
https://www.arxiv.org/abs/2408.12569
1. Introduction
최근 연구 성과
- 2D 및 3D에서 photorealistic human을 생성하는 방법이 크게 발전
- 이러한 성공은 2D keypoints, body-part segmentation, depth, surface normal와 같은 다양한 요소를 정확하게 estimation할 수 있는 기술에 크게 의존

- 그러나 이러한 요소를 정확하게 estimation하는 것은 여전히 활발히 연구되고 있으며, 각 task의 성능을 높이기 위한 복잡한 시스템은 널리 채택되는 것을 방해
문제점
- 정확한 'ground-truth' annotation을 현실 세계에서 large-scale로 얻는 것이 매우 어려움
Model의 세 가지 필요 성능 기준
- Generalization: 다양한 환경에서 일관된 성능을 보장하는 model의 robustness
- Broad applicability: 다양한 task에 최소한의 수정의 적합한 model의 성능
- High fidelity: 정확하고 high-resolution의 출력을 생성하는 model의 능력
Sapiens model
Pretraining
- 기존 연구에 따르면, large-scale dataset과 확장 가능한 model architecture를 활용하는 것이 일반화의 핵심
- 본 연구는 pretraining 후 fine-tuning 접근 방식을 사용하여 특정 task에 adaptation하는 방식을 채택
- 이는 "어떤 유형의 data가 pretraining에 가장 효과적인가?"라는 중요한 질문을 제기
- 컴퓨팅 자원의 한계 내에서 가능한 많은 human image를 수집하는 것이 좋을지, 아니면 현실 세계의 다양성을 더 잘 반영하는 less curated dataset을 사용하는 것이 더 나을지에 대한 논의
Humans-300M dataset
- 3억 개의 다양한 human image를 포함하는 dataset을 수집하여, 300M에서 2B까지의 파라미터를 가진 Vision Transformers를 pretraining
MAE (Masked-Autoencoder) 방식
- 간단하고 효율적인 pretraining을 위해 MAE 방식을 선택
- 이는 single-pass inference model로, large-scale image를 동일한 계산 자원으로 처리할 수 있음
Resolution and FLOPs
- Pretraining input resolution을 1024 pixel로 증가시켜 기존 model 대비 약 4배의 FLOPs 증가
- 각 model은 1.2조 개의 token으로 pretraining 됨
Fine-tuning
- Encoder-decoder architecture를 사용하여 2D pose estimation, body-part segmentation, depth 및 normal estimation task에 fine-tuning
- Encoder는 pretraining weight로 초기화되고, decoder는 경량화된 task 별 head로 random으로 초기화된 후, 둘 다 처음부터 끝까지 fine-tuning
Main contributions
- Sapiens 제안
- Large-scale human image dataset으로 pretraining된 vision transformer family를 제안
- Simple data curation & large-scale pretraining
