[논문 정리] Knowledge Transfer from Vision Foundation Models for Efficient Training of Small Task-specific Models
https://arxiv.org/abs/2311.18237
1. Introduction
- 최근 Computer Vision 분야에서는 large scale 데이터셋으로 pre-training 한 다양한 Vision, Multi-modal Foundation Models (VFMs)의 출현을 목격하고 있음
- 이러한 모델들은 task-specific labeled data가 제한적인 많은 downstream task에서 우수한 성능을 보였지만, 높은 inference 비용 때문에 resource-constrained applications에는 사용할 수 없음
- 자율 주행, 의료 영상 진단, 산업 자동화와 같은 여러 애플리케이션은 특정 task 또는 domain에 초점을 맞추고 있어 큰 VFM보다는 작은 task-specific models이 필요
- 자연스럽게 아래와 같은 의문이 제기
- 제한된 labeled training data로 새로운 target task에 대해 작은 task-specific 모델을 효과적으로 학습하기 위해 큰 VFM의 knowledge를 어떻게 활용할 수 있을까?
2. Approach and Contributions
- 본 논문에서는 large scale pre-trained VFM에서 작은 task-specific 모델로 knowledge를 transfer하는 간단하고 매우 효과적인 방법을 제안
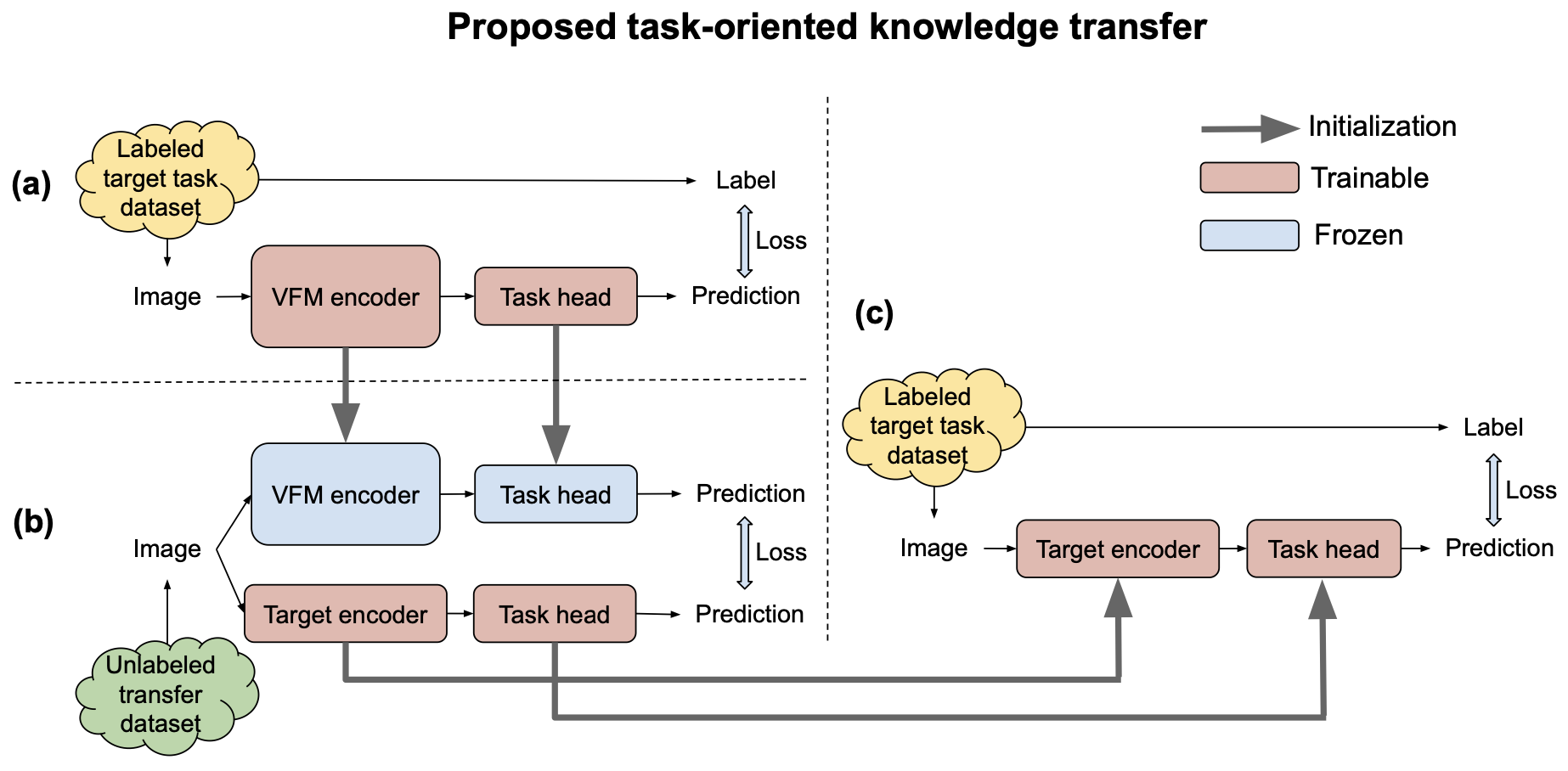
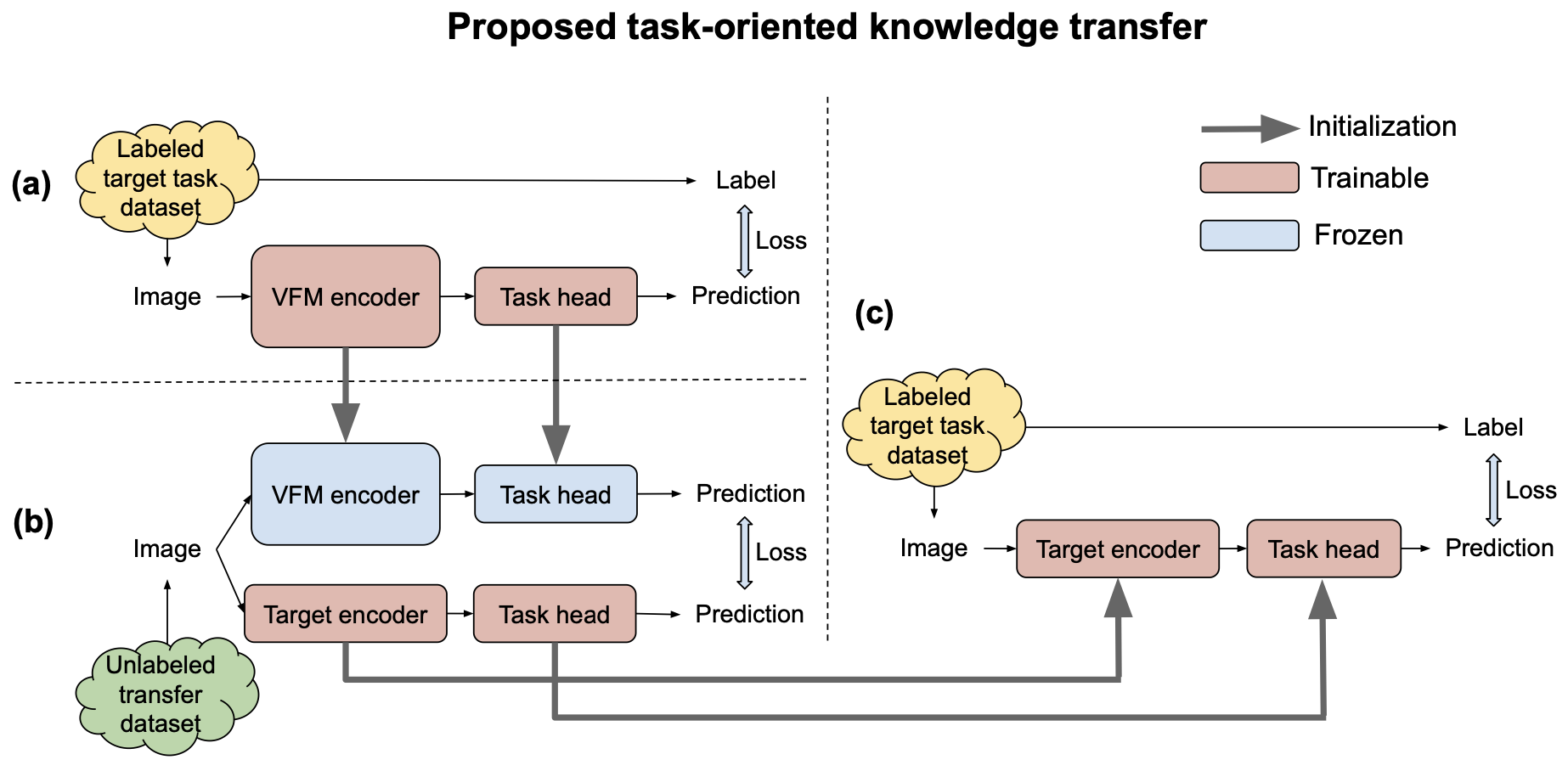
- 이 방법은 task-oriented knowledge transfer라고 하며 아래와 같은 과정을 거침
- 먼저 적절한 task-specific head와 제한된 labeled target task data를 사용하여 VFM에 target task를 학습
