https://arxiv.org/abs/1503.02531
1. Introduction
생물학적 비유와 머신 러닝
- 곤충은 에너지 추출에 최적화된 유충 단계와 이동 및 번식에 최적화된 성충 단계를 가짐
- 이와 유사하게, 머신 러닝에서 학습 단계와 배포 단계는 상이한 요구사항을 가짐:
- 학습 단계: 대규모의 중복된 dataset에서 구조를 추출하며, 실시간 처리나 계산 자원 제약이 적음
- 배포 단계: 낮은 지연 시간과 제한된 계산 자원 요구
- 이러한 비유는 데이터 구조 추출을 위해 복잡한 모델(cumbersome model)을 학습 단계에서 사용하고, 배포에 적합한 Small 모델로 지식을 Transfer 하는 전략을 제안
Knowledge Distillation Concept
- 복잡한 모델(예: 앙상블 또는 dropout과 같은 강한 정규화를 적용한 Large 모델)을 학습한 후, "Distillation" 과정을 통해 지식을 배포에 적합한 Small 모델로 Transfer
- Rich Caruana 등의 선행 연구 [1]에서 Large 앙상블 모델의 지식을 단일 Small 모델로 Transfer 가능함을 입증
- 지식은 학습된 파라미터 값이 아니라 입력 벡터에서 출력 벡터로의 매핑으로 정의, 모델 형태와 독립적인 추상적 개념으로 간주
복잡한 모델의 지식
- 복잡한 모델은 올바른 답변에 높은 확률을 부여하며, 잘못된 답변에도 상대적인 확률 분포 제공
- 예: BMW 이미지가 쓰레기 트럭으로 오인될 확률은 매우 낮지만, 당근으로 오인될 확률보다 훨씬 높음
- 이는 모델의 일반화 방식에 대한 중요한 정보 제공
- 이러한 상대적 확률은 학습 데이터에서 일반화된 패턴을 반영, Small 모델로 Transfer 시 유용
학습 목표의 불일치
- 일반적으로 모델은 학습 데이터 성능 최적화에 초점, 하지만 실제 목표는 새로운 데이터에 대한 일반화
- Distillation은 복잡한 모델의 일반화 능력을 Small 모델로 Transfer 하여, 동일한 학습 데이터로 학습된 Small 모델보다 우수한 테스트 성능 달성
- 복잡한 모델의 클래스 확률을 "soft targets"로 사용하여 Small 모델 학습, 높은 엔트로피의 soft targets는 hard targets보다 더 많은 정보와 낮은 gradient 변동 제공
2. Distillation
2.1. Distillation Procedure
- Neural Network은 softmax output layer를 사용하여 각 클래스에 대한 logit 를 확률 로 변환:
- 여기서 는 Temperature로, 일반적으로 1로 설정
- 높은 값은 클래스 간 더 부드러운 확률 분포 생성
Distillation Mechanism
- 기본 Distillation: 복잡한 모델의 높은 Temperature softmax에서 생성된 soft target 분포를 사용하여 Transfer set에서 Small 모델 학습
- Small 모델 학습 시 동일한 높은 Temperature 사용, 학습 후에는 로 설정하여 일반 예측 수행
- Transfer set에 정답 label이 포함된 경우, soft targets와 정답 label을 동시에 학습하여 성능 개선
- Objective Function
- 두 Loss function의 가중 평균 사용:
- Soft Target Cross Entropy: 복잡한 모델의 soft targets와 Small 모델의 softmax 출력(높은 Temperature) 간의 Cross Entropy
- Hard Target Cross Entropy: 정답 label과 Small 모델의 softmax 출력() 간의 Cross Entropy
- 두 Loss function의 가중 평균 사용:
- Soft target의 gradient는 로 스케일링되므로, 두 Loss의 상대적 기여도를 일정하게 유지하기 위해 soft target loss에 곱셈 적용
- Hard target loss에 낮은 가중치(예: 0.1) 부여로 최적 결과 도출
2.2. Matching logits is a special case of distillation
Gradient 분석
- Transfer set의 각 사례는 Small 모델의 logit 에 대한 Cross Entropy gradient 에 기여