- 동일한 계산 예산으로 model 성능을 크게 향상
- High-quality or synthetic label fine-tuned model
- 현실 세계에서의 일반화를 달성
- 1K resolution을 처음으로 지원하는 model
- 2D pose, body-part segmentation, depth 및 normal estimation task에서 SOTA 성능을 달성
2. Related Work
Large-scale pretraining (pretraining at Scale)
-
Large-scale pretraining 후 task별 fine-tuning으로 이어지는 방식은 language modeling에서 표준이 됨
-
이와 유사하게, computer vision에서도 점차 large-scale data를 활용한 pretraining을 채택 하고 있음
-
주요 dataset은 아래와 같음
- LAION5B, Instagram-3.5B, JFT-300M, LVD-142M, Visual Genome, YFCC100M
- 이러한 large-scale dataset은 전통적인 벤치마크의 범위를 넘어서는 data 탐색을 가능하게 함
-
주요 연구
- DINOv2, MAWS, AIM. DINOv2는 large-scale LDV-142M dataset에서 contrastive iBot 방법을 확장하여 SOTA 성능을 달성
- MAWS는 10억 장 이상의 image에서 MAE(Masked-Autoencoders) 확장을 연구
- AIM은 BERT와 유사한 auto-regressive visual pretraining 확장성을 탐구
-
본 연구의 차별성
- 기존 방법들이 일반 image pretraining 또는 zero-shot image classification에 초점을 맞춘 반면, 본 연구는 human-centric 접근을 채택하여 방대한 human image collection을 활용한 pretraining 후 human 관련 task을 위한 fine-tuning을 수행
-
Human Vision Tasks
- Large-scale 3D human digitization은 computer vision에서 중요한 목표로 남아 있음
- 현재까지 주로 제어된 스튜디오 환경에서 큰 성과를 거두었으나, 비제어된 환경에서 이러한 방법을 확장하는 데 여전히 어려움이 존재
- 중요한 human vision task
- Keypoint estimation, body-part segmentation, depth estimation, surface normal prediction
- 이러한 task을 자연스러운 환경에서도 일반화할 수 있는 다재다능한 model 개발이 필수적임
- 본 연구는 이러한 중요한 human vision task을 위해 자연스러운 환경에서 일반화할 수 있는 model을 개발하고자 함
-
Scaling Architectures
- 현재 가장 큰 공개된 language model은 100B 이상의 파라미터를 포함
- 그러나 ViT는 이 정도로 성공적으로 확장되지 못함
- 기존 한계 극복
- DiT와 같은 기존 transformer 기반 image 생성 model은 700M 미만의 파라미터를 사용하며, 압축된 잠재 공간에서 작동
- 본 연구에서는 Sapiens라는 large-scale high-resolution ViT model collection을 도입하여 수백만 장의 human image에서 1024 pixel resolution로 native pretraining을 진행
