https://arxiv.org/abs/2408.16357
1. INTRODUCTION
Current multimodal large language models (MLLMs)
- 최근 MLLMs는 pre-training 된 vision encoder와 강력한 language model을 통합하여 큰 발전을 이룸
- 예를 들어, CLIP이 주요 image feature encoder로 많이 사용되지만, 한계가 있음
- 따라서 alternative vision representation 방식과 여러 vision encoder를 결합하는 방법이 연구되고 있음
Vision representation selection problem
- Vision representation의 선택이 경험적으로 이루어져 왔으며, 최적의 vision representation이 특정 MLLM에 대해 경험적 성능에 의해 결정
- 하지만 특정 feature representation이 성능에 미치는 근본적인 이유는 잘 이해되지 않음
- 따라서 어떤 feature representation이 최고의 성능을 내는지에 대한 질문이 여전히 답을 얻지 못함
Law of Vision Representation in MLLMs
- 본 논문에서는 MLLM에서 vision representation이 최적화되는 이유를 설명하는 법칙을 제안
- 이 법칙은 vision representation의 핵심 요소가 MLLM 성능에 미치는 영향을 설명
- 특히, vision representation의 Cross-modal Alignment and Correspondence (AC)가 model 성능과 강하게 상관관계가 있다는 점을 발견
- AC가 증가할수록 model 성능이 향상
AC score definition and performance relationship
- AC score는 vision representation에서의 cross-modal alignment와 correspondence를 측정하는 score로 정의
- 이 AC score와 model 성능 사이에 95.72%의 결정 계수를 가진 선형 관계가 존재
AC policy proposal
- 최적의 vision representation을 선택하는 AC policy를 처음으로 제안
- 기존의 성능을 기반으로 하는 방법과 달리, AC score를 사용하여 더 많은 vision representation을 고려할 수 있음에도 추가적인 비용이 발생하지 않음
- 이 접근법은 임의로 vision representation을 선택하는 것보다 정확성과 효율성을 향상시킴
AC policy performance
- 이 정책은 13개 설정의 search space에서 language model을 세 번만 fine-tuning하여 상위 3개의 최적 구성을 96.6%의 확률로 식별
2. RELATED WORKS
2.1. VISION FOR MLLMS
Study of various vision representations
- 최근 연구들은 MLLM에서 다양한 vision representation 방식을 탐구
- CLIP 계열 외부 encoder들(예: DINOv2, Stable Diffusion)을 단독으로 사용하는 경우 성능이 낮아지는 경향이 있음
- 하지만 이 encoder들의 feature를 CLIP feature와 결합하면 성능이 크게 향상
- 예를 들어 image embedding을 token 또는 channel dimension에서 결합하는 방식이 효과적
- 하지만 성능 변화의 근본적인 원인에 대한 심층 분석은 아직 부족
- 이는 최적의 vision representation의 속성이 완전히 이해되지 않았음을 시사
2.2. CROSS-MODAL ALIGNMENT
Cross-modal alignment concept
- Cross-modal alignment는 image와 text feature space 간의 alignment(정렬)을 의미
- 이 개념은 text-image contrastive learning의 도입과 함께 등장
- 현재의 MLLMs는 contrastive learning을 통해 pre-training 된 image encoder를 사용하지만, 효과적인 alignment를 달성하는 문제는 여전히 남아있음
