https://arxiv.org/abs/2004.06165
1. Introduction
Vision-Language Pre-training (VLP)와 Cross-Modal Representation
- Vision-Language (V+L) task(예: visual question answering, image-text retrieval, image captioning)에서 cross-modal representation 학습은 핵심적인 역할 수행
- Visual Question Answering (VQA): 이미지와 관련된 질문에 답변하는 작업. 예: 이미지 속 개체, 색상, 행동 등을 묻는 질문에 텍스트로 답함 (예: "이 사진에 강아지가 있나요?" → "네, 강아지가 있습니다")
- Image-Text Retrieval: 이미지와 텍스트 간의 관련성을 찾아 매칭하는 작업. 예: 주어진 텍스트 설명에 맞는 이미지를 찾거나, 이미지에 맞는 텍스트를 검색 (예: "해변 일몰" → 관련 이미지 반환)
- Image Captioning: 이미지의 내용을 설명하는 텍스트를 생성하는 작업. 예: 이미지를 보고 자동으로 캡션 생성 (예: "해변에서 일몰을 바라보는 사람")
- 핵심 차이:
- VQA는 질문에 답하는 대화형 작업
- Image-Text Retrieval은 이미지와 텍스트 간 매칭
- Image Captioning은 이미지 설명 생성
- 최근 연구는 대규모 image-text pair를 활용한 VLP가 generic representation을 효과적으로 학습하며, task-specific fine-tuning을 통해 V+L task에서 state-of-the-art (SoTA) 성능 달성
- VLP 모델은 multi-layer Transformer 기반, image region feature와 text feature를 결합하여 self-attention 메커니즘으로 semantic alignment 학습
- 그러나 기존 방법은 명시적 alignment 정보 부족으로 weakly-supervised learning 문제에 직면하며, over-sampled, noisy, ambiguous visual region으로 인해 학습 난이도 증가
Object Tag를 활용한 Alignment 개선
- 본 연구는 이미지에서 검출된 object tag를 anchor point로 도입하여 image-text 간 semantic alignment 학습을 크게 개선
- 제안된 Oscar 모델은 학습 샘플을 (word sequence, object tag set, image region feature set)으로 구성된 triple로 정의
- MS COCO 데이터셋에서 image와 paired text가 1, 2, 3개 이상의 객체를 공유하는 비율은 각각 49.7%, 22.2%, 12.9%로, 객체가 텍스트에 자주 언급됨을 관찰
- Oscar는 650만 image-text pair로 구성된 대규모 V+L 데이터셋으로 pre-training, 7개 V+L understanding 및 generation task에서 fine-tuning 및 평가
- Object tag를 anchor point로 활용한 alignment modeling은 NLP에서 탐구된 바 있으나, VLP에서는 최초로 적용
- 기존 연구는 object/image tag를 feature representation 개선에 활용했으나, image-text alignment 학습에는 초점 맞추지 않음
기존 접근의 한계
- 기존 VLP 방법은 두 가지 주요 문제 직면:
- Ambiguity: Visual region feature는 Faster R-CNN과 같은 object detector로 추출되며, over-sampled region으로 인해 위치 간 overlap 발생, 예: dog와 couch의 region feature 구분 어려움
- Lack of grounding: 이미지와 텍스트 간의 명시적이고 정확한 연관성(alignment) 또는 매핑이 부족한 상황을 의미. VLP는 명시적 alignment label 부족으로 weakly-supervised learning 문제, 이미지와 텍스트 간 salient object (예: dog, couch)를 anchor point로 활용 가능
- 기존 방법은 self-attention에 의존해 brute-force 방식으로 alignment 학습, 이는 효율성과 정밀도에 한계
제안 방법의 개요
