평균 길이는 14초
- 다양한 "in-the-wild" 환경과 다양한 일상 시나리오 포함
- Comparison
- 기존 VOS 데이터셋보다 더 많은 video 포함
- 아래 Figure 5에서 처럼, video는 47개국에서 다양한 참여자에 의해 촬영된 것임을 알 수 있음
Masklets
- Composition
- 190.9K개의 manual masklet과 451.7K개의 auto masklet 포함

- 위 그림은 manual 및 auto masklet이 overlay 된 예시
- SA-V Manual의 Disappearance Rate는 42.5%로, 기존 데이터셋에 비해 경쟁적임
- 190.9K개의 manual masklet과 451.7K개의 auto masklet 포함
- Comparison
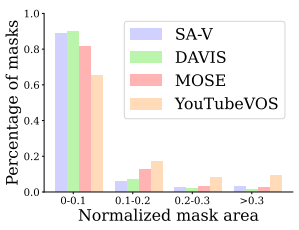
- 아래 그림에서 DAVIS, MOSE, YouTubeVOS와의 mask size 분포를 비교
- Video resolution에 따른 normalized mask area
- SA-V mask의 88% 이상이 normalized mask area 0.1 이하
- 아래 그림에서 DAVIS, MOSE, YouTubeVOS와의 mask size 분포를 비교
SA-V training, validation and test splits
- Data split
- Video author와 geographic location을 기반으로 SA-V 데이터셋을 나누어 유사한 object의 minimal overlap을 보장
- SA-V val 및 SA-V test set를 만들기 위해, video를 선택할 때 challenging target에 초점을 맞춥
- Annotation 작업자는 아래와 같은 challenging target을 식별
- 복잡한 가림 (complex occlusion)
- 사라짐/재등장 패턴 (disappearance/re-appearance pattern)
- Data engine Phase 1 설정으로 6 FPS에서 annotation
- Composition
- SA-V val set는 293개의 masklet, 155개의 video
- SA-V test set는 278개의 masklet, 150개의 video
Internal dataset
- Composition
- 추가 학습을 위해 내부적으로 사용 가능한 licensed video data를 사용
- 내부 데이터셋은 Phase 2 및 Phase 3에서 annotation 된 62.9K개의 video와 69.6K개의 masklet으로 구성
- Phase 1에서 annotation 된 96개의 video와 189개의 masklet으로 Internal-test 구성
6. Zero-shot experiments
6.1. Video tasks
6.1.1. Promptable video segmentation
- Overview
- User experience와 유사한 interaction 환경을 시뮬레이션하여 promptable video segmentation을 평가
- Offline과 online 두 가지 설정으로 evaluation 진행
- Offline evaluation
- Video를 여러 번 통과하여 가장 큰 model error가 발생한 frame을 선택해 interaction
- Online evaluation
- Video를 한 번만 통과하면서 frame을 annotation
- Dataset and evaluation
- 9개의 dense annotation zero-shot video 데이터셋에서 Nclick=3 으로 평가
- SAM+XMem++, SAM+Cutie 두 가지 baseline을 생성
- XMem++는 한 frame 또는 여러 frame에서 mask input을 기반으로 video segmentation을 생성
- SAM은 initial mask 제공 또는 output refinement에 사용
- Cutie는 여러 frame에서 mask input을 허용하도록 수정
- Results
- 아래 그림에서 의 interaction된 frame에 대한 평균 & 정확도 비교
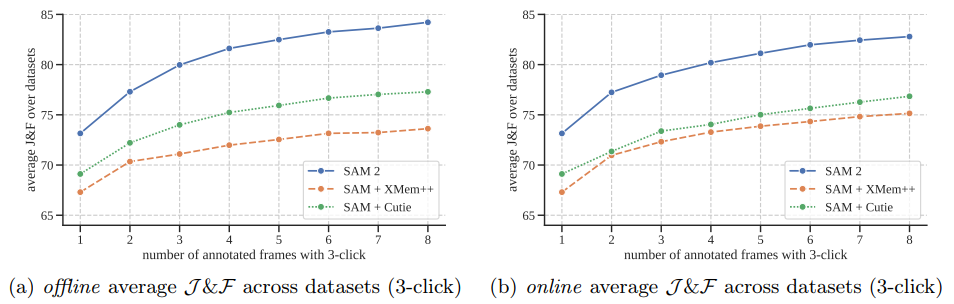
- SAM 2는 offline 및 online evaluation 설정 모두에서 SAM+XMem++ 및 SAM+Cutie를 능가
- SAM 2는 더 적은 interaction으로 high-quality video segmentation을 생성하고 추가 prompt를 통해 결과를 계속 정제할 수 있음
- 아래 그림에서 의 interaction된 frame에 대한 평균 & 정확도 비교
6.1.2. Semi-supervised video object segmentation
- Overview
- Video object segmentation(VOS)에서 첫 번째 frame에만 click, box, mask prompt를 사용하여 semi-supervised 방식으로 평가
- 첫 번째 video frame에서 1, 3, 5개의 click을 interactive 하게 샘플링 후, object를 tracking
- Comparison
- XMem++, Cutie와 비교
- SAM은 click과 box prompt에 사용, mask prompt의 경우 기본 설정 사용
- Evaluation metrices
- & 정확도 사용 (VOST는 J metric)

