https://arxiv.org/abs/1903.04688
1. Introduction
Semantic Segmentation의 중요성과 도전 과제
- Semantic segmentation은 이미지 이해를 위한 핵심 과제로, 각 픽셀에 고유한 카테고리 레이블을 할당하는 dense labeling map 예측을 목표
- Autonomous driving, video surveillance 등 다양한 응용 분야에서 큰 잠재력 보유
- Deep fully convolutional network(FCN) 기반 방법들이 주목할 만한 성과를 달성
기존 방법의 한계
- 복잡한 모델과 많은 파라미터로 인해 계산 부담이 큼
- High-resolution feature map을 유지하기 위해 작은 stride를 적용하는 최신 FCN 방법들은 계산 비용이 높아 실용성 제한
- 예: DeepLabV3+는 Xception-65 기반으로 PASCAL VOC, Cityscapes에서 우수한 성능을 보이지만, 41.0M 파라미터와 최대 6110G FLOPS로 효율성 문제 발생
- Feature map 해상도를 줄이는 sub-sampling은 정보 손실로 인해 정확도 저하 초래
Knowledge Distillation의 가능성과 한계
- Knowledge distillation(KD)은 teacher 네트워크의 soft label을 활용해 student 네트워크를 학습시켜 효율성과 단순성 제공
- 기존 KD 방법은 image-level classification에 초점을 맞춰 spatial context 구조를 고려하지 않음
- Semantic segmentation에 직접 적용하기 부적합
제안 방법의 개요
- Semantic segmentation에 특화된 새로운 KD 방법 제안
- Teacher의 풍부한 semantic knowledge를 compact representation으로 변환해 student가 쉽게 학습 가능하도록 설계
- Knowledge 변환은 teacher feature에서 unsupervised 방식으로 pre-trained된 auto-encoder를 통해 수행
- Affinity distillation module을 도입해 teacher와 student 간 넓은 spatial 영역의 관계를 조절, long-term dependency 전달
- 제안 방법은 student 모델의 성능을 추가 파라미터 없이 크게 개선하며, 큰 해상도 출력 모델 대비 8% FLOPS로 동등하거나 더 나은 결과 달성
3. Proposed Method
Overview
