[논문 정리] Hiera: A Hierarchical Vision Transformer without the Bells-and-Whistles
https://arxiv.org/abs/2306.00989
1. Introduction
- Vision Transformers (ViTs)는 간단한 구조로도 높은 accuracy를 자랑하며, computer vision 분야에서 중요한 역할을 해옴
- 특히 MAE(Masked Autoencoders)와 같은 pre-training 전략을 사용해 효율적으로 학습 가능
- 그러나 ViTs는 network 전반에 걸쳐 동일한 spatial resolution와 channel 수를 사용해 parameter를 비효율적으로 사용함
- 이는 초기 stage에서 높은 resolution와 적은 channel을, 이후 stage에서 낮은 resolution과 많은 channel을 사용하는 "hierarchical" model들과 대비
- Swin이나 MViT와 같은 hierarchical Vision Transformer model들은 점점 복잡해지고 있지만, 이러한 복잡성은 model을 느리게 만듦
- 본 논문에서는 ViTs의 단순성을 유지하면서 불필요한 복잡성을 제거하고, MAE pre-training을 통해 성능을 향상시킬 수 있다고 주장
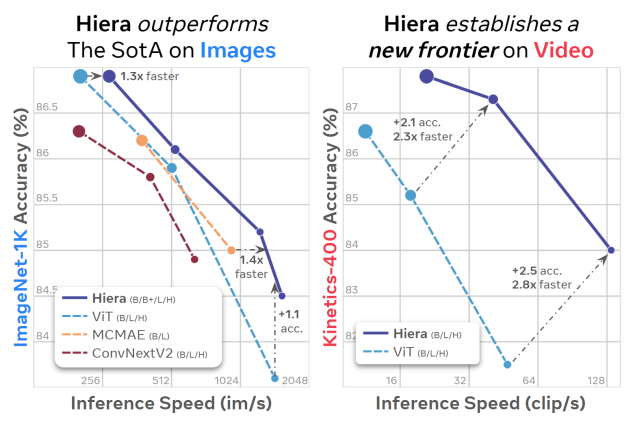
- 결과적으로, 본 논문의 Simple Hierarchical Vision Transformer (Hiera)는 기존 model보다 더 빠르고 정확하며, 여러 도메인과 task에서 우수한 성과를 보임
3. Approach
Goal
- 강력하고 효율적인 multi-scale vision transformer를 단순하게 설계하는 것
Proposed method
-
High accuracy vision transformer model을 만들기 위해 convolution, shifted windows, attention bias와 같은 특수한 module이 반드시 필요하지는 않음
-
대신, 복잡한 구조 변경 대신 강력한 pretext task를 통해 이러한 bias를 학습시키는 전략을 사용
-
기존의 hierarchical vision transformer에서 복잡한 요소들을 제거하고, 강력한 pretext task인 Masked Autoencoders(MAE)를 활용해 학습
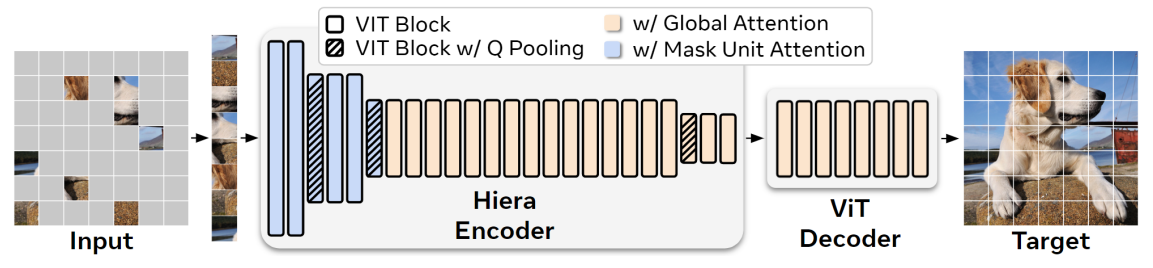
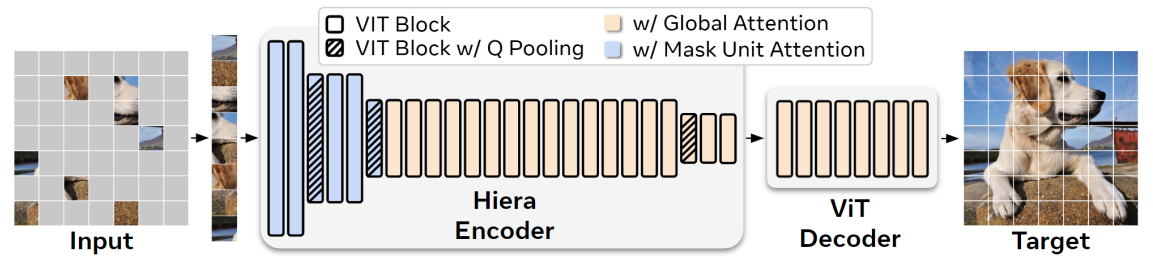
- MAE는 network가 masking 된 input patch를 재구성(reconstruction)하도록 하여 ViTs가 위치 감지 능력을 학습할 수 있게 함

- MAE pre-training은 효율적이지만, 기존 hierarchical model에서는 위 그림에서 처럼 2D grid가 깨지는 문제가 발생
Solution