- Large unlabeled dataset (transfer set)을 이용한 knowledge distillation framework를 통해 adaptation 된 VFM에서 target 모델로 task-oriented knowledge를 transfer
- 마지막으로 제한된 labeled target task data로 target 모델을 fine-tuning
- Alternative approach
- VFM의 image encoder를 target 모델의 image encoder로 먼저 distillation 한 다음, 제한된 labeled target task data로 target 모델을 fine-tuning 하는 것
- 이를 task-agnostic knowledge transfer라고 함
- 두 접근법 모두 web-scale datasets로 pre-train 된 VFMs를 활용하며, 작은 target 모델을 직접 web-scale dataset으로 pre-training하는 것보다 비용이 절감됨
- 예를 들어, MobileViT-V2 모델을 CLIP 접근법으로 학습하는 데만 1.2K A100 GPU 시간이 필요함
Task-oriented Knowledge Transfer의 주요 발견
- Task-oriented knowledge transfer
- 성능(Table 1)과 학습 비용(Figure 4) 면에서 task-agnostic transfer보다 큰 차이로 우수
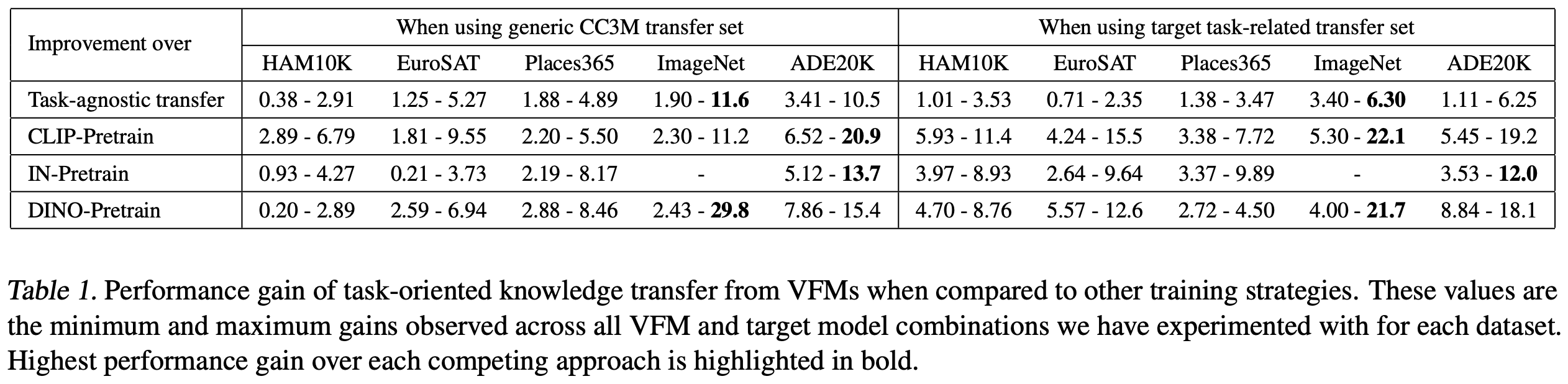
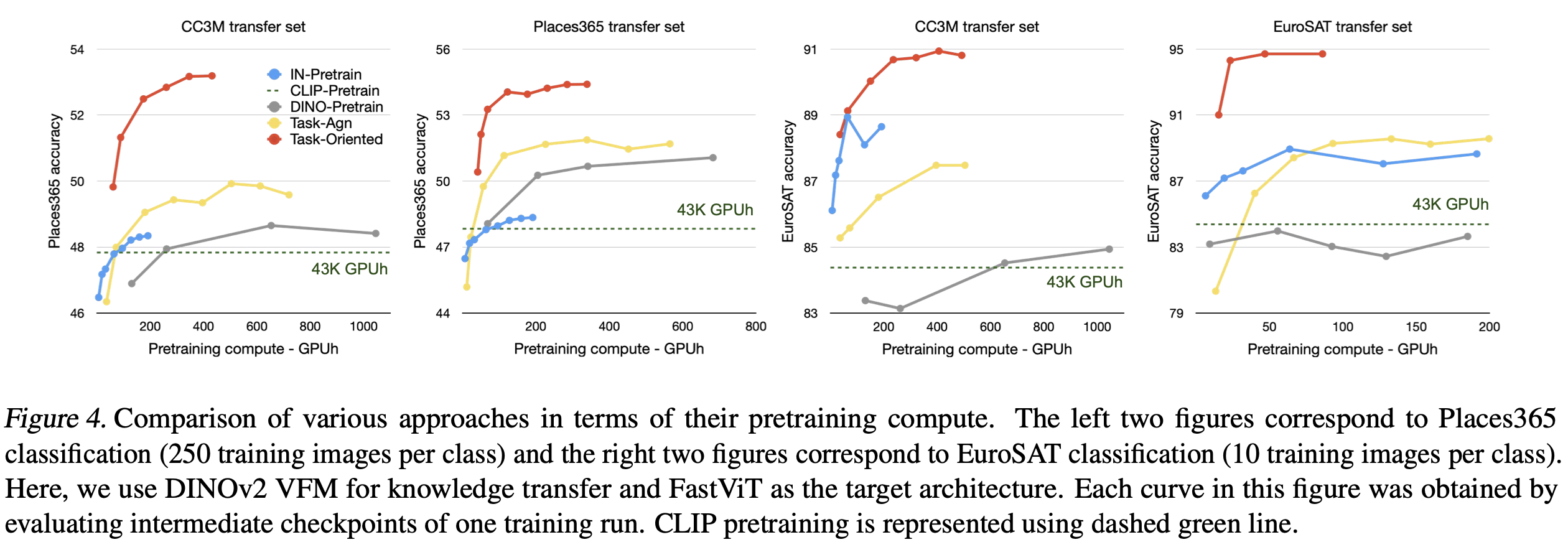
- VFMs는 큰 용량으로 방대한 knowledge를 저장할 수 있지만, 작은 모델은 이를 모두 상속받지 못하므로 task-oriented knowledge만 transfer하는 것이 더 나은 성과를 냄
- Task-oriented knowledge transfer는 계산 집약적인 CLIP, 널리 사용되는 supervised ImageNet, self-supervised DINO pre-training 접근법을 큰 차이로 능가하며, 계산 효율성도 높음 (Figure 1, Figure 4)