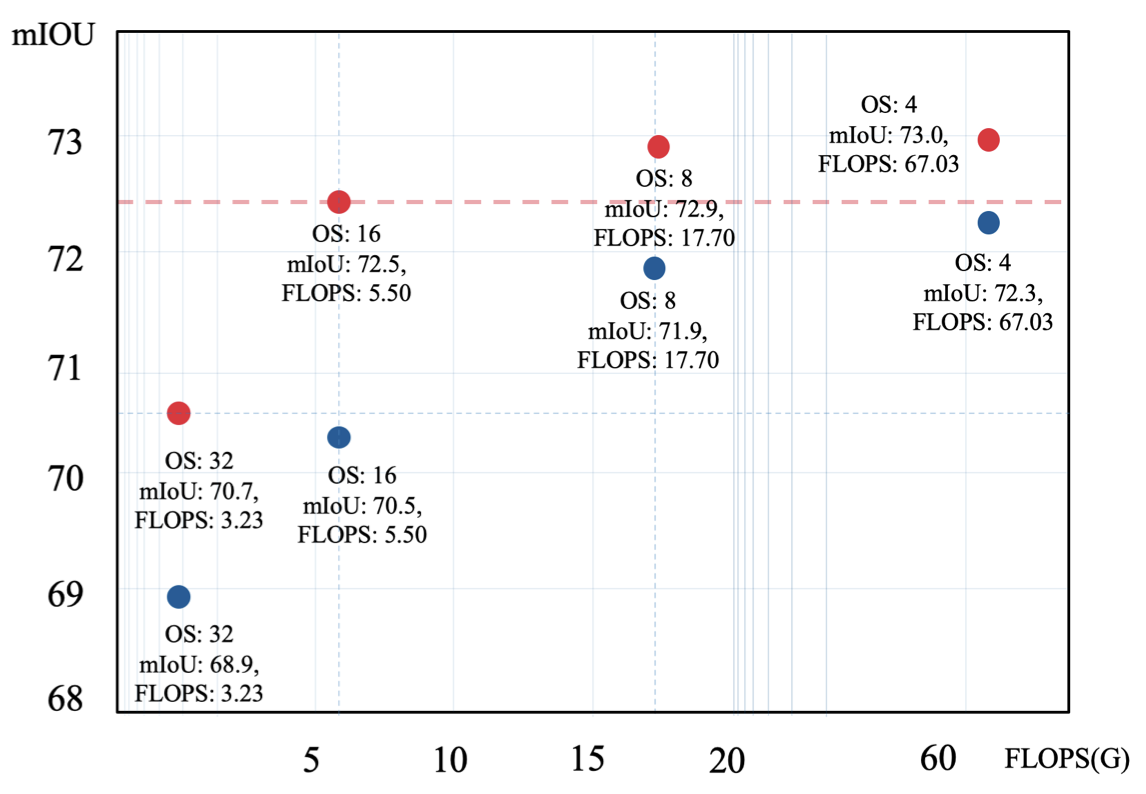
- Atrous convolution을 활용한 작은 output stride 네트워크는 큰 output stride 네트워크보다 세부 정보 포착에서 우수, 아래 Figure 1 참조
- Semantic segmentation에 특화된 새로운 knowledge distillation 방법 제안
- Framework는 두 네트워크로 구성: 고해상도 출력(예: 8s overall stride)의 teacher 네트워크와 빠른 추론을 위한 저해상도 출력(예: 16s overall stride)의 student 네트워크, 아래 Figure 2 참조
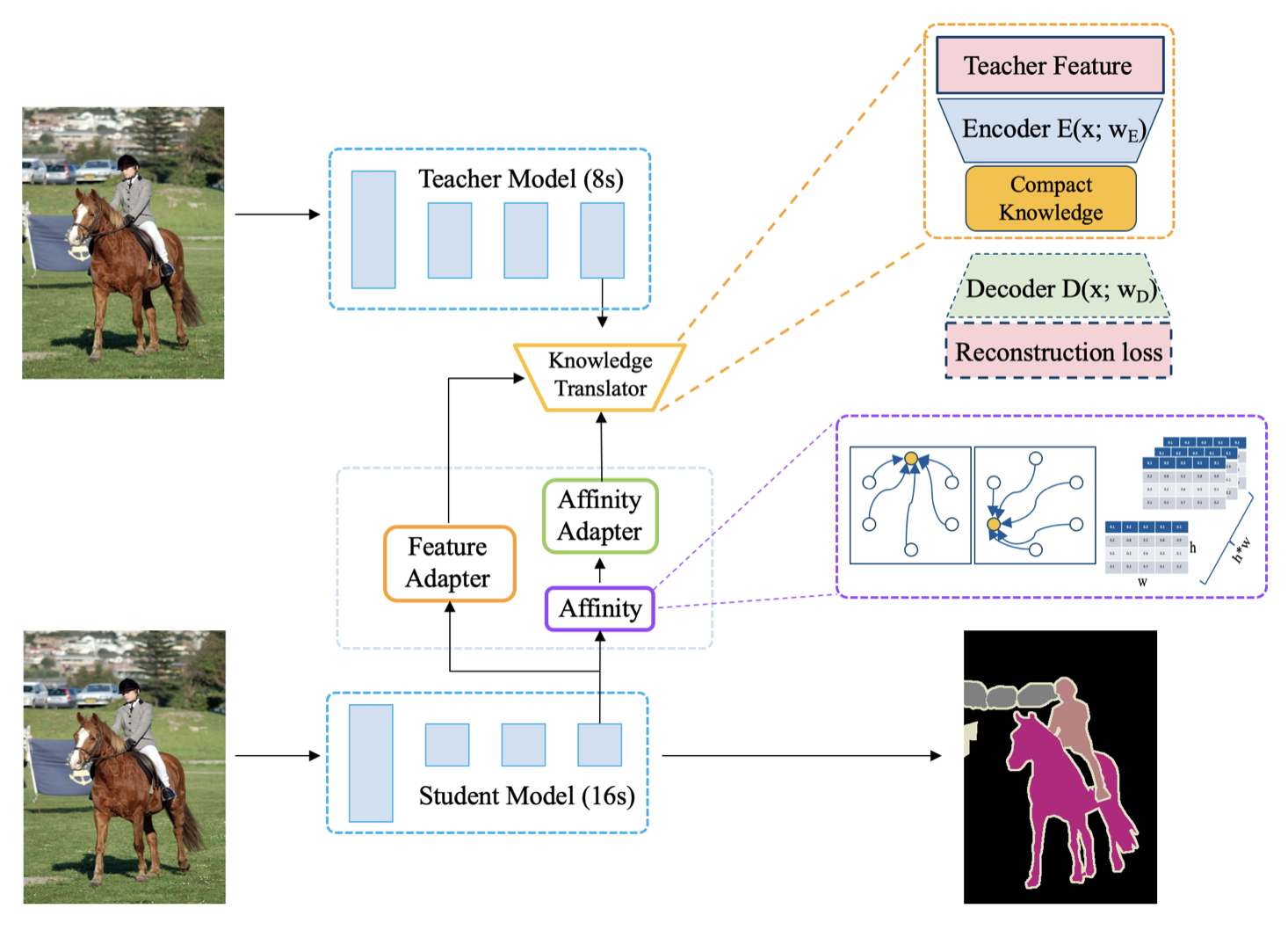
- Knowledge는 두 부분으로 정의:
- Teacher 네트워크의 지식을 compressed space로 변환해 정보 효율성 증대
- Teacher 네트워크의 long-range dependency 포착, 소규모 모델에서 제한된 receptive field와 abstraction 능력으로 학습 어려움 완화
3.1. Knowledge Translation and Adaptation
- Atrous convolution을 통한 FCN은 큰 receptive field를 유지하며 세부 정보 보존, 하지만 output stride 감소 시 계산 비용 기하급수적 증가, Figure 1 참조
- 고해상도 feature를 가진 대규모 teacher 모델을 활용해 저해상도 feature를 가진 경량 student 네트워크 학습
- Auto-encoder를 통해 입력 재구성, implicit structure 정보 추출 및 student 네트워크가 이해하기 쉬운 형식으로 knowledge 변환
- Low-level 및 middle-level feature는 모델 간 일반적이거나 네트워크 차이로 전달 어려움, high-level feature가 본 상황에 적합
- Auto-encoder는 teacher 모델의 마지막 convolution feature(Φt)를 입력으로 받아 3개의 strided convolution layer와 대칭적인 deconvolution layer로 구성
- Student 네트워크 S와 teacher 네트워크 T의 마지막 feature map은 각각 Φs와 Φt
- Auto-encoder 학습은 다음 reconstruction loss로 수행:
- 여기서 는 encoder, 는 decoder, 로 모든 실험에서 regularization loss 가중치 설정