- Model의 내부 resolution인 "token"과 MAE masking이 적용되는 "mask unit"을 구분

- 32×32 pixel 영역을 mask unit으로 지정하고, 이를 통해 hierarchical model을 평가할 때 mask unit을 다른 token과 분리하여 취급하는 방법을 사용
3.1. Preparing MViTv2
- Base architecture로 MViTv2를 선택

- 이 model은 작은 3×3 kernel을 사용해 mask unit separation 및 pad trick에 가장 적합
MViTv2 overview
- Hierarchical model로, 네 개의 stage에서 multi-scale representation을 학습
- 초기에는 작은 channel 용량과 높은 spatial resolution로 low-level feature를 modeling하고, 이후 stage에서 점점 더 복잡한 high-level feature를 modeling 하기 위해 channel과 spatial resolution을 교환
- Key feature
- Self-attention을 계산하기 전에 local attention 기능을 수행하는 pooling attention 사용

- 또한, absolute position embedding 대신 아래 두 가지를 사용
- Decomposed relative position embedding
- Attention block 내부에서 pooling 된 Q token을 건너뛰는 residual pooling connection
- Self-attention을 계산하기 전에 local attention 기능을 수행하는 pooling attention 사용
- Applying MAE
- MViTv2는 총 세 번 2×2 down-sampling을 하며, 4×4 pixel의 token 크기를 사용하기 때문에, 32×32 크기의 mask unit을 사용
- 이렇게 하면 각 mask unit이 각 stage에서 최소 하나의 고유 token을 포함하도록 보장
- 또한, convolution kernel이 제거된 token에 영향을 주지 않도록 mask unit을 batch dimension으로 이동시켜 pooling을 처리한 후, 다시 원래 위치로 복원해 self-attention이 global 하게 이루어지도록 함
3.2. Simplifying MViTv2
Objective
- MAE로 학습하면서 MViTv2의 비필수적인 요소들을 제거하고, image classification 성능을 유지하면서 단순화된 model을 만드는 것
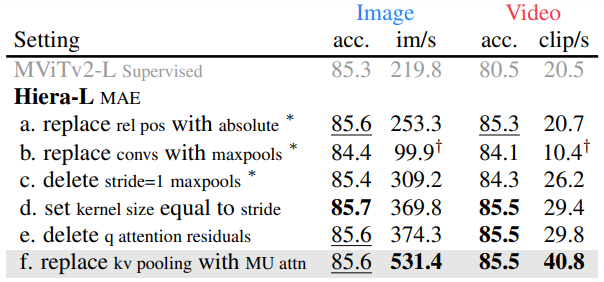
Relative Position Embeddings
- MViTv2에서는 기존의 absolute position embedding 대신, block마다 attention에 더해지는 relative position embedding을 사용