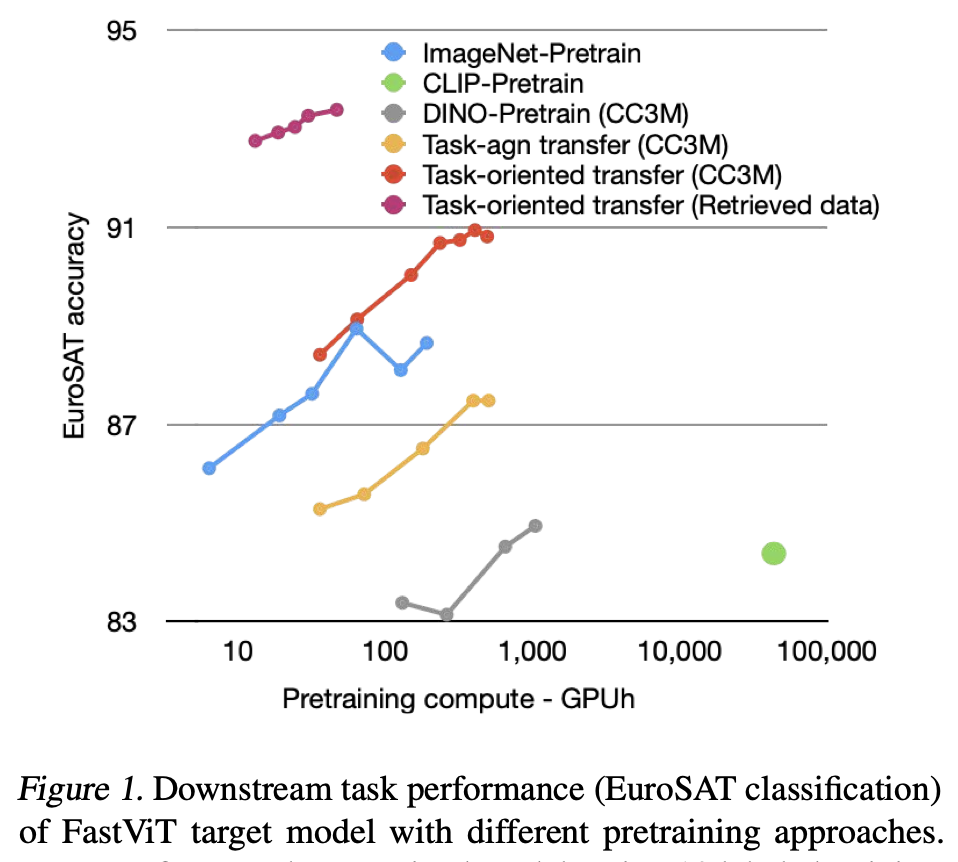
- 기존의 distillation 연구들이 target task datasets를 transfer sets로 사용하는 것과 달리, 본 논문에서는 transfer set의 효과를 체계적으로 연구하였으며, task-oriented knowledge transfer가 ImageNet과 CLIP pre-training보다 task-related transfer sets 없이도 더 나은 성능을 보임 (Table 1)
- Task-related transfer set이 쉽게 구할 수 없는 경우, 제한된 target task dataset을 query set으로 사용하여 web-scale image retrieval을 통해 dataset을 생성하는 방법을 제안
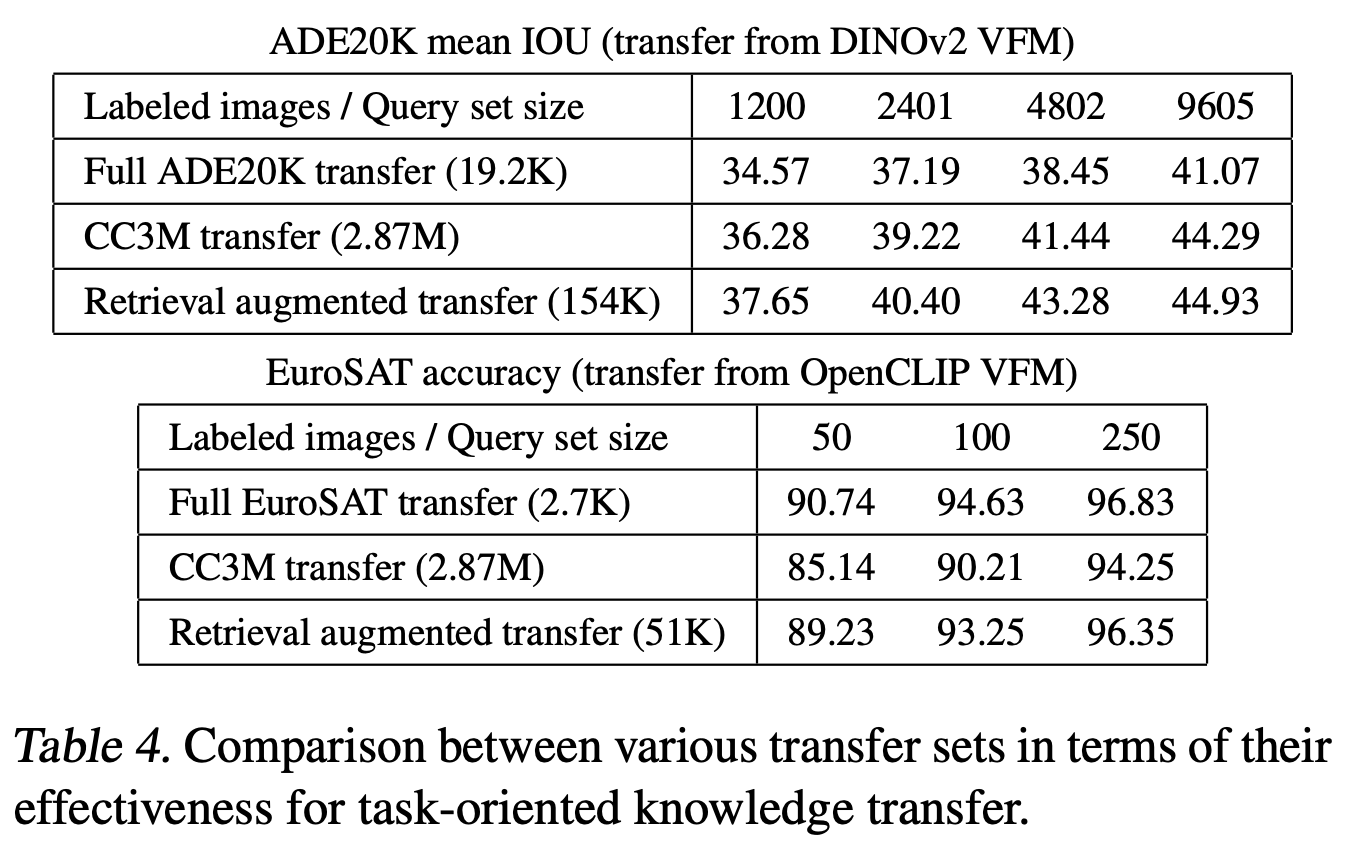
- 이 경우, retrieval-augmented transfer sets가 일반적인 CC3M transfer set보다 성능이 크게 향상됨 (Table 4)
3. Experimental Analysis
3.1. Experimental Setup
Training Stages
- Target 모델 학습은 두 단계로 수행
- Pretraining 후 Finetuning 단계로 나뉘며, Pretraining에서는 큰 unlabeled dataset을 transfer set으로 사용하여 task-oriented 및 task-agnostic knowledge transfer 접근법을 사용
- Finetuning에서는 작은 labeled target task dataset을 사용해 모델을 학습
Alternative approach
- IN-Pretrain
- ImageNet-1K dataset에서 1.28M labeled images를 사용한 supervised pretraining
- CLIP-Pretrain
- 0.7B image-text pairs에서 affinity mimicking CLIP distillation 접근법으로 contrastive language image pretraining