- Auto-encoder 학습 시 identity function 학습 문제 방지를 위해 을 활용해 sparse representation 생성, weight와 re-represented space 모두 regularization
- Feature mismatching 및 네트워크 간 본질적 차이 영향을 줄이기 위해 convolution layer를 추가한 feature adapter 사용
- Pre-trained auto-encoder 기반 knowledge 전달은 다음 식으로 정의:
- 여기서 는 pre-trained auto-encoder, 는 모든 student-teacher 쌍의 인덱스, 는 3×3 kernel, stride 1, padding 1, BN layer, ReLU activation function을 포함한 student feature adapter, feature는 matching 전 normalization, 와 는 안정성을 위한 서로 다른 normalization 유형
3.2. Affinity Distillation Module
- Long-range dependency 포착은 semantic segmentation에 중요, 깊은 convolution layer와 큰 receptive field를 가진 네트워크에서 쉽게 학습 가능
- 소규모 네트워크는 제한된 abstraction 능력으로 long-range dependency 학습 어려움
- 대규모 teacher 모델에서 long-range, non-local dependency를 명시적으로 추출하는 새로운 affinity distillation module 제안
- Affinity는 spatial 거리에 상관없이 두 위치 간 상호작용을 직접 계산해 정의, 동일 레이블 픽셀은 높은 응답, 다른 레이블 픽셀은 낮은 응답 생성
- 마지막 layer의 feature map Φ는 크기 , affinity matrix 는 다음 식으로 계산:
- 여기서 A(Φ)는 spectral normalization 적용된 feature map Φ에 대응하는 affinity matrix, i, j는 vectorized Φ의 인덱스
- Teacher와 student 모델 간 affinity matrix 매칭은 다음 loss로 정의:여기서 는 teacher의 변환된 knowledge, 는 student affinity를 위한 adapter
- Affinity distillation module 효과는 Figure 3에 시각화, 임의 선택 지점과 다른 spatial 영역 간 응답 비교:
- Student 네트워크는 long-range dependency 포착 실패, 로컬 유사 패턴만 강조