- 여기서 는 Large 모델(cumbersome model)의 soft target 확률, 는 복잡한 모델의 logit
- 는 Small 모델(distilled model)의 softmax 출력 확률, 클래스 에 대해 Small 모델이 예측한 확률
- 높은 Temperature Approximate 가 logit 크기에 비해 클 때, gradient는 다음과 같이 Approximate
- 각 Transfer case에 대해 logit이 zero-meaned ()라면
- 이는 높은 Temperature에서 Distillation이 최소화와 equivalent 임을 보여줌
- 쉽게 말하면, 높은 Temperature에서 Distillation 효과가 “최적이 된다”는 의미인데,
- 높은 T에서 loss를 최소화했을 때, 작은 모델이 큰 모델의 지식을 더 잘 학습할 수 있다는 뜻
- 이는 작은 모델이 단순히 큰 모델의 “가장 높은 확률 클래스”만 배우는 것이 아니라, 클래스 간의 상대적인 관계(즉, 더 풍부한 정보)를 학습할 수 있기 때문
- 높은 T는 Soft target의 확률 분포가 더 부드럽기 때문에, 작은 모델이 과적합(overfitting)하거나 너무 단순화된 패턴(예: 가장 높은 확률만 학습)에 치우치지 않고, 일반화된 지식을 더 잘 흡수할 가능성이 높아짐
시사점
- 낮은 Temperature에서는 낮은 음수인 logit에 덜 주목, 이는 잡음이 많은 logit을 무시하는 장점 제공
- 그러나 음수 logit은 복잡한 모델의 지식에 유용한 정보 포함 가능
- Small 모델이 복잡한 모델의 모든 지식을 포착하기에 너무 작을 경우, 중간 Temperature(예: )가 최적 성능 제공, 음수 logit의 영향을 부분적으로 줄이는 것이 유리함
Transfer Dataset
- Transfer set은 원본 학습 dataset 또는 별도의 unlabeled dataset 사용 가능
- 원본 학습 dataset 사용 시, 정답 label 예측을 유도하는 추가 Loss term 추가가 효과적
- Small 모델은 soft targets를 완벽히 매칭하지 못하므로, 정답 방향으로 오차 조정이 성능 향상에 기여
3. Preliminary experiments on MNIST
실험 설정
- Large Neural Network: 1200개의 ReLU Hidden unit을 가진 두 개의 Hidden layer, 60,000개 MNIST 학습 데이터로 학습, dropout 및 가중치 제약 [5]으로 강한 정규화 적용
- Dropout은 가중치를 공유하는 지수적으로 많은 앙상블 모델 학습으로 간주
- 입력 이미지는 최대 2픽셀 이동으로 Data augmentation (jittering)
- 결과: 테스트 오류 67개
- Small Neural Network: 800개의 ReLU Hidden unit을 가진 두 개의 Hidden layer, 정규화 없이 학습, 테스트 오류 146개
- Distillation 적용: Small Neural Network에 Large Neural Network의 Temperature 에서 생성된 soft targets 매칭 과제 추가, 테스트 오류 74개
- 이는 soft target이 일반화 지식(이동된 학습 데이터 포함)을 Small 모델로 효과적으로 Transfer 함을 보여줌 (Transfer dataset에 이동 데이터 미포함에도 불구하고)
Temperature 효과
- Small Neural Network의 Hidden layer unit이 300개 이상일 경우, Temperature 에서 유사한 성능 관찰
- unit 수를 30개로 급격히 줄이면, Temperature 에서 범위가 더 높은 또는 낮은 Temperature 보다 우수한 성능 제공
Transfer dataset 변형 실험
- 숫자 3 제외: Transfer dataset에서 숫자 3을 완전히 제외, Small 모델은 3을 학습 데이터로 보지 못함
- 결과: 테스트 오류 206개, 이 중 1010개의 테스트 3에서 133개 오류
- 오류 원인: 3 클래스에 대한 학습된 bias가 지나치게 낮음
- Bias를 3.5 증가(테스트 성능 최적화) 시, 총 오류 109개, 3에서 14개 오류, 즉 3의 98.6% 정확도 달성