- Oscar는 object tag를 anchor point로 활용해 semantic alignment 학습을 단순화, weakly-supervised learning 문제를 완화
- Training sample: , 여기서 : word sequence, : object tag set, : image region feature set
- 대규모 V+L 데이터셋 (650만 pair)으로 pre-training, 7개 downstream task에서 fine-tuning
Main Contribution
- Oscar 모델 제안: Object tag를 anchor point로 활용해 generic image-text representation을 학습하는 강력한 VLP 방법
- SoTA 성능: 다수 V+L benchmark에서 기존 접근법을 큰 차이로 상회하는 새로운 SoTA 달성
- 분석 및 통찰: Object tag를 anchor point로 사용한 cross-modal representation 학습의 효과와 downstream task 성능에 대한 실험적 분석 제공
3. Oscar Pre-training
Multi-Channel Perception과 Oscar 제안
- 인간은 다양한 채널(시각, 언어 등)을 통해 세상을 인식하며, 각 채널이 불완전하거나 노이즈가 있어도 중요한 요소는 여러 채널에 걸쳐 공유됨 (예: dog는 시각적, 언어적으로 모두 묘사 가능, 아래 Figure 참조)
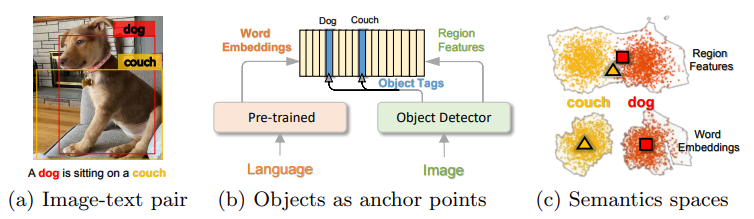
위 그림은 Oscar 모델이 image-text pair를 dictionary lookup으로 semantic space에 표현하는 과정 설명
- (a) Input 예시: Image-text pair 제공
- (b) Object tag 활용: Object tag(예: "dog", "couch")를 anchor로 이미지 region과 언어 모델의 word embedding 정렬
- (c) Word semantic space 우수성: Image feature보다 word semantic space가 더 대표성을 가짐. 예: Visual feature space에서 "dog"와 "couch" 혼동, word embedding space에서는 구분
- 본 연구는 이러한 관찰을 바탕으로 channel-invariant (또는 modality-invariant) semantic factor를 포착하는 새로운 VLP 방법 Oscar 제안
- Oscar는 입력 image-text pair의 표현 방식과 pre-training objective에서 기존 VLP와 차별화, 아래 Figure에 개요 제시
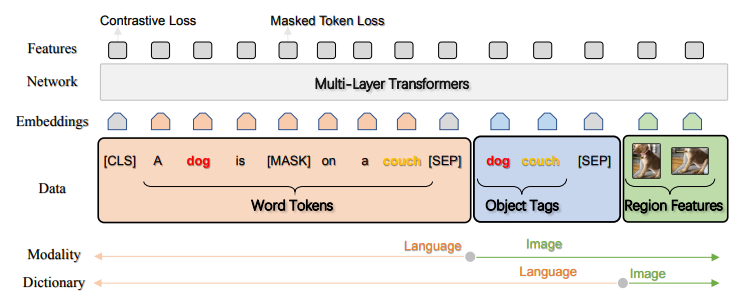
위 그림은 Oscar 모델 설명
- Image-text pair 표현: [word tokens, object tags, region features] 형태의 triple로 표현. Object tags(예: “dog”, “couch”)는 cross-domain semantics 정렬 제안. Object tags 제거 시, 기존 VLP 방법으로 축소
- 두 가지 관점:
- Modality view: Image와 text의 modality 간 관계
- Dictionary view: Dictionary lookup을 통한 semantic 정렬
- 요약: Oscar는 object tags로 image-text triple 구성, cross-domain semantics 정렬. Tags 제거 시 기존 VLP로 축소, modality 및 dictionary view로 이해 가능
Input Representation
- Oscar는 image-text pair를 Word-Tag-Image triple 로 표현:
- : text의 word embedding sequence
- : 이미지에서 검출된 object tag의 word embedding sequence
- : 이미지의 region vector set
- 기존 VLP는 로 입력을 표현, Oscar는 를 anchor point로 도입해 image-text alignment 학습 용이
- Object tag 는 이미지의 중요 객체가 paired text에 자주 나타난다는 관찰 기반, 동일 단어 또는 의미적으로 유사/관련된 단어로 표현
- Pretrained BERT 모델로 와 간 alignment 식별이 용이, 이미지 내 object tag가 검출된 region은 text의 관련 단어와 쿼리 시 높은 attention weight 가짐 (Fig. 2(b) 참조)