3. Method
3.1. Humans-300M Dataset
- Dataset 개요: 약 10억 장의 자연 상태에서 촬영된 human image를 사용하여 pretraining을 진행. 이 dataset은 human image에만 집중
- 전처리 과정: 워터마크, 텍스트, 예술적 표현, 비자연적 요소가 포함된 image를 삭제하고, Bounding-box detector로 사람을 감지한 후 점수 0.9 이상 및 size가 300 pixel을 초과하는 image만 남김
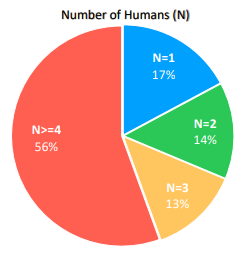
- Dataset 특성: 2억 4천 8백만 장 이상의 image에서 다중 인물이 포함
3.2. Pretraining
- MAE (Masked-Autoencoder) 방식을 채택: 부분적으로 관측된 image를 기반으로 원본 human image를 reconstruction 하는 model로 pretraining을 수행

- Model 구조: Image에서 일부 patch를 무작위로 masking하여 나머지 부분을 학습하고, masking 비율은 고정
- 특징: Model의 patch token 하나가 전체 image 면적의 0.02%를 차지하며, 이는 기존 ViT보다 16배 세밀한 계산이 가능
- 결과: 95% masking 비율에서도 human 해부학에 대한 그럴듯한 reconstruction이 가능
3.3. 2D Pose Estimation
- 기본 구조: Top-down 방식으로, input image에서 K개의 keypoint 위치를 탐지
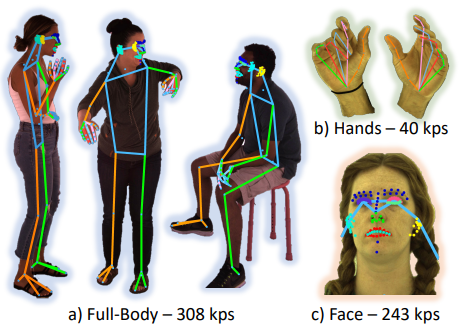
- Pose prediction 방식: K개의 heatmap prediction 문제로 정의하며, 각 heatmap은 해당 keypoint가 있을 가능성을 나타냄
- Model 구조: P라는 pose prediction transformer를 사용하며, input image를 prediction된 heatmap으로 변환. loss function는 MSE로 정의
- 세부 조정: 다양한 스켈레톤 형식에 대해 fine-tuning 진행 (예: K=17, K=133, K=308). 특히 308개의 Keypoint는 얼굴의 미세한 표현을 정확하게 포착하기 위한 것
- data: 4K resolution의 100만 장의 image에 대해 수동으로 annotation 처리
3.4. Body-Part Segmentation
- 목표: Human의 신체 부위를 분류하여 pixel 단위로 class를 지정

- Model 구조: 이전에 설명한 encoder-decoder architecture 및 초기화 방식을 채택
- Loss function: 실제 값과 prediction된 값 간의 weight CE loss로 정의
- Segmentation 범위: 기존의 20개 class 외에, 새로운 28개 class 추가. 예를 들어, 상/하반신 구분, 입술 상/하, 치아, 혀 등의 세부 구분을 추가
- Data: 10만 장의 4K resolution image를 수동으로 annotation 처리
3.5. Depth Estimation
-
목표: Depth estimation model 개발

-
Model 구조: Decoder 출력 채널이 1인 regression model로 변경
-
