https://arxiv.org/abs/1502.03044
1. Introduction
Image Caption Generation의 중요성과 도전 과제
- Image caption generation은 scene understanding의 핵심 task로, 이미지 내 객체를 식별하고 그들 간의 관계를 자연어로 표현해야 함
- 컴퓨터 비전(객체 인식)과 자연어 처리(관계 표현)를 동시에 해결해야 하는 복잡한 문제로, 인간의 시각 정보를 압축해 묘사적 언어로 변환하는 능력을 모방
- Machine learning 알고리즘에 중요한 도전 과제로, 시각 정보와 언어 표현의 효과적 연결 필요
최근 연구 동향
- Neural network 학습의 발전(Krizhevsky et al., 2012)과 대규모 분류 데이터셋(Russakovsky et al., 2014) 활용으로 caption generation 품질 크게 향상
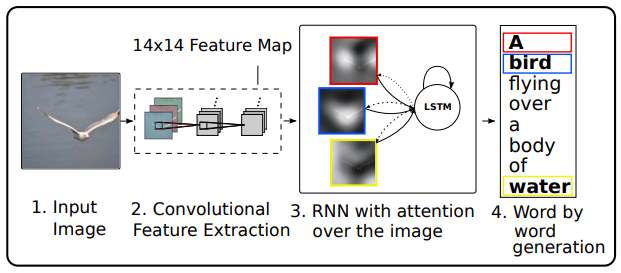
- Convolutional Neural Network(CNN)로 이미지의 vectorial representation을 추출하고, Recurrent Neural Network(RNN)로 이를 자연어 문장으로 변환하는 접근법 채택(Section 2 참조)
- 기존 방법은 이미지 전체를 static representation으로 압축, 복잡한 장면에서 정보 손실 가능성 존재
Attention Mechanism의 필요성
- 인간 시각 시스템의 attention(Rensink, 2000; Corbetta & Shulman, 2002)은 salient feature를 동적으로 강조, 복잡한 장면에서 중요한 정보 선택
- CNN top layer representation을 활용한 기존 접근은 salient 객체 추출에 효과적이지만, 정보 손실로 인해 풍부한 caption 생성에 한계
- Low-level representation은 정보 보존 가능하나, task-relevant 정보를 선택하기 위한 강력한 메커니즘 필요
- 본 연구는 attention mechanism을 도입해 이미지의 salient 부분에 집중하며 caption 생성
제안 방법과 Contribution
- 두 가지 attention-based image caption generation 모델 제안:
- Soft attention mechanism: Standard back-propagation으로 학습 가능한 deterministic 접근
- Hard attention mechanism: Approximate variational lower bound 최대화 또는 REINFORCE(Williams, 1992)로 학습 가능한 stochastic 접근
- Attention 메커니즘으로 모델이 주목하는 이미지 부분 시각화, 결과 해석 및 통찰 제공(Section 5.4 참조)
- Flickr8k(Hodosh et al., 2013), Flickr30k(Young et al., 2014), MS COCO(Lin et al., 2014) 데이터셋에서 state-of-the-art 성능 달성, attention의 유효성 입증(Section 5.3 참조)
- Machine translation(Bahdanau et al., 2014)과 object recognition(Ba et al., 2014; Mnih et al., 2014)에서의 attention 성공에 영감 받아, image caption generation에 attention 통합한 framework제시
2. Related Work
Image Caption Generation의 기존 연구
- Image caption generation은 최근 recurrent neural network(RNN)를 기반으로 한 여러 방법이 제안됨
- Sequence-to-sequence training의 성공(Cho et al., 2014; Bahdanau et al., 2014; Sutskever et al., 2014)에 영감을 받아, image caption generation은 이미지를 문장으로 "번역"하는 encoder-decoder framework(Cho et al., 2014)에 적합
- Kiros et al. (2014a)은 이미지 feature로 bias된 multimodal log-bilinear model을 제안, 이후 Kiros et al. (2014b)은 ranking과 generation을 모두 지원하는 모델로 확장
