https://arxiv.org/abs/2410.06718
1. Introduction
Deep Learning Model Scaling
- 딥러닝 모델은 Llama 3.2 시리즈와 같이 다양한 크기로 제공되며, 1B부터 90B까지 여러 크기가 있음
- 하지만 각 모델은 독립적으로 학습되기 때문에 동일한 Metric Space를 공유하지 않음
-> 모델들이 독립적으로 학습되기 때문에, 각 모델이 사용하는 내부 representation과 평가 기준(즉, Metric Space)이 다르게 형성됨. 이로 인해 서로 다른 크기의 모델이 동일한 데이터에서 일관된 성능이나 결과를 보장하지 못함 - 따라서 Speculative Decoding, Hybrid Cloud-Edge Inference와 같은 Inference Applications에서 효율적인 상황이 발생할 수 있음
- 특히 모델의 training cost가 높아 대부분 소수의 모델 크기만 선택적으로 학습되며, 이로 인해 2B 모델이 최적이지만 cost 문제로 1B 모델을 사용해야 하는 경우도 있음
Model Compression & Distillation
- 이러한 문제를 해결하기 위해 Model Compression과 Distillation 기법이 존재하지만, 추가 학습이 필요하고 Accuracy Drop이 발생할 수 있음
- 따라서 더 정밀한 단위에서의 Adaptive Inference 방법들이 필요
- 이러한 방법은 이미 Transformers와 ConvNets에서 연구되어 왔으며, 이를 더욱 효과적으로 구현하기 위한 노력이 이루어지고 있음
State Space Models
- Mamba2(Dao & Gu, 2024)와 같은 State Space Models (SSMs)는 Transformer에 비해 효율적인 scaling을 제공하며, 특히 더 긴 Context Length에서도 빠르게 작동
- 본 연구는 이러한 아키텍처를 기반으로 한 새로운 MatMamba 구조를 제안
MatMamba
- MatMamba는 Matryoshka Structure를 기반으로 하여 Mamba2 Block 안에 계층적으로 여러 Sub-Blocks를 배치하는 방식
- 이 구조를 통해 각 Sub-Block이 동적으로 다양한 Granularity에서 최적의 성능을 발휘할 수 있음
-> Granularity는 모델의 세부적인 구성 단위를 의미. 즉, 모델이 얼마나 세밀한 수준에서 구조를 조정할 수 있는지를 나타내며, 작은 단위에서부터 큰 단위까지 다양한 수준의 Sub-blocks를 조정하여 성능을 최적화하는 능력을 말함. Granularity가 높을수록 더 세밀한 조정이 가능 - 즉, 작은 모델에서부터 큰 모델까지 하나의 아키텍처 안에서 모두 유연하게 처리할 수 있으며, 높은 Accuracy와 낮은 Compute Cost를 동시에 달성
Main Contributions
-