- 이는 모호한 시각 공간의 객체 (예: Fig. 2(a)의 dog, couch)를 언어 공간에서 구별 가능한 entity로 grounding (Fig. 2(c))
Feature Extraction
- 이미지에 K개 region (보통 over-sampled, noisy) 주어짐, Faster R-CNN으로 각 region의 visual semantics를 로 추출:
- : P차원 region feature (P=2048)
- : R차원 region position vector (R=4 또는 6, top-left/bottom-right 좌표 또는 높이/너비 포함)
- 와 를 결합해 position-sensitive region feature 생성, linear projection으로 word embedding과 동일한 차원으로 변환해 생성
- 동일한 Faster R-CNN으로 high-precision object tag set 검출, 는 object tag의 word embedding sequence
Pre-Training Objective
- Oscar 입력은 두 관점에서 정의:
- Modality view: , 언어()와 이미지() representation 구분
- Dictionary view: , 언어적 semantic space()와 시각적 semantic space() 구분
- 이를 바탕으로 두 가지 pre-training loss 설계:
-
Masked Token Loss (MTL):
-
토큰 시퀀스 는 텍스트 단어()와 객체 태그()를 합친 것으로, 둘 다 같은 언어 의미 공간을 공유
- : 텍스트의 단어 시퀀스(word sequence)를 pre-trained BERT의 word embedding으로 변환한 것. 예: "A dog is sitting on a couch" → ["A", "dog", "is", "sitting", "on", "a", "couch"]의 embedding
- : 이미지에서 Faster R-CNN으로 검출된 object tag(예: "dog", "couch")를 BERT의 word embedding으로 변환한 시퀀스
- : 와 를 연결한 시퀀스
-
이미지 정보 : Faster R-CNN으로 추출한 region features(최대 50개의 ROI에서 얻은 시각적 특징 벡터 집합). 각 region feature는 시각적 정보(, 2048차원)와 위치 정보(, 4 또는 6차원)를 결합한 후 word embedding 차원(768 또는 1024)으로 변환
-
마스킹 과정: 각 token을 15% 확률로 [MASK]로 대체, 이는 BERT의 MLM과 동일한 전략:
- 예: 에서 "dog"과 "couch"가 마스킹되면 가 됨
-
Loss function:
- 의미: 데이터셋 에서 샘플링한 쌍에 대해, 마스킹된 토큰 의 예측 확률 의 로그를 최대화 (즉, Negative log-likelihood를 최소화)
- 즉, MTL은 텍스트와 object tag를 시각적 정보와 정렬하도록 학습시키며, 이미지-텍스트 간의 세밀한 의미적 연결을 강화
-
BERT의 masked language model과 유사, 이미지 정보를 추가해 word embedding을 vision context에 grounding
-
-
Contrastive Loss (LC):
- Contrastive Loss(LC)는 이미지와 텍스트가 올바르게 쌍을 이루는지(aligned) 구분하도록 학습
- 원본 이미지-텍스트 쌍(Positive sample)과 오염된(polluted) 쌍(Negative sample)을 비교하여, 모델이 올바른 쌍을 선호하도록 유도
- 이미지 modality , 언어 modality
- 를 데이터셋 에서 무작위로 샘플링한 다른 tag sequence로 50% 확률로 대체해 “polluted” 이미지 representation 생성
- 오염된(polluted) 이미지 생성: 를 데이터셋 에서 무작위로 샘플링한 다른 object tag 시퀀스로 50% 확률로 대체
- 오염된 이미지 표현은 가 됨
- [CLS] token의 encoder 출력은 vision-language 융합 representation, 이를 FC layer 로 이진 분류 (원본: , polluted: ):
- 학습 과정:
- Transformer는 입력 또는 오염된 를 처리해 [CLS] 토큰의 출력(encoder의 최종 representation)을 생성