- Mao et al. (2014)은 feed-forward neural language model을 RNN으로 대체해 유사한 접근법 채택
- Vinyals et al. (2014)과 Donahue et al. (2014)은 LSTM RNN을 사용, Vinyals et al. (2014)은 이미지 입력을 RNN의 시작 시점에만 제공, Donahue et al. (2014)은 비디오에도 LSTM을 적용해 설명 생성
- 기존 모델은 사전 학습된 convolutional neural network(CNN)의 top layer에서 단일 feature vector로 이미지를 표현
- Karpathy & Li (2014)는 R-CNN 객체 탐지와 bidirectional RNN 출력을 결합한 joint embedding space를 학습해 sentence-image similarity scoring
- Fang et al. (2014)은 객체 탐지 기반 3단계 pipeline 제안: multi-instance learning으로 visual concept detector 학습, caption으로 학습된 언어 모델 적용, joint image-text embedding space로 rescoring
- 본 연구는 객체 탐지기를 명시적으로 사용하지 않고, latent alignment를 처음부터 학습해 "objectness"를 넘어 추상적 개념에 주목
비 neural network 기반 접근
- Neural network 기반 방법 이전에는 두 가지 주요 접근법이 주류:
- Object detection과 attribute discovery를 기반으로 caption template을 채우는 방법(Kulkarni et al., 2013; Li et al., 2011; Yang et al., 2011; Mitchell et al., 2012; Elliott & Keller, 2013)
- 유사한 captioned 이미지를 대규모 데이터베이스에서 검색 후, 검색된 caption을 수정해 query에 맞춤(Kuznetsova et al., 2012; 2014), 이 과정에서 caption의 특정 정보(예: 도시 이름)를 제거하는 generalization 단계 포함
- 이러한 접근법은 neural network 기반 방법에 비해 현재 선호도 낮음
Attention in Neural Networks
- Vision 관련 task에서 attention을 neural network에 통합한 연구 다수 존재(Larochelle & Hinton, 2010; Denil et al., 2012; Tang et al., 2014)
- 본 연구는 특히 Bahdanau et al. (2014), Mnih et al. (2014), Ba et al. (2014)의 attention 연구를 직접 확장
- Attention 메커니즘은 이미지의 salient 부분에 동적으로 집중, caption generation의 품질과 해석 가능성 향상에 기여
3. Image Caption Generation with Attention Mechanism
3.1. Model Details
공통 Framework
- 두 가지 attention-based 모델(soft 및 hard attention)을 공통 framework 하에 설명, 주요 차이는 함수의 정의
- 벡터는 bold font, 행렬은 대문자로 표기, 가독성을 위해 bias term 생략
3.1.1. Encoder: Convolutional Features
- 단일 raw 이미지를 입력으로 받아 1-of-K encoded 단어 시퀀스로 caption 생성, 여기서 : vocabulary 크기, : caption 길이
- Convolutional Neural Network(CNN)을 사용해 annotation vector 집합 추출, 각 : 이미지 특정 부분의 D차원 표현
- 기존 연구와 달리 fully connected layer가 아닌 lower convolutional layer에서 feature 추출, decoder가 이미지의 특정 부분에 선택적으로 집중 가능
3.1.2. Decoder: Long Short-Term Memory Network
- Long Short-Term Memory(LSTM) network(Hochreiter & Schmidhuber, 1997)를 사용해 context vector, 이전 hidden state, 이전 단어를 조건으로 단어를 순차 생성
