https://arxiv.org/abs/2507.02798
1. Introduction
Semantic Segmentation의 annotation 문제와 promptable segmentation
- Segmentation task를 위한 대규모 annotation 수집은 비용이 많이 들고 시간이 오래 걸리는 과정임
- Segment Anything Model (SAM)을 포함한 최근 promptable segmentation framework는 point, box, sketch와 같은 간단한 geometric prompt를 사용해 고품질 mask 생성을 가능하게 하여 수작업 노력을 크게 줄임
- 그러나 이러한 mask는 semantic awareness가 부족하며, autonomous 작동을 위해 manual intervention이나 복잡한 domain-specific prompt-generation pipeline이 필요
- Manual prompt는 대규모 데이터셋이나 자동 처리가 필요한 시나리오에서 scalability를 제한하며, domain-specific pipeline은 cross-domain generalization을 저해
Reference-based instance segmentation의 가능성과 한계
- Reference-based instance segmentation은 소수의 annotated reference image를 활용해 대량의 target image를 segmentation하는 유망한 해결책
- 이는 annotation이 비용이 많이 들고 시간이 오래 걸리며 전문 지식이 필요한 데이터셋에 대해 저렴하고 빠른 자동 annotation을 가능하게 함
- Reference image는 예시로부터 직접 semantic understanding을 통합하여 automated segmentation task에 적합
- 그러나 기존 방법은 novel class에 대한 fine-tuning이 필요하며, 이는 task-specific data 요구, overfitting, domain shift와 같은 문제를 초래
- Vision foundation model의 general-purpose capability를 재사용하는 접근이 대안으로 제안됨
기존 접근의 한계
- Matcher와 같은 기존 연구는 DINOv2와 SAM을 통합해 semantic segmentation을 수행하나, 몇 가지 한계 존재
- Computationally expensive distance metric (예: Earth Mover’s Distance)과 복잡한 thresholding mechanism으로 인해 inference 속도가 느림
- Instance-level segmentation에 적합하지 않아 복잡한 multi-object scene에서 fine-grained discrimination이 어려움
- Instance segmentation은 occlusion, scale variation, ambiguous object boundary, 다양한 image quality 등 고유한 도전 과제를 가지며, 이는 소수의 reference image만으로 해결해야 함
- Semantic ViT backbone (예: DINOv2)의 generalization capability를 활용해 precise localization을 달성하는 것은 fine-tuning 없이 큰 도전 과제
제안 방법의 개요
- Training-free three-stage method 제안:
- Category-specific feature로 구성된 memory bank 구축
- Two-step aggregation을 통해 feature representation 정제
- Feature matching과 novel semantic-aware soft merging strategy를 통한 inference 수행
- 이 framework는 training 없이 고성능을 달성하며, 고정된 hyperparameter로 다양한 domain에서 효과 유지
- COCO-FSOD, PASCAL-FSOD, CD-FSOD benchmark에서 state-of-the-art 성능을 달성하며, intermediate fine-tuning 없이 강력한 generalization 능력 입증
Main Contribution
- Semantic-agnostic segmentation mask proposal과 fine-grained semantics를 효과적으로 통합하는 training-free 방법 제안
- Vision foundation model을 활용한 instance segmentation을 위한 novel three-stage framework 도입:
- Memory bank 구축
- Two-step feature aggregation
- Semantic-aware soft merging을 포함한 feature matching
- COCO-FSOD, PASCAL-FSOD, CD-FSOD benchmark에서 state-of-the-art 성능 달성, 고정된 hyperparameter로 다양한 데이터셋에서 강력한 generalization 입증
2. Related Work
Reference-based instance segmentation
- Reference-based instance segmentation은 동일 카테고리 내 개별 객체를 구분하며 이미지 내 객체를 분할하는 것을 목표로 함
- 전통적 접근법인 Mask R-CNN은 region proposal과 convolutional network를 사용해 instance mask를 예측하며, DETR, Mask2Former와 같은 transformer 기반 모델은 self-attention mechanism을 통해 global context를 통합
- 이러한 방법은 대규모 labeled dataset을 활용해 standard instance segmentation task에서 성공을 거둠
- Reference-based instance segmentation은 소수의 labeled example로 novel category를 처리하도록 확장
