https://arxiv.org/abs/2411.14402
1. Introduction
Vision Models and Pre-training Evolution
- Specialist model에서 general-purpose model로
- Vision model pre-training은 특정 task에 최적화된 Specialist model에서 시작해 최소한의 조정으로 다양한 downstream task에 적용 가능한 general-purpose model로 발전
- Large Language Model(LLM)의 영향: LLM의 성공으로 Vision model 활용 패러다임 변화
- 기존 고정된 task 설정을 넘어 LLM은 pre-trained Vision model의 잠재력을 효과적으로 탐구
- Vision model pre-training 방법 재고찰 필요
Generative Pre-training in Vision
- Language modeling의 성공
- Generative pre-training은 Language modeling에서 주도적이며 뛰어난 성능과 scalability 제공
- Vision에서의 generative pre-training
- Computer vision에서 탐구되었으나 discriminative method에 비해 성능 뒤처짐
- LLM 유사 pre-training은 scalability 보여주나 동등 성능 위해 더 큰 모델 필요
- Contrastive learning의 한계
- Parameter 효율성이 높지만 대규모 batch size와 복잡한 학습 과정 요구
- Generative pre-training의 simplicity와 scalability를 discriminative method의 효율성과 결합한 접근법 필요
Main Contributions
- Multimodal Autoregressive Framework
- Image Patch와 Text Token을 통합된 Sequence로 처리하는 Autoregressive Pre-training 방법 제시: AIMv2
- Vision Encoder와 Multimodal Decoder로 Simplicity와 Scalability 유지
- Superior Performance
- Multimodal Understanding, Open-vocabulary Detection, Referring Expression Comprehension에서 State-of-the-art 성능
- ImageNet-1k에서 89.5% Accuracy 달성 (AIMV2-3B, frozen trunk)
- Efficient Training
- Dense supervision으로 Contrastive learning 대비 적은 데이터(12B vs. 40B)로 훈련
- Large batch size나 Complex inter-batch communication 불필요
- Flexible Adaptation
- High-resolution adaptation(336px, 448px) 및 Native resolution fine-tuning으로 다양한 Resolution과 Aspect ratio 지원
- Zero-shot Recognition(LiT tuning) 및 Multimodal in-context Learning 호환성 입증
2. Approach
2.1. Pre-training
- AIMv2는 전통적인 autoregressive 프레임워크를 확장하여 Image와 Text를 하나의 통합된 시퀀스로 처리하는 독창적인 접근법을 제시
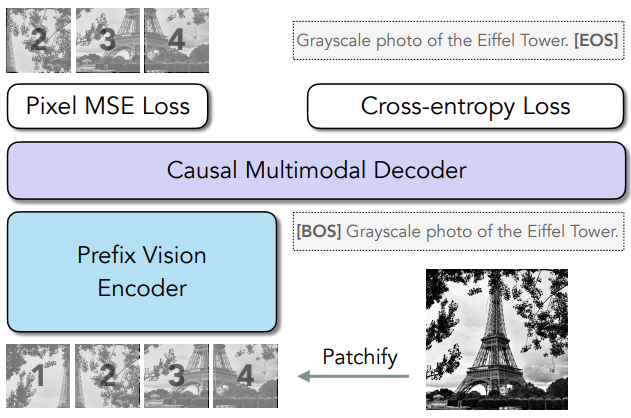
