https://arxiv.org/abs/2201.12086
1. Introduction
Vision-Language Pre-training (VLP) and Its Challenges
- Vision-Language Pre-training (VLP)은 Image-Text Retrieval, Image Captioning, Visual Question Answering (VQA), Visual Reasoning, Visual Dialog 등 다양한 멀티모달 다운스트림 태스크에서 큰 성공을 거둠
- Image-Text Retrieval: Image와 Text 설명을 매칭하거나, Text 쿼리에 맞는 Image를 검색 (예: "일몰 해변" 쿼리로 관련 Image 반환)
- Image Captioning: Image 내용을 자연어로 설명하는 문장 생성 (예: "일몰 해변에서 걷는 사람")
- Visual Question Answering (VQA): Image에 대한 질문에 답변 (예: "Image에 강아지가 있나요?" → "네")
- Visual Reasoning: 시각 및 Text 입력을 기반으로 논리적 추론 (예: 두 Image에 대한 문장이 참인지 판단)
- Visual Dialog: Image에 대해 다중 턴 대화 수행
- 그러나 기존 VLP 방법은 두 가지 주요 한계를 가짐:
- Model Perspective:
- 대부분의 방법은 Encoder-based 모델 (예: CLIP [Radford et al., 2021], ALBEF [Li et al., 2021a]) 또는 Encoder-Decoder 모델 (예: SimVLM [Wang et al., 2021], Cho et al., 2021)을 채택
- Encoder-based 모델: 이해 태스크 (예: Retrieval)에 효과적이지만, Image Captioning 같은 Text 생성 태스크로의 직접 전이가 어려움
- Encoder-Decoder 모델: 생성 태스크에 적합하나, Image-Text Retrieval 태스크에서 성공적으로 적용되지 못함
- Data Perspective:
- 최신 방법들 (예: CLIP, ALBEF, SimVLM)은 웹에서 수집된 대규모 image-text pair로 사전 학습
- 데이터셋 규모를 확장하면 성능이 향상되지만, 노이즈가 많은 웹 Text는 Vision-Language 학습에 최적이지 않으며, 크로스-모달 정렬 효율성을 저하
- Model Perspective:
Proposed Method: BLIP
- 본 연구는 BLIP (Bootstrapping Language-Image Pre-training)을 제안하여, 기존 방법보다 더 광범위한 다운스트림 태스크를 지원하는 새로운 VLP 프레임워크를 제시
- BLIP는 모델과 데이터 관점에서 두 가지 주요 기여를 제공:
- Multimodal Mixture of Encoder-Decoder (MED):
- 효과적인 멀티태스크 사전 학습과 유연한 전이 학습을 위한 새로운 모델 아키텍처
- MED는 세 가지 모드로 동작 가능:
- Unimodal Encoder: Text 또는 Image를 독립적으로 처리
- Image-Grounded Text Encoder: Image와 Text 표현을 정렬하여 이해 태스크 지원
- Image-Grounded Text Decoder: Image에 기반한 Text 생성 태스크 지원
- 세 가지 Vision-Language 목표로 공동 사전 학습:
- Image-Text Contrastive Learning (ITC): 매칭된 image-text pair의 similarity를 최대화하고, 비매칭 pair의 similarity를 최소화
- Image-Text Matching (ITM): image-text pair가 정렬된 여부를 예측
- Image-Conditioned Language Modeling (LM): Image 입력에 기반한 Text 생성
- Captioning and Filtering (CapFilt):
- 노이즈가 많은 웹 image-text pair에서 학습을 개선하는 데이터 부트스트래핑 방법
- 두 모듈로 구성:
- Captioner: 사전 학습된 MED를 파인튜닝하여 웹 Image에 대해 합성 캡션을 생성
- Filter: 원본 웹 Text와 합성 Text에서 노이즈가 많은 캡션을 제거
- Multimodal Mixture of Encoder-Decoder (MED):
- 광범위한 실험과 분석을 통해 다음 주요 관찰을 도출:
- Captioner와 Filter가 협력하여 캡션을 부트스트래핑함으로써 다양한 다운스트림 태스크에서 성능을 크게 향상
- 더 다양한 캡션은 더 큰 성능 이득을 제공
- BLIP는 Image-Text Retrieval, Image Captioning, VQA, Visual Reasoning, Visual Dialog 등 다양한 Vision-Language 태스크에서 State-of-the-Art 성능을 달성
- 또한, Text-to-Video Retrieval과 VideoQA 같은 두 가지 Video-Language 태스크에 직접 전이하여 Zero-Shot 성능에서도 State-of-the-Art를 달성
2. Related Work
2.1. Vision-Language Pre-training
- Vision-Language Pre-training (VLP)은 대규모 image-text pair로 모델을 사전 학습하여 다운스트림 비전-언어 태스크의 성능을 향상시킴을 목표로 함
- 인간이 주석을 단 Text를 수집하는 데 드는 높은 비용 때문에, 대부분의 방법은 웹에서 크롤링한 Image와 Alt-Text pair를 사용
- 간단한 규칙 기반 필터를 적용하더라도 웹 Text에는 노이즈가 여전히 존재. 그러나 데이터셋 규모를 늘리며 얻은 성능 향상으로 인해 노이즈의 부정적 영향은 크게 간과되어 옴
- 본 연구는 웹 Text의 노이즈가 Vision-Language 학습에 최적이지 않음을 보이며, 웹 데이터를 보다 효과적으로 활용하는 CapFilt 방법을 제안
- 다양한 비전-언어 태스크를 단일 프레임워크로 통합하려는 시도가 많았음. 가장 큰 도전 과제는 이해 기반 태스크(예: Image-Text Retrieval)와 생성 기반 태스크(예: Image Captioning)를 모두 수행할 수 있는 모델 아키텍처를 설계하는 것임
- Encoder-based 모델과 Encoder-Decoder 모델은 두 유형의 태스크 모두에서 뛰어난 성능을 발휘하지 못하며, 단일 통합 Encoder-Decoder 역시 모델의 역량을 제한
- 본 연구에서 제안하는 Multimodal Mixture of Encoder-Decoder (MED)는 사전 학습을 간단하고 효율적으로 유지하면서, 다양한 다운스트림 태스크에서 더 큰 유연성과 우수한 성능을 제공
2.2. Knowledge Distillation
- Knowledge Distillation (KD)은 Teacher 모델로부터 Student 모델로 지식을 전달하여 Student 모델의 성능을 향상시킴
- Self-Distillation은 Teacher와 Student 모델의 크기가 동일한 KD의 특수 사례로, Image 분류와 최근 VLP에서 효과적임이 입증됨
- 기존 KD 방법은 대체로 Student가 Teacher의 클래스 예측을 모방하도록 강제하지만, 본 연구에서 제안하는 CapFilt는 VLP 맥락에서 더 효과적인 KD 방식으로 해석될 수 있음
- Captioner: 의미적으로 풍부한 합성 캡션을 통해 지식을 전달
- Filter: 노이즈가 많은 캡션을 제거하여 지식을 정제
- 이는 VLP에서 KD를 수행하는 새로운 접근 방식으로, 캡션의 품질과 의미적 정합성을 강화
2.3. Data Augmentation
- Data Augmentation (DA)은 컴퓨터 비전에서 널리 사용됨. 그러나 언어 태스크에서의 DA는 직관적이지 않음
- 최근 생성 언어 모델을 사용하여 다양한 NLP 태스크에 대한 예제를 합성하는 연구가 진행됨
- 이러한 방법들은 주로 저자원 언어 전용 태스크에 초점을 맞췄으나, 본 연구는 대규모 Vision-Language 사전 학습에서 합성 캡션의 이점을 입증
- 제안된 방법은 합성 캡션을 활용하여 웹 데이터의 노이즈 문제를 완화하고, 데이터 품질을 개선하여 모델 성능을 향상
