[논문 정리] Medical SAM 2: Segment Medical Images As Video Via Segment Anything Model 2
https://arxiv.org/abs/2408.00874
1. Introduction
- Large scale model들은 다양한 application 분야에서 강력한 zero-shot 성능을 보임
- Medical image segmentation 분야에서는 Segment Anything Model(SAM)이 특히 주목받고 있음
- SAM 2는 SAM을 기반으로 개발된 real-time object segmentation model로
- Static image 와
- Video stream 에서 모두 사용 가능
- SAM 2는 real-time 처리 능력을 갖추고 있으며, object의 움직임과 가림 현상이 있는 복잡한 시나리오를 처리하는 데 강점이 있음
- Medical image segmentation은 진단과 image 기반 수술에 필수적인 task으로, 최근에는 일관성과 정확성을 높이기 위해 automatic segmentation 이 주목받고 있음
- Deep learning 기술의 발전으로, 전통적인 CNN 뿐만 아니라 비교적 최근 개발된 ViT model들이 medical image segmentation task에 성공적으로 적용되고 있음
Model generalization problems
- 특정 organ이나 tissue를 target으로 학습된 model이 다른 target에 쉽게 adaptation 하지 못하는 문제를 의미
- 이 문제 때문에 각 segmentation target마다 별도의 model이 필요
One-prompt Segmentation
- 사용자가 첫 번째 frame에서 원하는 영역을 지정하면, 이후의 모든 frame에서도 동일한 영역을 자동으로 segmentation하는 기능
- MedSAM-2 model이 이 기능을 효과적으로 구현
Characteristic of MedSAM-2
- MedSAM-2는 medical image를 video으로 간주하여 2D 및 3D medical image segmentation에 적용 가능하도록 설계된 model
- One-prompt Segmentation을 통해 사용자가 첫 frame에서만 prompt를 제공하면, 이후 모든 frame에서 자동으로 segmentation
- MedSAM-2는 zero-shot generalization이 가능하여 새로운 visual contents에도 adaptation 가능
- 사용자가 중간에 target segmentation 영역을 수정할 수 있는 유연성을 제공하여, medical image 분석 시 편리함을 크게 향상
Model evaluation
- MedSAM-2는 15개의 다른 benchmark에서 26개의 개별 task를 평가한 결과, 기존의 fully-supervised segmentation model과 SAM 기반의 interactive model 보다 우수한 성능을 보임
Contributions
- SAM-2 기반 medical image segmentation model인 MedSAM-2를 처음으로 제안