MatMamba Introduction: MatMamba는 Matryoshka Structure를 기반으로 Mamba2 State Space Model에 적용된 새로운 아키텍처임. 이 구조는 모든 Granularity에서 최적화를 통해 하나의 유연한 Elastic Model을 가능하게 함
-
Scalability and Performance: MatMamba는 다양한 크기의 모델에서 Baseline Mamba2 Models와 동일하게 동작하며, 35M에서 1.4B Parameters까지 확장 가능함. 이를 통해 Language와 Vision Tasks에서 강력한 성능을 발휘
-
Mix’n’Match Flexibility: Mix’n’Match 기술을 사용하여 수백 개의 Submodules를 유연하게 결합할 수 있으며, 이를 통해 Adaptive Inference를 가능하게 하고 Performance와 Compute Cost 간의 최적의 균형을 찾음
-
Visual Task Adaptation: MatMamba-Vision 모델은 작은 Submodules를 활용해 적은 Compute로도 high-resolution의 Visual Tasks를 처리할 수 있음. 특히 ViT보다 더 효율적이며, Long-form/High-resolution Visual Processing에서 높은 성능을 보임
3. MatMamba
3.1. Mamba2 Preliminaries
-
MatMamba는 Mamba2를 기반으로 하며, Matryoshka Structure를 추가하여 간단히 수정된 형태
- Matryoshka 구조는 러시아의 마트료시카 인형처럼, 작은 블록이 큰 블록 내부에 중첩되는 형태를 의미
-
이 구조는 input linear projection, Causal 1D Convolution Layer, Chunk + Selective Scan Operation (SSM), output projection layer로 구성
-
이 블록은 Transformer와 유사하게 작동하며, 모양의 텐서를 입력받아 순차 변환 후 다시 형태의 output을 생성
-
(1)
- 위 수식은 Mamba2 Block에서 input 를 처리하는 첫 단계
- 여기서 Conv는 1D Causal Convolution을 나타내며, 는 각 그룹에 적용되는 weight
- 이 weight들끼리의 결합(즉, )은 서로 다른 Sub-blocks의 파라미터를 함께 사용하여 모델이 서로 다른 특성을 학습하도록 함
- 그다음 , , 는 input 에 대해 weighted sum을 적용한 것
- 는 activation function(이 경우 SiLU를 사용)를 뜻하며, nonlinearity를 부여하여 모델이 복잡한 패턴을 학습하도록 도움
-
(2)
- 여기서 는 SSM (Selective Scan Operation)을 통해 나온 결과
- 는 이전 수식에서 계산된 값이고, 는 SSM에 적용되는 추가 weight
- , 는 학습 가능한 SSM Parameters로, 이 값들을 이용해 SSM에서 sequence 데이터를 선택적으로 처리
- 이 단계에서는 sequence 데이터의 특정 부분을 집중적으로 다루어 효율적인 계산을 수행