- CLIP 계열의 한계에 대한 비판과 alternative vision representation을 탐구하려는 시도에도 불구하고, 많은 접근법이 여전히 contrastive learning encoder에 의존하거나 contrastive loss를 추가하는 방식에 의존
- 본 연구에서는 vision representation에서의 alignment이 model 성능 향상과 데이터 효율성에 필수적임을 강조
- Alignment 되지 않은 vision representation을 사용하면 cross-modal alignment를 달성하기 위해 large-scale data pre-training이 필요
2.3 VISUAL CORRESPONDENCE
Visual correspondence concept
- Visual correspondence는 컴퓨터 vision에서 중요한 구성 요소로, 정확한 correspondence가 image detection, visual generation, MLLM 등의 task에서 성능 향상을 이끌 수 있음
- Correspondence는 주로 의미적(Semantic)과 기하학적(Geometric) correspondence로 분류
- Semantic correspondence는 동일한 instance를 나타내지 않더라도 동일한 의미적 개념을 나타내는 point를 일치시키는 반면, geometric correspondence는 동일한 image를 정확하게 일치시키는 것을 요구
Limitations of the CLIP series
- 몇몇 연구들은 CLIP 계열의 vision representation이 "시각적 디테일이 부족하다"는 점을 지적
- 이는 image 내 patch 간의 유사성을 높여 더 세부적인 정보를 검색할 수 있도록 하는 correspondence 개념을 통해 설명할 수 있음
3. LAW OF VISION REPRESENTATION IN MLLMS
Introduce of law
- Multimodal Large Language Models (MLLMs)에서의 Law of Vision Representation은 MLLM 성능(Z)을 vision representation의 cross-modal alignment (A)와 correspondence (C) 두 가지 요인으로 추정할 수 있음을 제안
- 다른 구성 요소(예: language model, alignment module)는 고정된 상태에서 vision representation만 독립 변수로 가정하며, 이 관계는 다음과 같이 표현:여기서 는 와 의 2차 polynomial transformations에 대한 linear function
3.1. THEORETICAL JUSTIFICATION
Theoretical analysis
- A와 C가 증가하면 model 성능이 향상되는 이유를 이론적으로 분석
- Vision representation이 높은 cross-modal alignment와 정확한 correspondence를 보일 때, MLLM은 다음과 같은 바람직한 특성을 나타냄
- Cross-modal alignment와 성능 향상
- Vision representation이 언어 분포와 잘 well-aligned 된 경우, pre-training 된 language model이 modality 간의 차이를 조정하는 데 필요한 계산 노력이 줄어듦
- 이는 fine-tuning에서 언어 데이터만 사용하는 것과 거의 동일한 효율성을 제공
- 따라서 제한된 학습 데이터로도 성능이 향상될 수 있음
- 정확한 correspondence와 세부 정보 포착
- Vision representation이 정확한 correspondence를 보장하면 image embedding 내에서의 attention이 정밀해짐
- 결과적으로 MLLM이 text-image attention만으로는 얻을 수 없는 세부적인 시각적 정보를 포착할 수 있게 됨
- Cross-modal alignment와 성능 향상
3.2. EMPIRICAL JUSTIFICATION
Empirical analysis
- AC가 model 성능과 강한 상관관계를 가짐을 경험적으로 증명
- 이를 위해 cross-modal alignment와 correspondence를 측정하는 방법을 제안
- Cross-modal alignment 측정
- 동일한 개념의 image와 text embedding을 비교함으로써 alignment를 측정하려고 하지만, alignment를 확보하기 어렵기 때문에 CLIP vision embedding을 기준으로 사용