- medical image을 video으로 간주하는 철학을 도입하여, MedSAM-2에서 One-prompt Segmentation 기능을 구현
- Confidence Memory Bank와 Weighted Pick-up 모듈을 설계하여 기술적으로 One-prompt Segmentation을 가능하게 함
- MedSAM-2는 15개의 benchmark와 26개의 개별 task에서 뛰어난 성능을 보이며, state-of-the-art를 달성
2. Method
2.1. Applying SAM 2 on 3D medical images
- 3D medical image를 처리하는 일반적인 접근 방식은 이들을 2D slice sequence로 간주하는 것
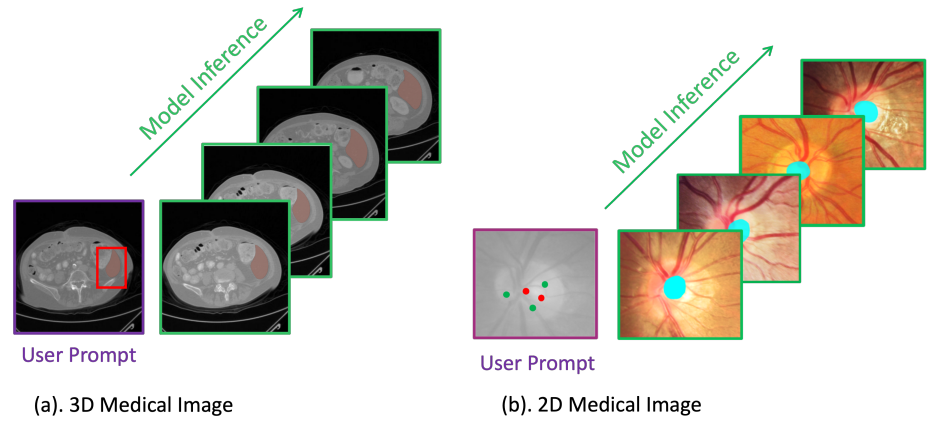
- 하지만 연속적인 slice 간의 고유한 연관성을 활용하면, 단일 slice 2D image 처리에서 발생하는 여러 문제를 해결할 수 있음
- 예를 들어, medical image에서 organ이나 tissue는 환자나 medical device의 움직임으로 인해 edge가 흐릿해질 수 있음
- 이 경우 인접한 slice의 맥락 정보를 활용하여 slice의 품질이 낮아도 정확한 segmentation을 할 수 있음
- SAM 2는 video segmentation을 위한 사전 학습된 기본 network로, 3D video data를 처리할 수 있으며, video frame 전반에 걸쳐 object를 tracking하고 segmentation하도록 설계됨
- 3D medical image는 natural video와 유사하게 연속적 특성을 가짐
- 이 특성 덕분에 SAM 2를 사용하면 각 slice에 추가적인 prompt 없이도 3D image 전체에서 target을 tracking하고 segmentation 성능을 향상시킬 수 있음
2.2. From universal iVOS to one-prompt segmentation
- SAM 2를 3D medical image에 적용하는 것은 간단하지만, 2D image segmentation에서의 고유한 장점은 즉시 드러나지 않음
- 그러나 동일한 종류의 organ를 포함하고 있지만 서로 다른 내용을 가진 일련의 2D medical image를 video sequence로 간주하면, SAM 2가 다른 방법에서는 드물게 달성되는 'One-prompt Segmentation' 기능을 구현할 수 있음
One-prompt Segmentation
- 이전 연구에 따르면, 사용자가 학습된 model에 대해 하나의 prompt만 제공하면 model이 재학습이나 fine tuning 없이도 새로운 task를 효과적으로 수행할 수 있음
- SAM 2의 video segmentation 기능을 2D image sequence 처리에 적용하면 One-prompt Segmentation을 달성하는 효과적인 방법이 될 수 있음
- 이 개념을 수식으로 설명하면:
- 다양한 medical image segmentation task 집합 가 있다고 가정
- 각 task 는 image-label pair 로 주어짐