Loss function
-
Relative depth를 prediction 하기 위해 log 차이를 기반으로 loss function 정의
1) Equation (1)- Depth 차이 는 실제 depth 값 의 log에서 prediction된 depth 값 의 log를 뺀 값으로 계산
2) Equation (2)
- Mean depth 차이 는 모든 pixel 에 대한 개별 depth 차이 의 mean으로 계산
- Mean squared depth 차이 는 모든 pixel 에 대해 차이의 제곱 값 의 mean으로 계산
3) Equation (3)
- 최종 depth loss function 는 mean squared depth 차이에서 mean depth 차이의 절반 제곱을 뺀 값의 제곱근으로 계산
- 위 수식은 depth estimation task에서 prediction된 depth 값과 실제 depth 값 사이의 오차를 정량화하기 위해 사용
- Depth 차이 는 실제 depth 값 의 log에서 prediction된 depth 값 의 log를 뺀 값으로 계산
-
-
Data: 500,000개의 synthetic image를 사용하여 depth map 및 surface normal map 생성
3.6. Surface Normal Estimation
- 목표: Surface normal vector prediction
- Model 구조: Decoder 출력 채널을 xyz normal vector에 맞춰 3개로 설정
- Loss function: Human pixel에 대해만 계산하며, 아래 수식으로 정의
4. Experiments
4.1. Implementation Details
- 가장 큰 model인 Sapiens-2B는 1024개의 A100 GPU를 사용해 PyTorch로 18일 동안 학습
- 모든 실험에서 AdamW optimizer 사용
- Learning schedule은 짧은 linear warm-up 후, pretraining을 위해 cosine annealing, fine-tuning을 위해 linear decay 적용
- 모든 model은 1024×1024 resolution에서 patch size 16으로 처음부터 pretraining
- Fine-tuning을 위해 input image는 4:3 비율로 조정되며, resolution는 1024×768
- Cropping, scaling, flipping, photometric distortions 같은 표준 augmentation 기법 사용
- Segmentation, depth, surface normal prediction task에서 COCO dataset의 non-human images를 배경으로 추가
- Differential learning rate를 사용해 일반화 유지
- 초기 layer에 낮은 learning rate, 이후 layer에 점차 높은 learning rate 적용
- Layer 별 learning rate 감소율은 0.85, encoder의 weight weight decay은 0.1
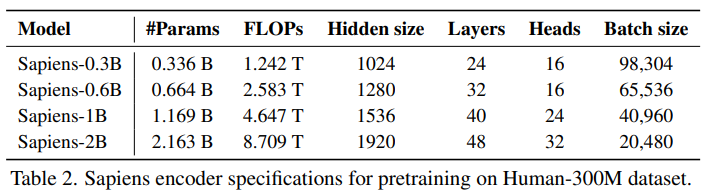
- Model 디자인은 table 2에서 설명하며, depth 보다는 width 확장에 중점을 둠
- Sapiens-0.3B model은 전통적인 ViT-Large와 유사한 architecture를 가지고 있지만, 더 높은 resolution 때문에 20배 더 많은 FLOPs를 사용
