https://arxiv.org/abs/2303.15343
Abstract
- 언어-이미지 사전 학습을 위한 Sigmoid Loss을 제안하며, 이는 효율성과 성능 향상을 가져올 수 있음
- Sigmoid Loss는 CLIP의 표준 Contrastive Loss와 달리, 이미지-텍스트 쌍을 독립적으로 처리하여 배치 크기 확장이 용이
- 실험 결과, Sigmoid Loss는 작은 배치 크기에서 더 나은 성능을 보이고, 노이즈에 Robust
- ImageNet 제로샷 정확도에서 CLIP보다 우수하며, 제한된 자원으로도 빠른 학습이 가능
Introduction
- 이 논문은 언어-이미지 사전 학습에서 Sigmoid Loss(SigLIP)를 도입하여, 기존 CLIP의 Contrastive Loss(InfoNCE)보다 효율적이고 확장 가능한 방법을 제시
- Sigmoid Loss는 이미지-텍스트 쌍을 독립적으로 평가하여, 작은 배치 크기에서도 성능을 높이고 큰 배치 크기에서도 잘 작동
주요 장점
- 작은 배치 크기(4k~8k)에서 CLIP보다 우수한 성능을 보임
- 메모리 효율성이 높아, 제한된 하드웨어(4 TPUv4 칩)로도 2일 만에 84.5% ImageNet 제로샷 정확도를 달성
- 데이터 노이즈에 강건하며, 다양한 벤치마크에서 CLIP, OpenCLIP 등 기존 모델을 능가
실험 결과
- 실험에서 SigLIP은 ImageNet-1k에서 79.2%, ObjectNet에서 74.7%의 제로샷 정확도를 기록하며, CLIP(B/196)의 68.3%, 55.3%를 상회
- 또한, 다국어 작업에서도 뛰어난 성능을 보임
Method
SigLip의 Sigmoid Loss vs. CLIP의 InfoNCE Loss
- Sigmoid Loss(SigLIP)은 CLIP의 표준 Contrastive Loss(softmax 기반 InfoNCE)과 크게 다름
수식 비교
-
Softmax-Based Contrastive Loss:
- Softmax loss는 image model 와 text model 를 아래 objective를 최소화하도록 학습
- 배치 크기에 따라 계산 복잡도가 급격히 증가하며, 글로벌 정규화 필요
- Softmax loss는 image model 와 text model 를 아래 objective를 최소화하도록 학습
-
Sigmoid-Based Contrastive Loss:
- Sigmoid Loss는 글로벌 정규화 없이 각 이미지-텍스트 쌍을 독립적으로 처리, 이진 분류 문제로 변환
- 각 쌍 독립 평가, 메모리 효율적, 노이즈에 강건.
요약
- 시그모이드 손실은 작은 배치 크기(4k~8k)에서 우수하며, 큰 배치 크기에서도 확장 가능
- 특히, 4 TPUv4 칩으로 2일 만에 84.5% ImageNet 제로샷 정확도를 달성하며, 데이터 노이즈에 강한 성능을 보임
| 측면 | Sigmoid Loss(SigLIP) | Softmax Loss(CLIP) |
|---|---|---|
| 설명 | Sigmoid 연산 사용, 각 이미지-텍스트 쌍 독립 평가, 글로벌 정규화 없음 | Softmax 연산 사용, Positive 쌍 Loss는 배치 내 모든 Negative 쌍에 의존 |
| 문제 정의 | 이진 분류: 매칭 쌍(Positive) vs. 비매칭 쌍(Negative) | 다중 클래스 분류: 이미지 를 배치 내 모든 Negative 텍스트 중 매칭 텍스트 에 할당 |