- Fully-supervised 방식의 segmentation 방법은 input image 로부터 segmentation map 를 추정하는 함수 를 학습
- 그러나 이 함수 는 특정 task 에만 적용
- 반면, universal interactive video object segmentation(iVOS)에서는 sequence video frame을 와 로 나타내고, unseen object 를 포함한 image 와 target에 대한 prompt 집합 를 이용해 model이 에서 object 를 generalization 하도록 유도
- One-Prompt Segmentation에서는, 함수 를 학습하여 모든 medical task s에 적용할 수 있음
- 여기서 는 고정된 템플릿 image 와 연관된 prompt 로 구성
iVOS와 One-Prompt Segmentation의 관계
- iVOS의 image-label pair는 반드시 순차적일 필요가 없어, One-Prompt Segmentation은 시간적 연관성이 없는 다른 image에서도 동일한 object를 segmentation 가능
- iVOS의 prompt는 하나의 image에만 적용되므로, 처리된 image 집합을 video sequence로 간주하면 iVOS에서 One-Prompt Segmentation으로의 전환이 용이
- 두 패러다임은 기술적으로 유사할 수 있지만, 다양한 application 분야에서 의미가 다름
- 특히 One-Prompt Segmentation은 임상 환경에서 사용하기 편리
- Prompt가 있는 샘플 하나만으로 새로운 task에 model이 adaptation 할 수 있어, 복잡한 학습이나 fine tuning이 필요하지 않음
- 이는 컴퓨터 과학 배경이 없는 임상의들에게도 큰 장점을 제공
2.3. Segment medical images as videos
3D Medical Images
- SAM 2 model을 3D medical image에 적용하는 방법 설명
- 3D medical image는 시간적 연관성이 있는 인접 slice들로 구성되며, video data와 유사하게 처리됨
- SAM 2 model의 memory 시스템을 사용하여 이전 slice와 그 prediction 값을 참조하면서 연속적인 slice를 segmentation
- 핵심 개념은 frame embedding을 memory와 과거 prediction으로 조건화하는 것
- Memory bank에 저장된 memory는 neural network 기반의 memory encoder를 통해 encoding
- Memory embedding을 통해 input image embedding을 강화하는 memory attention을 사용
- Memory attention은 주로 attention mechanism에 기반하여 수행
- Input embedding이 memory embedding으로 조건화된 후, decoder로 전달되어 segmentation prediction을 수행
- Segmentation 결과는 memory bank에 추가되어 후속 slice의 segmentation tracking에 도움
2D Medical Images
- 2D medical image를 처리하는 방법은 SAM 2와 다르게 설정