-
(3)
- 이 수식은 마지막 Normalization 단계
- 에서 activation 된 output에 weight를 곱하고 activation function을 한 번 더 적용함으로써 모델이 추가적으로 non-linear 패턴을 학습하도록 함
- 그 후 Layer Normalization(여기서는 RMSNorm을 사용)이 적용되어 output을 안정화시키며, 는 최종 projection에 사용되는 weight matrix
- 이 과정을 통해 최종적으로 MatMamba Block의 output을 완성
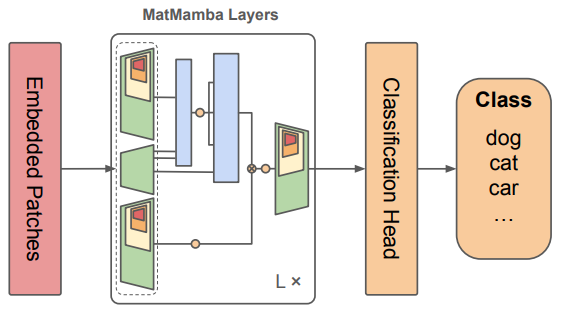
3.2. MatMamba Block
- MatMamba Block은 input과 output 모두 모양을 가지며, Mamba2 blocks로 이루어진 Nested Structure
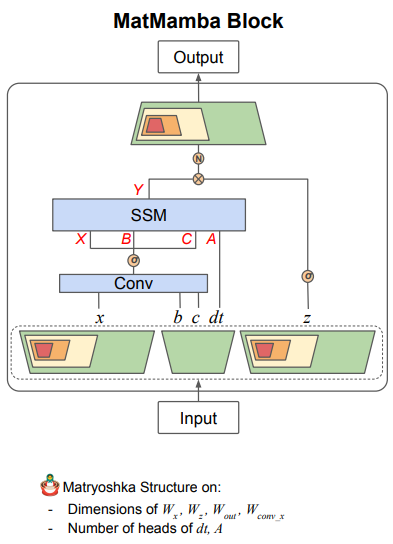
-
각 Sub-block 는 Matryoshka Dimension 에 따라 선택되며, 파라미터를 효율적으로 사용할 수 있도록 설계
-
Mamba2 구조에서 파라미터의 수를 줄이면서도 모델 성능을 유지하는 특징을 가지고 있음
-
(4)
- 이 수식은 Sub-block 에 해당하는 처리 과정을 나타냄
- Matryoshka 구조에 따라 각 Sub-block은 전체 모델의 작은 부분집합
- 여기서 는 이 Sub-block에서 사용되는 dimension
- 이전의 Conv 연산을 에 맞춰 축소된 weight로 수행하여, 더 작은 dimension의 데이터를 효율적으로 처리
-
(5)
- 는 이전 수식에서 나온 를 바탕으로 SSM을 적용한 결과
- 여기서 는 특정 Sub-block에서 사용하는 Heads의 수이며, 이 역시 에 맞춰 축소된 값
- 이로 인해 모델은 작은 규모에서도 필요한 부분만 선택적으로 처리할 수 있음
-
(6)
- 는 각 Sub-block에서 처리된 후의 최종 output
- 와 의 부분집합을 이용하여 최종 activation과 Normalization을 수행한 뒤, output projection을 통해 완성
3.3. Training
Training Process
- MatMamba 블록들로 구성된 모델을 학습할 때, g Granularities에서 각각의 Submodel에 대해 Joint Loss Function을 계산
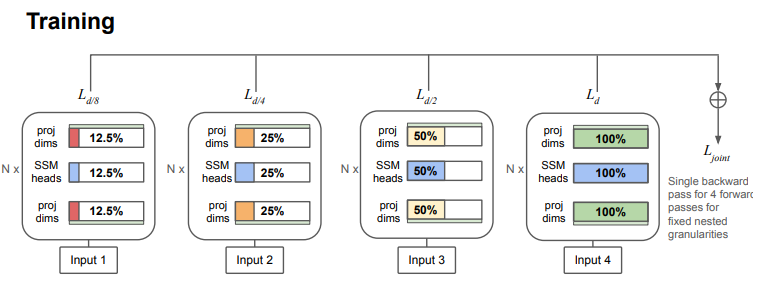
- 각 모델은 g 번의 Forward Pass를 거치며 Single Backward Pass를 수행
(7) - Forward Pass 동안 각 Submodel에 대해 loss 값을 계산하고, Backward Pass에서는 모든 loss 값을 합산해 한번에 파라미터를 업데이트
- 이렇게 함으로써 각 Granularity의 Submodel들이 동시에 학습되면서 성능을 극대화
- 여기서 는 각각의 Submodel에 할당된 weight이며, 본 연구에서는 로 설정