- DINO-Pretrain
- Unlabeled transfer set을 사용한 self-supervised pretraining
- Target Tasks
- HAM10K skin lesion classification, EuroSAT classification, Places365 scene classification, ImageNet object classification, ADE20K semantic segmentation
- Transfer Sets
- CC3M dataset의 training split에서 2.87M unlabeled images로 구성된 일반적인 transfer set과 각 target task domain에서 수집한 task-related transfer set 사용
- Vision Foundation Models (VFMs)
- DINOv2-ViT-L/14 및 OpenCLIP-ViT-L/14 모델 사용
- Target Models
- FastViT-S12 및 MobileViT-V2-1.0
- Task-specific Heads
- Classification task에는 linear classifier 사용, segmentation task에는 DeepLabV3 segmentation head 사용
3.2. Effectiveness of Task-oriented Knowledge Transfer
3.2.1. Performance Improvement
- 다양한 VFM 및 transfer set 조합의 성능 비교 결과, Task-oriented knowledge transfer는 모든 target task에서 task-agnostic transfer, ImageNet, CLIP, DINO pretraining 접근법보다 우수한 성능을 보임 (아래 Figure 참고)
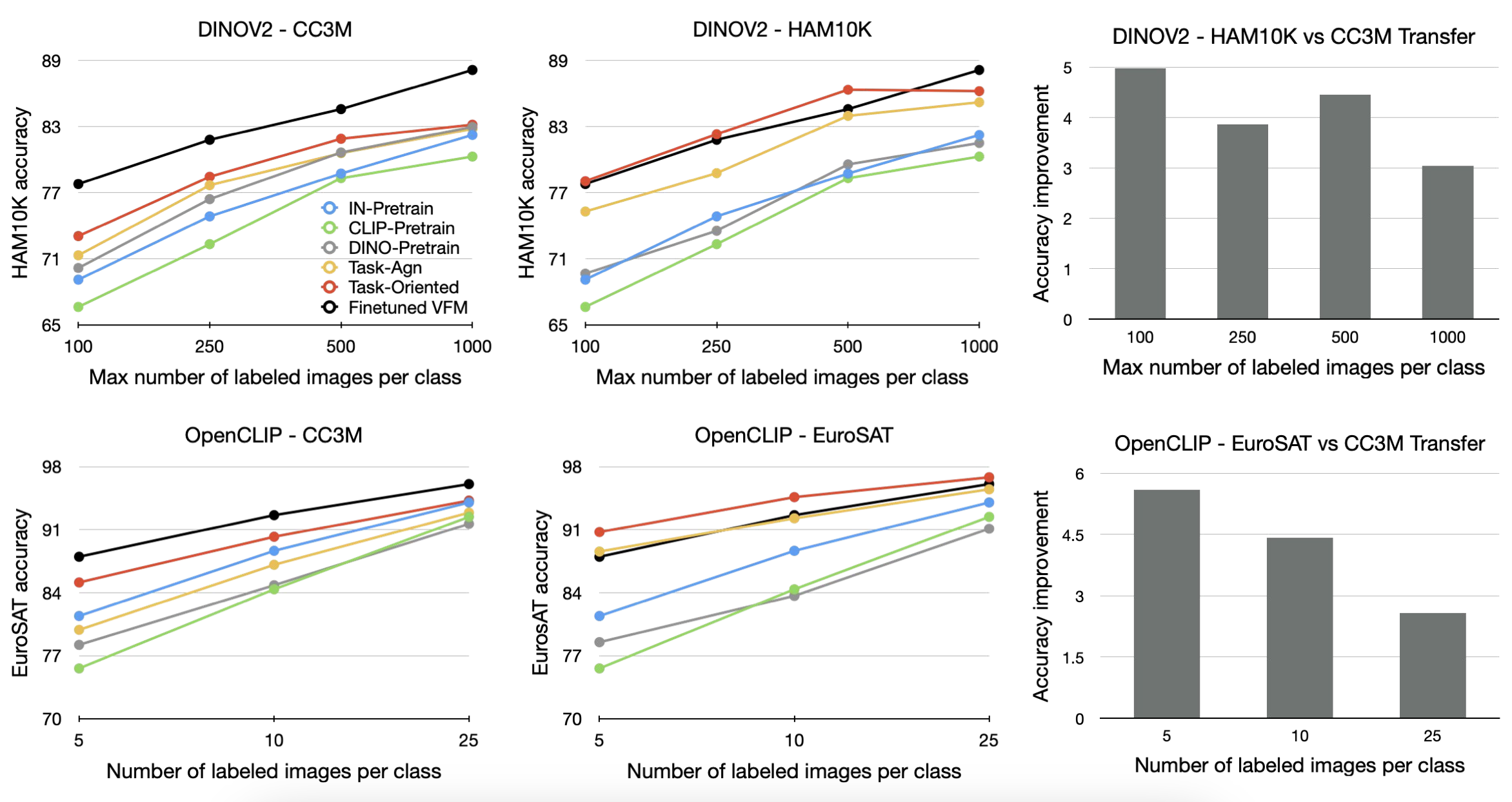

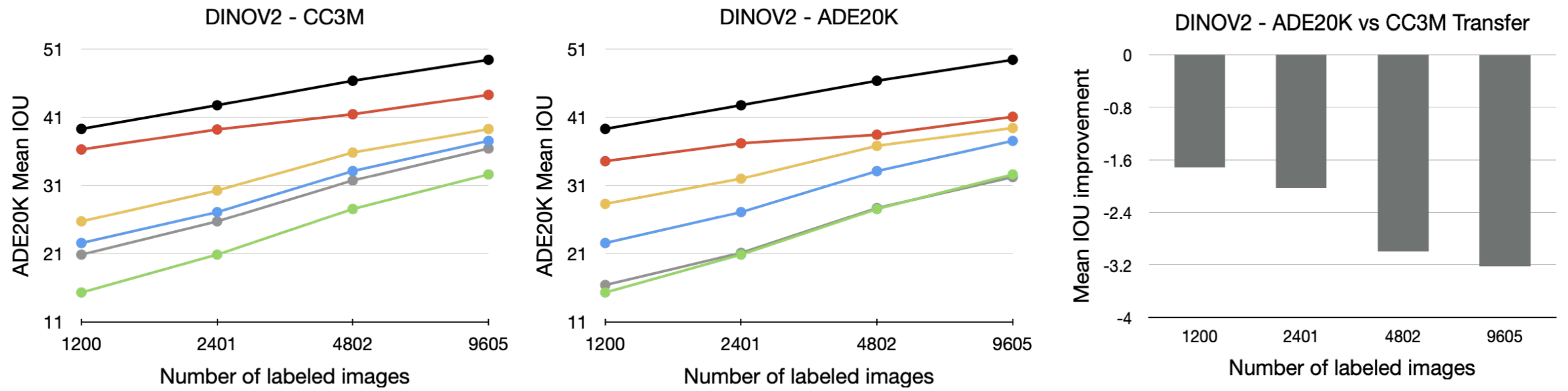
- Performance Gains
- CC3M Transfer Set 사용 시