- 동일한 organ나 tissue이 포함된 2D image를 ‘medical image flow’으로 그룹화
- 이 flow는 시간적 관계는 없지만, segmentation 목적으로 video sequence처럼 처리
- 사용자가 flow 내에서 임의의 image를 prompt하면, MedSAM-2는 해당 image의 segmentation을 prediction하고 이 prediction을 flow의 다른 image로 propagation
- 이를 위해 ‘confidence-first’ memory bank을 도입하여 model의 confidence가 높은 결과를 저장
- Confidence는 model prediction의 확률을 기반으로 계산
- Memory bank에 저장되는 템플릿은 가장 정확한 샘플을 포함하여 noise의 영향을 최소화
- Image의 다양성을 고려해 memory bank에 추가하며, image embedding의 유사성을 통해 평가
- Input image와 memory bank의 정보를 결합할 때 모든 정보를 동일하게 결합하는 대신 weight selection 전략을 사용
- Input image와 유사한 image에 더 높은 weight를 부여하여 propagation를 용이하게 함
- 학습 단계에서는 calibration head를 사용하여 model의 prediction confidence를 조정
- 이 calibration은 model의 confidence를 prediction 정확도와 일치시켜 confidence memory bank의 효과를 높임
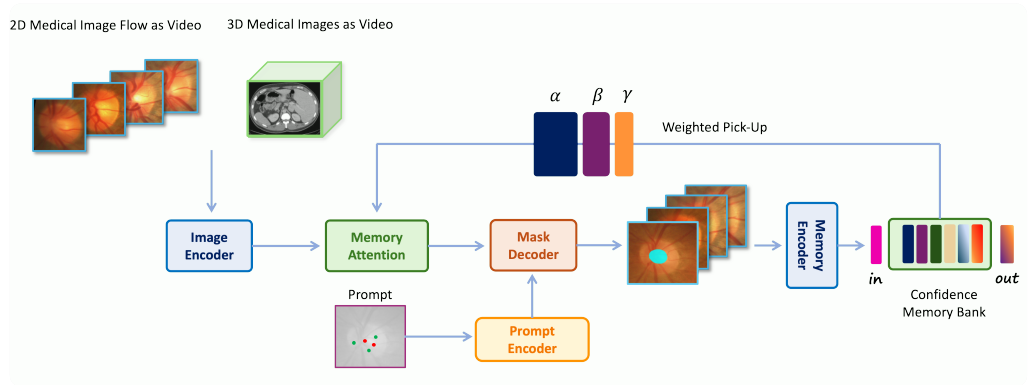
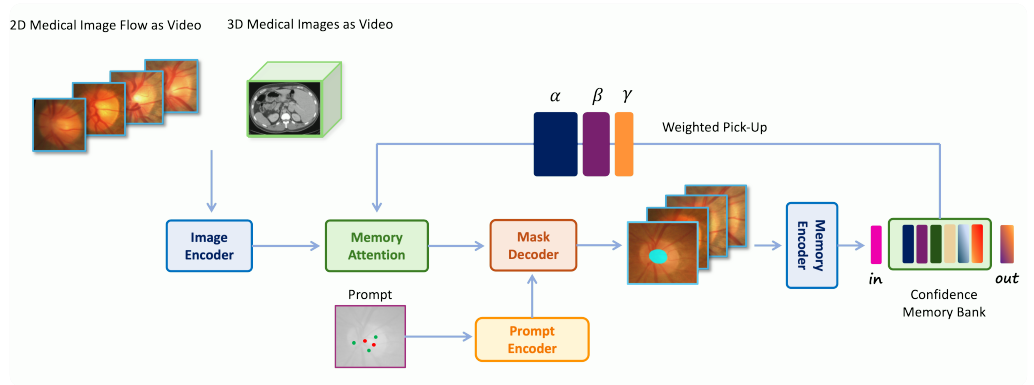
2.4. MedSAM-2 Architecture
Architecture Overview
-
MedSAM-2는 image encoder, memory encoder, memory attention으로 구성
-
SAM 2와 유사한 기본 architecture를 가지고 있으며, 각 구성 요소의 간단한 소개 제공
Encoder and Decoder
- Network의 encoder와 decoder는 SAM의 encoder와 decoder와 유사
- Encoder는 hierarchical vision transformer를 사용하여 input image를 embedding으로 변환
- Decoder는 lightweight bidirectional transformer로, prompt embedding과 image embedding을 통합
- Prompt embedding은 prompt encoder에서 생성되며, 사용자의 prompt를 처리하여 대응하는 embedding을 추출
Memory Attention Component
- Memory attention component는 여러 개의 attention block으로 구성
- 각 attention block은 self-attention와 cross-attention mechanism을 포함
- Frame의 memory와 object pointer를 memory bank에 저장