- [CLS] 토큰의 출력은 vision-language 융합 representation으로, 이미지와 텍스트 간의 관계를 요약
- 이 출력은 fully-connected layer 를 거쳐 이진 분류 문제로 처리
- 원본 쌍(): 레이블 (Positive sample)
- 오염된 쌍(): 레이블 (Negative sample)
- 목표: 모델이 원본 쌍과 오염된 쌍을 구분하도록 학습하며, 텍스트()가 원본 이미지()와 유사하고 오염된 이미지와는 다르도록 BERT word embedding space를 조정
- Loss function:
- Text가 paired image (object tag)와 유사하고, polluted image와는 다르도록 BERT word embedding space 조정
-
- 전체 Pre-training objective:
Objective 설계 논의
- 다른 loss function도 가능하나, MTL과 LC 선택 이유:
- 각 loss는 dictionary view와 modality view에서 대표적인 학습 신호 제공, 제안된 관점의 효과 분석에 적합
- 기존 VLP보다 단순한 loss 설계로도 우수한 성능 달성
- Objective는 image-text alignment을 명시적으로 강화하며, object tag를 proxy로 활용해 weakly-supervised 문제 완화
Pre-training Corpus
- COCO, Conceptual Captions, SBU Captions, Flicker30k, GQA 등 기존 V+L 데이터셋 기반 corpus 구축
- 총 410만 unique image, 650만 text-tag-image triple로 구성 (자세한 내용은 Appendix 참조)
Implementation Details
- 두 모델 variant pre-training:
- Oscar_B: BERT base ()로 초기화
- Oscar_L: BERT large ()로 초기화, 는 hidden size
- Image region feature는 linear projection matrix 로 word embedding과 동일 차원으로 변환, 학습 파라미터:
- AdamW Optimizer 사용:
- Oscar_B: 최소 100만 step, learning rate , batch size 768
- Oscar_L: 최소 90만 step, learning rate , batch size 512
- Discrete token 의 sequence length: 35, region feature : 50
4. Adapting to V+L Tasks
Overview
- Pre-trained Oscar 모델을 7개 downstream V+L task에 적응, 5개 understanding task와 2개 generation task 포함
- 각 task는 고유한 적응 도전 과제를 제시, fine-tuning 전략은 아래에 설명, 데이터셋 및 평가 메트릭 세부사항은 Appendix 참조
Image-Text Retrieval
- Task 설명: Image-Text Retrieval은 joint representation에 크게 의존, image retrieval과 text retrieval 두 sub-task로 구성 (검색 대상 modality에 따라 나뉨)
- Fine-tuning 전략:
- Binary classification 문제로 formulize, aligned image-text pair 주어짐
- Unaligned pair는 무작위로 다른 image 또는 caption 선택해 생성
- [CLS] token의 최종 representation을 classifier 입력으로 사용, pair가 aligned인지 예측
- Binary classification loss 사용 (ranking loss보다 성능 우수)
- Inference: Probability score로 주어진 image-text pair 순위 매김
- 평가: COCO 1K 및 5K test set에서 top-K retrieval 결과 보고
Image Captioning
- Task 설명: 이미지 내용을 자연어로 설명하는 문장 생성
- Fine-tuning 전략:
- Seq2seq objective로 fine-tuning, 입력은 pre-training과 동일한 (image region feature, caption, object tag) triple