- Task-agnostic transfer 대비 최대 11.6%, CLIP 대비 20.9%, ImageNet 대비 13.7%, DINO 대비 29.8% 성능 향상
- Task-related Transfer Set 사용 시
- Task-agnostic transfer 대비 최대 6.3%, CLIP 대비 22.1%, ImageNet 대비 12%, DINO 대비 21.7% 성능 향상
- CC3M Transfer Set 사용 시
- Task-related Transfer Set을 사용할 때, 일부 task에서는 finetuned VFM보다 우수한 성과를 보이며, 이는 large scale unlabeled target domain data를 사용한 knowledge transfer 과정 때문일 수 있음
3.2.2. Training Efficiency
- Task-oriented knowledge transfer는 다른 pretraining 전략에 비해 훨씬 적은 computing resource로 더 나은 성능을 달성
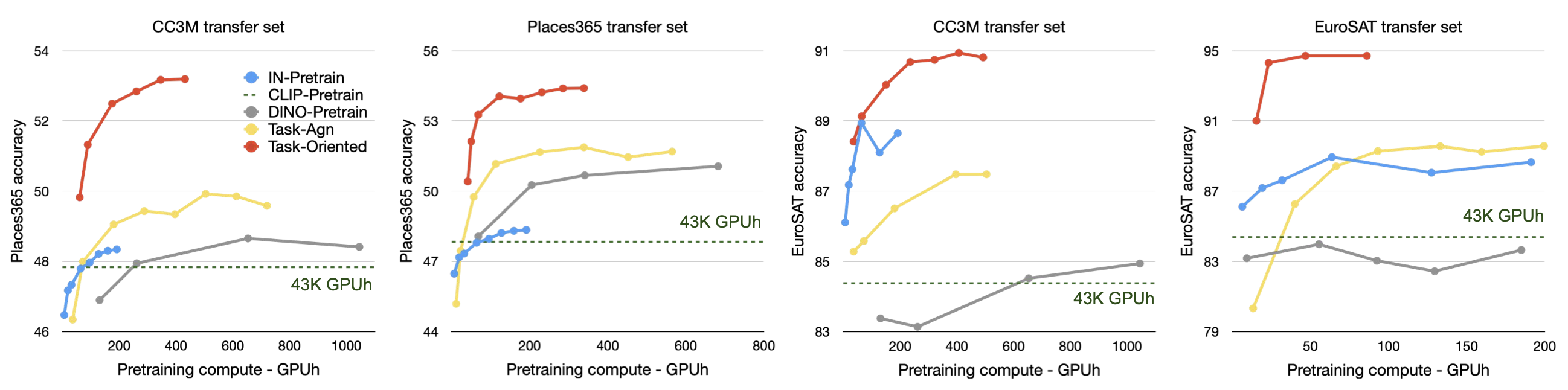
- Compute Cost Reduction
- Task-agnostic knowledge transfer 대비 최대 9배, ImageNet pre-training 대비 4배, DINO pre-training 대비 15배 감소
- CLIP pre-training은 훨씬 더 많은 computing resource를 사용(43K GPUh)하면서도 성능이 떨어짐
3.2.3. VFM Finetuning vs Linear Probing
- VFM을 target task에 맞추는 과정에서 linear probing과 full finetuning을 모두 고려
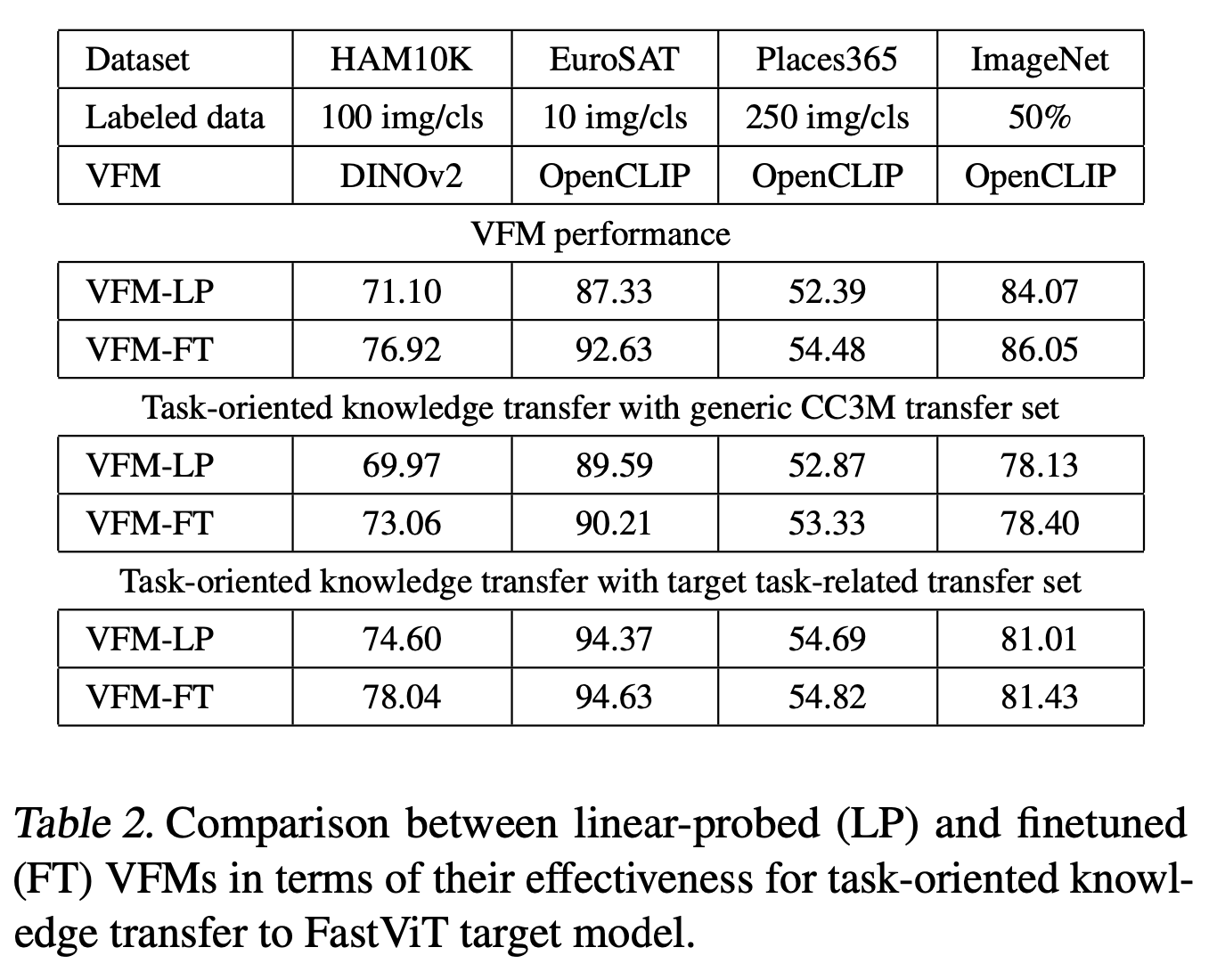
-
Finetuning이 대부분의 실험에서 linear probing보다 더 나은 성과를 보임
-
Linear-probed VFM과 finetuned VFM 간의 성능 차이는 크지만, target model로의 knowledge transfer에서는 그 차이가 작음
-
이는 VFM이 더 강력해짐에 따라 full finetuning이 꼭 필요하지 않을 수 있음을 시사