- 이 과정에서 Image는 중복이 없는 여러 Patch로 분할
- Text는 하위 단어 Token으로 세분화
- 특히, Image 시퀀스를 Text 시퀀스 앞에 배치하여 시각적 특징이 모델에 우선적으로 반영되도록 설계했으며, 이를 통해 시각적 조건을 강화하고 multi modal 학습의 효율성을 높임
- 이러한 구조는 모델이 Image와 Text 간의 상호작용을 자연스럽게 학습할 수 있는 기반을 마련
Objective function
-
Overall Loss:
- 전체 Loss 함수는 Text 예측 Loss()와 Image 예측 Loss()를 결합한 형태
- 모델 파라미터 를 조정하며 이를 최소화하는 목표를 둠
- 여기서 는 두 Loss 간의 균형을 조절하는 가중치로, 실험적으로 최적화
-
Image Patch 예측을 위한 Regressive Loss:
- 모델이 예측한 Image Patch 와 실제 Image Patch 간의 제곱 오차를 계산하여 평균화
- Norm을 사용해 Pixel 단위의 정밀한 Regression 성능을 보장하며, 는 전체 Image Patch 수를 나타냄
- 이는 모델이 시각적 세부 사항을 정확히 재구성하도록 유도
-
Text Token 예측을 위한 Cross-Entropy Loss:
- Text Token 예측에 사용되는 이 loss 함수는 cross-entropy 방식을 채택하여, 이전 Token 시퀀스 를 기반으로 다음 Token 의 확률 분포(; )를 평가
- 는 Text Token 수를 의미
2.2. Architecture
Vision Encoder:
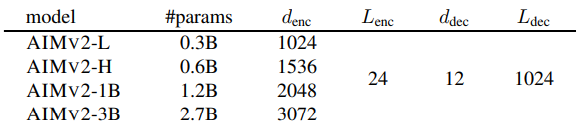
- AIMv2의 Vision Encoder는 Vision Transformer (ViT) 구조를 채택
- 300M에서 3B 파라미터까지 다양한 크기의 Vision Encoder를 학습했으며, 세부 사양은 아래 Table에 표기
Prefix Attention:
- El-Nouby의 접근법에 따라 Vision Encoder의 Self-attention 메커니즘에 Prefix attention mask를 적용
- 이는 추가 Fine-tuning 없이 추론 시 Bidirectional attention을 가능하게 함
- Prefix 길이 은 다음 분포에서 Random 선택:
- Pixel loss는 prefix가 아닌 Patch에 대해서만 계산
SwiGLU와 RMSNorm:
- Vision Encoder와 Multi-modal Decoder는 SwiGLU를 feedforward network (FFN)으로 사용
- 모든 정규화 Layer를 RMSNorm으로 대체하며, 이는 언어 모델링에서 입증된 SwiGLU와 RMSNorm의 효과를 활용
Multimodal Decoder:
- 통합 Multi-modal Decoder는 Image와 Text Modal을 동시에 Autoregressive 방식으로 생성
- 아키텍처에는 별도의 Text 인코더가 없지만, Causal Multimodal Decoder가 Image patch와 Text Token을 통합된 시퀀스로 처리
- Vision encoder에서 추출된 Image feature와 Text의 Embedding이 Concatenation되어 Multimodal Decoder로 입력
- 여기서 Text Embedding은 사전 학습된 Token Embedding 테이블(예: Vocabulary Embedding)에서 가져옴
- 예를 들어, "[BOS] Grayscale photo of the Eiffel Tower [EOS]"는 각 Token에 해당하는 Embedding 벡터로 변환된 후, Image Feature와 결합