- Caption token을 15% 확률로 무작위 마스킹, 출력 representation으로 token id 예측 (classification)
- Self-attention mask는 uni-directional generation 모방, caption token은 이전 token 및 모든 image region, object tag에 full attention 허용
- Inference:
- 입력으로 image region, object tag, [CLS] token 인코딩
- [MASK] token으로 시작, vocabulary에서 likelihood 기반 token 샘플링
- 이전 [MASK]를 샘플링된 token으로 대체, 새로운 [MASK] 추가해 다음 단어 예측, [STOP] token 출력 시 종료
- Beam search (beam size=5) 사용
- 평가: COCO image captioning 데이터셋에서 결과 보고
Novel Object Captioning (NoCaps)
- Task 설명: Open Images 데이터셋 기반, training corpus에 없는 novel object 설명 능력 테스트
- Fine-tuning 전략:
- NoCaps 제한 가이드라인 준수, Visual Genome 및 Open Images 예측 label로 tag sequence 구성
- Pre-training 초기화 없이 COCO 데이터셋으로 Oscar 학습
- 평가: Novel object 설명 능력 평가
Visual Question Answering (VQA)
- Task 설명: 이미지 기반 자연어 질문에 답변, multi-choice list에서 정답 선택
- 데이터셋: VQA v2.0 (MSCOCO 기반), train (83k 이미지, 444k 질문), validation (41k 이미지, 214k 질문), test (81k 이미지, 448k 질문)
- Fine-tuning 전략:
- 입력 sequence는 질문, object tag, region feature 결합
- Oscar의 [CLS] 출력은 task-specific linear classifier로 전달, 답변 예측
- Multi-label classification 문제로 처리, 인간 답변 relevancy 기반 soft target score 할당
- Cross-entropy loss (예측 score와 soft target score 간) 최소화
- Inference: Softmax 함수로 예측
- 평가: 3,129개 공유 답변 set에서 선택
GQA
- Task 설명: VQA와 유사하나, 질문에 답변하기 위한 reasoning 능력 테스트
- 데이터셋: Public GQA 데이터셋, 1,852개 후보 답변 set
- Fine-tuning 전략:
- Oscar_B 기반 두 모델 개발:
- VQA와 유사한 fine-tuning
- Oscar*_B: “all-split”에서 5 epoch fine-tuning 후, “balanced-split”에서 2 epoch fine-tuning
- Oscar_B 기반 두 모델 개발:
- 평가: Reasoning 능력 중심 평가
Natural Language Visual Reasoning for Real (NLVR2)
- Task 설명: 두 이미지와 자연어 문장 주어짐, 문장이 이미지 쌍에 대해 참인지 판단
- Fine-tuning 전략:
- 두 입력 sequence 구성, 각 sequence는 문장 (자연어 설명)과 하나의 이미지 결합
- Oscar에서 두 [CLS] 출력 추출, 결합 후 MLP 기반 binary classifier로 전달
- 평가: Binary classification으로 참/거짓 판단
5. Experimental Results & Analysis
5.1 Performance Comparison with SoTA
- Oscar의 parameter 효율성을 평가하기 위해 세 가지 SoTA 기준과 비교:
- SoTA_S: Transformer 기반 VLP 모델 이전의 소규모 모델이 달성한 최고 성능
- SoTA_B: BERT base와 유사한 크기의 VLP 모델이 달성한 최고 성능
- SoTA_L: BERT large와 유사한 크기의 VLP 모델이 달성한 최고 성능 (현재 UNITER가 유일)
- 아래 Table 1은 7개 V+L task에 대한 전체 결과 요약, Oscar 결과는 회색 배경, task별 최고 성능은 파란색으로 표시
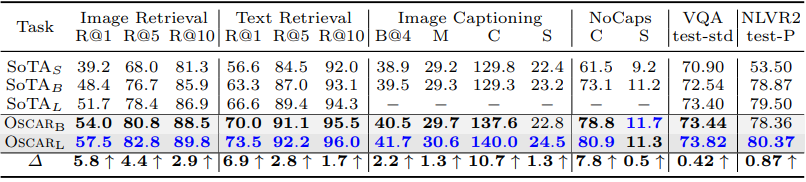