3.4. Mix’n’Match
- Mix’n’Match 전략은 MatFormer(Devrit et al., 2023)에서 사용된 방법을 MatMamba에도 적용하여, 다양한 Granularities의 Submodels을 유연하게 선택해 Inference에 활용할 수 있음
- 각 layer 에서 dimension 를 선택할 수 있으며, 명시적으로 최적화된 개의 Granularity 중에서 선택하거나, 명시적으로 학습되지 않은 dimension을 선택할 수도 있음
- 예를 들어, 135M-MatMamba-Vision 모델에서 (25% 크기), (100% 크기), (75% 크기) 등을 선택해 혼합할 수 있음
- Matryoshka Structure 덕분에, 첫 번째 5개의 dimension들은 강력한 representation을 학습하도록 유도
3.5. Elastic Inference
- Elastic Inference에서는 MatMamba 모델을 배포할 때 단일 Universal Model을 메모리에 저장해두고 Inference할 수 있음
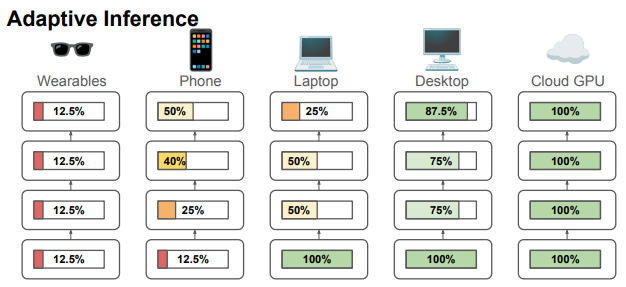
- Compute 제약이 없으면 전체 모델을 사용해 최적의 성능을 낼 수 있고, 반대로 Compute 제약이나 에너지 사용, 정확도 요구에 따라 일부 네트워크 조각을 선택적으로 사용할 수도 있음
- 또한, Cloud와 Edge Inference를 결합할 가능성도 있음
- 예를 들어, 더 작은 Submodel을 엣지 장치에 배치하고, 필요시 Cloud에서 더 큰 모델을 사용하거나, 작은 모델로 Speculative Decoding을 하고 더 큰 모델로 검증할 수도 있음
- 이러한 적응 가능한 Submodel Selection이 가능하도록 설계되어 있음
4. Experiments
4.1. MatMamba-Vision
- MatMamba-Vision은 image classification과 adaptive image retrieval에서 효율적으로 작동하는 아키텍처
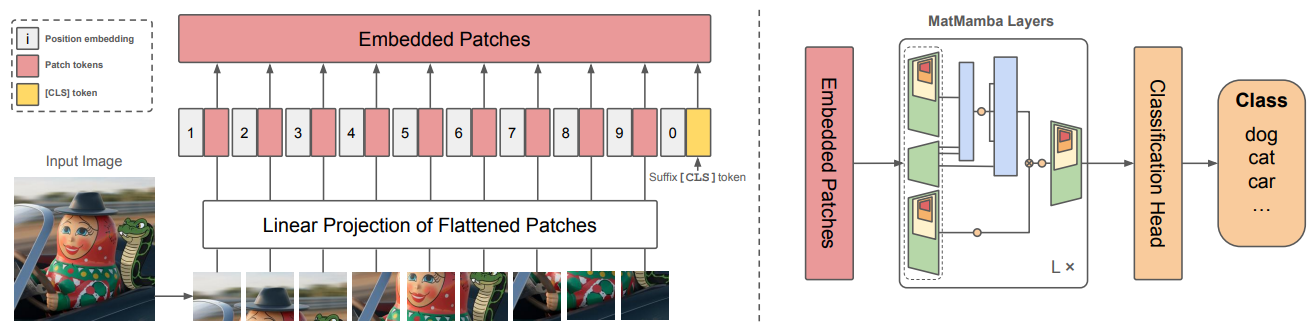
- 이 모델은 개의 MatMamba Blocks와 Unidirectional SSM Scan으로 구성되어 있으며, [CLS] token을 Suffix로 사용하여 sequence 전체에서 정보를 추출
- 이를 통해 sequence 내 모든 위치의 정보를 효과적으로 활용할 수 있음
- 아래 테이블과 같이, ImageNet-1K에서 35M 파라미터(패치 크기 16, )와 135M 파라미터(패치 크기 16, )로 각각 학습된 두 가지 모델이 실험에 사용
- 이 실험에서 Mix’n’Match 전략을 사용해 다양한 Granularities를 결합하여 성능을 극대화할 수 있었음
- 이렇게 결합한 Submodels은 명시적으로 학습된 Granularities 사이에서 성능과 파라미터 수 간의 최적 균형을 제공
4.1.1. Image Classification
Adaptive Inference using Mix’n’Match