- 이는 Small 모델이 학습 중 3을 보지 않았음에도 Distillation을 통해 강력한 일반화 성능 제공함을 시사
- 숫자 7과 8만 포함: Transfer dataset에 학습 데이터의 7과 8만 포함
- 결과: 테스트 오류율 47.3%
- 7과 8의 bias를 7.6 감소(테스트 성능 최적화) 시, 오류율 13.2%로 감소
4. Experiments on speech recognition
실험 개요
- 자동 음성 인식(ASR)에서 DNN 음향 모델 앙상블의 Distillation 효과 평가
- Distillation 전략은 앙상블의 지식을 단일 모델로 Transfer, 동일 데이터로 학습된 단일 모델보다 우수
모델 및 학습
- DNN: 8개 Hidden layer(각 2560 ReLU unit), 14,000개 HMM 타겟 softmax 출력, 약 8500만 파라미터
- 입력: 26프레임 Mel-scaled 필터뱅크 계수(10ms 이동), 21번째 프레임 HMM 상태 예측
- 학습: 2000시간 영어 음성 데이터(7억 사례), 프레임 단위 Cross Entropy 최소화
- 여기서 는 HMM 상태, 는 음향 관찰
결과
- Baseline: 프레임 정확도 58.9%, WER 10.9%
- 10배 앙상블: 프레임 정확도 61.1%, WER 10.7%
- 단일 모델 Distillation: 프레임 정확도 60.8%, WER 10.7%
5. Training ensembles of specialists on very big datasets
5.1. The JFT dataset
dataset 개요
- JFT: Google 내부 dataset, 1억 개 레이블 이미지, 15,000개 클래스
- Baseline 모델: Deep CNN, asynchronous stochastic gradient descent로 6개월 학습, 다중 코어 병렬 처리 학습
5.2. Specialist Models
- 대규모 클래스 처리: 앙상블은 전체 데이터를 학습한 일반 모델 1개와 혼동되기 쉬운 클래스 하위 집합에 특화된 Expert 모델 다수로 구성
- Expert 모델은 비관심 클래스를 dustbin 클래스로 통합, softmax 크기 축소
- 과적합 방지: 일반 모델 가중치로 초기화, 학습 데이터는 특화 클래스(50%)와 무작위 샘플(50%)로 구성
- 편향 보정: dustbin 클래스 logit을 특화 클래스 과다 샘플링 비율의 로그만큼 증가
5.3. Assigning classes to specialists
클러스터링 방법
- 일반 모델 예측의 공분산 행렬에 online K-mean 알고리즘 적용, 혼동되기 쉬운 클래스 집합 식별
JFT 1: Tea party; Easter; Bridal shower; Baby shower; Easter Bunny; ...
JFT 2: Bridge; Cable-stayed bridge; Suspension bridge; Viaduct; Chimney; ...
JFT 3: Toyota Corolla E100; Opel Signum; Opel Astra; Mazda Familia; ...
- True label 없이 공분산 행렬 기반 클러스터링, 다양한 알고리즘으로 유사 결과 확인
5.4. Performing inference with ensembles of specialists
추론 과정
- 입력 이미지 에 대해 2단계 top-1 분류
- 일반 모델로 가장 가능성 높은 클래스 집합 () 식별
- 와 교집합이 있는 Expert 모델 을 활성 집합 로 선택, KL divergence 최소화:
- 여기서 , 은 일반 및 Expert 모델의 확률 분포, ()는 gradient descent으로 최적화된 logit 기반 분포
- Dustbin 클래스는 에서 비관심 클래스 확률 합산
- Kullback-Leibler divergence ?
- 두 확률 분포 와 간의 차이를 측정하는 비대칭 척도
- 정보 이론에서 사용, 를 참 분포로 가정 시 가 얼마나 유사한지 평가.
(이산 분포 Baseline) - Expert 앙상블 추론에서, 일반 모델 분포 와 Expert 모델 분포 을 결합하여 최적 분포 를 구함
- 모델 간 예측 차이를 정량화, 앙상블의 통합된 예측 분포 최적화에 활용
- Kullback-Leibler divergence ?