- 초기 연구는 instance-level discriminative feature 도입 또는 uncertainty-guided bounding box 예측을 통해 Mask R-CNN을 조정
- 최근 연구는 in-context learning framework로 segmentation task를 통합하며, 광범위한 segmentation task에 대한 고비용 pretraining 수행
- 그러나 labeled data 부족, multi-instance scenario의 복잡성, specialist model의 cross-domain generalization 제한, reference image의 모호성, predefined class label 의존성 등으로 인해 여전히 도전 과제 존재
- Frozen backbone을 instance segmentation에 재사용하는 것도 pretrained 목적이 달라 어려움 지속
- 본 연구는 reference-based instance segmentation을 위해 두 개의 frozen vision foundation model을 활용, 추가 training 없이 효과적으로 작동하며 비정형 domain에서도 강력한 generalization 달성
Vision foundation model
- Vision foundation model은 강력한 pretrained representation을 학습해 다양한 task에 transfer 가능
- CLIP은 contrastive learning으로 visual 및 textual representation을 정렬, DINO는 unlabeled data에서 robust image embedding 학습
- 이들 모델은 open-vocabulary detection, semantic segmentation 등 downstream task에 널리 채택
- 그러나 CLIP은 detailed spatial reasoning에 한계, DINOv2는 fine-grained semantics를 포착하나 low-resolution feature map 생성
- Segment Anything Model (SAM, SAM2)은 category-agnostic dataset (SA-1B)으로 학습, 최소 입력(point, bounding box)으로 segmentation mask 생성에 탁월
- 하지만 SAM은 inherent semantic understanding 부족
- 이를 해결하기 위해 SAM을 language model, diffusion model, 또는 COCO, ADE20K와 같은 labeled dataset으로 fine-tuning하는 시도 존재
- 그러나 이는 복잡한 pipeline이나 scalability 제한으로 이어짐
- SAM의 semantic-agnostic 특성은 instance-level class differentiation이 필요한 시나리오에서 한계
- 본 연구는 DINOv2와 SAM의 상호보완적 강점을 결합, fine-tuning 없이 high-precision, training-free instance segmentation을 가능하게 하며, few-shot benchmark에서 state-of-the-art 결과 달성
Automatic vision prompting for SAM
- Automatic prompting pipeline은 SAM의 복잡한 visual task에서의 versatility를 향상, manual input 의존성 감소 목표
- Training-free 방법은 feature-matching 기법을 활용하나, manually tuned threshold, distance metric, 복잡한 pipeline에 의존
- Spatial 또는 semantic optimisation을 통해 prompt를 직접 학습하는 접근도 multi-instance 또는 semantically dense 설정에서 도전 과제 직면
- Zero-shot 방법은 visual marker를 사용해 segmentation 중 attention을 유도하나, fine-grained precision 부족
- SEEM은 shared decoder를 통해 segmentation과 recognition task를 통합, SINE은 task ambiguity를 해소하며 segmentation task 분리
- SAM과 Stable Diffusion을 결합한 open-vocabulary segmentation, LISA의 text-guided task 적응 등 최근 노력 존재
- 그러나 multi-instance scenario와 semantic ambiguity를 training 없이 처리하는 것은 여전히 어려움
- 본 연구는 SAM과 DINOv2를 추가 training이나 prompt optimisation 없이 통합
- Multi-stage 방법(memory bank 구축, representation aggregation, semantic-aware feature matching)을 고정된 hyperparameter로 구현, 다양한 downstream application에 실용적이며 practitioner가 쉽게 접근 가능
3. Method
3.1. Preliminaries
- Segment Anything Model (SAM): Promptable segmentation을 위해 설계된 모델로, 다양한 geometric prompt에 반응해 image segmentation mask를 생성. 주요 구성 요소는 다음과 같음:
- Image encoder: High-resolution 입력에 적응한 pretrained Vision Transformer (ViT)
- Prompt encoder: Sparse prompt (point, box, text)와 dense prompt (rough mask)를 처리, positional encoding, learnt embedding, off-the-shelf text encoder 활용
- Mask decoder: Modified Transformer decoder block을 사용해 self-attention과 cross-attention으로 효율적 mask 생성
- 학습은 focal loss와 dice loss 조합 사용