- CLIP embedding()과 목표 vision representation embedding() 간의 cosine similarity 를 계산하여 alignment score를 정의
- 여기서 은 image 샘플의 총 개수, 는 번째 image의 vision feature 에서 나온 번째 embedding vector
- Correspondence score 측정
- 짝을 이룬 image들에서 feature를 추출하여 대응점을 예측하고, 올바른 keypoint의 비율을 계산(PCK)하여 correspondence score를 정의
- 여기서 는 image 내 object instance의 bounding box 크기에 비례하는 threshold
- 짝을 이룬 image들에서 feature를 추출하여 대응점을 예측하고, 올바른 keypoint의 비율을 계산(PCK)하여 correspondence score를 정의
- AC score 계산
- A와 C score의 2차 polynomial transformations으로 AC score를 정의
- A와 C score의 2차 polynomial transformations으로 AC score를 정의
- Cross-modal alignment 측정
Results
- 13개의 vision representation을 사용하여 4개의 vision 기반 MLLM 벤치마크에 대해 간단한 linear regression model을 fitting한 결과, AC score를 사용했을 때 평균 결정 계수()가 95.72%로 나타남
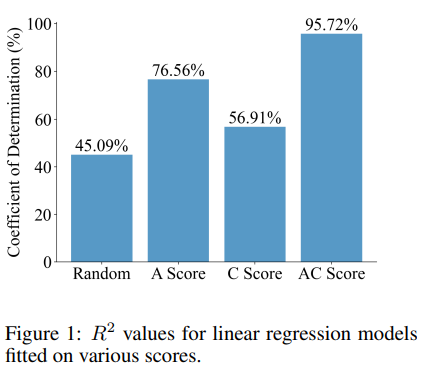
- 이를 비교하기 위해 13개의 임의 score, A score만 사용한 model, C score만 사용한 model도 fitting했으나 성능과의 상관관계가 훨씬 낮았음
- 이 결과는 AC score와 MLLM 성능 사이의 강한 상관관계를 강조하며, vision representation 법칙의 유효성을 입증
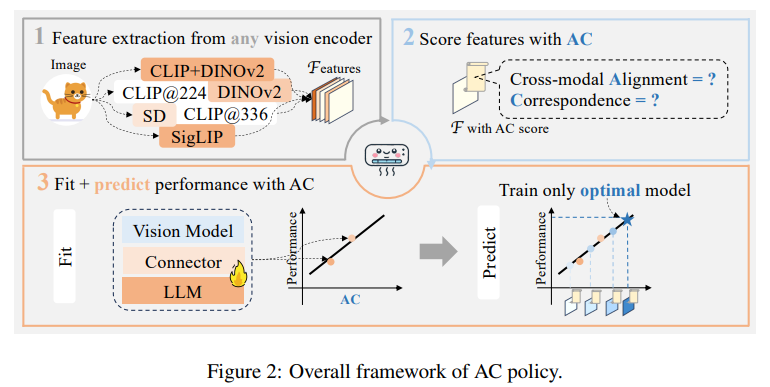
4. AC POLICY
Problem Formulation
- MLLM architecture
- Frozen vision encoder, alignment module, 그리고 language model로 구성
- k개의 vision representation 중 최적의 representation을 결정하려면 LLM을 k번 fine-tuning해야 하는데, 이는 규모 확장이 어려움
- N개의 vision encoder가 주어지면, AC policy를 제안해 효율적으로 최적의 vision representation을 추정하는 방법 제시
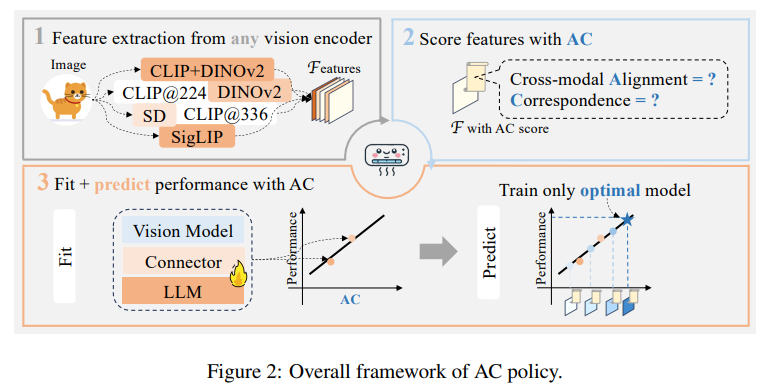
- 이 방법은 k개의 representation 중에서 최적의 representation을 찾아내기 위해 인 LLM만 fine-tuning 하여 성능을 평가 가능하게 함
Policy Fitting
- : Vision representation의 AC score matrix
- : 개의 데이터 point를 subsampling하여 linear regression model 입력으로 사용
- Linear regression 식:
- : Model parameter vector
- : Error term vector
- : 벤치마크 성능을 나타냄
Sampling Strategy
- sampling이 model 예측 정확성에 중요한 영향을 미침
- A와 C score가 너무 가까운 샘플을 피하기 위해 좌표를 기반으로 sampling 전략 사용
- k개의 vision representation의 정규화된 A와 C score 쌍을 2D 그래프 상에 좌표로 나타내고, 그래프를 여러 영역으로 나눠 다양한 sampling 보장
- 총 sampling point가 에 도달할 때까지, 그래프를 영역으로 나누고 빈 영역 및 이미 sampling된 영역은 제거한 후, 남은 영역에서 random으로 선택
Results
- 아래 Table에서 AC policy가 제한된 자원으로 최적의 vision representation을 일관되게 예측함을 보여줌
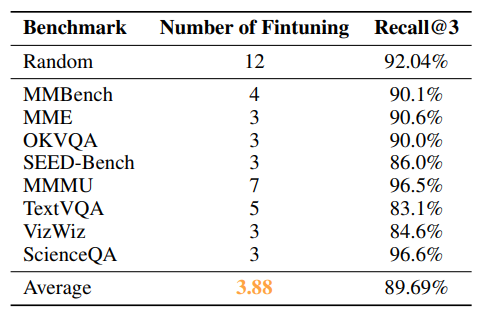
- random 하게 선택한 subset을 학습하면 13개 중 12개를 fine-tuning해야 90% 이상의 Recall@3 달성