- 제안 방법으로 long-range 및 global 정보 포착, robust decision 가능
3.3. Training Process
- 제안 방법은 teacher 네트워크와 student 네트워크로 구성
- Teacher 네트워크는 pre-trained 상태로, 학습 중 파라미터 고정
- Student 네트워크는 세 가지 loss로 학습:
- Ground truth 레이블과의 cross entropy loss
- Adaptation loss , 식 (2) 참조
- Affinity transferring loss , 식 (4) 참조
- 세 loss는 각각 가중치 , 로 조정
- , , 는 각각 encoder, decoder, student 모델의 파라미터
- 학습 과정은 두 단계로 구성:
- Stage 1: Teacher 네트워크의 knowledge 를 사용해 auto-encoder 학습,
- Stage 2: Pre-trained encoder 파라미터 를 사용해 student 네트워크 학습,
4. Experiments
Overview
- 데이터셋과 구현 세부 사항 소개, 제안 방법의 효과를 조사하기 위한 ablation study 수행
- Pascal VOC, Cityscapes, Pascal Context 벤치마크에서 경량 모델들과 성능 비교
4.1. Datasets
- Pascal VOC: 1,464개 학습 이미지, 1,449개 검증 이미지, 1,456개 테스트 이미지 포함, 20개 foreground 클래스와 1개 background 클래스, [9]에서 제공된 coarse labeling으로 데이터 증강, 성능은 21개 클래스에 대한 pixel intersection-over-union (mIOU) 평균으로 측정
- Cityscapes: 도시 거리 장면의 semantic 이해에 초점, 1024×2048 고해상도 이미지와 dense pixel-wise annotation 포함, 50개 도시에서 수집된 5,000개 finely annotated 이미지 (2,975개 학습, 500개 검증, 1,525개 테스트), 평가 프로토콜에 따라 30개 semantic 레이블 중 19개 사용
- Pascal Context: 총 10,103개 이미지 (4,998개 학습, 5,105개 검증), [18]에 따라 가장 빈번한 59개 클래스와 1개 background 클래스 평가
4.2. Implementation Details