- 위 테이블은, 7개의 video 데이터셋에 대한 semi-supervised VOS 평가에서 다양한 prompt를 사용한 zero-shot 정확도 비교 (평균 J&F 값)
- 17개의 데이터셋에서 다양한 input prompt 사용
- SAM 2는 non-interaction VOS task에서도 우수한 성능을 보여줌
- & 정확도 사용 (VOST는 J metric)
6.1.3. Fairness evaluation
-
Objective
- SAM 2의 fairness(공정성)를 평가
- EgoExo4D (Grauman et al., 2023) 데이터셋에서 사람 카테고리에 대해 annotation 수집
- Video의 주체가 제공한 self reported demographic information 사용
- SA-V val 및 test set와 동일한 annotation 설정 적용
- 20초 분량의 third-person(외부) 시점 video clip에서 평가
-
Method and results
- 첫 번째 frame에서 1-click, 3-click 및 ground-truth mask prompt를 사용해 평가
- 아래 Table 5에서 성별 및 연령에 따라 사람을 segmentation한 SAM 2의 J&F 정확도 비교
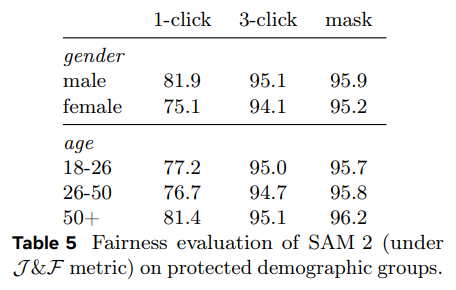
- 3-click과 GT mask prompt에서 큰 차이 없음
- 1-click 예측을 수동으로 검사한 결과, model이 자주 전체가 아닌 사람의 일부를 예측함
- 사람이 올바르게 segmentation 된 clip으로 제한할 때 1-click의 차이가 크게 줄어듦
(J&F 남성 94.3, 여성 92.7) - 이는 prompt의 모호성 때문일 수 있음
6.2 Image tasks
Evaluation method
- SAM 2의 성능을 "Segment Anything" task에서 37개의 zero-shot 데이터셋을 대상으로 평가
- 여기에는 SAM에서 이전에 평가에 사용된 23개의 데이터셋이 포함

- 위 Table 6에서는 1-click과 5-click mIoU를 비교, A100 GPU에서 측정
- 추가 데이터 사용 없이도 속도는 6배 빨라짐
- 이는 SAM 2의 더 작지만 효율적인 Hiera image encoder의 영향
- SA-1B 및 비디오 데이터 혼합으로 학습 시 정확도가 23개의 데이터셋에서 평균 61.4%까지 향상
- 또한 SA-23에서의 비디오 banchmark와 새로 추가된 14개의 비디오 데이터셋에서 큰 성과를 보임
7. Comparison to state-of-the-art in semi-supervised VOS
Comparison Targets and Methods
- 본 논문에서는 주로 일반적이고 interactive PVS task에 집중
- 하지만, 구체적으로 semi-supervised VOS setting (첫 frame에서 ground-truth mask 제공)에 대해서도 다룸
- 아래 Table 7에서는 기존 SOTA 방법과 비교하여 정확도를 비교