- Object pointer는 각 frame의 mask decoder output token에서 파생된 semantic information vector로 구성
- 이 구조는 사용자가 prompt를 제공할 때, memory attention mechanism이 이를 반영하여 3D image segmentation 결과를 개선하도록 함
3. Experiment
3.1. Dataset
- 5개의 서로 다른 medical image segmentation dataset을 사용하여 실험 수행, 자동 생성된 mask prompt 사용
Generalization performance evaluation
- REFUGE2 dataset을 사용하여 fundus image의 optic disk 및 optic cup segmentation
- BraTs 2021 dataset을 사용하여 MRI scan에서 뇌 종양 segmentation
- TNMIX benchmark를 사용하여 초음파 image에서 갑상선 결절 segmentation, TNSCUI와 DDTI dataset 결합
- ISIC 2019 dataset을 사용하여 피부 병변(흑색종 또는 모반) segmentation
Additional 2D image segmentation task evaluation
- KiTS23, ATLAS23, TDSC, WBC dataset에서는 point prompt 사용
- SegRap, CrossM23, REFUGE dataset에서는 bounding box prompt 사용
- CadVidSet, STAR, ToothFairy dataset에서는 mask prompt 사용
3.2. Evaluation metrics
Intersection over Union (IoU)
- IoU는 object detector의 정확도를 평가하는 지표로, prediction된 segmentation과 실제 정답 간의 겹치는 영역의 비율을 측정
Dice Score
- 두 샘플 간의 유사성을 비교하는 통계적 도구, 특히 medical image 분석에서 object의 크기에 대한 민감도로 인해 많이 사용
Hausdorff Distance (HD95) Metric
- 두 점 집합 간의 불일치를 측정하는 지표, object boundary의 정확도를 평가하는 데 사용
- Boundary 간의 최대 거리를 측정하지만, outlier에 민감할 수 있음, HD95는 거리의 95번째 백분위수만을 고려하여 보다 견고한 측정값을 제공
3.3. Results
3.3.1. Performance of univeral medical image segmentation
-
MedSAM-2를 여러 SOTA medical image segmentation 방법들과 비교
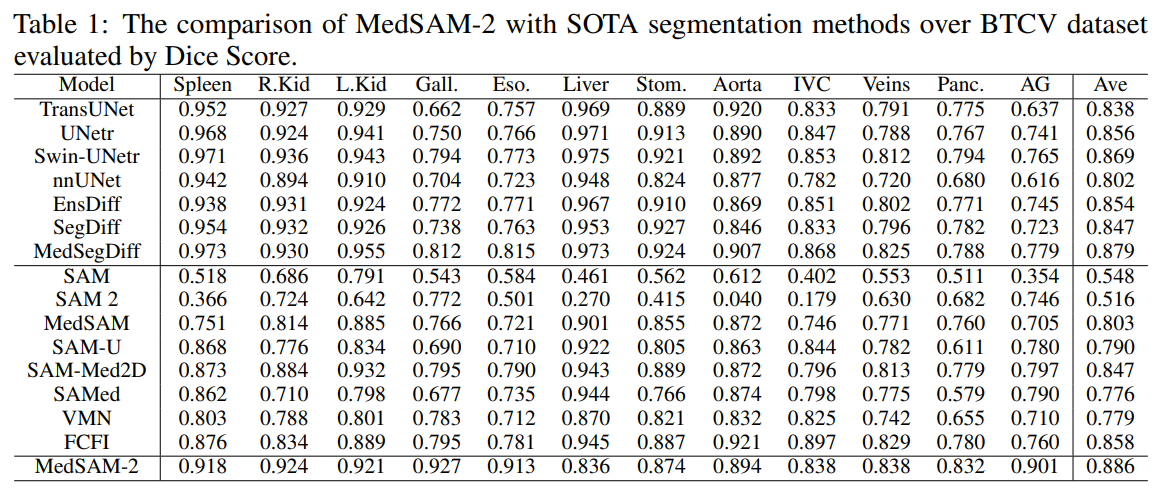
-
Dice score를 사용하여 성능 측정
-
MedSAM-2는 BTCV dataset에서 이전 model들에 비해 큰 발전을 보여줌
- Average dice score: 88.57%
- 이전의 fully-supervised 기반 SOTA model MedSegDiff를 0.70% 초과
- Interactive model 중에서 가장 높은 성능 기록