- Baseline 모델: MobileNetV2 [21]는 계산 효율성과 FLOPS, 실제 latency, 파라미터 수 간 최적 trade-off로 주목, MobileNetV2-1.3 및 MobileNetV2-1.4는 각각 width multiplier 1.3, 1.4인 변형 모델, [21]의 mobile segmentation 모델은 DeepLabV3 [4]의 축소 형태 사용, 제안 방법은 추가 파라미터나 계산 오버헤드 없이 성능 크게 향상
- Teacher 네트워크 학습:
- ResNet-50 [10]과 Xception-41 [6]을 teacher 모델로 선택, atrous convolution과 atrous spatial pyramid pooling (ASPP)로 큰 feature map 생성
- Mini-batch SGD 사용: batch size 16 (최소 12), momentum 0.9, weight decay 4 × 10⁻⁵
- Poly learning rate 전략 (power 0.9), 초기 learning rate 0.007
- 데이터 증강: 이미지 무작위 뒤집기, scale jitter
- Pascal VOC: COCO 데이터셋에서 300K iteration 학습 후, trainaug 데이터셋 [9]에서 30K iteration 학습
- Cityscapes: COCO 사전 학습 없이, train-fine 데이터셋에서 90K iteration 학습, trainval 및 train-coarse로 fine-tuning 후 테스트 데이터셋 평가
- Pascal Context: COCO 사전 학습 없이, train set에서 30K iteration 학습, val set 평가
- Auto-encoder 학습:
- 1 epoch 내 학습 완료, learning rate 0.1, weight decay 10⁻⁴로 입력 포인트의 작은 부분에 낮은 에너지 부여
- 전체 시스템 학습:
- Teacher 네트워크 학습과 유사한 파라미터 사용, 단 student 네트워크는 ASPP와 decoder 제외 ([21]과 동일)
- Atrous convolution으로 저해상도 feature map 생성
- 학습 중 teacher 네트워크 파라미터 W_T와 auto-encoder 파라미터 W_E는 업데이트 없이 고정
4.3. Ablation Study
Knowledge Adaptation and Affinity Distillation Module
- 풍부한 spatial 정보를 활용하기 위해 teacher의 knowledge를 compact 형식으로 변환, student가 이를 모방하도록 설계
- Affinity distillation module은 소규모 student 모델의 제한된 receptive field 보완, 아래 Figure 3에서 long-range dependency와 context 포착 효과 시각화