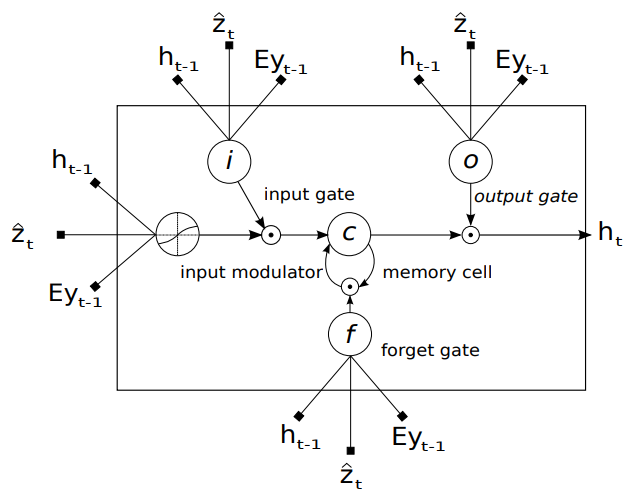
- Forget Gate : 이전 cell state 에서 잊을 정보를 결정
- Input Gate : 새로운 정보를 cell state에 추가할지 결정
- Input Modulator : 새로운 정보를 생성 (보통 활성화 함수 사용)
- Output Gate : 현재 hidden state 를 생성하기 위해 cell state를 필터링
- Memory Cell : 장기 문맥을 저장
- LSTM 구현은 Zaremba et al. (2014) 따라, 수식은 다음과 같음:여기서
- : 각각 input, forget, memory, output, hidden state
- : 특정 입력 위치의 visual 정보 포함 context vector
- : embedding matrix
- : 이전 단어 의 embedding vector
- : 이전 시간 단계의 hidden state
- : embedding 및 LSTM 차원
- : logistic sigmoid
- : element-wise multiplication
- Context vector : 시간 에서 이미지의 관련 부분을 동적으로 표현, annotation vector 에서 함수로 계산:
- 즉, 은 시간 단계 에서 캡션의 다음 단어(예: "dog", "grass")를 생성하기 위해 이미지의 어떤 부분을 봐야 할지를 선택한 뒤, 그 부분의 시각적 정보를 요약한 vector
- : Annotation vector로, 이미지의 특정 공간적 위치 (14×14 격자의 한 셀)에 해당하는 feature vector (총 =196개)
- : Attention 가중치로, 각 가 현재 단어 생성에 얼마나 중요한지를 나타내는 값
- : 와 를 결합해 를 만드는 함수 (Weighted sum)
- 는 디코더(LSTM)에 입력되어, 현재 단어 를 생성할 때 이미지의 관련된 시각적 정보를 제공
여기에서 시간 란?
이 문장은 단어 단위로 순차적으로 생성
예를 들어:
시간 : "A"
시간 : "dog"
시간 : "is"
시간 : "running"
등등...
여기서 시간 ( t )는 디코더(LSTM)가 캡션의 각 단어를 생성하는 순차적 단계
Soft/Hard Attention
-
각 위치 에 대해 attention model 는 이전 hidden state 를 조건으로 positive weight 생성:
- 는 주로 MLP나 단순 linear transform으로 구현
- : 이미지의 특정 위치(i)의 시각적 특징
- : 지금까지 생성된 단어 시퀀스(예: "A dog")의 문맥을 반영한 decoder 상태
- 출력 : 가 현재 단어 를 예측하는 데 얼마나 유용한지를 수치로 표현. 값은 양수(positive)가 될 수 있지만, 정규화 전이므로 절대적인 중요도를 의미하진 않음
- 는 위치 가 시간 에서 상대적 중요도(relative importance)를 나타냄
-
여기서 : soft attention에서는 각 위치의 상대적 중요도
"dog" 단어에서 (개 위치)가 5, (잔디 위치)가 1이라면:
- ,
- ,
- 결과: 가 훨씬 크므로 개 위치가 더 중요
- Hard attention에서는 다음 단어 생성에 집중할 위치의 확률(Bahdanau et al., 2014)
- Soft: 모든 를 weighted sum, 는 기여 비율
- Hard: 하나의 만 선택, 는 선택 확률
- 논문에서는 Soft attention이 주로 사용되며, Hard는 보조적으로 다룸
- 초기 memory state 와 hidden state 는 annotation vector 평균을 두 개의 MLP()로 예측:
- Output word 확률은 deep output layer(Pascanu et al., 2014)로 계산:여기서 : 학습된 파라미터
4. Learning Stochastic “Hard” vs Deterministic “Soft” Attention
4.1. Stochastic “Hard” Attention
- Attention 모델 의 stochastic 메커니즘에서, 위치 변수 는 번째 단어 생성 시 모델이 주목하는 위치를 나타냄
- 는 one-hot 변수로, 번째 위치(총 개 중)에서 visual feature를 추출할 경우 1로 설정
- Attention 위치를 중간 latent 변수로 간주, multinoulli distribution을 로 파라미터화:여기서 는 random variable