- DINOv2: Self-supervised learning 기반 vision model로, general-purpose visual feature 생성
- Vision Transformer (ViT) 아키텍처 기반 discriminative self-supervised learning 적용
- Teacher-student network, Sinkhorn-Knopp normalisation, multi-crops 전략, image-level 및 patch-level objective를 위한 별도 projection head, 추가 regularization 기법 활용
- 142M 이미지로 구성된 LVD-142M 데이터셋에서 효율적 학습 기법(fast memory-efficient attention, stochastic depth 등)으로 학습
- Feature는 다양한 task와 domain에 transfer 가능, global 및 local visual understanding에 강력한 backbone 제공
- Reference-based instance segmentation: Reference segmented image를 예시로 사용해 target image를 분할. 공식적으로, reference image 와 해당 annotation (여기서 는 object category)를 사용해 target image 에서 동일 category 에 속하는 영역을 분할
3.2. Training-free method
- 목표: Annotated reference example에서 category-specific feature를 추출해 target image에서 instance를 분할 및 분류
- Model retraining이 필요한 방법과 달리, discriminative representation을 저장하는 memory-based 접근법 사용
- 세 단계로 구성: (1) Reference image에서 memory bank 구축, (2) Two-stage feature aggregation으로 representation 정제, (3) Feature matching과 semantic-aware soft merging을 통한 target image inference. 전체 pipeline은 아래 그림 참고
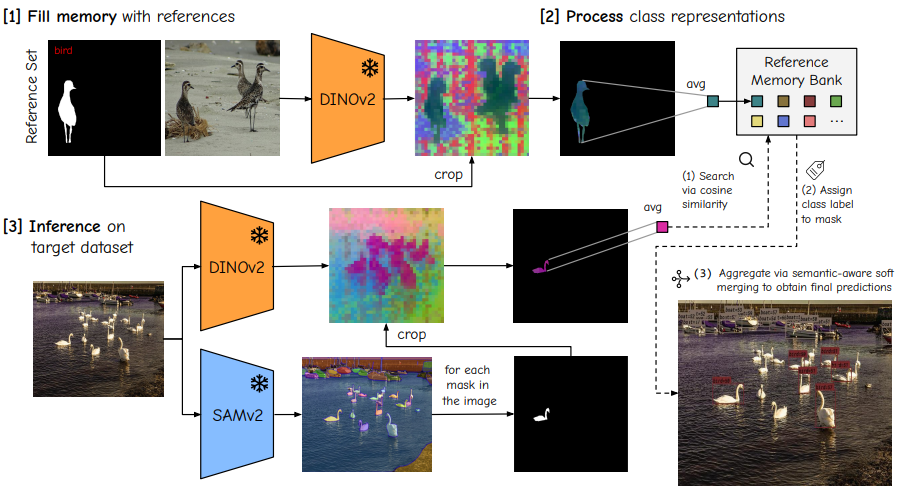
(1) Memory Bank 구축
- Reference image 집합 와 해당 instance mask (category )가 주어짐
- Pretrained frozen encoder 을 사용해 dense feature map 추출 (: feature dimension, : feature map의 spatial resolution)
- Instance mask 는 feature map resolution에 맞게 resize
- 각 category 에 대해 masked feature 저장:여기서 는 element-wise multiplication
- Category-wise feature set은 memory bank 에 저장, distributed setting에서 GPU 간 일관성 보장을 위해 동기화
(2) Two-stage feature aggregation
- Category prototype 구축을 위해 instance-wise feature representation을 계산 후 class-wise prototype으로 집계
- (a) Instance-wise prototype:
- Reference image 의 각 instance 에 대해, 해당 mask 내 feature embedding 평균 계산:여기서 는 image 의 -번째 instance의 평균 feature representation
- Reference image 의 각 instance 에 대해, 해당 mask 내 feature embedding 평균 계산:
- (b) Class-wise prototype:
- 동일 category 에 속하는 모든 instance-wise prototype을 평균 내어 category prototype 계산:여기서 는 image 에서 category 에 속하는 instance 집합, 는 category 의 총 instance 수
- Class-wise prototype 는 memory bank에 저장
- 동일 category 에 속하는 모든 instance-wise prototype을 평균 내어 category prototype 계산:
- (a) Instance-wise prototype:
(3) Target image inference
- Target image 에서 동일 encoder 로 dense feature 추출
- Frozen SAM model로 개 candidate instance mask () 생성
- 각 mask 에 대해 average pooling과 L2 normalization으로 feature representation 계산:여기서 는 normalized mask feature
- (a) Feature matching:
- 과 category prototype 간 cosine similarity 계산:이는 mask 의 classification score 제공
- 과 category prototype 간 cosine similarity 계산:
- (b) Semantic-aware soft merging:
- Overlapping prediction 처리 위해 novel soft merging strategy 도입
- 동일 category의 두 mask , 에 대해 intersection-over-self (IoS) 계산:
- Feature similarity로 가중치 계산:
- 각 mask의 최종 score는 decay factor로 조정:이를 통해 redundant detection 감소, 부분적 overlap이 있는 distinct instance 보존
- Adjusted score로 mask를 ranking, top-K 예측을 최종 출력으로 선택
3.3. Technical implementation details
- SAM2-L (Hierarchical ViT)를 mask 생성에, DINOv2-L을 feature encoder로 사용.
