[논문 정리] DeblurGAN: Blind Motion Deblurring Using Conditional Adversarial Networks

https://arxiv.org/abs/1711.07064
1. Introduction
- 이 논문은 blind motion deblurring에 대한 연구
- Image super-resolution과 inpainting에서 Generative Adversarial Networks (GANs)의 활용으로 큰 진전이 있었음
- GANs는 image의 texture details을 보존하고, 실제 image와 유사한 image를 만들어내는 데 효과적
- 최근 연구에 영감을 받아 DeblurGAN을 제안, 이는 Conditional GAN과 multi-component loss function을 기반으로 하는 방법
- Wasserstein GAN과 perceptual loss를 사용하여 기존의 MSE나 MAE 최적화 대상보다 더 미세한 texture 복원이 가능
- Main Contributions:
- 첫째, 새로운 loss function과 architecture를 통해 기존의 방법보다 5배 빠른 속도로 state-of-the-art 달성
- 둘째, random trajectories 기반으로 motion deblurring 학습용 데이터를 자동으로 생성하는 방법을 제시
- 셋째, deblurring 알고리즘을 평가하는 object detection 성능 향상을 위한 새로운 데이터셋과 방법을 제안
2. Related work
2.1. Image Deblurring
-
Non-uniform blur model의 일반적인 수식은 다음과 같음:
- : Blurred image
- : Motion field 에 의해 결정되는 blur kernel
- : 선명한(sharp) latent image
- : Convolution 연산
- : Additive noise
-
Deblurring 문제는 blind deblurring과 non-blind deblurring으로 나뉨
- Non-blind deblurring은 blur kernel 이 알려진 상황을 가정
- Blind deblurring은 sharp image ()와 blur kernel ()을 모두 추정하는 문제
-
기존의 방법은 Lucy-Richardson 알고리즘, Wiener 필터, Tikhonov 필터 등을 사용해 deconvolution 연산 수행
-
Blind deblurring에서 각 픽셀에 대한 blur function을 찾는 것은 ill-posed problem이며, 대부분의 알고리즘은 휴리스틱, image 통계, blur 원인에 대한 가정에 의존
-
최근에는 Whyte 등이 파라미터화된 기하학적 model을 사용한 새로운 알고리즘을 개발했고, Gupta는 3D camera 움직임을 blur의 원인으로 가정
-
Convolutional Neural Networks (CNNs)을 사용한 새로운 방법들이 등장:
- Sun: CNN을 사용해 blur kernel 추정
- Chakrabarti: Fourier coefficients로 motion kernel을 추정
- Gong: Fully Convolutional Network로 motion 흐름 추정
-
Kernel-free end-to-end approaches:
- Noorozi와 Nah는 multi-scale CNN을 사용해 직접 deblurring 수행