- 새로운 objective function 를 정의, 이는 이미지 feature 에 대해 단어 시퀀스 의 marginal log-likelihood 에 대한 variational lower bound:
- 모델 파라미터 에 대한 학습은 를 직접 최적화:
- Monte Carlo 기반 샘플링으로 gradient 근사, 를 Equation 8의 multinoulli distribution에서 샘플링:
- Monte Carlo estimator의 variance 감소를 위해 Weaver & Tao (2001)의 moving average baseline 사용:
- 추가 variance 감소를 위해 multinoulli distribution의 entropy term 추가, 확률 0.5로 샘플링된 attention 위치 를 기대값 로 설정
- 최종 학습 규칙:여기서 는 cross-validation으로 설정된 hyper-parameter
- 이는 REINFORCE 학습 규칙(Williams, 1992)과 등가, attention의 action sequence에 대한 reward는 샘플링된 attention trajectory 하에서 target sentence의 log-likelihood에 비례
- Hard attention에서 는 multinoulli distribution에 기반해 시간마다 샘플링된 반환
4.2. Deterministic “Soft” Attention
- Stochastic attention은 매번 attention 위치 를 샘플링하나, deterministic attention은 context vector 의 기대값을 직접 계산:
- Soft attention weighted annotation vector를 로 계산(Bahdanau et al., 2014), 이는 가중 context를 시스템에 입력
- Deterministic attention은 standard back-propagation으로 end-to-end 학습 가능, 모델 전체가 smooth하고 differentiable
- Deterministic attention 학습은 Section 4.1의 attention 위치 random variable 하에서 marginal likelihood(Equation 10)를 근사적으로 최적화
- LSTM의 hidden activation 는 stochastic context vector 의 linear projection 후 tanh non-linearity 적용, 첫 번째 Taylor 근사로 (기대 context vector 사용)
- Equation 7에서 , 는 로 계산된 , softmax 번째 단어 예측에 대한 normalized weighted geometric mean(NWGM):
- 이는 기대 context vector 를 사용한 feedforward propagation으로 NWGM 근사,
- Baldi & Sadowski (2014)에 따르면, , 즉 deterministic attention 모델은 attention 위치의 marginal likelihood에 대한 근사
4.2.1. Doubly Stochastic Attention
- Soft attention 모델에서, 은 softmax 출력으로 보장됨
- Deterministic 모델 학습 시 doubly stochastic regularization 도입, 을 유도하여 생성 과정에서 이미지의 모든 부분에 균등한 주목을 장려
- 실험에서 이 penalty는 BLEU score 향상에 기여, 질적으로 더 풍부하고 묘사적인 caption 생성
- Soft attention 모델은 이전 hidden state 에서 gating scalar 를 예측, 로 정의
- 는 이미지 내 객체에 더 많은 주목을 유도, attention weight의 효과 강조
- 모델은 다음 penalized negative log-likelihood를 최소화하며 end-to-end 학습:여기서 는 hyper-parameter
4.3. Training Procedure
- Stochastic 및 deterministic attention 모델 모두 stochastic gradient descent로 학습, adaptive learning rate 알고리즘 사용
- Flickr8k 데이터셋: RMSProp(Tieleman & Hinton, 2012) 최적
- Flickr30k/MS COCO 데이터셋: Adam 알고리즘(Kingma & Ba, 2014) 사용