- Encoder는 518×518 resolution, 14×14 patch size로 이미지 처리, SAM2는 1024×1024 resolution으로 작동
- Inference 중 SAM2는 32×32 grid의 query point로 candidate mask 생성
- 각 mask에 대해 masked region 내 encoder feature를 average pooling 및 L2 normalization으로 계산
- Memory bank는 category당 개 reference image의 feature 저장.
- IoU threshold 0.5로 non-maximum suppression 적용 후, semantic-aware soft merging strategy로 overlapping prediction 처리
- 이미지당 최대 100개 instance 출력
- PyTorch와 PyTorch Lightning을 사용해 GPU 간 distributed workload 구현
4. Results
4.1. Object Detection 및 Instance Segmentation
- 본 training-free 방법은 segmentation mask를 출력하나, 기존 방법과의 공정 비교를 위해 instance mask를 bounding box로 변환
COCO-FSOD Benchmark
- COCO-20i 데이터셋에서 strict few-shot setting (10-shot 및 30-shot)으로 평가
- 결과는 아래 테이블에 제시, COCO-NOVEL 클래스 (PASCAL VOC과 교차하는 COCO 카테고리)에 대해 비교
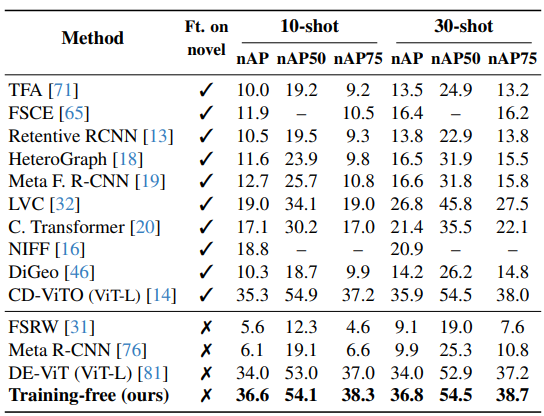
- 본 방법은 완전히 training-free로 state-of-the-art 성능 달성, novel class에 fine-tuning하는 방법들 상회
- 아래 그림은 crowded scene에서 multiple overlapping instance를 fine-grained semantics와 precise localization으로 처리하는 능력 시각화

- Semantic-aware soft merging으로 duplicate detection과 false positive 완화
PASCAL VOC Few-Shot Benchmark
- PASCAL VOC 데이터셋은 20개 클래스 포함
- Few-shot 평가를 위해 클래스를 3개 그룹으로 분할, 각 그룹은 15개 base 클래스와 5개 novel 클래스 포함
- 기존 연구와 동일하게 novel 클래스에 대해 AP50 결과 비교
- 아래 테이블은 본 방법이 모든 split에서 기존 방법들을 상회하며 state-of-the-art 성능 달성, fine-tuning 여부와 관계없이 우수
4.2. Cross-Domain Few-Shot Object Detection
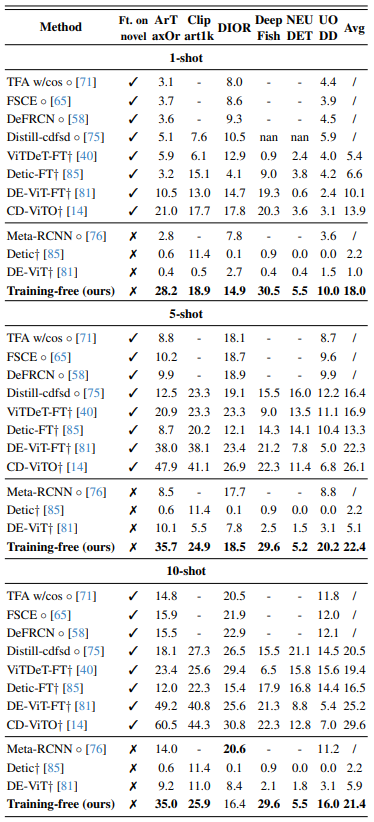
- CD-FSOD benchmark는 domain shift와 limited data 시나리오의 도전을 평가하기 위해 설계
- COCO를 source training dataset (SD)으로 사용, 6개 target dataset (TD)—ArTaxOr, Clipart1k, DIOR, DeepFish, NEUDET, UODD—는 photorealistic, cartoon, aerial, underwater, industrial domain을 포함하며 높은 inter-class variance 보유
- 많은 방법은 TD의 소수 labeled instance (support set )로 fine-tuning 후 query set 에서 테스트하나, 본 모델은 완전히 training-free
- 6개 target dataset에서 fine-tuning 없이 직접 평가
- 아래 테이블은 1-shot, 5-shot, 10-shot 설정에서 FSOD 방법 비교. 본 방법은 training-free 방법 중 state-of-the-art 설정, fine-tuned 모델과 비교에서도 경쟁력 유지