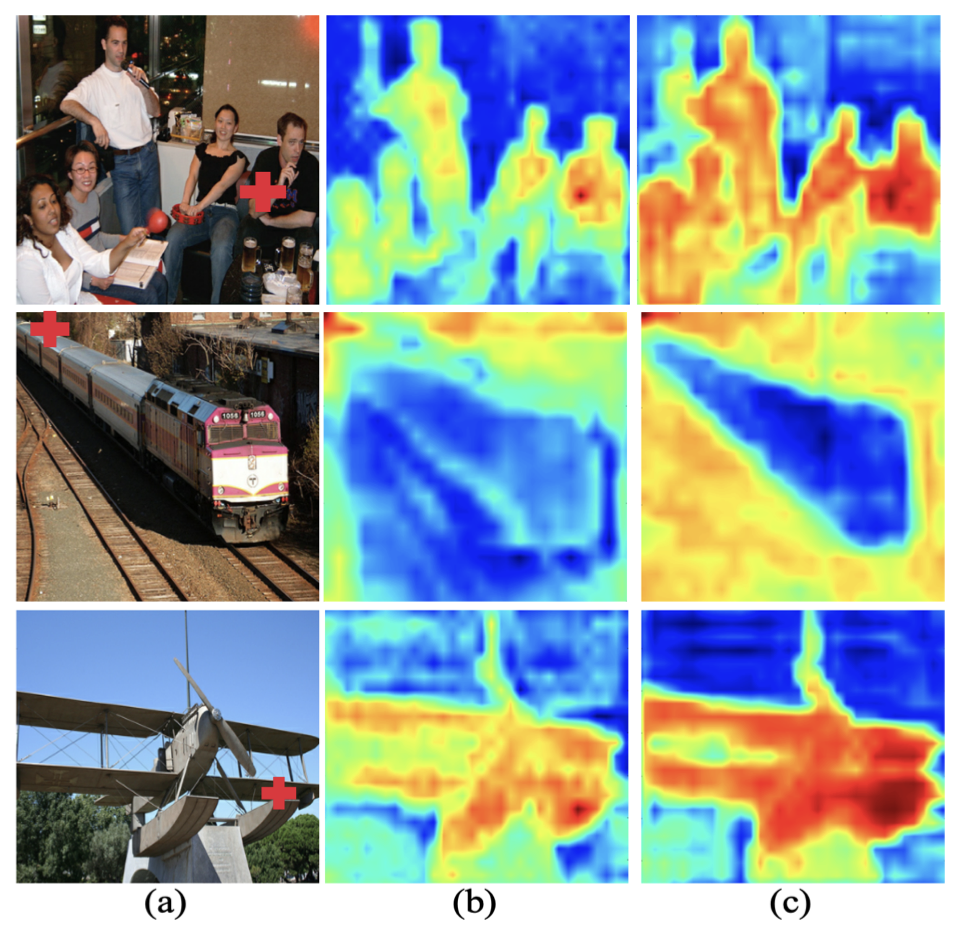
(a) Input Image: 입력 이미지, 임의로 선택된 지점은 빨간색 '+'로 표시
(b) Affinity Map (Without Affinity Distillation): Affinity distillation module 미적용 시 student 모델의 선택 지점에 대한 affinity map, long-range dependency 포착 부족
(c) Affinity Map (With Affinity Distillation): 제안된 affinity distillation module 적용 시 affinity map, long-range 및 global 정보 포착으로 향상된 응답 시각화
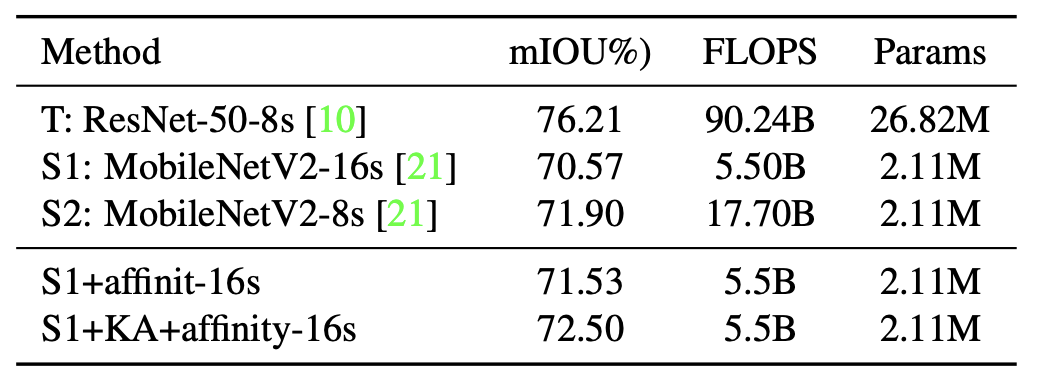
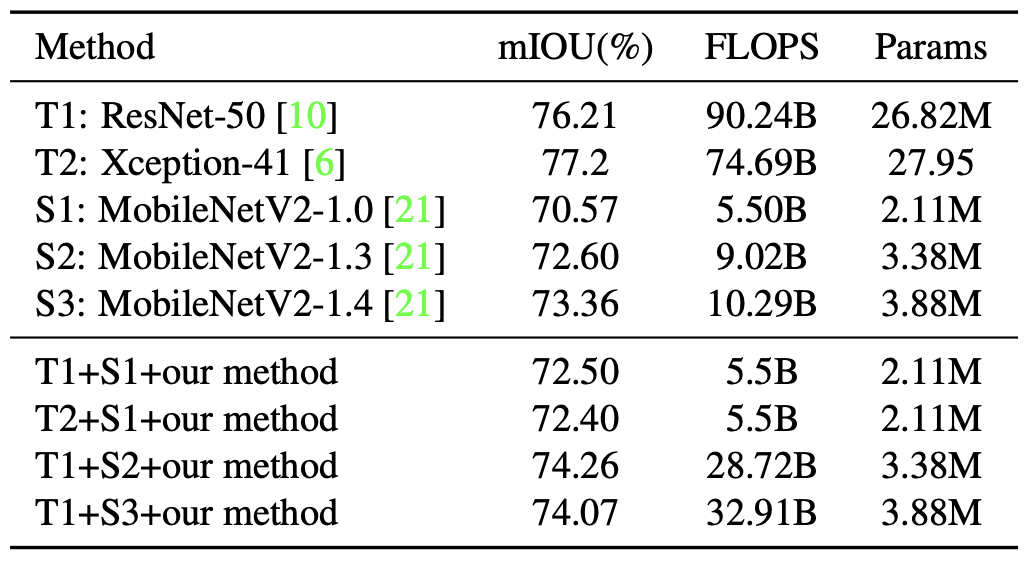
- Pascal VOC val set에서 single scale로 COCO 사전 학습 없이 mIOU로 성능 평가 (아래 Table 1):
- Affinity distillation module 적용 시 mIOU 70.57에서 71.53으로 향상
- Knowledge adaptation 추가 시 0.97 포인트 추가 향상
- Affinity matrix 불일치 문제 해결 위해 feature map을 동일 차원으로 resize, 단일 affinity module 효과 확인
- Output stride 16인 MobileNetV2가 31% FLOPS만 사용해 output stride 8인 MobileNetV2 성능 초과
- Figure 2에서 output stride 4인 baseline 대비 16s 모델이 8% FLOPS로 더 우수한 성능 달성, 추가 파라미터 없이 구현
Different Networks
- MobileNetV2는 width-multiplier로 정확도와 효율성 trade-off 조정 [21], 실험에서 width-multiplier 1.3, 1.4 사용, ImageNet 사전 학습 모델 활용
- ResNet-50 [10]과 Xception-41 [6] 등 서로 다른 네트워크 구조로 제안 방법 효과 검증 (아래 Table 2):
- MobileNetV2-1.0은 ResNet-50 지도 하에 1.93, Xception-41 지도 하에 1.83 mIOU 향상
- MobileNetV2-1.3과 MobileNetV2-1.4는 각각 1.66, 0.71 mIOU 향상