- 두 가지 버전의 SAM 2를 평가, 각각 Hiera-B+/-L image encoder 크기를 사용해 속도와 정확도 간의 균형을 조절
- SAM 2는 정확도와 추론 속도(FPS) 모두에서 기존의 SOTA 방법보다 유의미한 개선을 보임
- 더 큰 image encoder를 사용하는 것이 전반적인 정확도 향상에 기여
- 또한 SA-V val 및 test set에서 대부분의 기존 방법들이 유사한 정확도에 머물러 있음을 발견
- LVOS banchmark 결과에서도 SAM 2가 long-term video object segmentation에서 눈에 띄는 성과를 보임
8. Data and model ablations
Evaluation of Design Decisions
- SAM 2의 design decision에 대한 ablation 실험을 제시
8.1. Data ablations
Data mix ablation
- 아래 Table 8에서는 SAM 2가 다양한 데이터 혼합으로 학습되었을 때의 정확도를 비교
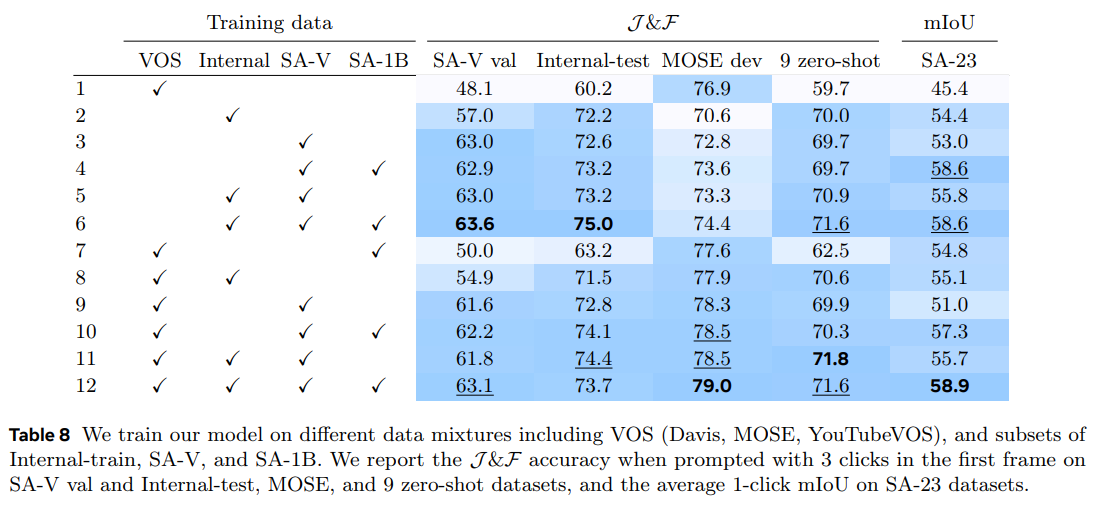
- SA-1B에 대해 사전 학습 후 각 설정에 대해 별도의 model을 학습
- 고정된 iteration(200k)과 batch size(128)에서 실험, 데이터만 변경
- SA-V val set, MOSE, 9개의 zero-shot video banchmark, SA-23 task에서 정확도를 비교
- VOS 데이터셋으로만 학습된 model(Davis, MOSE, YouTubeVOS)은 in-domain MOSE dev에서 좋은 성과를 내지만 다른 데이터셋에서는 성과가 좋지 않음
- Data engine 데이터를 학습에 추가하면 9개의 zero-shot 데이터셋에서 평균 성능이 12.1% 향상됨
- SA-1B image를 추가하면 image segmentation task에서 성능이 향상되지만 VOS 성능은 저하되지 않음
- 모든 데이터셋(VOS, SA-1B, data engine data)을 혼합하면 최상의 결과를 얻음
Data quantity ablation
- SA-1B에서 사전 학습된 후 SA-V의 다양한 크기로 학습된 SAM 2를 평가
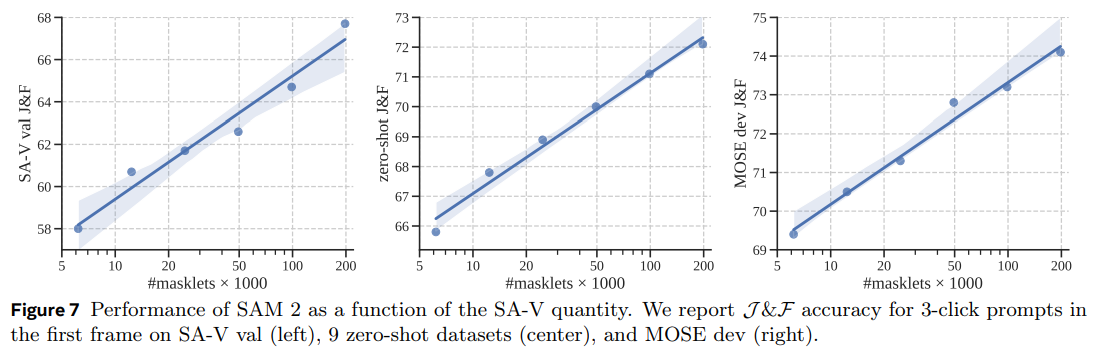
- Average J&F score (3-click input 시)를 비교
Data quality ablation
- 아래 Table 9에서는 quality filtering strategies를 실험

- SA-V에서 50k의 masklet을 무작위로 또는 annotator가 가장 많이 edit 한 masklet을 선택해 sub-sampling
- Edited frame 수를 기준으로 필터링하면 데이터의 25%만 사용하여도 강력한 성능을 보이며 무작위 샘플링보다 우수
- 그러나 190k SA-V masklet 전체를 사용하는 것보다 성능은 낮음
8.2. Model architecture ablations
Overview
- Model의 다양한 design decision을 유도한 ablation 실험을 제시
- Video (J&F)와 image (mIoU) task에서의 segmentation 정확도 및 video segmentation 속도 (FPS)를 비교
- Image와 video component에 대한 design 선택은 주로 독립적임
8.2.1 Capacity ablations
-
Input size
- 학습 중 fixed resolution과 길이의 frame sequence를 샘플링