- 결과는 강력한 cross-domain generalization과 retraining 없는 robustness 입증
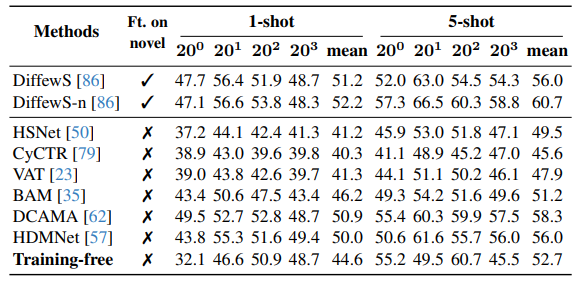
4.3. COCO Few-Shot Semantic Segmentation
- 본 방법은 instance segmentation용으로 설계되었으나, COCO-20i Few-Shot Semantic Segmentation benchmark에서도 평가
- 80개 COCO 클래스는 4개 fold로 나뉘며, 각 fold는 60개 base 클래스와 20개 novel 클래스 포함
- Strict 1-shot 및 5-shot 설정에서 20개 novel 클래스 성능 평가
- 결과는 아래 테이블에 제시
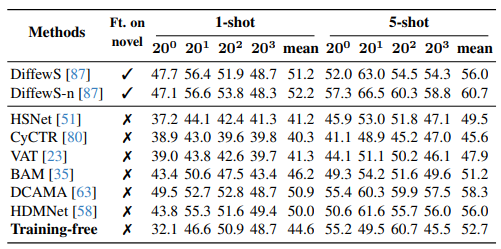
- Instance segmentation 예측을 semantic segmentation에 적응시키기 위해 동일 클래스의 모든 instance를 semantic map으로 집계, 기존 방법과 직접 비교 가능
- 완전히 training-free임에도 fine-tuned 방법과 경쟁력 있는 성능 달성
4.4. Variance in reference set
- 서로 다른 reference image를 사용하면 결과에 변동성이 발생하며, 성능은 선택된 reference image의 품질에 의존
- 이 변동성을 정량화하기 위해 COCO-20i few-shot object detection benchmark에서 서로 다른 random seed를 사용해 reference image를 선택하여 평가
- Figure 4는 10회 실행에 걸친 standard deviation (std)을 보여줌
- Reference image 수 증가 (higher n-shots)는 결과 변동성을 줄이며, std 값이 낮아짐
- 1, 2, 3-shot 설정에서는 reference image 선택이 성능에 더 큰 영향을 미침
- 5-shot 이상에서는 낮은 std로 reference set 변동에 대한 robustness 입증
- 이는 특정 reference image가 주어진 shot 설정에서 본질적으로 더 강력함을 시사
- "최적" reference set의 특성 탐구는 향후 연구의 열린 방향으로 남음
5. Conclusions
- 본 연구는 SAM의 mask 생성 능력과 DINOv2의 fine-grained semantic understanding을 통합한 novel training-free few-shot instance segmentation 방법을 제안
- Reference image를 사용해 memory bank를 구축하고, feature aggregation으로 내부 representation을 정제하며, cosine similarity와 semantic-aware soft merging을 통해 novel instance에 대한 feature matching 수행
- 기존 frozen foundation model의 신중한 설계를 통해 추가 training 없이 state-of-the-art 성능 달성:
- COCO-FSOD에서 36.8% nAP (fine-tuned 방법 상회)
- PASCAL VOC Few-Shot에서 71.2% nAP50
- CD-FSOD benchmark에서 강력한 cross-domain generalization
- Semantic segmentation 결과는 instance 예측을 semantic map으로 집계하여 instance segmentation을 넘어 확장 가능함을 확인
- 향후 연구 방향:
1) 1-5 shot 시나리오에서 가장 정보가 풍부한 reference image를 자동으로 찾는 learning-based 전략 탐구
2) DINOv2의 global semantic bias를 개선하여 fine-grained task에서 feature localization 향상
3) 1-5 shot 시나리오에서 내부 memory bank representation을 개선하기 위한 lightweight fine-tuning 접근 조사

AI Research Engineer