- 주요 결과:
- Oscar base 모델은 대부분 task에서 기존 large 모델을 큰 차이로 상회, parameter 효율성 입증
- Object tag를 anchor point로 사용하여 image-text semantic alignment 학습 용이
- Oscar는 650만 pair로 pre-training, UNITER (960만 pair) 및 LXMERT (918만 pair)보다 적은 데이터로 학습
- Task별 비교 (아래 Table 2):
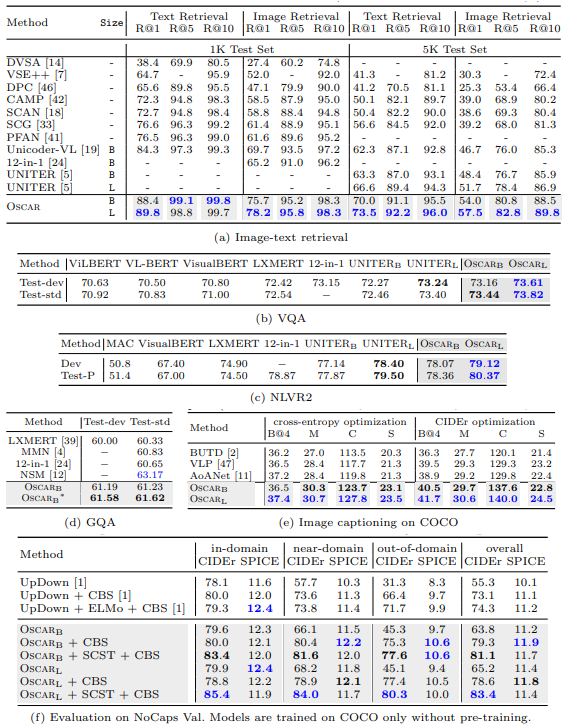
- VLP 성능 우위: VLP 방법은 소규모 모델 대비 대부분 V+L task에서 우수, Oscar는 7개 task 모두에서 기존 VLP를 상회, 6개 task에서 새로운 SoTA 달성
- GQA: Neural State Machine (NSM)은 강력한 structural prior 활용, 향후 Oscar에 통합 가능
- 12-in-1 비교: BERT base 기반 multi-task learning 모델 12-in-1 대비 Oscar_B는 NLVR2 Test-P 제외 거의 모든 task에서 우수, single-task fine-tuning의 효과 입증
- Image Captioning: Self-critical sequence training (SCST)으로 추가 fine-tuning, BLEU@4와 CIDEr에서 각각 2, 10 포인트 이상 개선, 기존 VLP 대비 우수
- NoCaps: COCO 학습 데이터만 사용, constrained beam search 적용, Oscar는 UpDown 대비 near-domain 및 out-of-domain에서 큰 성능 격차로 SoTA 달성, 강력한 generalization 입증
5.2 Qualitative Studies
- COCO test set의 image-text pair를 t-SNE로 2D map에 시각화, 각 image region과 word token의 last-layer 출력 feature로 분석
- 주요 발견 (아래 Figure 4):

- Intra-class: Object tag 사용 시 동일 객체의 시각적/텍스트 representation 간 거리 크게 감소 (예: person, zebra)
- Inter-class: Object tag 추가 시 관련 semantic class (예: animal, furniture, transportation)는 구분 가능하면서도 가까워짐, baseline은 혼합 (예: person/zebra, chair/couch)
- Object tag는 cross-modal feature 학습에서 anchor point로 작용, alignment 정규화에 기여
- Caption 생성 비교 (아래 Figure 5):

- Baseline (object tag 없는 VLP) 대비 Oscar는 Faster R-CNN으로 검출된 정확하고 다양한 object tag 활용, 더 상세한 이미지 설명 생성
- Object tag는 word embedding space에서 anchor point로 작용, text 생성 과정 가이드
5.3 Ablation Analysis
-
Oscar의 pre-training 및 fine-tuning 설계 선택을 네 가지 대표 downstream task에서 ablation 실험, base 모델 사용
-
Object Tag 효과:
- 세 설정 비교:
- Baseline (No Tags): Object tag 미활용, 기존 VLP와 동일
- Predicted Tags: COCO 데이터셋으로 학습된 object detector로 tag 예측
- Ground-truth Tags: COCO ground-truth tag 사용, 성능 상한선
- VQA, image retrieval, image captioning task에서 실험 (Fig. 6):
- Object tag 사용 시 fine-tuning 학습 곡선이 baseline보다 빠르고 우수
- VQA 및 retrieval task에서 tag 사용 시 baseline 최종 성능을 절반 시간에 달성, Oscar의 효율성 입증
- 더 정확한 object detector 개발 시 ground-truth tag에 근접한 성능 기대
- 세 설정 비교:
-
Attention Interaction:
- Image-text retrieval에서 attention mask 변화를 통해 text, object tag, region feature 간 상호작용 분석