3. Method
3.1. Model Architecture
- 본 연구는 BLIP를 제안하며, 이는 노이즈가 많은 image-text pair에서 학습하는 통합 VLP 프레임워크
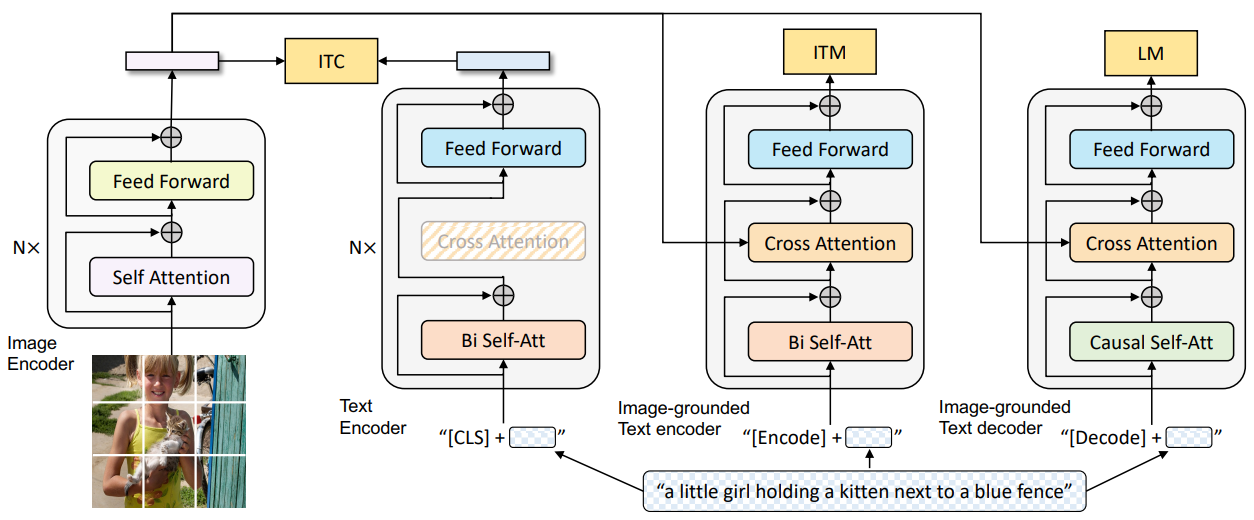
- Image 인코더로 Vision Transformer (ViT)를 사용하며, 입력 Image를 패치로 나누어 임베딩 시퀀스로 인코딩하고, 전체 Image feature를 나타내는 [CLS] 토큰을 추가
- 사전 학습된 Object Detector를 사용한 Feature 추출에 비해 ViT는 계산 효율적이며, 최근 방법들에서 채택
- 이해와 생성 능력을 모두 갖춘 통합 모델을 사전 학습하기 위해 Multimodal Mixture of Encoder-Decoder (MED)를 제안하며, 이는 세 가지 기능으로 동작:
- Unimodal Encoder: Image와 Text를 독립적으로 인코딩. Text 인코더는 BERT와 동일하며, 문장을 요약하는 [CLS] 토큰을 Text 입력 시작에 추가
- Image-Grounded Text Encoder: Text 인코더의 각 Transformer 블록에서 Self-Attention (SA) 레이어와 Feed Forward Network (FFN) 사이에 Cross-Attention (CA) 레이어를 추가하여 시각 정보를 주입. 태스크별 [Encode] 토큰을 Text에 추가하며, [Encode]의 출력 임베딩은 image-text pair의 멀티모달 표현으로 사용
- Image-Grounded Text Decoder: Image-Grounded Text Encoder의 양방향 Self-Attention 레이어를 Causal Self-Attention 레이어로 대체. [Decode] 토큰으로 시퀀스 시작을 알리고, End-of-Sequence 토큰으로 종료를 알림
3.2. Pre-training Objectives
- 사전 학습에서 두 개의 이해 기반 목표와 한 개의 생성 기반 목표, 총 세 가지 목표를 공동으로 최적화
- 각 image-text pair는 계산량이 많은 Visual Transformer를 한 번만 통과하고, Text Transformer를 세 가지 기능으로 세 번 통과하여 세 가지 Loss를 계산:
- 1) Image-Text Contrastive Loss (ITC)
- 예시 - Python code
sim_i2t = image_feat @ text_feat_all / self.temp sim_t2i = text_feat @ image_feat_all / self.temp loss_i2t = -torch.sum(F.log_softmax(sim_i2t, dim=1)*sim_i2t_targets, dim=1).mean() loss_t2i = -torch.sum(F.log_softmax(sim_t2i, dim=1)*sim_t2i_targets, dim=1).mean() loss_ita = (loss_i2t + loss_t2i) / 2 - 해석
- Image-Text Contrastive Loss (ITC)는 이미지와 텍스트의 [CLS] 토큰 임베딩 간 유사도를 계산해 Positive pair의 유사도를 최대화하고 Negative pair를 최소화
- ViT와 Text Transformer로 추출한 특징을 projection 해서 feature space를 정렬하며, log_softmax를 사용해 loss를 계산
- 이를 통해 image-text pair의 정렬성을 강화, 이해 기반 태스크 성능을 향상
- 예시 - Python code
- 2) Image-Text Matching Loss (ITM)
- Image-Grounded Text Encoder를 활성화. 비전과 언어 간 세밀한 정렬을 포착하는 멀티모달 표현을 학습
- ITM은 이진 분류 태스크로, ITM Head (Linear Layer)를 사용해 image-text pair가 Positive인지 Negative인지 예측