- AC policy는 평균적으로 3.88회 전체 학습을 통해 89.69% Recall@3 도달
5. EMPIRICAL RESULT DETAILS
5.1. EXPERIMENT SETTINGS
- MLLM 파이프라인
- LLaVA의 training 절차 및 architecture, dataset을 따름
- 첫 번째 단계
- 558K 샘플이 포함된 LLaVA 1.5 dataset으로 2-layer GeLU-MLP 커넥터 학습
- 두 번째 단계
- 확장된 LLaVA 1.5 dataset(665K 샘플)으로 커넥터와 language model을 함께 학습
- 각 학습 과정에서 vision representation만 변경되며 다른 요소들은 동일하게 유지
- 13개의 vision representation은 아래 Table에 나열
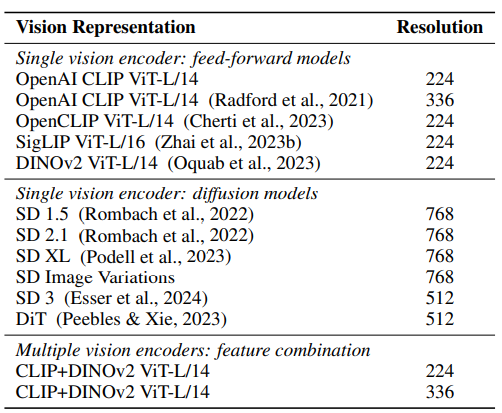
- 사용된 MLLM 벤치마크
- MMBench, MME, OKVQA, SEED-Bench 등 4개의 vision 기반 벤치마크와 MMMU, TextVQA, VizWiz, ScienceQA 등 4개의 QCR 기반 벤치마크 포함
5.2. AC SCORE
- Cross-modal alignment score를 계산하기 위해, 모든 vision representation에 대해 1단계 학습 진행하여 MLP를 얻음
- 이 과정은 2단계보다 훨씬 적은 계산 자원(약 0.298%) 소모
- Alignment score는 각 벤치마크별로 random 하게 sampling된 100개의 image 평균값으로 계산
- Correspondence score는 SPair-71k dataset을 사용해 일관된 값으로 설정
5.3. FEATURE EXTRACTION
- Image feature extraction
- MLLM 학습과 score 계산 모두 image feature extraction을 포함
- Feed-forward model vision representation
- 주어진 image 에 대해 U-Net model은 원본 형태로 처리하고, transformer model은 patch화된 형태로 처리
- Transformer: 마지막 hidden state 에서 추출, 여기서 은 sequence length, 는 hidden dimension
- U-Net model: 첫 번째 upsampling block 이후 중간 activation 에서 추출
- 이 두 model의 feature는 sequence 형식과 grid 형식 간에 reshaping 및 flattening을 통해 상호 변환 가능
- Feed-forward model vision representation
- Diffusion model vision representation
- Diffusion model은 다중 단계의 denoising을 통해 image를 생성하는 데 주로 사용되지만, 최근에는 vision representation model로도 활용
- 주어진 image 에 대해, 먼저 VAE로 인코딩된 representation에 noise를 추가
- Noise 수식:
- 여기서 , 는 noise 스케줄에 따라 결정
- Noise가 적은 전략을 사용해 로 설정하고, 이때 Diffusion model은 noise-latents의 denoising을 한 번만 수행
- 이 한 번의 denoising latents를 vision representation feature으로 간주
- Diffusion model은 다중 단계의 denoising을 통해 image를 생성하는 데 주로 사용되지만, 최근에는 vision representation model로도 활용
- MLLM 학습과 score 계산 모두 image feature extraction을 포함
5.4. ADDITIONAL RESULTS ON THE LAW OF VISION REPRESENTATION
-
Section 3 summary
- AC score와 MLLM 성능 사이의 강한 상관관계를 linear regression model의 결정 계수() 분석을 통해 증명
-
Additional experimental
- Random score, A score, C score를 각각 사용하여 model 성능을 fitting 하는 추가 실험 수행

- A와 C score 사이의 관계를 분석하기 위해 두 가지 데이터 변환(변환 없음, 2차 polynomial transformations) 적용