- 기본 설정은 모든 modality 간 full attention, 부분 attention mask (w-v, v-q 등) 비교
- Table 3 (COCO 1K test set 결과):
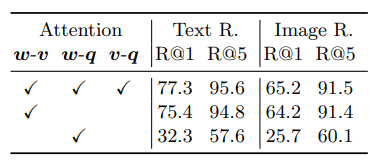
- Full attention 대비 w-v partial attention 비교 시 object tag 추가가 유리
- Region feature가 object tag보다 이미지 표현에 더 유익 (w-v > v-q)
- Object tag는 feature로 사용 시 미미한 개선, anchor point로 사용 시 효과적
-
Pre-training에서의 Object Tag:
- Visual Genome (VG) 및 Open Images (OI) 데이터셋으로 학습된 object detector의 tag 사용, Oscar_VG 및 Oscar_OI pre-training (589k step)
- Table 4 결과:

- Object tag 사용(Oscar_VG, Oscar_OI)은 baseline(No Tags) 대비 성능 향상
- VG tag가 OI tag보다 약간 우수, VG의 더 다양한 객체 집합 때문으로 추정
- OI는 더 높은 정밀도, VG는 객체 다양성 제공
6. Related Work
Vision-Language Pre-training (VLP)
- V+L task(예: visual question answering, image-text retrieval, image captioning)에 대한 관심 증가, generic 모델을 pre-training하여 다양한 문제 해결:
- Visual Question Answering (VQA): 이미지 기반 질문에 답변, 예: "사진에 고양이가 있나요?" → "네, 고양이가 있습니다."
- Image-Text Retrieval: 텍스트 또는 이미지 쿼리에 맞는 대상을 검색, 예: "산속 풍경" → 관련 이미지 반환
- Image Captioning: 이미지 설명 생성, 예: "숲속에서 하이킹하는 사람들"
- 기존 VLP 방법은 BERT-like objective를 사용하여 visual region feature와 language token embedding의 concatenated sequence에서 cross-modal representation 학습
- Transformer의 self-attention 메커니즘에 의존해 양 modality의 contextualized joint representation 학습:
- 초기 연구는 two-stream 또는 three-stream Transformer 기반 framework 제안, co-attention으로 modality 융합
- Chen 등은 다양한 pre-training objective의 효과 분석
- Zhou 등은 VQA와 image captioning을 downstream task로 한 통합 모델 제안
- Oscar의 차별점: Object tag를 anchor point로 사용하여 image-text alignment 학습, cross-modal semantic alignment을 처음부터 학습해야 하는 기존 VLP의 도전 과제 완화
- Oscar base 모델은 기존 large VLP 모델을 대부분 V+L task에서 상회, 학습 효율성 및 성능 개선 입증
Object Tags
- Anderson 등은 Faster R-CNN을 활용해 이미지를 visual region set으로 표현, object-level attention 계산, fine-grained image understanding task의 표준으로 자리 잡음
- 본 연구는 object tag를 사용하여 Anderson 등의 object-region feature를 pre-trained linguistic semantic space에 정렬
- Object tag 활용은 이미지 이해에서 탐구된 바 있음:
- Wu 등은 CNN 기반 grid-wise region feature에서 예측된 object tag를 LSTM 입력으로 사용 (image captioning)
- You 등은 tag와 region feature 모두 고려
- Zhou 등은 object prediction probability vector를 region feature와 결합하여 VLP의 visual input으로 사용
- 한계: 기존 연구는 object tag를 object region과 text의 word embedding에 동시에 연관시키지 않아 grounding 부족