- 실험 결과, 35M 및 135M MatMamba-Vision 모델의 명시적으로 최적화된 Submodels은 동일한 아키텍처로 독립적으로 학습된 4개의 Baseline Models과 성능이 매우 비슷하게 나타남
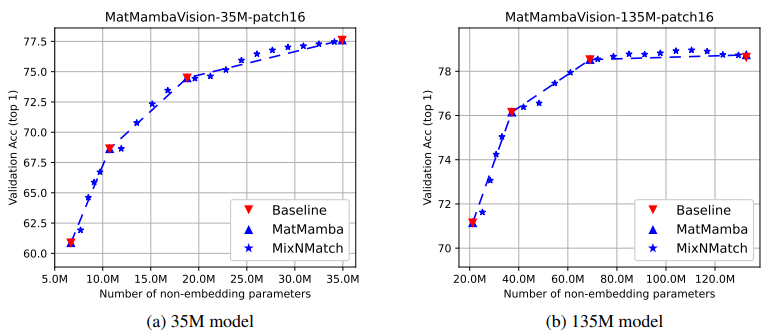
- 하지만, 4개의 개별 모델 대신 하나의 MatMamba-Vision 모델을 사용해 유연하게 Granularity를 조정하면서도 성능을 유지할 수 있었음
- 또한 Mix’n’Match를 사용한 adaptive Inference를 통해, 다양한 Granularity를 결합하여 최적화되지 않은 dimension도 유연하게 조정할 수 있었음
- 이를 통해 더 많은 Submodels을 결합하여 정확도를 극대화할 수 있음
Inference Speeds at Higher Resolutions
- 이 부분에서는 MatMamba-Vision 모델의 Nested Granularities가 서로 비교될 때, 그리고 ViT-B/16 모델과 비교될 때 Inference Speed의 트레이드오프를 연구
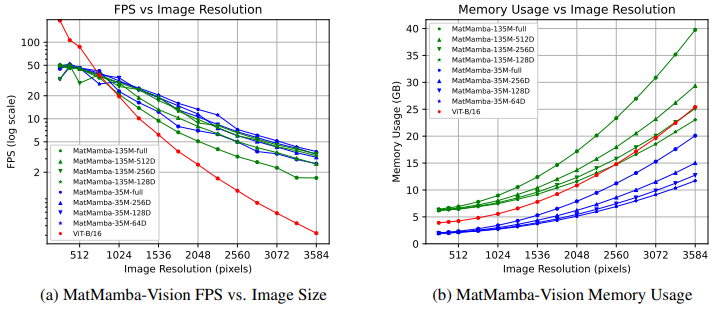
- 512px 이하의 resolution에서는 ViT가 GPU Parallelism과 FlashAttention과 같은 최적화 덕분에 가장 빠른 모델로 나타남. 그러나 resolution이 1024px 이상으로 증가하면, Mamba-style 모델이 Throughput과 Latency 측면에서 ViT를 능가하기 시작
- 메모리 사용량 또한 연구했으며, resolution이 증가함에 따라 MatMamba-Vision이 최적화된 ViT-B/16보다 더 잘 확장됨을 확인. 이 결과는 MatMamba 기반 모델이 더 높은 resolution에서 긴 sequence의 visual 데이터를 단일 가속기에서 처리할 수 있는 가능성을 보여줌
- 이는 RingAttention(Liu et al., 2023)과 같은 방법을 사용하는 Transformers와는 달리, 여러 가속기 없이 긴 sequence에서도 단일 Forward Pass로 처리할 수 있음을 시사
4.1.2. Adaptive Image Retrieval
- MatMamba-Vision은 Image Retrieval에서 유연성을 제공하는 강력한 후보
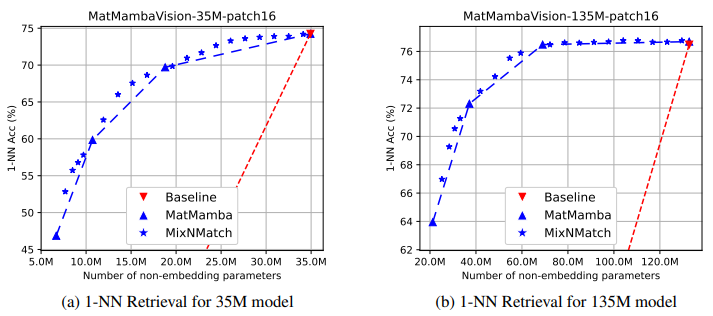
- 이는 다양한 Granularity를 통해 database와 query embedding 간의 거리 관계를 유지하면서도 효율적인 retrieval을 가능하게 함
- 예를 들어, 135M-MatMamba-Vision 모델은 파라미터 수가 적은 모델임에도 불구하고 55% 이상의 computational cost 절감을 제공하면서도 성능 손실이 거의 없음
- 이 실험에서는 [CLS] token을 활용한 image retrieval에서 Nearest Neighbor (NN) 정확도를 평가하였으며, 이 전략을 사용한 Submodel들이 거리 유지 능력을 효과적으로 제공함을 입증