4.2. 2D Pose Estimation
- Sapiens model을 얼굴, 신체, 발, 손의 pose estimation(K = 308)에 대해 fine-tuning
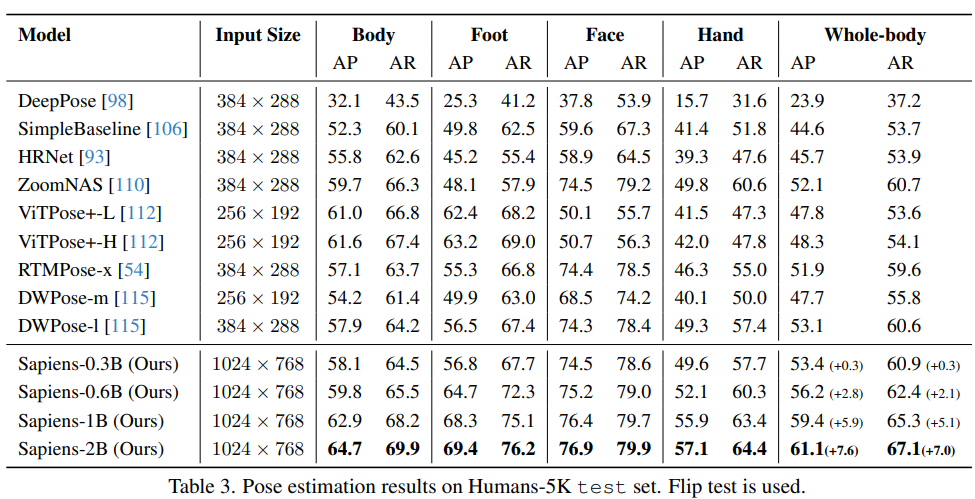
- 1백만 개의 image로 학습하고, Humans5K라는 이름의 5천 개 image로 구성된 testset으로 평가
- 평가 방법은 Top-down 접근법 사용
- Bounding box 검출을 위해 off-the-shelf detector 사용, single human pose inference 수행
- 기존 방법들과의 비교 결과, Sapiens-0.6B model이 현재 SOTA model인 DWPose-l을 +2.8 AP 차이로 능가
- Sapiens는 단순한 encoder-decoder 구조를 사용하여 large-scale human-centric의 pretraining 만으로도 높은 성능을 보임
- Sapiens-2B model은 61.1 AP로 SOTA를 기록, 이전 model 대비 +7.6 AP 성능 향상
4.3. Body-Part Segmentation
- Sapiens model은 28개 class의 body-part segmentation에 대해 fine-tuning 및 평가
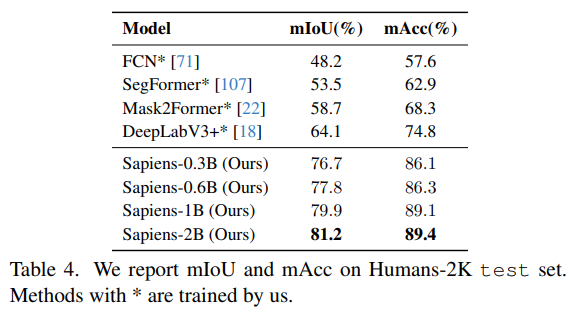
- 100K image로 학습, Humans-2K라는 2천 개 image로 평가
- Sapiens-0.3B는 기존의 SOTA segmentation 방법들을 12.6 mIoU 차이로 능가
- Model size가 커질수록 segmentation 성능도 향상
- Sapiens-2B는 81.2 mIoU 및 89.4 mAcc로 최고 성능 기록
4.4. Depth Estimation
- THuman2.0과 Hi4D dataset에서 depth estimation model 평가
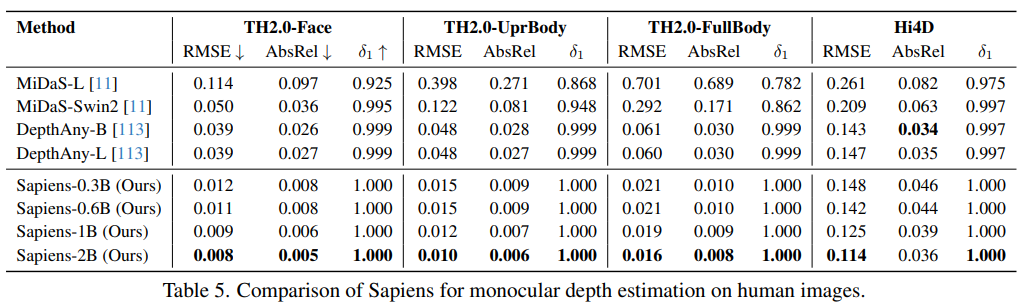
- THuman2.0은 526개의 high-quality human scan data로 구성
- 얼굴, 상반신, 전신 image로 나누어 평가
- Hi4D는 multi-person scenario에 초점을 맞춤
- 총 1195개의 실세계 multi-person image로 평가
- Sapiens-2B는 single human image와 multi-person scenario에서 기존 model들을 능가하며, RMSE 지표에서 20% 감소를 보임

- 기존 model들이 다양한 장면에서 학습된 반면, Sapiens는 human-centric의 depth estimation에 특화됨
4.5. Surface Normal Estimation
- Surface 평가에 사용된 dataset은 depth estimation에서 사용된 것과 동일
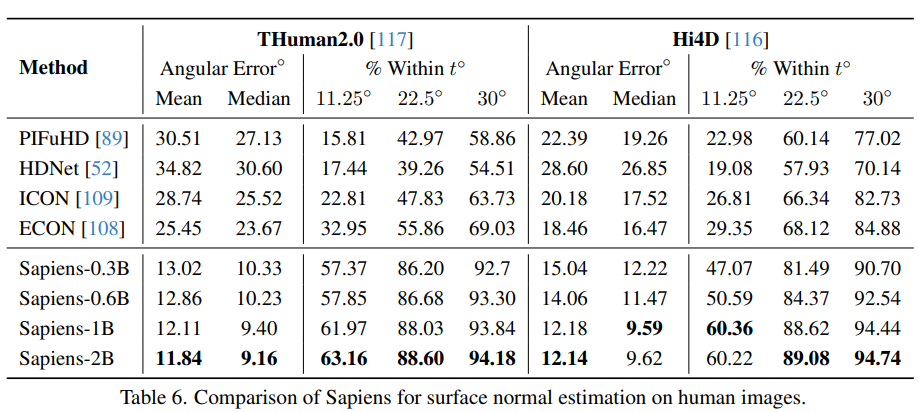
- Sapiens model은 기존의 human-centric surface estimation 방법을 상당히 능가

- Sapiens-2B model은 mean eroor 12도를 기록
4.6. Discussion
Importance of Pretraining Data Source
- Feature quality는 pretraining data quality와 밀접하게 연관