- 배치 내 Contrastive Similarity가 높은 Negative pair를 선택하는 Hard Negative Mining 전략을 채택
- 예시 - Python code
encoder_input_ids = text.input_ids.clone() encoder_input_ids[:,0] = self.tokenizer.enc_token_id output_pos = self.text_encoder(encoder_input_ids, attention_mask=text.attention_mask, encoder_hidden_states=image_embeds, encoder_attention_mask=image_atts, return_dict=True) vl_embeddings = output_pos.last_hidden_state[:,0,:] vl_output = self.itm_head(vl_embeddings) loss_itm = F.cross_entropy(vl_output, itm_labels) - 해석
- Image-Text Matching Loss (ITM)는 Image-Grounded Text Encoder를 사용해 image-text pair가 매칭되는지 이진 분류로 예측
- [Encode] 토큰의 멀티모달 임베딩을 ITM Head로 투영해 Positive/Negative를 판단, Cross-Entropy Loss로 학습
- Hard Negative Mining을 통해 어려운 Negative pair를 선별, image-text 정렬을 세밀히 강화
- 3) Language Modeling Loss (LM)
- Image-Grounded Text Decoder를 활성화
- Image를 조건으로 Text 설명을 생성하며, Cross Entropy Loss를 최적화해 Autoregressive 방식으로 Text의 가능도를 최대화
- Loss 계산 시 Label Smoothing (0.1)을 적용. MLM Loss와 달리 LM은 시각 정보를 일관된 캡션으로 변환하는 일반화 능력을 제공
- 예시 - Python 코드:
decoder_input_ids = text.input_ids.clone() decoder_input_ids[:,0] = self.tokenizer.bos_token_id decoder_targets = decoder_input_ids.masked_fill(decoder_input_ids == self.tokenizer.pad_token_id, -100) decoder_output = self.text_decoder(decoder_input_ids, attention_mask=text.attention_mask, encoder_hidden_states=image_embeds, encoder_attention_mask=image_atts, labels=decoder_targets, return_dict=True) loss_lm = decoder_output.loss - 해석
- LM은 Image-Grounded Text Decoder로 이미지 조건 기반 텍스트(캡션) 생성을 학습
- 코드에서
text_decoder는 CA로 이미지 특징([CLS]+패치)을 참조해 [BOS]로 시작하는 텍스트 생성 loss_lm은 Cross-Entropy로 target 캡션과의 차이를 최소화, image-text 생성 정렬 강화
- 1) Image-Text Contrastive Loss (ITC)
3.3. CapFilt
- Annotation 비용 문제로 고품질 human annotation image-text pair는 제한적이며, 최근 연구는 웹에서 자동 수집한 다량의 Image와 Alt-Text pair를 사용. 그러나 Alt-Text는 Image의 시각적 내용을 정확히 묘사하지 못해 노이즈 신호로 작용하며, 비전-언어 정렬 학습에 비최적임
- 본 연구는 Text 코퍼스의 품질을 개선하는 Captioning and Filtering (CapFilt) 방법을 제안
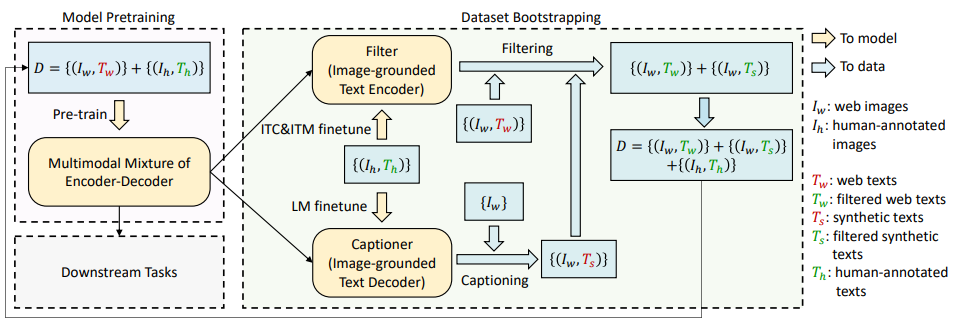
- CapFilt는 두 모듈로 구성:
- Captioner: Image-Grounded Text Decoder로, COCO 데이터셋에서 LM 목표로 Fine-tuning하여 웹 Image에 대해 합성 캡션을 생성. 각 웹 Image에 대해 하나의 합성 캡션을 생성
- Filter: Image-Grounded Text Encoder로, COCO 데이터셋에서 ITC와 ITM 목표로 Fine-tuning하여 Text가 Image와 매칭되는지 학습. 원본 웹 Text와 합성 Text에서 ITM Head가 비매칭으로 예측한 노이즈 Text를 제거
- 필터링된 image-text pair과 인간 주석 pair를 결합하여 새로운 데이터셋을 형성하며, 이를 사용해 새로운 모델을 사전 학습
4. Experiments and Discussions
4.1. Pre-training Details
- 모델은 PyTorch로 구현하며, 두 개의 16-GPU 노드에서 사전 학습. Image Transformer는 ImageNet에서 사전 학습된 ViT로 초기화하고, Text Transformer는 BERTbase로 초기화. ViT-B/16과 ViT-L/16 두 가지 ViT 변형을 탐구하며, 특별히 명시하지 않는 한 BLIP는 ViT-B를 사용
- 20 Epoch 동안 사전 학습하며, 배치 크기는 ViT-B에서 2880, ViT-L에서 2400. AdamW Optimizer를 사용하며, Weight Decay는 0.05. 학습률은 ViT-B에서 3e-4, ViT-L에서 2e-4로 Warm-up 후 선형적으로 0.85 비율로 감소
- 사전 학습 중 224 × 224 해상도의 무작위 Image 크롭을 사용하며, Fine-tuning 시 384 × 384로 증가. 사전 학습 데이터셋은 총 14M Image를 포함하며, 인간 주석 데이터셋(COCO, Visual Genome)과 웹 데이터셋(Conceptual Captions, Conceptual 12M, SBU Captions)을 사용. 추가로 115M Image의 더 노이즈가 많은 LAION 데이터셋도 실험
4.2. Effect of CapFilt
- 다양한 데이터셋으로 사전 학습한 모델을 비교하여 CapFilt의 다운스트림 태스크(Image-Text Retrieval, Image Captioning, Fine-tuned 및 Zero-Shot 설정)에서의 효과를 입증
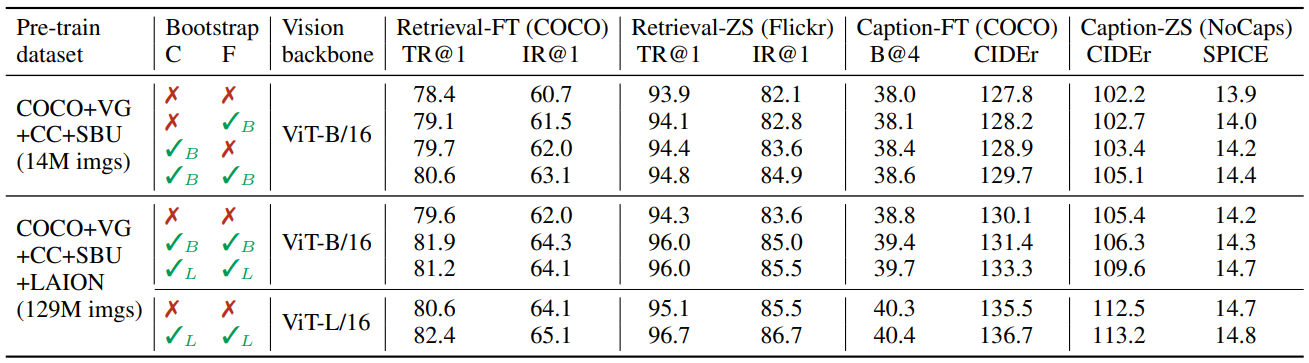
- 위 테이블에서, CapFilt의 Captioner(C)는 합성 캡션을 생성하고, Filter(F)는 노이즈가 많은 웹 이미지-텍스트 쌍을 제거해 데이터 품질을 개선
- 이미지-텍스트 검색(Text Retrieval(TR)과 Image Retrieval(IR)의 Recall@1)과 이미지 캡셔닝(CIDEr 등으로 평가)을 파인튜닝(FT) 및 제로샷(ZS) 설정에서 평가
- ✓B/L은 Captioner 또는 Filter가 ViT-B 또는 ViT-L을 비전 백본으로 사용했음을 의미
- 14M Image 데이터셋에 Captioner 또는 Filter만 적용했을 때 성능 향상이 관찰됨. 두 모듈을 함께 적용하면 상호 보완적으로 작용하여 원본 노이즈 웹 Text 사용 대비 상당한 성능 개선을 달성
- CapFilt는 더 큰 데이터셋과 더 큰 Vision Backbone (ViT-L)에서도 성능을 향상시키며, 데이터와 모델 크기의 확장 가능성을 검증. ViT-L로 구성된 대형 Captioner와 Filter를 사용하면 Base 모델의 성능도 개선

위 그림은, CapFilt 방법에서 웹에서 수집한 원본 텍스트(Tw)와 Captioner가 생성한 합성 텍스트(Ts)의 예시. 녹색 텍스트는 Filter에 의해 수용된(이미지와 잘 맞는) 텍스트이고, 빨간색 텍스트는 Filter에 의해 거부된(노이즈가 많거나 이미지와 맞지 않는) 텍스트
- Captioner는 새로운 Text 설명을 생성하고, Filter는 원본 웹 Text와 합성 Text에서 노이즈 캡션을 제거하는 효과를 정성적으로 보여줌
4.3. Diversity is Key for Synthetic Captions
- CapFilt에서 Nucleus Sampling을 사용해 합성 캡션을 생성
Nucleus Sampling?