- *BOS(Beginning of Sequence)
- *EOS(End of Sequence)
- 예를 들어, "[BOS] Grayscale photo of the Eiffel Tower [EOS]"는 각 Token에 해당하는 Embedding 벡터로 변환된 후, Image Feature와 결합
- Image 특징과 원시 Text Token은 각각 Linear projection 및 Embedding 되어 동일한 차원으로 변환
- Decoder는 Image와 Text 특징의 연결된 시퀀스를 처리하며, Self-attention 연산에서 Causal attention을 사용
- 출력은 Image Token과 Text Token을 각각 예측하는 두 개의 별도 Linear head로 처리
- 모든 AIMv2 변형에 동일한 Decoder Capacity 적용
Optimization Hyperparameters:
- 모든 AIMv2 모델의 사전 학습에 사용된 최적화 하이퍼파라미터는 Table A1에 표기
2.3. Data
Dataset:
- AIMv2 모델은 Image-Text 쌍이 포함된 Open 및 Closed 데이터셋을 결합해 사전 학습
- Open dataset
- DFN-2B, COYO
- Closed dataset
- Apple의 독점 데이터 High Quality Image-Text Pairs (HQITP)
- Alt-text 외에 Lai의 방법을 따라 합성 캡션 사용
- 데이터셋 크기와 각 데이터셋의 Sampling 확률은 아래 Table에 표기
- 기본적으로 120억 개의 Image-Text 샘플로 사전 학습

2.4. Post-Training
Post-training Overview:
- 초기 사전 학습으로 높은 성능의 모델을 얻었으나, 다양한 Post-training을 통해 추가 성능 향상
High-resolution Adaptation:
- 초기 사전 학습은 224px 고정 해상도로 진행
- Detection, Segmentation, multi-modal LLM과 같은 하위 작업은 더 높은 해상도(336px, 448px)가 유리
- 이를 위해 20억 개의 Image-Text 쌍(합성 캡션 제외) 사용해 Fine-tuning
Native Resolution Fine-tuning:
- 고정 해상도와 종횡비로 학습하면 원본 형태의 Image를 처리하는 데 제약 따름
- FlexiViT와 NaViT 같은 기존 연구 참고했으나, AIMv2는 다른 방법 채택
- 미니배치에서 Image 수, Image당 Patch 수, 총 Patch 수 정의
- Random 하게 면적을 Sampling 하고, 종횡비 유지하며 Image를 조정
- 면적은 로 설정하며, [-1, 1] 범위의 절단된 정규 분포에서 값 을 Sampling하고 [7, 12]로 매핑 -> 128~4096
- Sampling 된 면적 에 맞춰 Image 크기를 조정하되, 원본 Image의 종횡비는 그대로 유지한 채 모델에 입력
- 예를 들어, 원본 Image가 800x600px라면, 면적 에 따라 크기를 조정하더라도 4:3 비율은 유지
- Image 수는 총 Patch 수가 일정하도록 동적으로 조정
- 예: 고해상도 Image는 더 많은 패치를 생성하므로, 배치 내 Image 수를 줄여 총 Patch 수를 일정하게 유지
- 이는 Sequence packing, Attention masking, Custom pooling 같은 복잡한 기술 없이 유연한 학습 가능
3. Analysis