- Decoder의 annotation 는 ImageNet에서 사전 학습된 Oxford VGGnet(Simonyan & Zisserman, 2014)을 fine-tuning 없이 사용, 원칙적으로 다른 encoding 함수도 가능
- 4번째 convolutional layer의 14×14×512 feature map(flatten 후 , 즉 ) 사용
- 최장 문장 길이에 비례하는 학습 시간 문제를 완화하기 위해, 전처리 단계에서 문장 길이를 기준으로 caption subset 사전을 생성
- 학습 중 무작위로 길이를 샘플링, 해당 길이의 mini-batch(크기 64)로 학습, 수렴 속도 크게 향상, 성능 저하 없음
- MS COCO 데이터셋에서 soft attention 모델은 NVIDIA Titan Black GPU에서 3일 미만으로 학습
- Regularization은 dropout(Srivastava et al., 2014)과 validation set의 BLEU score 기반 early stopping 사용
- 실험에서 후반 학습 단계에서 validation log-likelihood와 BLEU score 간 상관관계 저하 관찰, BLEU score를 모델 선택 기준으로 사용
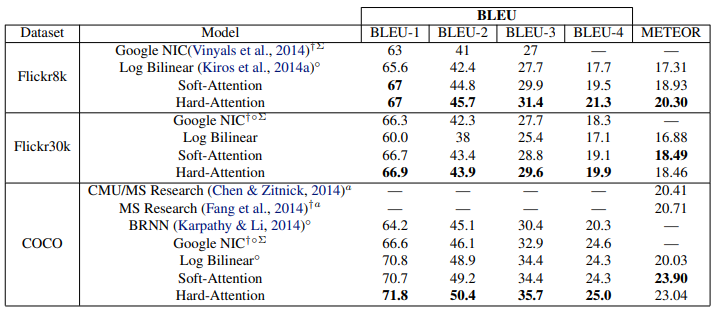
- 위 Table 본 연구의 attention 기반 이미지 캡션 생성 모델과 기존 방법들의 성능을 Flickr8k, Flickr30k, MS COCO 데이터셋에서 BLEU-1, BLEU-2, BLEU-3, BLEU-4 및 METEOR metric으로 비교
- BLEU metric?
- 생성된 캡션과 참조 캡션 간 n-gram 일치를 평가하며, BLEU-1부터 BLEU-4까지는 각각 1-gram에서 4-gram까지의 정밀도를 측정
- BLEU는 n-gram(연속된 단어 그룹, 예: 1-gram = 단어, 2-gram = 두 단어 쌍)의 일치 비율을 기반으로 문장의 유사성을 평가.
- 생성 문장이 참조 문장과 비슷한 n-gram을 많이 공유하면 의미적으로 유사하다고 간주
- 예시:
- 참조 문장: "A dog is running on the grass."
- 생성 문장: "A dog runs on grass."
- 1-gram ("A", "dog", "runs", "on", "grass") 중 공통: "A", "dog", "on", "grass" (4/5).
- 2-gram ("A dog", "dog runs", ...) 중 공통: "A dog", "on grass" (2/4).
- METEOR는 단어 의미, 동의어, 어간 일치를 고려해 더 유연한 평가를 제공
- †는 다른 데이터셋 split 사용, (—)는 미보고 metric, ◦는 저자가 개인 커뮤니케이션으로 제공한 metric, Σ는 ensemble 모델, a는 AlexNet feature 사용을 의미
- 본 모델은 single model로 state-of-the-art 성능을 달성, 특히 MS COCO에서 METEOR 점수 향상을 통해 regularization 기법과 lower-level representation의 효과 입증
- Flickr8k 실험에서 Whetlab(Snoek et al., 2012; 2014)을 활용해 hyper-parameter 탐색, Flickr30k 및 COCO 실험에 유용한 통찰 제공
5. Experiments
5.1. Data
- Flickr8k(8,000 이미지), Flickr30k(30,000 이미지), Microsoft COCO(82,783 이미지) 데이터셋에서 결과 보고
- Flickr8k 및 Flickr30k는 이미지당 5개의 reference sentence 제공, MS COCO는 일부 이미지에 5개 이상의 reference 포함하나 일관성을 위해 초과분 제외
- MS COCO에 기본 tokenization 적용, Flickr8k 및 Flickr30k와 일치
- 모든 실험에서 고정된 vocabulary 크기 10,000 사용
- Attention 기반 모델 결과는 Table 4.2.1에 보고, BLEU metric(1~4, brevity penalty 제외) 사용, 이는 caption generation 문헌의 표준
- BLEU 평가 코드는 Vinyals et al. (2014), Karpathy & Li (2014), Kiros et al. (2014b)와 일치 확인, 공정한 비교를 위해 동일 평가 코드 사용 결과만 비교
- BLEU에 대한 비판 고려, METEOR(Denkowski & Lavie, 2014) metric도 추가 보고