-
작은 target 모델은 task-related transfer set을 사용할 때 teacher VFM보다 더 나은 성과를 보이며, 이는 추가적인 unlabeled 샘플에 노출되었기 때문일 가능성이 있음
3.2.4. Contributions of Finetuning Step
- Task-oriented knowledge transfer 접근법의 마지막 단계는 제한된 labeled data로 target 모델을 finetune하는 것

- 이 finetuning 단계가 성능에 얼마나 기여하는지에 대한 의문이 있을 수 있음. Table 3에서 finetuning 단계로 인한 성능 향상을 보여줌
- Finetuning의 효과
- Pretraining 동안 일반적인 CC3M transfer set을 사용할 때, finetuning 단계가 상당한 성능 향상을 가져옴
- Target task-related transfer set을 사용할 경우, ADE20K segmentation task에서만 유의미한 성능 향상을 보였으며, classification task에서는 뚜렷한 성능 향상을 관찰하지 못함
3.3. Importance of Transfer Set
- 그림 3(b)는 task-oriented knowledge transfer에서 generic CC3M transfer set 대신 target task-related transfer sets를 사용했을 때, FastViT target 모델의 성능 향상 효과를 보여줌
- Target Task-related Transfer Set 사용 시 정확도 향상
- HAM10K (최대 5%), EuroSAT (7.3%), Places365 (2.3%), ImageNet classification task (10.9%)에서 정확도가 향상
- 하지만 ADE20K segmentation task에서는 generic CC3M transfer set이 더 나은 성능을 보임
- 이는 ADE20K transfer set 크기가 19.2K 이미지로 작기 때문일 수 있음. 이 문제는 다음 섹션에서 설명할 image retrieval을 사용해 더 큰 task-related transfer set을 생성함으로써 해결