- 위 Table에서 처럼, resolution이 높을수록 image와 video task에서의 성능이 크게 향상
- Frame 수를 늘리면 video banchmark에서 성능이 눈에 띄게 향상되며, 속도와 정확도 간의 균형을 맞추기 위해 기본값을 8로 설정
- 학습 중 fixed resolution과 길이의 frame sequence를 샘플링
-
Memory size
- Memory의 최대 개수 을 늘리면 일반적으로 성능이 향상됨
- 그러나 아래 Table에서처럼 약간의 변동이 있을 수 있음

- 과거 6 frame을 기본값으로 사용하여 시간적 맥락 길이와 계산 비용 간의 균형을 맞춤
- Memory channel의 수를 줄여도 성능 저하는 크지 않으며, 저장 공간은 4배 더 적게 필요
-
Model size
- Backbone이나 memory-attention의 용량이 많을수록 성능이 향상됨

- Backbone을 확장하면 image와 video 지표 모두에서 성능이 향상되며, memory-attention을 확장하면 video 지표에서만 향상
- 기본적으로 B+ backbone을 사용하여 속도와 정확도 간의 균형을 맞춤
- SAM 2는 B+ backbone을 사용하더라도 SAM ViT-H보다 성능이 우수
- Backbone이나 memory-attention의 용량이 많을수록 성능이 향상됨
8.2.2 Relative positional encoding
- 기본적으로 image encoder와 memory attention 모두에서 absolute positional encoding을 사용
- Comparison
- SAM은 모든 backbone layer에 relative positional biases(RPB)를 추가
- Bolya et al. (2023)은 모든 global attention layer를 제외한 RPB를 제거하고 "absolute-win" positional encoding을 도입하여 속도를 크게 향상시킴

- 본 논문에서는 backbone에서 모든 RPB를 제거하여 성능 저하 없이 속도를 크게 향상
- 2d-RoPE를 memory attention에서 사용하는 것이 유익함을 발견
8.2.3 Memory architecture ablations
-
Recurrent memory
- Memory feature를 memory bank에 추가하기 전에 GRU에 feed를 input하는 방식의 효과를 조사
GRU (Gated Recurrent Unit)
- RNN의 variation으로, 시간 순서에 따른 데이터의 long term dependency를 다룸
- GRU는 update gate와 reset gate라는 두 개의 gate를 사용하여, 정보의 흐름을 selective 하게 제어
- 이로 인해 GRU는 LSTM보다 구조가 단순하면서도 유사한 성능을 제공하며, 학습 속도가 빠른 것이 특징
- LVOSv2에서 약간의 개선을 제외하고는 GRU 상태를 사용하는 것이 성능을 향상시키지 못함
- Memory feature를 직접 memory bank에 저장하는 것이 더 간단하고 효율적임
- Memory feature를 memory bank에 추가하기 전에 GRU에 feed를 input하는 방식의 효과를 조사
-
Object pointers
- 다른 frame의 mask decoder output에서 object pointer vector에 cross-attend 하는 것의 영향을 조사

- 평균 성능 향상은 없지만 SA-V val 데이터셋과 LVOSv2 banchmark에서 성능이 크게 향상됨
- 따라서 memory bank와 함께 object pointers에 cross-attend 하는 것을 기본으로 함
- 다른 frame의 mask decoder output에서 object pointer vector에 cross-attend 하는 것의 영향을 조사
9. Conclusion
Conclusions
- Segment Anything을 video domain으로 확장한 연구로,
- (i) Promptable segmentation task를 video로 확장하고,
- (ii) Video에 적용될 때 SAM architecture가 memory를 사용할 수 있도록 하고,
- (iii) Video segmentation을 위한 학습 및 benchmark를 위한 다양한 SA-V 데이터셋을 제시
- SAM 2는 visual recognition에서 중요한 발전을 의미
Limitations
- SAM 2는 image와 video에서는 우수한 성능을 보이나,
짧은 변화, 군중 장면, 얇거나 미세한 물체, 비슷한 모양의 물체를 tracking 하는 데에는 여전히 한계가 있음 - Model이 object를 잃거나 error를 발생시킬 경우, refinement clicks으로 prediction을 수정할 수 있음
- SAM 2는 각 object를 개별적으로 처리하며, object 간의 communication이 없음
- 이 접근 방식의 간단함에도 불구하고 효율성을 높이기 위해서는 shared object-level contextual information이 필요
- 데이터 검증은 인간 annotator가 담당하며, 자동화가 필요

AI Research Engineer