- 정의: Nucleus Sampling은 확률적 디코딩 방법으로, 각 토큰을 생성할 때 누적 확률 질량이 특정 임계값 (논문에서는 )를 초과하는 토큰 집합(‘nucleus’)에서 랜덤하게 샘플링
- 다양성: Nucleus Sampling은 더 다양한 텍스트를 생성. 확률 분포에서 덜 가능성 있는 토큰도 선택될 수 있어, 생성된 캡션이 데이터셋 내 흔한 패턴을 벗어나 새로운 표현을 포함할 가능성이 높음
- 예시: "A dog running on the beach" 대신 "A playful puppy sprinting along the shore" 같은 변형된 표현이 나올 수 있음
- 장점: 다양성 덕분에 모델이 새로운 시각-언어 관계를 학습할 수 있는 풍부한 정보를 제공
- 단점: 때로는 문법적으로 덜 정확하거나 이미지와 덜 관련된 캡션을 생성할 수 있어, Filter가 노이즈를 제거하는 역할이 중요

- Beam Search와 비교하면, Nucleus Sampling은 Filter의 높은 노이즈 비율에도 불구하고 더 우수한 성능을 보임
Beam Search?
- 정의: Beam Search는 결정적 디코딩 방법으로, 각 단계에서 가장 높은 확률을 가진 개의 시퀀스(beam)를 유지하며 최종적으로 가장 높은 확률의 캡션을 선택
- 장점 - 안정성: Beam Search는 데이터셋에서 자주 등장하는 "안전한" 캡션을 생성하는 경향이 있음
- 단점 - 단조로움: 생성된 캡션은 문법적으로 정확하고 이미지와 관련 있을 가능성이 높지만, 다양성이 부족해 새로운 정보를 추가하지 못할 수 있음
- Nucleus Sampling은 더 다양하고 놀라운 캡션을 생성하여 모델이 혜택을 받을 수 있는 새로운 정보를 포함. 반면 Beam Search는 데이터셋에서 흔한 안전한 캡션을 생성하여 추가 지식을 제공하지 못함
4.4. Parameter Sharing and Decoupling
- 사전 학습 중 Text 인코더와 디코더는 Self-Attention 레이어를 제외한 모든 파라미터를 공유. 14M 웹 Text Image로 사전 학습한 모델의 다양한 파라미터 공유 전략을 평가

- SA 레이어를 제외한 모든 레이어 공유는 공유하지 않는 경우보다 우수한 성능을 보이며, 모델 크기를 줄여 학습 효율성을 향상
- SA 레이어를 공유하면 인코딩과 디코딩 태스크의 충돌로 성능이 저하
- CapFilt 중 Captioner와 Filter는 COCO에서 개별적으로 End-to-End Fine-tuning. 파라미터 공유 시 다운스트림 태스크 성능이 감소하며, 이는 Confirmation Bias로 인해 Captioner의 노이즈 캡션이 Filter에 의해 덜 제거됨 (노이즈 비율 8% vs. 25%)
5. Comparison with State-of-the-arts
5.1. Image-Text Retrieval
- COCO와 Flickr30K 데이터셋에서 Image-to-Text Retrieval (TR)과 Text-to-Image Retrieval (IR)을 평가. 사전 학습 모델을 ITC와 ITM Loss로 Fine-tuning
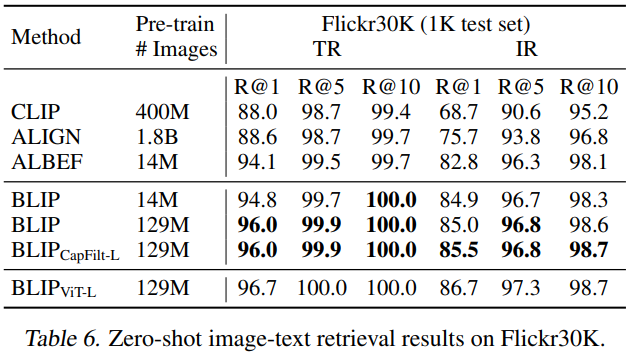
- 추론 속도를 위해 image-text Feature Similarity 기반 k 후보 선택 (COCO k=256, Flickr30K k=128) 후 ITM 점수로 재랭킹
- 기존 방법 대비 큰 성능 향상. 14M 사전 학습 Image 사용 시 ALBEF 대비 COCO 평균 Recall@1 +2.7%. COCO Fine-tuning 모델을 Flickr30K에 Zero-Shot 전이 시 기존 방법 크게 상회
5.2. Image Captioning
- NoCaps와 COCO 데이터셋에서 평가하며, COCO에서 LM Loss로 Fine-tuning한 모델 사용
- COCO: 이미지 캡셔닝의 표준 데이터셋으로, 각 이미지에 5개의 인간 주석 캡션이 제공