3.4. Retrieval Augmented Knowledge Transfer
- HAM10K, EuroSAT, Places365, ImageNet classification task에서는 충분히 큰 target task-related transfer set이 일반적인 CC3M transfer set보다 더 나은 성과를 보임
- 그러나 모든 task에서 큰 transfer sets가 즉시 사용 가능하지 않을 수 있음
- 이를 해결하기 위해, image retrieval을 사용하여 큰 task-related transfer sets를 생성하는 방법을 제안
- Image Retrieval Method
- 제한된 target task labeled dataset을 쿼리 집합 로 사용하고, 웹에서 가져온 큰 이미지 집합을 갤러리 로 사용
- Encoder network 를 사용해 모든 이미지를 -dimension embedding 공간에 매핑하고, euclidean distance를 기반으로 검색을 수행
- 쿼리 균형 접근 방식을 따라, 쿼리 이미지 에 대해 그 이웃 중 개의 가장 가까운 이미지를 찾음
3.4.1. ADE20K Segmentation
- YFCC15M dataset (15M 이미지 포함)을 갤러리로 사용하고, OpenCLIP-ViT-L/14 image encoder와 FastViT target 모델 조합을 실험
- Retrieval Augmented Transfer Set 크기별 성능
- 4800개의 labeled 이미지로 구성된 dataset을 finetuning과 검색 쿼리로 사용했을 때, transfer set 크기가 154K 이미지에 도달할 때까지 성능이 증가하고 그 이후에는 감소
- 이는 YFCC15M의 많은 이미지가 ADE20K segmentation에 관련성이 낮기 때문일 수 있음
3.4.2. EuroSAT Classification
- EuroSAT dataset은 위성 이미지로 구성되어 있어, 더 큰 갤러리를 사용해 좋은 매칭을 찾을 확률을 높임