- AIMv2의 주요 장점 중 하나는 구현과 확장이 용이한 단순성에 있음
- 본 섹션에서는 AIMv2 모델군의 스케일링 특성을 분석하여 데이터 크기와 모델 Capacity이 성능에 미치는 영향을 조사
3.1. Scaling AIMv2
- AIMv2의 스케일링 효과를 평가하기 위해, 데이터 크기와 모델 Capacity를 변화시키며 검증 성능에 미치는 영향을 분석
실험 설정:
- 3억에서 30억 파라미터에 이르는 네 가지 모델 Capacity를 학습
- 사전 학습 중 접한 Image-Text 쌍의 수를 5억에서 64억으로 변화
- 모든 모델은 조기 종료 없이 수렴할 때까지 학습. 계산 비용을 최소화하기 위해, 각 Capacity별로 50억 Image를 사용해 단일 모델을 학습하며, half-cosine Learning rate Schedule(최종 Learning rate는 최대 Learning rate의 절반)을 적용
- 이 과정에서 7개의 중간 체크포인트를 선택하고, Learning rate을 으로 선형적으로 감소(cooldown). Cooldown 단계의 기간은 초기 사전 학습 단계의 20%로 설정
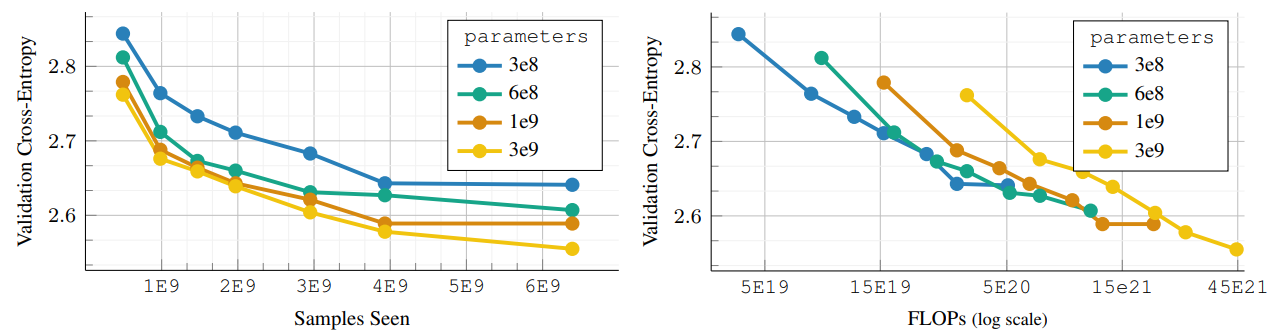
실험 결과:
- AIMv2의 스케일링 특성은 모델의 효율성을 입증
- 좌측 그래프는 파라미터 수 증가가 표현력을 높여 일반화 성능을 개선함을 보여주며, AIMv2의 Autoregressive 구조가 대규모로 일 때도 안정적임을 나타냄
- 우측 그래프는 계산 자원의 중요성을 강조하며, Large Capacity 모델이 충분한 자원 없이는 과소 학습되지만, 자원이 늘어나면 Small Capacity 모델을 능가함을 보여줌
- 이는 Hoffmann의 언어 모델 연구와 일치
3.2. AIMv2 vs. Captioning
- AIMv2 사전 학습에서 Image 수준의 Autoregressive objective의 역할을 조사
- Multi-modal autoregressive 목표로 학습된 모델과 언어 감독만으로 학습된 모델의 성능을 비교
실험 설정:
- 특별히 명시되지 않는 한, ViT-H 백본과 20억 개의 Image-Text 쌍을 사용해 사전 학습
모든 모델은 Cosine learning rate schedule로 수렴할 때까지 학습 - 고정된 트렁크(Frozen trunk)를 사용한 Attentive probe 후 IN-1k top-1 정확도를 측정
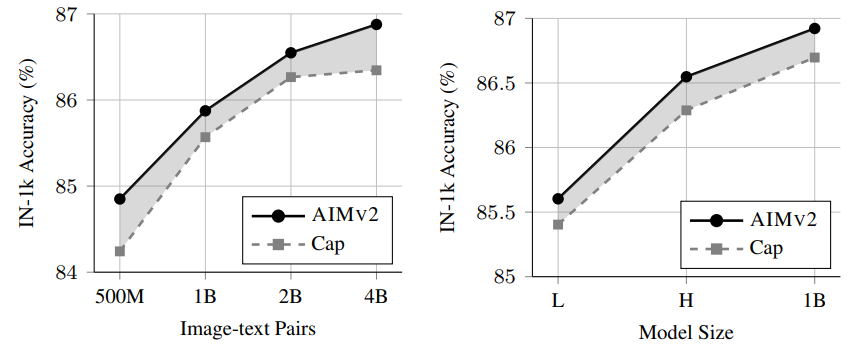
실험 결과:
- AIMv2의 Image-level objective와 Captioning baseline을 비교한 결과
- AIMv2는 모든 데이터셋 및 모델 크기에서 Captioning baseline을 지속적으로 능가하며, 데이터 스케일링 시 성능 포화 징후가 적음
- Captioning baseline?
- Image Captioning에 특화된 Pre-training 모델로, Text 예측에만 초점을 맞춤
- AIMv2와 비교해 Image patch reconstruction objective가 없어 데이터 스케일링 시 성능 포화 경향
- ViT-H backbone, 2B image-text pair로 학습, AIMv2보다 ImageNet-1k accuracy에서 낮음
4. Results
- AIMv2는 Recognition, 탐지, Captioning, multi-modal 벤치마크 등 다양한 하위 작업에 적용 가능한 범용 Vision Encoder로 평가
Attentive Probing:
- Attentive Probing?