- NoCaps: COCO와 유사하지만, 더 다양한 객체 카테고리를 포함하며, 특히 훈련 데이터에 없는 새로운 객체(near-domain, out-of-domain)에 대한 제로샷(Zero-Shot) 성능을 평가
- 캡션 시작에 "a picture of" 프롬프트를 추가하여 약간의 성능 향상
- 아래 테이블은, BLIP과 최신 이미지 캡셔닝 방법들을 NoCaps와 COCO Caption 데이터셋에서 비교한 결과를 보여줌
- 모든 방법은 파인튜닝 시 Cross-Entropy Loss를 사용했으며, 평가 지표는 CIDEr(C), SPICE(S), BLEU@4(B@4)
- CIDEr (C):
- 캡션의 의미적 품질과 인간 주석 캡션과의 유사성을 평가, n-gram 기반 TF-IDF로 정보성을 측정
- 데이터셋 의존적이며, 높은 점수(예: BLIP의 141.4)는 풍부한 내용과 관련성을 나타냄
- 이미지의 주요 내용을 얼마나 잘 설명하는지를 중시, 인간 판단과 유사
- 예시: 이미지 "해변에서 달리는 강아지"에 "A dog runs on the beach"는 참조 캡션과 유사해 높은 CIDEr 점수
- SPICE (S):
- 캡션의 시맨틱 정확성을 평가, 객체·속성·관계의 의미 그래프 일치도로 F1 스코어 계산
- 문법보다 이미지와의 의미적 관련성을 중시, NoCaps에서 BLIP의 16.9 점수로 제로샷 성능 입증
- 새로운 객체(out-of-domain) 묘사에 유용, 데이터셋 분포에 덜 의존
- 예시: "A playful dog runs on the beach"는 객체("dog", "beach"), 관계("runs on")가 맞아 높은 SPICE 점수
- BLEU@4 (B@4):
- 생성 캡션과 참조 캡션 간 4-gram 일치도를 측정, 문법적 유사성과 구문 정확성 평가
- Brevity Penalty로 짧은 캡션 패널티 부여, BLIP의 41.2 점수는 유사한 표현 생성 능력 보여줌
- 의미보다는 표면적 일치에 초점, 창의적 표현에는 낮은 점수 가능
- 예시: "A dog is running on the beach"는 참조 캡션과 4-gram("dog is running on") 일치로 높은 BLEU@4 점수
- CIDEr (C):
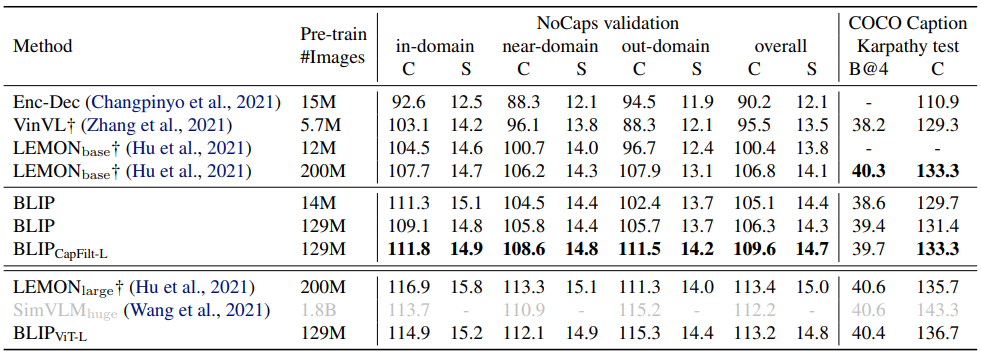
- BLIP (14M): 14M 이미지로 사전 학습, COCO에서 CIDEr 136.7, NoCaps에서 CIDEr 113.2로 기존 모델(VinVL, SimVLM) 대비 우수
- BLIP_CapFilt-L (129M): ViT-L과 CapFilt로 부트스트랩된 129M 이미지로 학습, COCO에서 CIDEr 141.4, NoCaps에서 CIDEr 121.6으로 LEMON(200M)과 경쟁적
- VinVL†, LEMON†: 2.5M 인간 주석 바운딩 박스와 고해상도(800×1333) 필요. BLIP은 Detector-Free, 저해상도(384×384)로 더 효율적
- SimVLM_huge: 13배 큰 데이터와 더 큰 비전 백본 사용, BLIP_CapFilt-L이 적은 데이터로도 비슷하거나 우수한 성능
결론: BLIP는 CapFilt와 Detector-Free 방식으로 데이터 효율성과 계산 효율성을 높이며, 제로샷(NoCaps)과 파인튜닝(COCO)에서 최신 방법들을 상회
5.3. Visual Question Answering (VQA)
- VQA는 Image와 질문에 대한 답변 예측. Multi-Answer Classification 대신 Answer Generation 태스크로 공식화하여 Open-Ended VQA 가능
- Fine-tuning 시 사전 학습 모델을 재배치하여 Image-질문을 멀티모달 임베딩으로 인코딩 후 Answer Decoder에 전달. LM Loss로 Ground-Truth 답변을 타겟으로 Fine-tuning
- 14M Image 사용 시 ALBEF 대비 Test Set +1.64%. 129M Image 사용 시 13배 데이터와 더 큰 Vision Backbone 사용 SimVLM보다 우수
5.4. Natural Language Visual Reasoning (NLVR2)