- 하지만 MAE 학습에서는 복잡성을 피하기 위해 absolute position embedding으로 되돌림
- 실험 결과, MAE에서는 relative position embedding이 필요하지 않으며, absolute position embedding이 훨씬 더 빠름
Removing Convolutions
- Vision-specific module인 convolution을 제거하여 불필요한 overhead를 줄이는 것 목표
- Conv layer를 maxpool로 대체했을 때, accuracy가 1% 이상 떨어졌지만, stride=1 convs를 삭제하면 accuracy를 거의 회복하면서도 model 속도가 크게 향상
Removing Overlap
- 남은 maxpool layer의 3×3 kernel 크기는 학습과 추론 시 별도의 padding 작업을 필요로 함
- 이 문제를 해결하기 위해 maxpool kernel 크기를 stride와 동일하게 설정하여 padding 작업 없이도 MAE pre-training이 가능하게 하고, 결과적으로 속도가 크게 향상
Removing the Attention Residual
- MViTv2의 attention layer에는 residual connection이 추가되어 있으나, layer 수를 최소화하여 이 connection을 안전하게 제거
Mask Unit Attention
- 마지막으로 남은 특수 module은 pooling attention
- Q pooling은 hierarchical model을 유지하기 위해 필수적이나, KV pooling은 attention matrix 크기를 줄이기 위함
- 이를 제거하는 대신, 간단한 대안으로 mask unit 내에서 local attention을 적용
- 이 방식은 속도를 크게 증가시키면서도 accuracy에 영향을 주지 않음
Hiera
-
위의 변화를 통해 "Hiera"라는 매우 간단하고 효율적인 model이 완성
-
Hiera는 image 처리에서 2.4배, video 처리에서 5.1배 더 빠르며, accuracy도 높음
- MAE 덕분에 Hiera는 매우 빠르게 학습 가능하며, 같은 조건에서 MViTv2-L보다 3배 더 빠르게 학습 가능
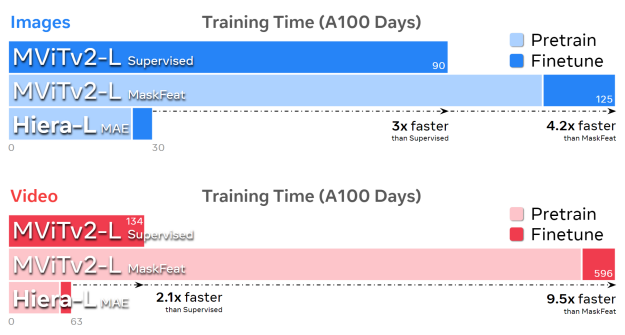
-
결과적으로, Hiera는 다양한 크기로 구현될 수 있으며, 각 실험에서 우수한 성능을 보임
4. MAE Ablations
Objective
- Hiera model의 image와 video에서 MAE pre-training 설정을 최적화하고, ImageNet-1K (IN1K)와 Kinetics-400 (K400) 데이터셋을 사용하여 성능 평가
Multi-Scale Decoder
- Hiera는 hierarchical 구조를 활용

- Encoder의 마지막 block에서만 decoder로 input을 전달하는 대신, 모든 stage의 representation을 결합하여 성능을 크게 향상