5.5. Results
학습 효율
- Expert 모델은 Baseline 모델 가중치 초기화로 며칠 내 학습 완료 (JFT Baseline 수주 대비), 독립적 병렬 학습 가능
성능 결과
- Baseline 모델 대비 61개 Expert 모델 추가 시 테스트 정확도 4.4% 상대적 개선
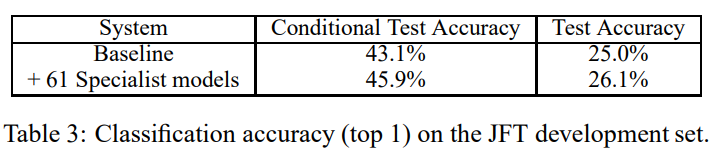
- 조건부 테스트 정확도(특화 클래스에 제한)도 향상
- 클래스당 Expert 모델 수 증가 시 Top-1 정확도 개선폭 증가, 병렬 학습 효율성 입증
- Soft targets 활용으로 과적합 방지, Expert 모델의 일반화 성능 향상
Top-1 정확도 개선 분석
- JFT dataset에서 클래스당 Expert 모델 수에 따른 테스트 세트 성능 분석
- Expert 모델을 사용 시 Top-1 정확도에서 정답 수 증가 및 상대적 정확도 개선율 측정
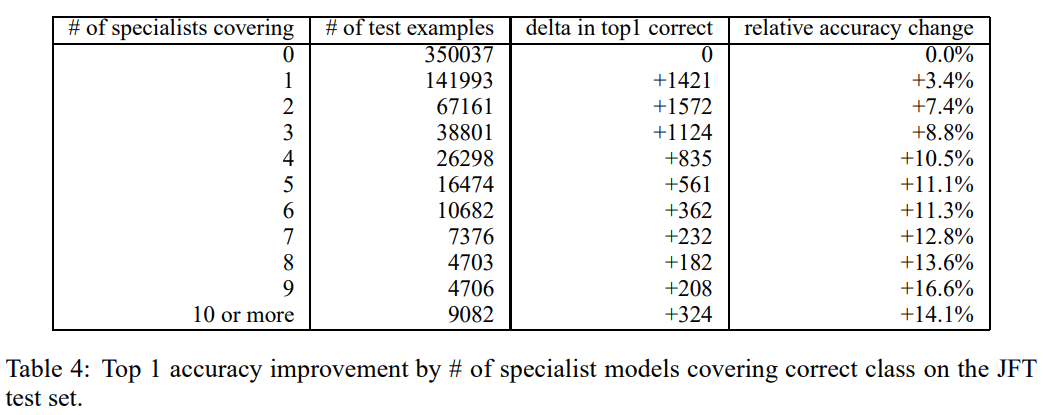
- 주요 발견: 클래스당 Expert 모델 수 증가 시 정확도 개선폭 커짐
- 독립적 Expert 모델 학습의 병렬화 용이성으로, 다수 Expert 모델 활용이 효율적
6. Soft Targets as Regularizers
6.1. Using soft targets to prevent specialists from overfitting
Soft Targets의 역할
- Soft targets는 hard target이 담을 수 없는 풍부한 정보를 제공, 8500만 파라미터 음성 모델에서 확인
- 학습 데이터 3% (약 2000만 사례)로 Baseline 모델 학습 시, hard targets는 과적합(최대 정확도 44.5% 후 급감, 조기 종료 필요) (아래 테이블 참고)

- Soft targets로 학습 시 조기 종료 없이 57% 정확도 달성, 전체 데이터 정보의 약 98% 회복
- 이는 soft targets가 전체 데이터에서 학습된 모델의 일반화 정보를 효과적으로 전달함을 보여줌
Expert 모델 적용
- JFT dataset의 Expert 모델은 비관심 클래스를 dustbin 클래스로 통합, 과적합 가능성 높음
- 일반 모델 가중치로 초기화 후, 비특화 클래스에 soft targets(일반 모델 제공)와 특화 클래스에 hard targets를 결합 학습, 과적합 방지 및 비특화 클래스 지식 유지
- 현재 이 접근법 탐구 중
7. Relationship to Mixtures of Experts
Expert 혼합 비교
- Expert 혼합(Mixtures of Experts, MoE) [6]은 게이팅 네트워크가 각 사례를 Expert에 할당, Expert의 판별 성능 기반으로 할당 확률 학습
- MoE는 입력 벡터 클러스터링보다 우수하나, Expert 간 상호 의존으로 병렬화 어려움
- 반면, Expert 모델은 일반 모델 학습 후 혼동 행렬로 특화 클래스 정의, 독립적 병렬 학습 가능
- 테스트 시 일반 모델 예측으로 관련 Expert 선택, 효율적 추론 가능
8. Discussion
Distillation 효과
- Distillation은 앙상블 또는 강하게 정규화된 Large 모델의 지식을 Small 모델로 효과적으로 Transfer
- MNIST에서 Transfer dataset에 특정 클래스(예: 3) 미포함 시에도 우수한 성능, Android 음성 검색 DNN 앙상블의 개선 대부분을 단일 모델로 Transfer
- 대규모 Neural Network의 앙상블 학습은 계산 비용 문제로 비현실적이나, 혼동되기 쉬운 클래스 클러스터에 특화된 Expert 모델 학습으로 단일 Large 모델 성능 크게 개선
- Expert 모델의 지식을 단일 Large 모델로 Distillation하는 것은 미탐구 과제

AI Research Engineer