Other Knowledge Distillation Methods
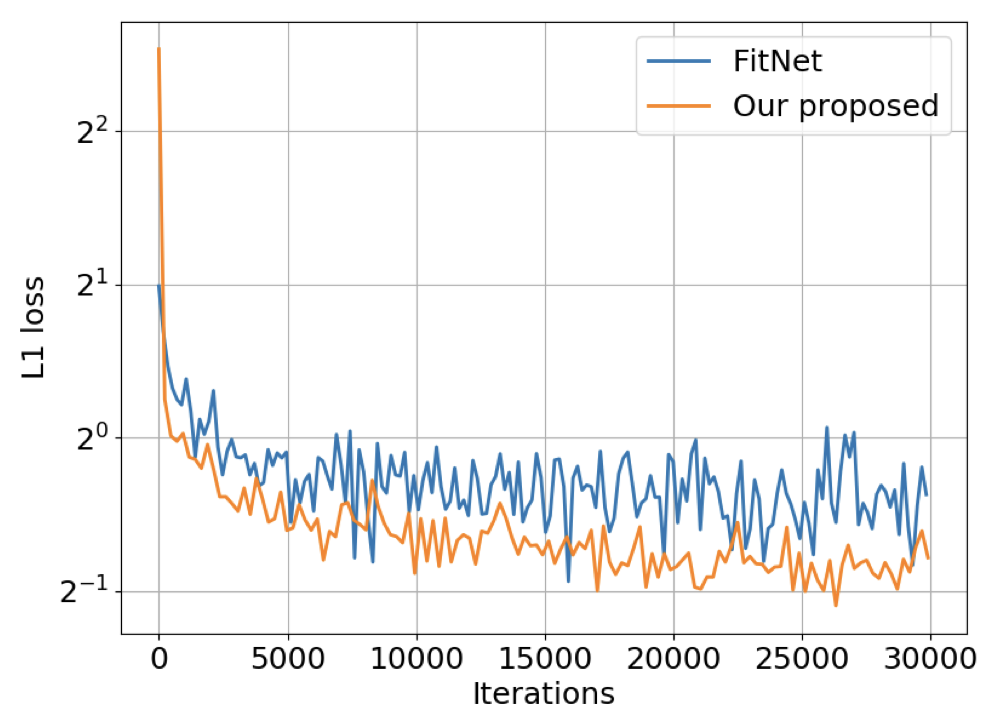
- Image-level classification용 KD [11]와 FitNet [20] 비교, KD는 teacher의 soft label을 knowledge로 정의, temperature (2, 4, 6)로 soften degree 조절
- 공정 비교 위해 logits map을 teacher 네트워크 크기로 bilinear upsampling, Pascal VOC val set에서 COCO 사전 학습 없이 평가
- FitNet은 intermediate representation 매칭 시도, 유사한 네트워크 설계 필요, 실험에서 마지막 layer feature map upsampling 후 loss 적용 (loss curve: 아래 Figure 5)
- 제안 방법은 teacher의 knowledge를 student가 학습하기 쉬운 형식으로 변환, Table 3에서 설정 변화에도 mIOU 변동 적고 KD 대비 우수
- FitNet 대비 1.2 포인트 향상, 네트워크 간 본질적 차이 완화
- 아래 Figure 4에서 affinity transfer module로 context 정보 포착
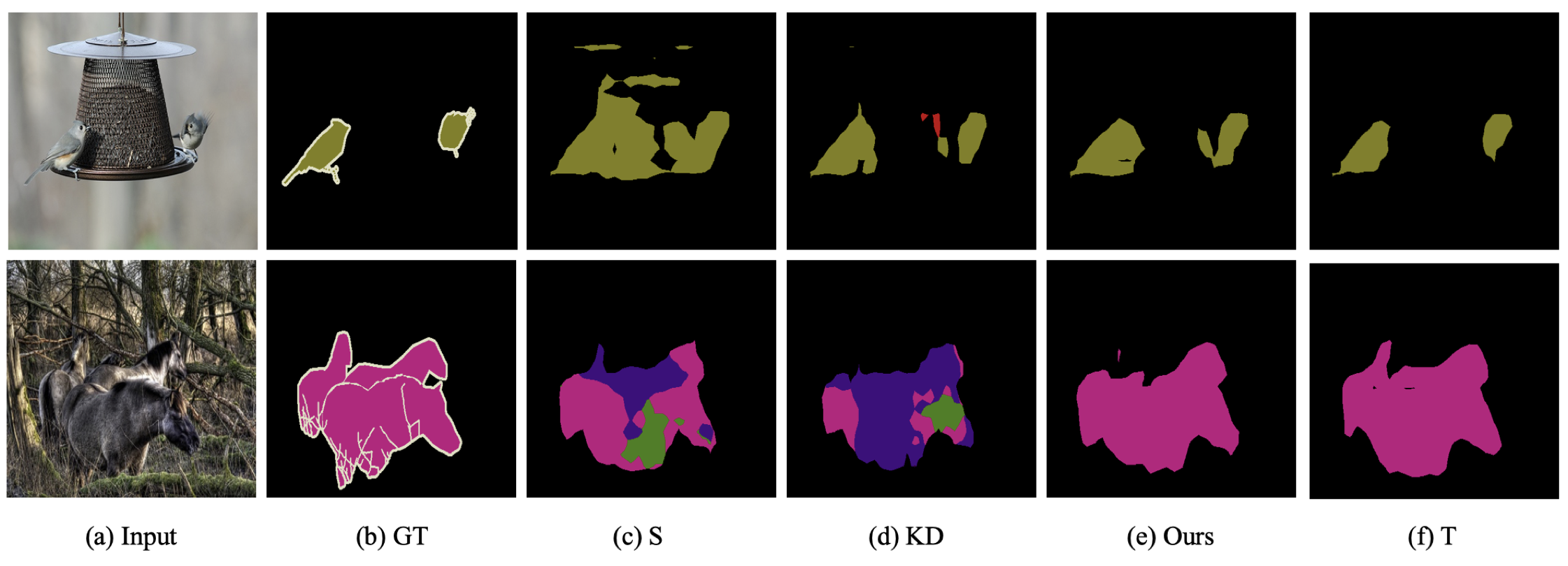
- 아래 Figure 6에서 knowledge translator와 adapter로 세부 정보 손실 감소 및 일관된 예측 시각적 확인
Comparison with Other Lightweight Models
- Pascal Context: Table 4, 제안 방법으로 baseline 1.3 포인트 향상
- Pascal VOC: Table 5, mIOU 75.8로 속도를 고려하지 않은 여러 방법보다 우수, MobileNetV2 baseline 대비 약 1 포인트 향상
- Cityscapes: Val set에서 mIOU 70.3, test set에서 72.7 달성, 경쟁력 있는 baseline에서 추가 파라미터나 계산 오버헤드 없이 각각 2.1, 2.5 포인트 향상 (Table 6)
6. Implementation Details
Knowledge Translator
- Auto-encoder는 3개의 2D convolution layer와 3개의 2D transposed convolution layer로 구성
- Encoder의 첫 번째 convolution layer와 decoder의 마지막 convolution layer의 stride는 2로 설정