Masking Ratio
- Video에서는 image보다 더 높은 masking ratio가 필요하며, 이는 정보 중복도가 높기 때문
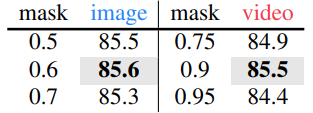
- Image에서는 optimal masking ratio는 0.6, video에서는 0.9로 나타남
Reconstruction Target
- Pixel target과 HOG target 모두 강력한 성능을 보임

- 기본적으로는 HOG target이 더 나은 성능을 보이지만, 긴 학습 시간에서는 video의 경우 성능이 같아지며, image에서는 Pixel target이 약간 더 나음
Droppath Rate
- Hiera-L model은 ViT-L보다 depth가 두 배로, drop path 적용 시 pre-training 중에 성능이 크게 향상
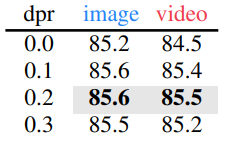
- 이는 Hiera가 MAE 작업에 overfitting될 수 있음을 시사
Decoder Depth
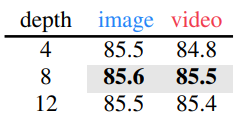
- Video에서는 더 깊은 decoder가 유의미한 이점을 가져오며, 이는 이전 연구 결과와 일치
Pretraining Schedule
- 더 긴 pre-training schedule이 성능 향상에 도움이 됨
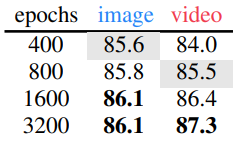
- Hiera는 400 epochs에서 ViT-L MAE보다 0.7% 더 높은 accuracy를 보였으며, 1600 epochs에서 video의 경우 800 epochs보다 0.9% 더 큰 향상을 보임
5. Video Results
Kinetics-400, -600, -700:
- Hiera-L은 Kinetics-400에서 기존 SOTA 보다 2.1% 높은 성능을 보였으며, 45% 적은 FLOPs, 43% 더 작은 model 크기, 2.3배 더 빠른 속도를 보임

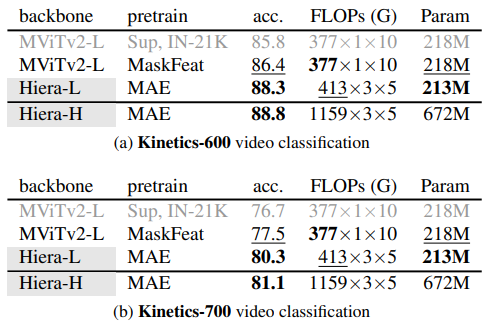
- 상위 model과 비교했을 때도 Hiera-L은 0.7% 더 높은 성능을 보이며, 3배 더 작은 크기와 3.5배 더 빠른 속도
- 또한, Hiera-L은 MViTv2-L의 supervised learning 기준 model보다 6.8% 높은 성능
Something-Something-v2 (SSv2)
- K400에서 pre-training 된 Hiera-L은 MaskFeat와 비교하여 0.6% 높은 성능을 보였으며, efficiency 면에서도 큰 차이를 보임
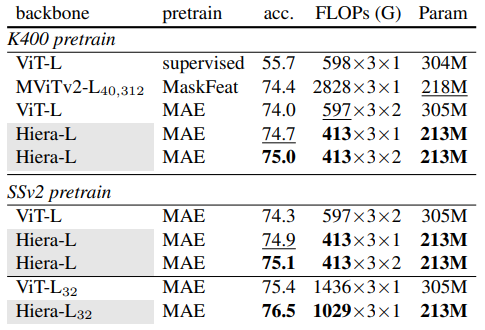
- Hiera는 224×224 resolution에서 16 frame을 사용한 반면, MaskFeat는 312×312 resolution에서 40 frame을 사용
Action Detection (AVA)