- MedSAM-2는 적은 prompt로 더 나은 결과를 도출
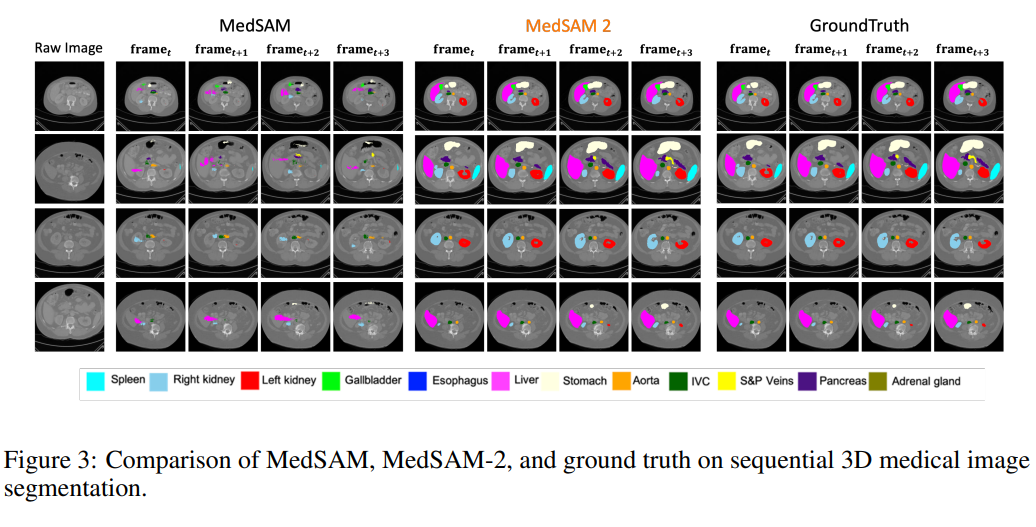
2D medical image에서의 성능
- 다양한 image modality와 특정 task에 대한 SOTA model과 비교
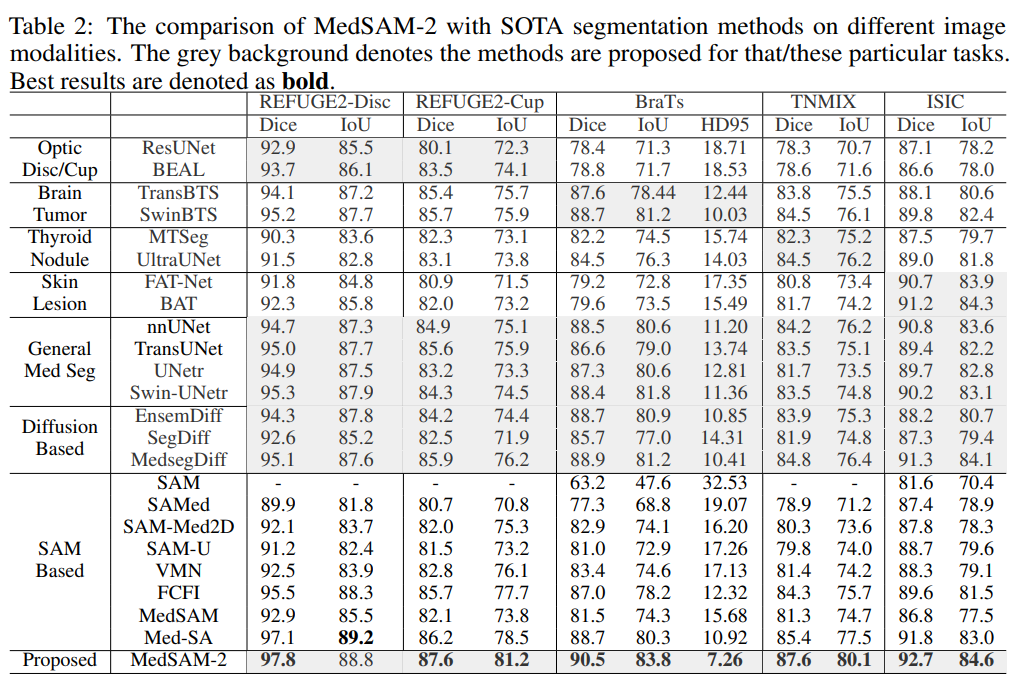
- Tasks
- Optic Cup segmentation: ResUnet, BEAL
- Brain Tumor segmentation: TransBTS, SwinBTS
- Thyroid Nodule segmentation: MTSeg, UltraUNet
- Skin Lesion segmentation: FAT-Net, BAT
- MedSAM-2는 5가지 task 모두에서 비교 model들을 초과 달성
- Dice score 개선
- Optic-Cup에서 2.0%, Brain Tumor에서 1.6%, Thyroid Nodule에서 2.8%
- Interactive model들보다 우수한 성능 기록
- Dice score 개선
3.3.2. One-prompt segmentation performance under different prompts
One-Prompt 설정에서의 성능 평가
-
MedSAM-2를 다양한 few/one-shot 학습 model과 비교
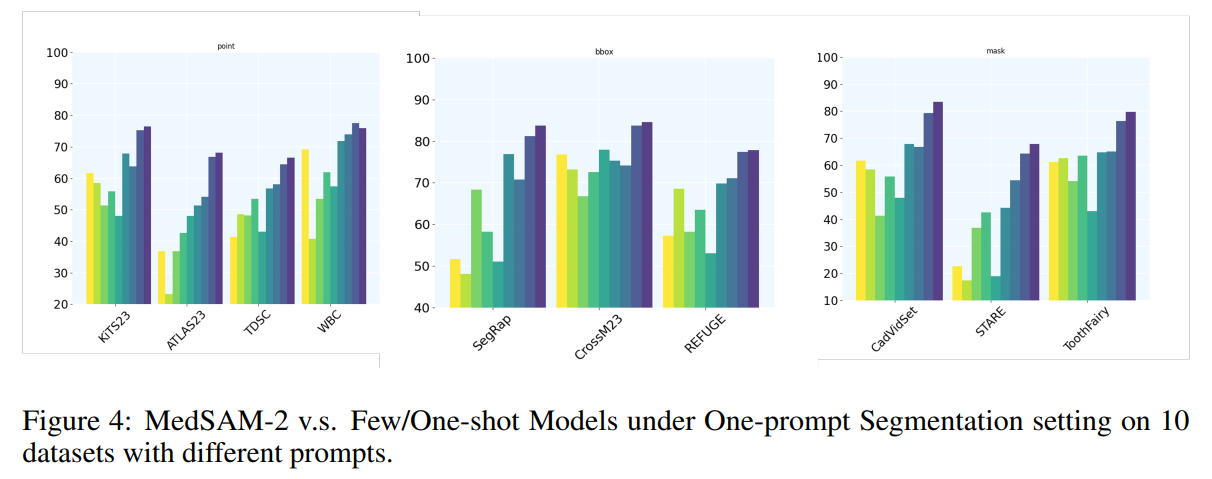
-
MedSAM-2는 모든 model을 유의미한 차이로 초과 달성
-
One-prompt Segmentation model Wu & Xu (2024)와 비교해도 10개 task 중 9개 task에서 우수한 성능 기록
-
Mask prompt가 제공되는 경우 MedSAM-2는 평균적으로 3.1% 더 높은 성능 기록, 가장 큰 차이
4. Conclusion
MedSAM-2
- MedSAM-2는 medical image segmentation 분야에서 중요한 발전을 의미
- SAM 2 framework를 통합하고 video와 유사한 접근 방식을 채택하여 2D 및 3D medical image에서 고급 segmentation 기술의 적용을 확장
Advantage of One-prompt segmentation
- 지속적인 user interactive의 필요성을 크게 줄여 보다 효율적이고 user friendly task flow을 제공, 특히 임상 환경에서 유리
Performance evaluation
- 다양한 imaging modality에서의 종합 평가를 통해 MedSAM-2는 현재의 최신 model들을 지속적으로 초과 달성, 우수한 generalization 능력과 강력한 성능을 제공
The implications of this research
- Video segmentation 원칙을 medical imaging에 적용함으로써 진단 도구의 정밀도와 유용성을 크게 향상시킬 수 있음을 시사
Future works
- Real-time 처리와 더 다양한 data 유형 통합에 대한 접근 방식의 추가 개선을 기대, medical 분야 외의 복잡한 segmentation 시나리오에 대한 MedSAM-2의 adaptation 가능성 탐색 예정

AI Research Engineer