| 메모리 복잡도 | NxN 행렬 필요 없음, 대규모 배치 크기에서도 점진적 평가 가능 | 글로벌 정규화 필요, NxN 행렬로 이차 메모리 복잡도 |
| GPU 통신 | 텍스트 특징만 전달, 1회 all-gather 연산 | 이미지와 텍스트 특징 모두 전달, 2회 all-gather 연산 |
| 배치 크기 영향 | 32k에서 최적, 작은 배치(4k~8k)에서 우수 | 98k에서 피크, 큰 배치 크기에서 성능 차이 줄어듦 |
| 노이즈 강건성 | 데이터 노이즈에 강건, 5가지 부패 방법에서 우수 | 노이즈에 덜 강건, 성능 저하 |
- Sigmoid Loss는 각 쌍을 독립적으로 처리하여 메모리 효율성을 높이고, 특히 작은 배치 크기에서 수렴이 빠르며 노이즈에 강한 장점을 보임
Experiments
-
다양한 실험을 통해 SigLIP과 SigLiT(Sigmoid Loss 기반 모델)의 성능을 평가했으며, CLIP, OpenCLIP, EVA-CLIP, CLIPA-v2 등 기존 방법과 비교. 주요 결과는 다음과 같음:
-
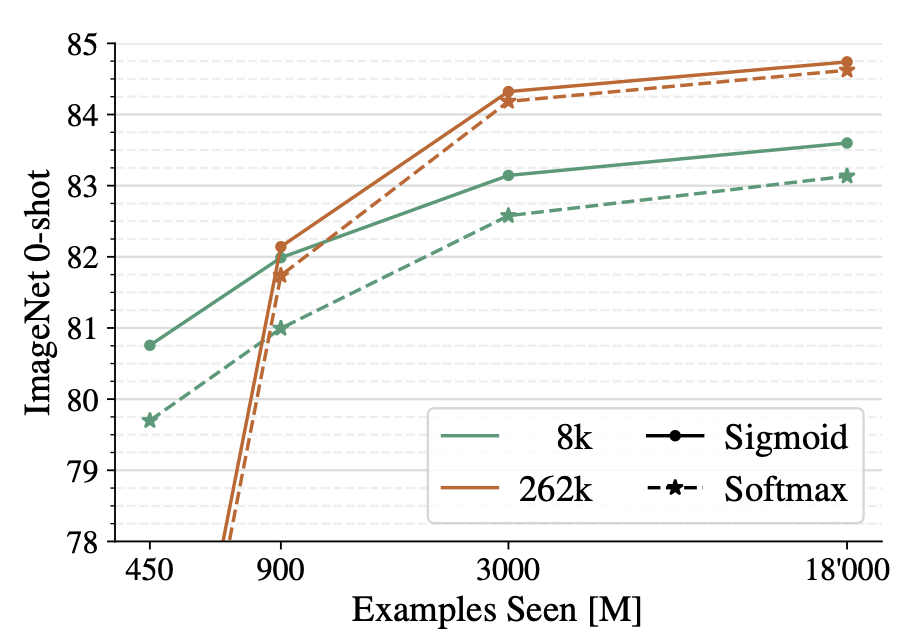
제로샷 ImageNet 정확도:
- SigLiT B/8, 32k 배치 크기, 4 TPUv4 칩, 1일 학습으로 79.7% 달성
- SigLiT g/14, 20k 배치 크기, 4 칩, 2일 학습으로 84.5% 달성
- CLIP은 256 TPUv3 코어에서 5~10일 학습 필요, 비교적 느림
-
확장 비교(Table 3):
- 아래 표는 다양한 벤치마크에서의 성능을 보여줌:
모델 ImageNet-1k (%) ImageNet-v2 (%) ObjectNet (%) COCO I→T R@1 (%) COCO T→I R@1 (%) SigLIP B/1024 79.2 73.0 74.7 67.6 50.4 SigLIP L/576 82.1 75.9 81.0 70.6 52.7 CLIP B/196 68.3 61.9 55.3 52.4 33.1 - SigLIP은 모든 벤치마크에서 CLIP을 능가하며, 특히 ObjectNet과 COCO 검색 작업에서 큰 차이를 보임
-
다국어 성능:
- mSigLIP(32k 배치 크기)으로 XM3600(36개 언어)에서 텍스트-이미지 검색 평균 34.9% 달성, 기존 28.5%보다 우수
- 확장된 mSigLIP(*32k)으로 이미지 검색 R@1 54.1%, 텍스트 검색 R@1 42.6% 기록
-
배치 크기 영향:
- SigLIP은 32k 배치 크기에서 최적 성능(73.4%, 9B 예제), 307k 이상에서는 성능 저하(71.6%)
- Softmax는 98k에서 피크(73.2%), 큰 배치 크기에서 성능 차이 줄어듦
Conclusion
- "Sigmoid Loss for Language Image Pre-Training"은 언어-이미지 사전 학습에서 혁신적인 접근법을 제시
- Sigmoid Loss는 계산 복잡도를 줄이고, 작은 배치 크기에서 우수한 성능을 보이며, 노이즈에 강건
- 실험 결과, SigLIP과 SigLiT은 CLIP, OpenCLIP 등 기존 모델을 다양한 벤치마크에서 능가하며, 다국어 작업에서도 뛰어난 성능을 보임
- 이 연구는 제한된 자원으로도 고품질 비전-언어 모델 학습 가능성을 열어주며, 실세계 응용에서 큰 잠재력을 가짐

AI Research Engineer