- Ramakrishnan은 pix2pix framework와 densely connected convolutional networks를 결합하여 blind kernel-free image deblurring 수행
2.2. Generative adversarial networks
-
Generative Adversarial Networks (GANs)는 두 개의 경쟁하는 network(discriminator와 generator) 사이의 game으로 정의
- Generator는 noise를 입력받아 sample을 생성
- Discriminator는 실제 sample과 생성된 sample을 구분하려고 시도
- Generator의 목표는 Discriminator를 속여, 실제 image와 구분하기 어려운 설득력 있는 sample을 생성하는 것
-
GAN의 game은 다음 minimax objective로 설명:
-
여기서 은 데이터 분포, 는 model 분포
- 이며, 는 간단한 noise 분포에서 가져온 sample
- GANs는 실제 image와 유사한 설득력 있는 sample을 생성하는 데 능숙
-
GAN 학습에서 발생하는 문제들(예: mode collapse, vanishing gradients)이 있음
- 이러한 문제를 해결하기 위해 Wasserstein GAN (WGAN)이 제안
-
WGAN의 objective function은 Kantorovich-Rubinstein duality를 사용해 다음과 같이 정의:
-
는 1-Lipschitz functions의 집합이며, 는 model 분포
- Wasserstein distance를 사용하여 실제 분포와 model 분포 사이의 distance를 근사
- 이때 Discriminator는 critic이라고 불리며, sample 간의 distance를 근사
- WGAN에서는 Lipschitz constraint를 적용하기 위해 weight clipping을 사용
-
Gradient penalty를 적용하는 방식:
2.3. Conditional adversarial networks
-
GANs는 image-to-image translation 문제에 널리 사용됨
- 예: super-resolution, style transfer, photo generation
-
Conditional GAN (cGAN)은 조건부로 image translation을 수행하는 GAN의 일종
- cGAN은 입력 image 와 random noise vector 로부터 을 학습
- Discriminator에 조건을 추가하고 U-net architecture와 Markovian discriminator를 사용하여 다양한 작업에서 설득력 있는 결과를 얻음
- 예: label maps에서 synthesizing photos, edge maps에서 object reconstruction, image inpainting
3. The proposed method
- 목표는 blurred image 만을 입력으로 받아 선명한 image 를 복구하는 것
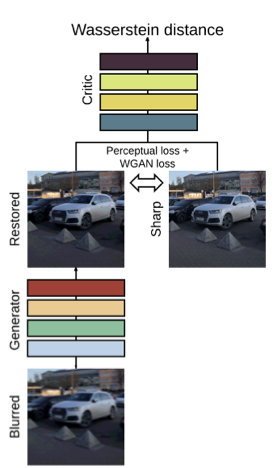
- Blur kernel에 대한 정보는 제공되지 않으며, Generator 역할을 하는 CNN 가 이 작업을 수행
- 각 에 대해 대응하는 image를 추정
- 학습 중 critic network 를 도입해 두 network를 adversarial manner로 학습
3.1. Loss function
-