- 6개 layer는 모두 3×3 kernel, padding 1, BN layer, ReLU activation function 사용
- 6개 convolution layer의 채널 수는 teacher 모델의 마지막 feature map 채널 수와 동일
Knowledge Adapter
- Adapter는 student 모델의 마지막 convolution feature 위에 적용
- 3개의 convolution layer로 구성, 각 layer는 3×3 kernel, stride 1, padding 1, BN layer, ReLU activation function 사용
- 3개 convolution layer의 feature map은 spatial resolution 유지, 채널 수는 teacher 모델의 마지막 layer feature 수로 조정
Training Process
- Teacher와 student 모델 학습은 각각 DeepLabV3+ [5]와 MobileNetV2 [21] 전략 따름
- Pascal VOC:
- Teacher와 student 네트워크를 COCO 데이터셋에서 500,000 iteration 학습
- Trainaug 데이터셋에서 30,000 iteration 추가 학습, val set에서 성능 검증
- Pascal Context:
- Train set에서 30,000 iteration 학습, val set에서 성능 평가
- Cityscapes:
- Train-fine 데이터셋에서 90,000 iteration 학습
- Trainval 및 train-coarse set에서 추가 90,000 iteration fine-tuning, test set에서 성능 평가
- COCO 데이터셋 사전 학습 사용 안 함
- 학습 설정: learning rate 0.007, total batch size 64
- 4개 GPU 사용, Pascal VOC와 Pascal Context는 crop size 513×513, Cityscapes는 769×769
7. Results Visualization
- Pascal VOC:
- MobileNetV2 [21] 기반 student 네트워크 사용, ASPP [5]와 decoder 제외
- 아래 Figure 7에서 제안 방법은 student 네트워크 및 [11] 결과보다 정확한 segmentation 결과 생성

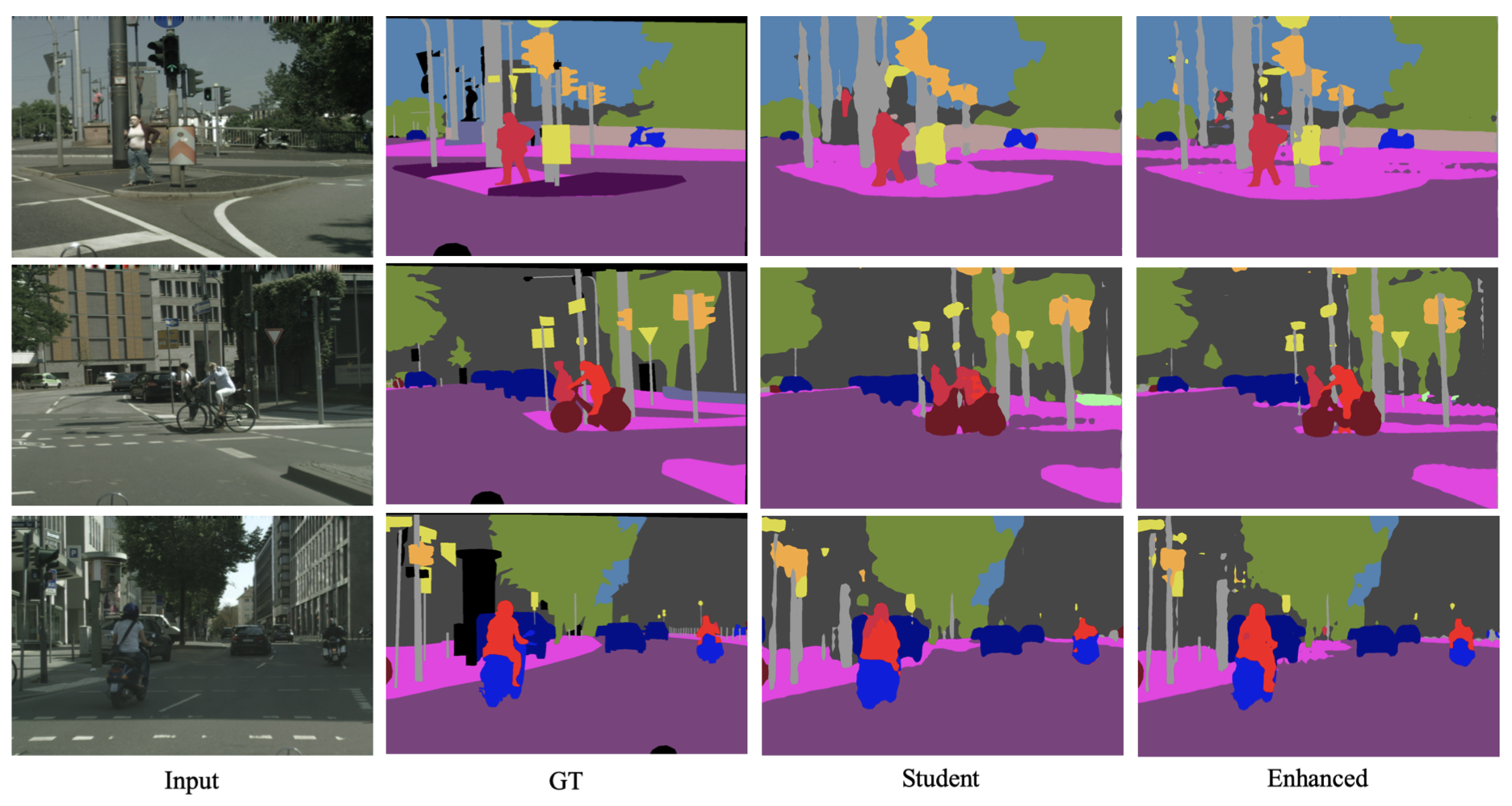
- Cityscapes:
- 아래 Figure 8에서 제안 방법의 추가 결과 시각화, 효과 입증

- 아래 Figure 8에서 제안 방법의 추가 결과 시각화, 효과 입증

AI Research Engineer