- 다양한 data source에서 pretraining의 중요성을 평가하기 위해 Sapiens-0.3B model을 각각의 dataset으로 동일한 learning schedule과 iteration으로 pretraining 진행
- 이후 각 task에 대해 model을 Fine-tuning하여 조기 checkpoint를 선택하고 평가
- 이는 model의 초기 Fine-tuning이 Generalization 능력을 더 잘 반영한다고 판단
- 일반 image(사람을 포함할 수 있음)와 human 전용 image를 사용한 pretraining의 차이를 평가
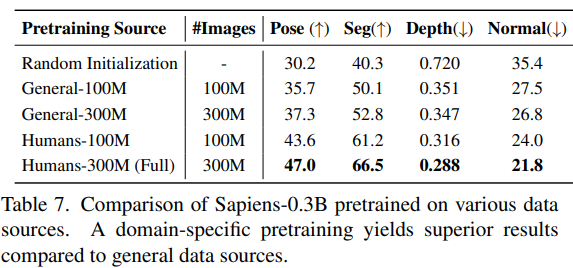
- 1억 개와 3억 개의 일반 image를 무작위로 선택해 General-100M과 General-300M dataset을 생성
- 결과적으로, Human300M dataset을 사용한 pretraining이 모든 task에서 성능을 향상시킴
- Pretraining 동안 관찰한 고유한 human image의 수가 model의 성능에 미치는 영향을 연구
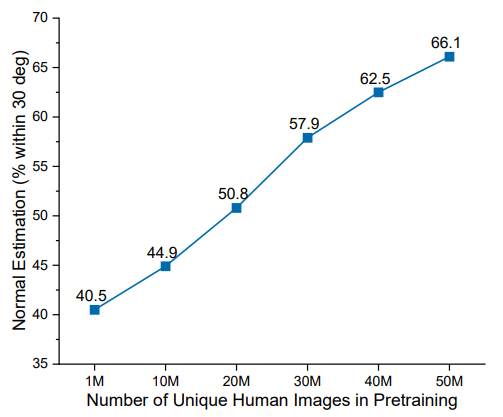
- 위 그림에서 처럼, data size가 증가할수록 성능이 꾸준히 향상됨을 확인 (Saturation 상태 없이)
Zero-Shot Generalization
- Sapiens model은 다양한 설정에 대해 폭넓은 Generalization을 보임
- 예를 들어, Segmentation task에서 Sapiens는 single human image만으로 fine-tuning 진행

- 제한된 피사체 다양성, 최소한의 배경 변화, 3인칭 뷰만 사용
- 그럼에도 불구하고 large-scale pretraining 덕분에 다양한 피사체 수, 연령대, 시점에 걸쳐 Generalization을 달성
- 예를 들어, Segmentation task에서 Sapiens는 single human image만으로 fine-tuning 진행
Limitations
- Model 성능은 일반적으로 뛰어나지만, 복잡하거나 드문 포즈, 과밀, 심한 가림 현상이 있는 image에 어려움
- Data augmentation과 detect-and-crop 전략을 통해 이러한 문제를 완화할 수 있음
- 제안한 model은 사람이 실시간으로 피드백을 제공하는 방식으로 large-scale 실세계 학습을 위한 도구로 활용할 가능성이 있음
5. Conclusion
- Sapiens는 human-centric vision model을 foundation model로 발전시키기 위한 중요한 진전을 나타냄
- 다양한 human-centric task에서 뛰어난 Generalization 능력을 보임
- 제안한 model이 SOTA 성능을 달성한 요인은 다음과 같음:
- Human understanding에 특화된 large-scale pretraining
- High-resolution, high-capacity Vision Transformer Backbone
- High-quality annotation data 사용 (augmented studio 및 synthetic data)
- 이 model들은 다양한 downstream task에서 핵심적인 역할을 할 수 있으며, 더 넓은 커뮤니티에 high-quality vision backbone을 제공할 수 있을 것임
- 향후 task으로는 Sapiens를 3D 및 multi-modal dataset으로 확장하는 방향이 제안됨

AI Research Engineer