- Oscar의 기여: Object tag와 해당 region feature, word embedding을 결합한 완전하고 정보적인 객체 표현 생성, 특히 pre-trained linguistic entity embedding 활용 시 효과적
Multimodal Embeddings
- V+L task는 이미지와 텍스트 간 inter-modal correspondence를 정렬하는 공유 embedding space에서 이점:
- Socher 등은 kernelized canonical correlation analysis로 word와 image region을 공통 공간에 투영, annotation 및 segmentation에서 성과
- 유사 아이디어는 image captioning 및 text-based image retrieval에 적용
- DeViSE는 un-annotated text에서 얻은 semantic 정보로 visual object 식별, zero-shot prediction에서 수천 개의 novel label에 대해 성능 향상
- 후속 연구는 pre-trained linguistic knowledge를 활용해 semantic alignment와 cross-modal transfer learning의 sample 효율성 개선
- 본 연구는 neural language model pre-training 시대의 풍부한 word embedding semantics를 재검토, Oscar는 novel object captioning 결과로 pre-trained 모델의 generalization 능력 향상 입증
7. Conclusion
연구 요약
- 본 연구는 object tag를 anchor point로 활용하여 image와 language modality를 공유 semantic space에 정렬하는 새로운 VLP 방법 Oscar 제안
- Oscar는 650만 text-image pair로 구성된 공개 corpus로 pre-training, triple (word sequence, object tag, image region feature)을 입력으로 사용
- Pre-training objective는 Masked Token Loss ()와 Contrastive Loss () 결합, weakly-supervised learning 문제 완화
- Object tag는 Faster R-CNN으로 검출, linguistic semantic space에서 anchor point로 작용해 cross-modal alignment 학습 효율화
주요 성과
- Oscar는 6개 V+L understanding 및 generation task에서 새로운 state-of-the-art 성능 달성:
- Image-Text Retrieval: COCO 1K/5K test set에서 top-K 결과 개선
- Image Captioning: SCST fine-tuning으로 BLEU@4, CIDEr 성능 대폭 향상
- NoCaps: Near-domain 및 out-of-domain에서 강력한 generalization
- VQA, GQA, NLVR2: Task-specific fine-tuning으로 기존 VLP 모델 상회
- Oscar base 모델은 UNITER, LXMERT 등 large 모델 대비 적은 데이터(650만 vs. 960만/918만 pair)로 학습, parameter 효율성 입증
- Qualitative 분석(t-SNE 시각화, Fig. 4)으로 object tag가 intra-class 및 inter-class representation 정렬에 기여 확인
- Ablation 실험(Fig. 6, Table 3, 4)으로 object tag의 anchor point 역할과 pre-training 효율성 검증
향후 연구 방향
- 더 정확한 object detector 개발로 ground-truth tag에 근접한 성능 기대
- 다양한 object tag set(예: Visual Genome, Open Images 외 다른 데이터셋) 탐구로 generalization 추가 개선
- Structural prior(NSM 등) 통합으로 GQA와 같은 reasoning task 성능 향상
- Multi-task learning(12-in-1 등)과 Oscar의 single-task fine-tuning 결합 가능성 탐색

AI Research Engineer