Loss function은 adversarial loss와 content loss의 결합으로 정의:
-
여기서 는 100으로 설정 (모든 실험에서)
-
Adversarial loss는 다음과 같이 계산:
-
Content loss는 Perceptual loss를 사용하며, 이는 VGG19 network에서 추출된 feature map 간의 차이에 기초한 L2 loss
-
Perceptual loss는 일반적인 내용 복원에 집중하며, texture details 복원도 포함
-
TV regularization을 추가했으나, 성능은 27.9 vs. 28.7로 오히려 저하됨 (PSNR 기준, GoPro dataset)
3.2. Network architecture
- Generator CNN 구조는 두 개의 스트라이드 convolution block, 아홉 개의 residual blocks, 두 개의 transposed convolution blocks로 구성
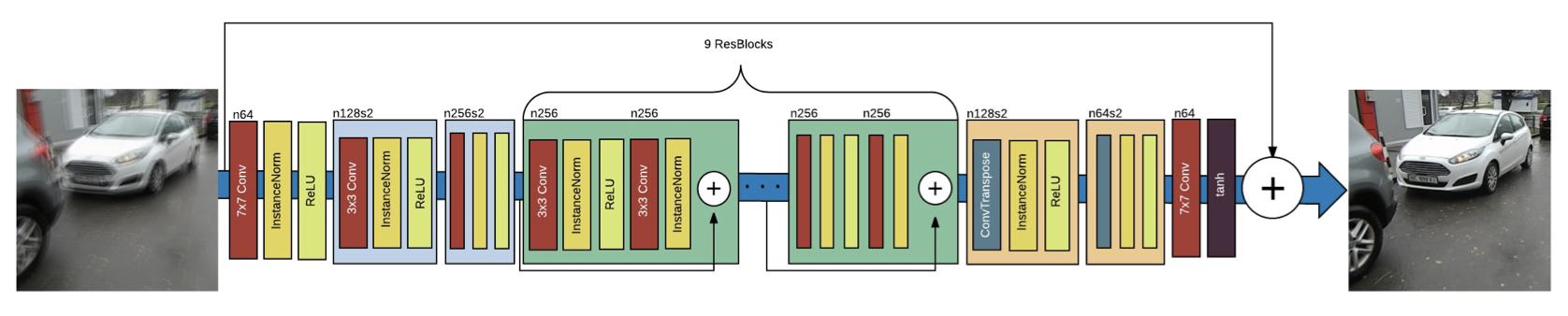
- 각 ResBlock은 convolution, instance normalization, ReLU activation을 포함
- Dropout regularization(확률 0.5)이 첫 번째 convolution layer 이후에 추가
- Global skip connection(ResOut)을 도입해 로 학습
4. Motion blur generation
-
Sharp image와 blurred image pair를 얻는 것은 쉽지 않음
- 대표적인 방법으로 high frame-rate camera를 사용해 비디오의 선명한 프레임들을 평균하여 blur를 시뮬레이션하는 방법
- 하지만 이 방법은 촬영된 비디오의 특정 장면으로만 한정되어 데이터셋 확장이 어려움
-
Sun et al.은 73개의 선형 motion kernel 중 하나를 사용해 깨끗한 자연 image를 convolution하여 synthetically blur image를 생성
-
Chakrabarti는 6개의 random point를 sample링하고, 이를 spline으로 맞추어 blur kernel을 생성
-
이 연구에서는 더 복잡하고 현실적인 blur kernel을 제안하며, Boracchi와 Foi의 random trajectories 생성 아이디어를 따름
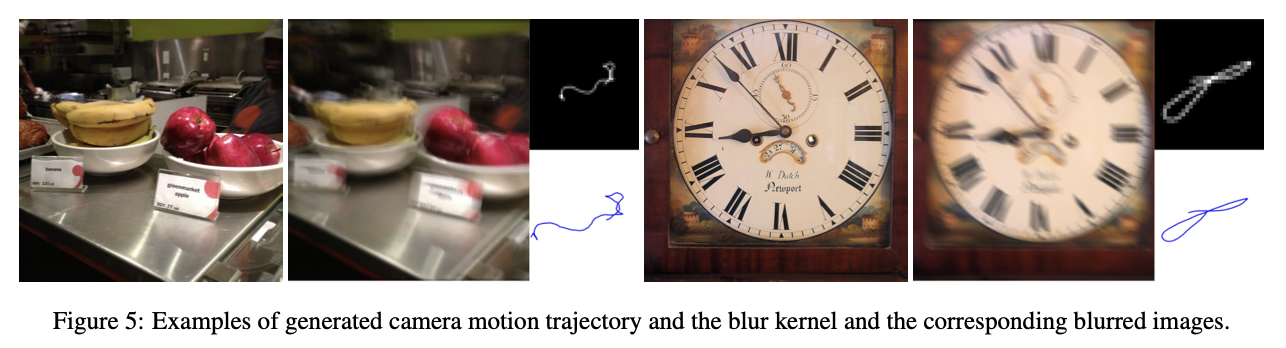
-
각 trajectory(궤적) vector는 2D random motion을 따르는 object의 위치를 나타내는 복소수 vector로, 이는 Markov process에 의해 생성 (아래 Pseudo code 참고)

- Trajectory의 다음 point 위치는 이전 point의 속도와 위치, Gaussian perturbation, impulse perturbation, deterministic inertial component에 기반해 random하게 생성
5. Training Details
- PyTorch를 사용해 모든 model을 구현
- DeblurGAN_WILD는 GoPro 데이터셋에서 256x256 크기의 random crop으로 학습
- DeblurGAN_synth는 MS COCO 데이터셋에서 synthetically blur image를 사용해 학습
- DeblurGAN_comb은 synthetically blur image와 실제 blur image를 함께 사용해 학습 (비율 2:1)