- DataComp-1B dataset (1.28B 이미지) 사용, 각 이미지에 대해 무작위로 변형된 10개의 crops를 생성하여 12.8B 이미지의 갤러리를 만듦
- Retrieval Augmented Transfer Set 크기별 성능
- 100개의 labeled 이미지를 사용해 성능이 약 51K에서 포화됨 (Saturation)
- 작은 쿼리 세트를 사용한 retrieval augmented transfer set이 generic CC3M transfer set보다 훨씬 더 나은 성능을 보이며, 전체 EuroSAT transfer set과 비교해도 경쟁력 있는 성과를 냄
5. Conclusions
- 본 연구는 pre-trained VFMs를 활용해 작은 task-specific 모델을 학습하기 위한 간단하지만 매우 효과적인 task-oriented knowledge transfer 접근법을 제안
- 이 접근법은 target task 성능과 학습 효율성 모두에서 task-agnostic VFM distillation, web-scale CLIP pre-training, supervised ImageNet pre-training, self-supervised DINO pre-training 접근법보다 뛰어난 성능을 보임
- Transfer sets
- Task-related transfer sets를 사용할 때 가장 효과적이나, 일반적인 웹 데이터(CC3M)를 사용할 때도 매우 효과적임
- Future works
- 추가적인 large scale unlabeled data를 활용하여 VFMs를 target task/domain에 더 잘 적응시키는 방법, 또는 active learning과 adversarial filtering을 통한 더 정교한 transfer set 구성 전략을 탐구
- Limitations
- Crop-based retrieval 전략은 다양한 이미지 집합에서 세밀한 retrival을 가능하게 하지만, 일부 specific domain에서는 여전히 큰 transfer set을 구성하는 것이 어려울 수 있음

AI Research Engineer