- Hiera를 사용해 K400/K600/K700에서 pre-training 한 model의 AVA v2.2 데이터셋에서의 action detection 성능을 평가
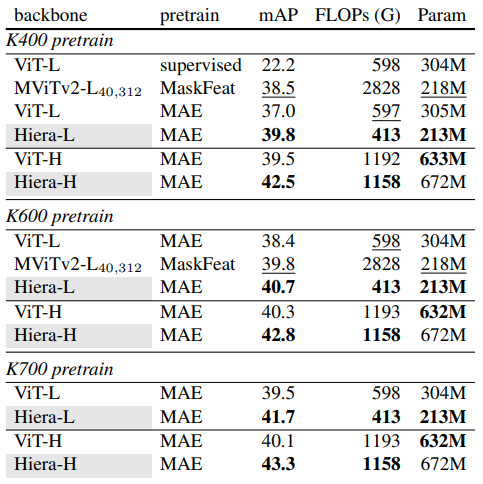
Hiera-L은 ViT-L과 비교해 2.8% 더 높은 평균 정밀도(mAP)를 기록했으며, Hiera-H는 ViT-H를 3.0% 앞섬
- Hiera는 FLOPs와 parameter 면에서도 효율적인 model임을 증명
6. Image Results
Performance on ImageNet-1K
- Hiera는 MAE pre-training을 통해 뛰어난 성능을 보여줌
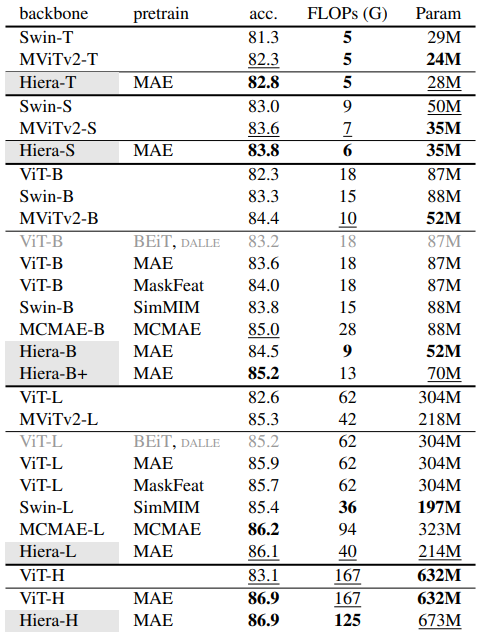
- 특히 Hiera-L MAE는 86.1%의 accuracy를 기록하며, MViTv2-L보다 0.8% 높은 성능을 보임
6.2. Transfer learning experiments
Classification on iNaturalists and Places
- iNaturalist 2017, 2018, 2019와 Places 365 데이터셋에서 ImageNet-1K로 pre-training된 Hiera를 fine-tuning
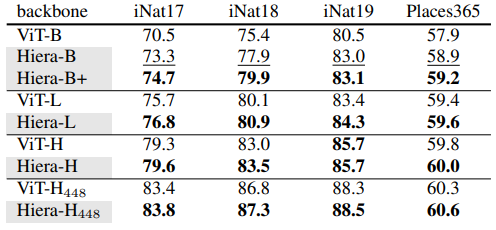
- Hiera가 ViT(MAE로 pre-training된)보다 꾸준히 우수한 성능을 보임을 나타내며, Hiera-L과 Hiera-H 아키텍처가 ImageNet 외의 다른 데이터셋에서도 효과적이라는 것을 보여줌
Object detection and segmentation on COCO
- COCO 데이터셋에서 다른 pre-training 된 backbone을 사용하여 Mask R-CNN을 fine-tuning
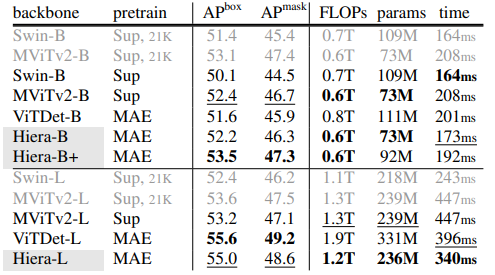
- Object detection(APbox)과 instance segmentation(APmask)의 성능을 비교
- Hiera는 ViTDet와 유사한 결과를 달성하면서도 더 빠른 추론 속도와 낮은 연산량
- 특히 Hiera-B는 ViTDet-B에 비해 더 적은 parameter와 더 낮은 추론 시간을 가지면서도 더 높은 APbox를 달성
- Hiera-L 또한 ViTDet-L보다 일관되게 더 빠른 속도를 보였지만, accuracy는 약간 낮음
7. Conclusion
- 본 논문에서는 기존의 복잡한 hierarchical vision transformer에서 불필요한 요소를 제거하고, MAE pre-training을 통해 spatial bias를 추가하여 간단한 Hiera 아키텍처를 제안
- Hiera는 현재 image recognition task에서 더 효과적이며, video task에서 SOTA를 능가하는 성능을 보임
- 이 model이 향후 연구에서 더 많은 task를 더 빠르게 수행할 수 있기를 기대

AI Research Engineer