- 학습은 Adam을 사용하며, 첫 150 epcoh 동안 learning rate를 0으로 점진적으로 줄임
- 최종 추론 단계에서는 dropout과 instance normalization을 적용
6. Experimental evaluation
6.1. GoPro Dataset
- GoPro 데이터셋은 2103 pair의 blur 및 선명 image로 구성
- 결과는 아래 Table에 나와 있으며, DeblurGAN은 self-similarity, peak signal-to-noise ratio (PSNR)에서 우수한 결과를 보여줌
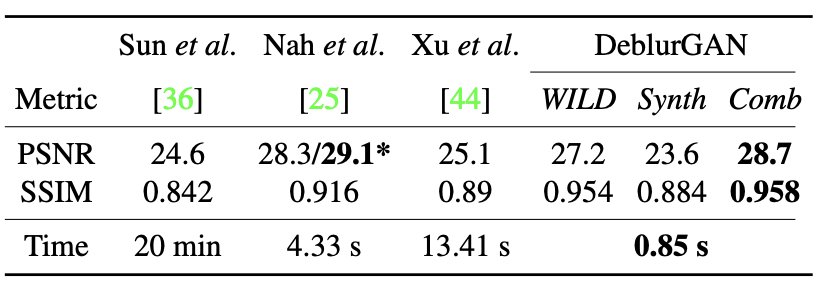
- Multi-scale CNN과 비교했을 때, 6배 적은 파라미터를 사용하여 빠른 추론 시간 확보
6.2. Kohler Dataset
- Kohler 데이터셋은 4개의 image와 12개의 다른 kernel로 구성된 벤치마크 데이터셋
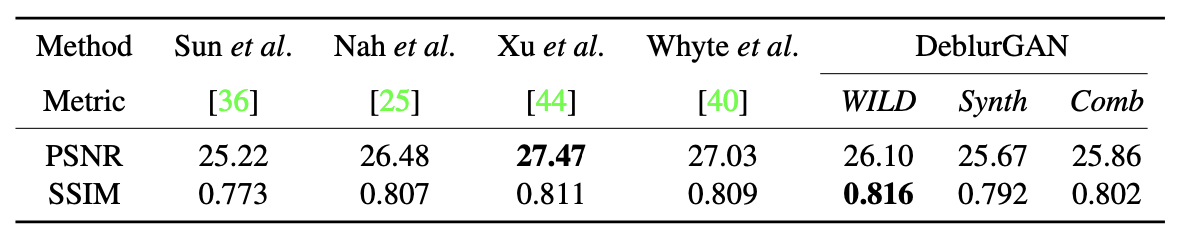
- 실제 camera motion을 기록해 생성된 데이터셋으로 6D camera motion trajectory를 사용
6.3. Object Detection benchmark on YOLO
- Object Detection은 컴퓨터 비전에서 잘 연구된 문제로, 다양한 분야에 적용됨

- 최근 몇 년간 Deep Convolutional Neural Networks 기반의 방법이 state-of-the-art 성능을 보여줌
- 그러나, 이 network들은 제한된 데이터셋으로 학습되며 실제 환경에서는 motion blur 같은 여러 아티팩트로 인해 image가 손상됨
- 본 연구는 motion blur가 object detection에 미치는 영향을 연구하고, 사전 학습된 YOLO network를 기반으로 deblurring 알고리즘의 성능을 평가하는 새로운 방법을 제안
- 이를 위해 high frame-rate camera를 사용하여 sharp 및 blurred image pair를 생성한 데이터셋을 구축
- blur source에는 camera shake와 자동차 움직임에 의한 blur가 포함
- YOLO network를 사용하여 선명한 image에 대해 object detection을 수행하고, 시각적 검증을 거쳐 ground truth로 사용
- 이후 blur된 image와 복원된 image에 대해 YOLO를 다시 수행하여, 얻은 결과와 ground truth 간의 average recall 및 precision을 계산
- 이 접근 방식은 deblurring models의 품질을 평가하는 새로운 방법을 제공
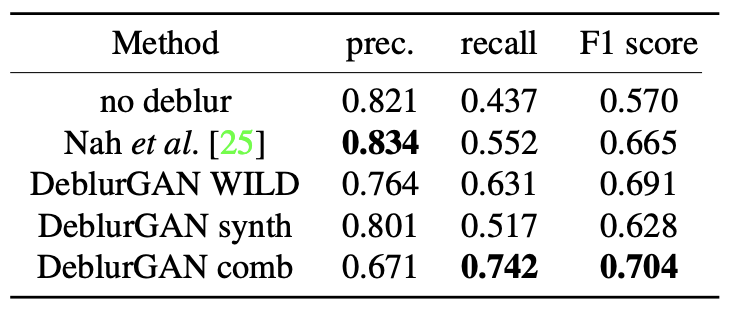
- 결과는 위 Table에 나타나 있으며, DeblurGAN이 recall과 F1 score에서 경쟁 model보다 우수한 성능을 보임
7. Conclusion
- 이 논문에서는 kernel-free blind motion deblurring 학습 방법을 소개하고, multi-component loss function으로 최적화된 DeblurGAN을 제안
- 또한 다양한 blur source를 modeling할 수 있는 현실적인 synthetic motion blur 생성 방법을 제시
- Object detection 결과를 기반으로 deblurring algorithms의 품질을 평가하는 새로운 벤치마크를 제시하고, DeblurGAN이 blur된 image에서 detection 성능을 크게 향상시킴을 보여줌