4.2. MatMamba-LM
- MatMamba-LM은 MatMamba Block을 사용해 Decoder Language Models를 학습하는데, 학습 절차와 Hyperparameters는 11m.c (Karpathy, 2024)를 따름
- MatMamba-LM의 Base model architecture는 아래 표와 같이 설정

- GPT-2 Tokenizer(Radford et al., 2019)를 사용하며, 50,280개의 어휘 크기를 가짐. FineWeb Dataset(Penedo et al., 2024)을 사용해 130M, 370M, 790M, 1.4B 크기의 모델을 학습
- 아래 그림은 MatMamba-LM이 모든 모델 및 학습 scale에 걸쳐 명시적으로 최적화된 Mamba2 Baseline과 동등하게 scaling 됨을 보여줌
- 이와 동시에, MatMamba-LM은 학습 중간에도 정확한 Sub-models을 제공할 수 있는 유연성을 가짐
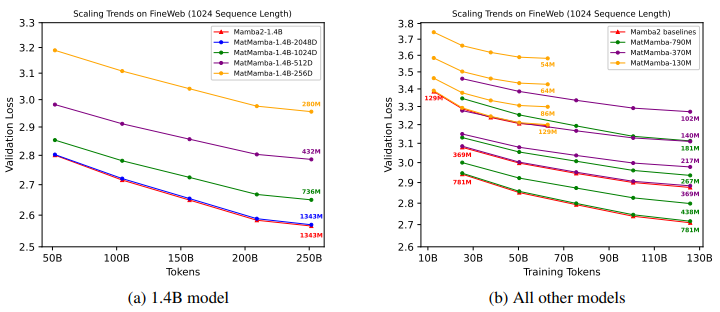
- 각 모델은 4개의 Granularities 에 대해 최적화
- 아래 그림은 language modeling task에서 모델 크기에 따른 validation loss을 보여줌
- MatMamba-LM은 명시적으로 최적화된 Granularities에서 Mamba2 Baseline만큼 정확하며, 동시에 Mix’n’Match를 통해 Pareto Optimal Submodels을 가능하게 함
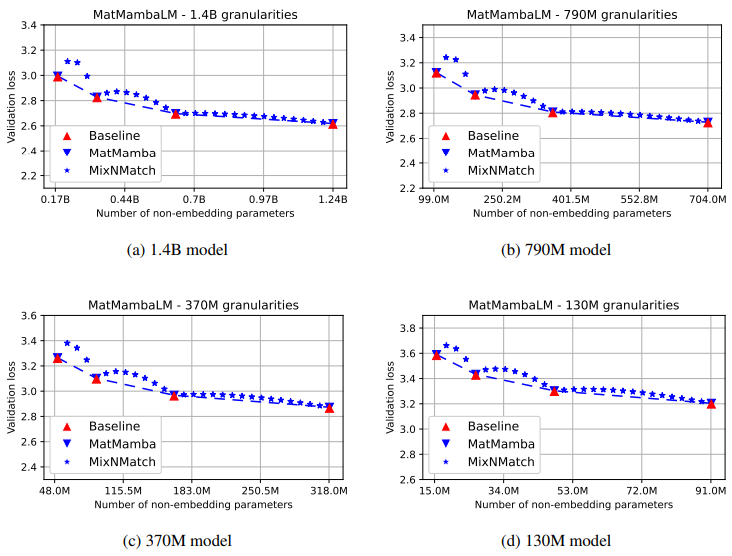
- MatMamba-LM 모델은 Mamba2 모델과 동일하게 확장되며, 모든 Granularity에서 Baseline Model과 유사한 성능을 보임
- 각 Granularity의 validation loss가 가장 큰 모델과 가장 작은 모델 간의 차이는 대개 0.4의 loss 차이로 일관되게 나타남
- 이를 통해, 하나의 MatMamba-LM 모델이 4개의 개별 모델 대신 다양한 배포 요구에 맞춰 사용할 수 있음을 보여줌
5. Conclusions
- 본 연구에서는 MatMamba라는 아키텍처를 제시하였으며, 이는 Mamba2 State Space Model에 중첩된 Matryoshka Structure를 적용한 방식
- 이 구조는 Mamba-style Models의 장점(더 빠른 Inference Time 및 Matryoshka-style Learning)을 결합하여, 다양한 크기의 Submodels을 유연하게 추출하고 사용할 수 있게 설계
- MatMamba-Vision과 MatMamba-LM은 Mamba2와 유사한 성능과 정확도를 유지하면서도, 단일 Matryoshka-style 모델로 여러 시나리오에 맞춰 Speculative Decoding, Input-Adaptive Submodel Selection, Hybrid Cloud-Edge Inference 등의 사용 사례를 가능하게 함