- 2차 polynomial transformations가 model 성능과의 상관관계에서 가장 높은 값을 나타냄
-
Conclusions
- AC score를 사용한 방법이 다른 설정들보다 항상 더 우수한 성능을 보임
- A와 C score 간의 내재된 trade-off 존재: cross-modal alignment이 높은 vision representation은 낮은 correspondence를 보이며 그 반대도 마찬가지
- OCR 기반 벤치마크 성능과 C score 간의 상관관계가 낮아, AC score와 OCR 기반 벤치마크 성능 간의 상관관계도 낮아짐
5.5. ADDITIONAL RESULTS ON THE AC POLICY
-
Section 4 summary
- AC score fitting이 최소 자원으로 최적의 vision representation을 일관되게 예측 가능함을 보여줌

-
Additional experimental simulation results
- Random 하게 subset을 선택해 학습할 경우, 최적의 vision representation을 포함하기 위해 13개의 설정 중 최소 11개를 학습해야 함
- 이는 작은 subset만 학습할 경우 신뢰할 수 없다는 것을 의미
-
Advantages of AC policy
- 평균적으로 3.88회 전체 학습을 통해 89.69%의 Recall@3 달성
- ScienceQA 벤치마크에서 최적의 구성 선택 가능성이 96.6%로 높음
- 이를 통해 AC 정책이 MLLM vision representation 탐색의 노력과 비용을 크게 줄여줌
6. DISCUSSION AND LIMITATIONS
6.1. FINDING VISION REPRESENTATIONS WITH HIGH AC
- AC score가 MLLM 성능과 높은 상관관계를 가지므로, 높은 AC score를 가진 vision representation을 식별해 search space에 추가하는 것이 중요
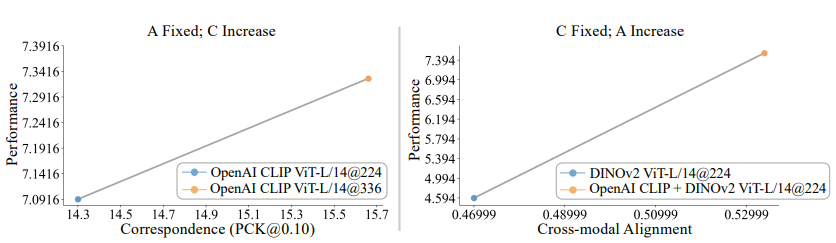
- Strategy
- Increase resolution
- Resolution를 224에서 336으로 증가시키면 성능이 향상
- Feature fusion
- 두 개의 feature를 channel dimension에서 결합해 alignment과 correspondence를 동시에 개선
- Increase resolution
6.2. REFINING A SCORE DESIGN
- A score는 CLIP embedding과 목표 embedding 사이의 코사인 유사도를 최대화하는 방식으로 계산
- Resolution가 다를 경우 correspondence 효과가 포함될 수 있음
- 해결책
- 다양한 resolution에서 A score 평균을 계산하여 영향 완화
6.3. REFINING C SCORE DESIGN
-
OCR-based benchmark performance
- Vision 기반 벤치마크에 비해 AC score와 약한 상관관계를 보임
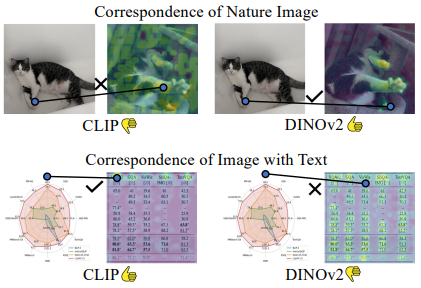
-
원인
- C score를 계산할 때 사용된 correspondence dataset에서 발생
- SPair71k dataset은 고양이, 기차 같은 natural image의 feature correspondence를 측정
-
문제점
- SPair71k dataset은 text가 포함된 image의 correspondence를 정확하게 반영하지 못함
- CLIP encoder는 자연 image에서는 DINOv2보다 낮은 correspondence를 보이지만, text가 포함된 image에서는 DINOv2보다 훨씬 높은 correspondence를 나타냄
-
해결책
- 각 벤치마크마다 고유의 keypoint가 labeled image를 사용해 correspondence를 평가하는 것이 이상적
- 최소한 OCR 전용 correspondence dataset이 있으면 MLLM 평가에 매우 유용할 것
- 현재 이런 dataset은 존재하지 않으며, 이에 대한 추가 연구가 필요
- 특히 표와 차트 이해와 같은 기본적인 기능을 다루는 MLLM 분야에서 가치가 클 것

AI Research Engineer
좋아요! 그런데 재밌는 게임을 하나 소개해 드릴게요. 스트레스 받을 때 space waves 게임이에요.