- 사전 학습된 Vision Encoder의 표현력(representation quality)을 평가하기 위한 방법으로, 모델이 다양한 다운스트림 작업(downstream tasks, 예: 이미지 분류, 객체 탐지 등)에 얼마나 잘 일반화되는지를 측정
- Frozen Trunk: 사전 학습된 Vision Encoder의 파라미터는 고정(freeze)된 상태로 유지되며, 추가 학습이나 fine-tuning 없이 평가
- Attentive Mechanism: 단순한 Linear classifier 대신, Attention 메커니즘을 포함한 Probing 레이어를 추가하여 모델의 특징을 더 효과적으로 활용
- AIMv2는 MAE, AIM 보다 Small Capacity으로도 우수하며, DINOv2를 IN-1k, Food101, DTD, Cars, Infographic에서 능가
- ViT-Large AIMv2는 OAI CLIP, DFN-CLIP, SigLIP보다 적은 데이터(12B vs. 40B)로 IN-1k 등에서 경쟁력 있음
- 448px Fine-tuning 된 AIMv2-3B는 IN-1k에서 89.5% top-1 정확도 달성
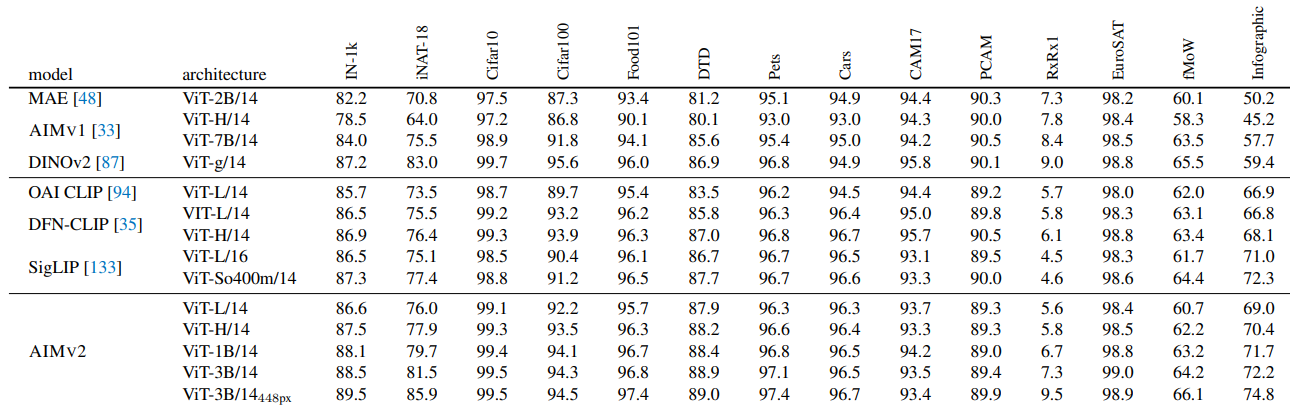
Zero-shot (LiT Tuning):
- AIMv2는 Captioning 기준선 및 OAI CLIP을 제로샷 IN-1k에서 능가하나, SigLIP에는 뒤짐

Native Resolution:
- AIMv2-L native는 다양한 해상도에서 강력한 성능을 제공하며, IN-1k 원본 해상도에서 87.3% 정확도 달성
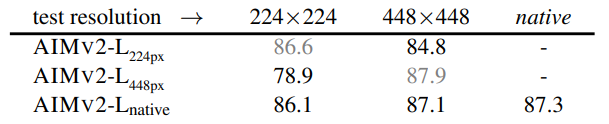
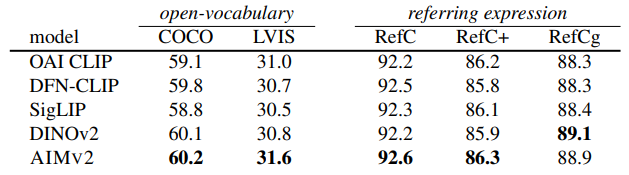
Object Detection and Grounding:
- AIMv2는 오픈 어휘 탐지(COCO, LVIS)와 참조 표현 이해(RefCOCO, RefCOCO+, RefCOCOg)에서 DINOv2 및 Vision-언어 모델을 대부분 능가, 특히 LVIS에서 강력
Review
- AIMv2는 적은 데이터로도 높은 성능을 달성하며, 단순한 Autoregressive 구조의 효율성과 확장성을 입증
- Attentive probing 결과는 AIMv2가 다양한 Recognition 작업에서 경쟁력 있는 범용성을 보여주며, 특히 고해상도 Fine-tuning으로 성능이 극대화됨을 나타냄
- 제로샷 성능은 Multi-modal 학습의 잠재력을 확인시키며, Native resolution 지원은 실제 환경에서의 유연성을 보장
- 탐지 및 Grounding 결과는 AIMv2가 Vision-언어 통합 작업에서도 강력한 일반화 능력을 가짐을 시사하며, 특히 LVIS와 같은 복잡한 데이터셋에서 두드러진 성능을 발휘
7. Conclusion
- 본 논문은 Image Patch와 Text Token을 재구성하는 Multi-modal Autoregressive 목표로 사전 학습된 Vision Encoder군인 AIMv2를 제안
- 이 통합된 목표는 AIMv2가 Image Recognition, Grounding, Multi-modal Understanding 등 다양한 작업에서 탁월한 성능을 발휘
- AIMv2의 우수한 성능은 모든 입력 Token과 Patch로부터 신호를 활용하여, 다른 방법에 비해 적은 샘플로 효율적인 학습을 가능케 하는 능력에 기인
- AIMv2는 기존 자가 감독 및 Vision-언어 사전 학습 모델을 지속적으로 능가하거나 동등한 성능을 보이며, Vision Encoder로서의 강력함과 다재다능함을 입증

AI Research Engineer