5.2. Evaluation Procedures
- 비교 시 세 가지 도전 과제 존재:
- Convolutional feature extractor 선택: 동일 decoder 아키텍처에서 GoogLeNet, Oxford VGG(Szegedy et al., 2014; Simonyan & Zisserman, 2014)는 AlexNet(Krizhevsky et al., 2012) 대비 성능 향상, 본 평가에서는 GoogLeNet/Oxford VGG 결과와 직접 비교, METEOR 비교 시 AlexNet 결과 일부 포함
- Single model vs. ensemble: 다른 방법은 ensembling으로 성능 향상 보고, 본 연구는 single model 성능만 보고
- Dataset split 차이: Flickr8k는 사전 정의된 split 사용, Flickr30k 및 COCO는 표준화된 split 없음, Karpathy & Li (2014)의 공개 split 사용, split 차이는 성능에 큰 영향 없음
5.3. Quantitative Analysis
- Table 4.2.1에 실험 결과 요약, Flickr8k, Flickr30k, MS COCO에서 state-of-the-art 성능 달성
- MS COCO에서 METEOR 성능 크게 향상, Section 4.2.1의 regularization 기법과 lower-level representation 사용이 기여한 것으로 추측
- Single model로 ensemble 없이 해당 성능 달성
5.4. Qualitative Analysis: Learning to Attend
- Attention component 시각화를 통해 모델 출력의 해석 가능성 향상(아래 Figure 참조)
- 기존 시스템은 객체 탐지 시스템으로 alignment target 생성(Karpathy & Li, 2014), 본 접근은 "non-object" salient region에도 주목 가능, 더 유연
- 19-layer OxfordNet은 3x3 filter 스택 사용, max pooling layer에서만 feature map 크기 감소
- 입력 이미지는 짧은 변을 256으로 resize, aspect ratio 유지, 224x224 center crop 후 convolutional network 입력, 4번의 max pooling으로 top convolutional layer 출력은 14x14
- Soft attention 모델의 attention weight 시각화를 위해 weight를 배 upsample 후 Gaussian filter 적용, 14x14 unit의 receptive field는 고도로 중첩
- 아래 Figure 2, 3에서 모델이 학습한 alignment는 인간 직관과 강하게 일치, 특히 오류 사례에서 시각화를 통해 오류 원인 직관적 이해 가능

Figure 2. Attention over Time모델이 각 단어를 생성할 때, attention은 이미지의 관련 부분을 반영하도록 변화
- Soft attention (상단 행): 각 시간 단계에서 이미지의 여러 부분에 가중치를 부여해 부드럽게 주목
- Hard attention (하단 행): 각 시간 단계에서 특정 위치에 집중적으로 주목
- 본 예시에서 soft와 hard attention 모델은 동일한 caption 생성
시각화는 attention 메커니즘이 단어 생성에 따라 이미지의 어떤 부분에 초점을 맞추는지 보여줌

Figure 3. Examples of Attending to the Correct Object모델이 올바른 객체에 주목하는 사례 시각화
- 흰색 영역은 모델이 주목한(attended) 이미지 부분을 나타냄
- 밑줄은 주목한 영역에 대응하는 생성된 단어를 표시
- 시각화는 모델이 단어 생성 시 이미지 내 관련 객체에 정확히 초점을 맞추는 능력을 보여줌
6. Conclusion
- Attention 기반 접근법으로 Flickr8k, Flickr30k, MS COCO 데이터셋에서 BLEU 및 METEOR metric 기준 state-of-the-art 성능 달성
- 학습된 attention을 활용해 모델 생성 과정의 해석 가능성 제공, alignment가 인간 직관과 잘 일치
- 본 연구는 visual attention의 미래 연구를 장려, encoder-decoder와 attention의 모듈화는 다른 도메인에서도 유용한 응용 가능성 제시

AI Research Engineer