- NLVR2는 두 Image에 대한 문장이 설명하는지 예측. 이전 접근보다 계산 효율적인 아키텍처로 사전 학습 모델 수정
- Image-Grounded Text Encoder의 각 Transformer 블록에서 두 Image를 처리하는 두 Cross-Attention 레이어 추가, 출력 병합 후 FFN 전달. 두 CA 레이어는 사전 학습 가중치로 초기화. 병합 레이어는 첫 6 레이어에서 평균 풀링, 6-12 레이어에서 연결 후 Linear Projection. [Encode] 토큰 출력에 MLP Classifier 적용
- 기존 방법 대부분 상회하나, ALBEF는 맞춤 사전 학습으로 우수. 웹 데이터 추가 시 성능 향상이 적음 (웹 데이터와 다운스트림 데이터 도메인 갭 때문)
5.5. Visual Dialog (VisDial)
- VisDial은 대화 설정에서 VQA 확장으로, Image-질문 pair뿐만 아니라 대화 히스토리와 Image 캡션을 고려해 답변 예측. Discriminative 설정에서 답변 후보 풀 랭킹
- Image와 캡션 임베딩을 연결하여 Cross-Attention으로 Dialog Encoder에 전달. ITM Loss로 전체 대화 히스토리와 Image-캡션 임베딩 주어 질문 답변이 참/거짓 구별
- VisDial v1.0 Validation Set에서 State-of-the-Art 성능 달성
5.6. Zero-Shot Transfer to Video-Language Tasks
- Image-언어 모델은 Video-Language 태스크에 강력한 일반화 능력을 보임. COCO-Retrieval과 VQA 학습 모델을 Text-to-Video Retrieval과 Video Question Answering에 Zero-Shot 전이
- 비디오 입력 처리 위해 비디오당 n 프레임 (Retrieval n=8, QA n=16) 균등 샘플링 후 feature를 단일 시퀀스로 연결. 시간 정보 무시
- 도메인 차이와 시간 모델링 부재에도 두 Video-Language 태스크에서 State-of-the-Art 성능 달성. Text-to-Video Retrieval에서 Zero-Shot BLIP는 타겟 비디오 데이터셋 Fine-tuning 모델 대비 Recall@1 +12.4%. ViT를 TimeSformer로 대체하고 비디오 데이터 Fine-tuning 시 추가 성능 향상 가능
6. Additional Ablation Study
- CapFilt 향상은 더 긴 학습 때문이 아님. Bootstrapped 데이터셋이 원본보다 더 많은 Text를 포함하므로, 원본 데이터셋에서 웹 Text 복제하여 학습 샘플 수 동일하게 조정. 노이즈 웹 Text로 더 긴 학습은 성능 향상 없음
- Bootstrapped 데이터셋으로 새로운 모델 학습. 이전 사전 학습 모델에서 계속 학습 시 성능 도움 없음. 이는 Knowledge Distillation의 일반 관행과 일치하며, Student 모델은 Teacher로부터 초기화되지 않음
7. Conclusion
- BLIP를 제안하며, 이는 이해 기반과 생성 기반을 포함한 광범위한 다운스트림 Vision-Language 태스크에서 State-of-the-Art 성능을 보이는 새로운 VLP 프레임워크임
- BLIP는 대규모 노이즈 image-text pair에서 다양한 합성 캡션을 주입하고 노이즈 캡션을 제거하는 데이터셋 부트스트래핑으로 Multimodal Mixture of Encoder-Decoder 모델을 사전 학습
- 부트스트랩 데이터셋을 공개하여 미래 Vision-Language 연구 촉진
- BLIP 성능 향상을 위한 잠재 방향:
- (1) 데이터셋 부트스트래핑 여러 라운드
- (2) Image당 여러 합성 캡션 생성으로 사전 학습 코퍼스 확대
- (3) 여러 Captioner와 Filter 학습 후 앙상블로 CapFilt 강화. 모델과 데이터 측면 개선을 장려하여 Vision-Language 연구의 기반 강화

AI Research Engineer