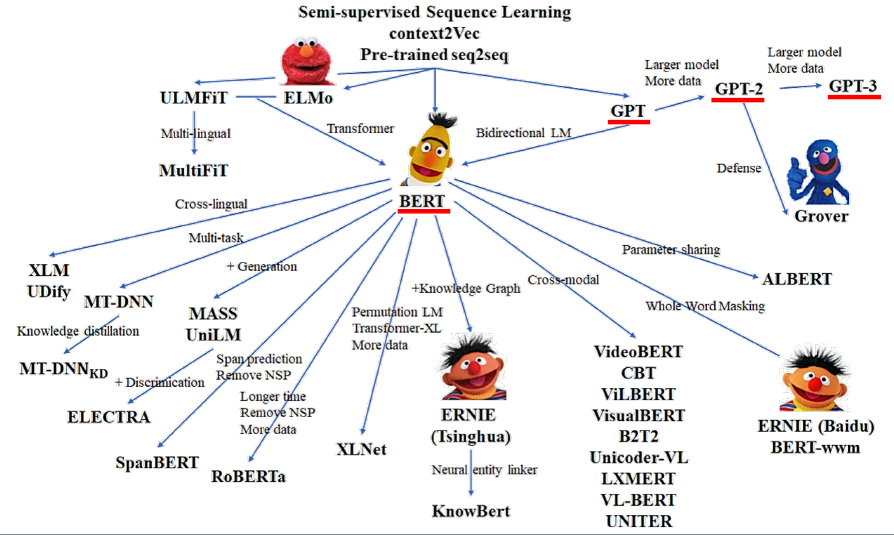
자연어 처리
인간의 자연어처리
대화의 단계
- 화자는 자연어 형태로 객체를 인코딩
- 메세지의 전송
- 청자는 자연어를 객체로 디코딩
화자는 청자가 이해할 수 있는 방법으로 이쁘게 인코딩
청자는 본인 지식을 바탕으로 디코딩
컴퓨터의 자연어처리
대화의 단계
- Encoder는 벡터 형태로 자연어를 인코딩
- 메세지의 전송
- Decoder는 벡터를 자연어로 디코딩
Encoder는 Decoder가 이해할 수 있는 방법으로 인코딩
Decoder는 본인 지식을 바탕으로 디코딩
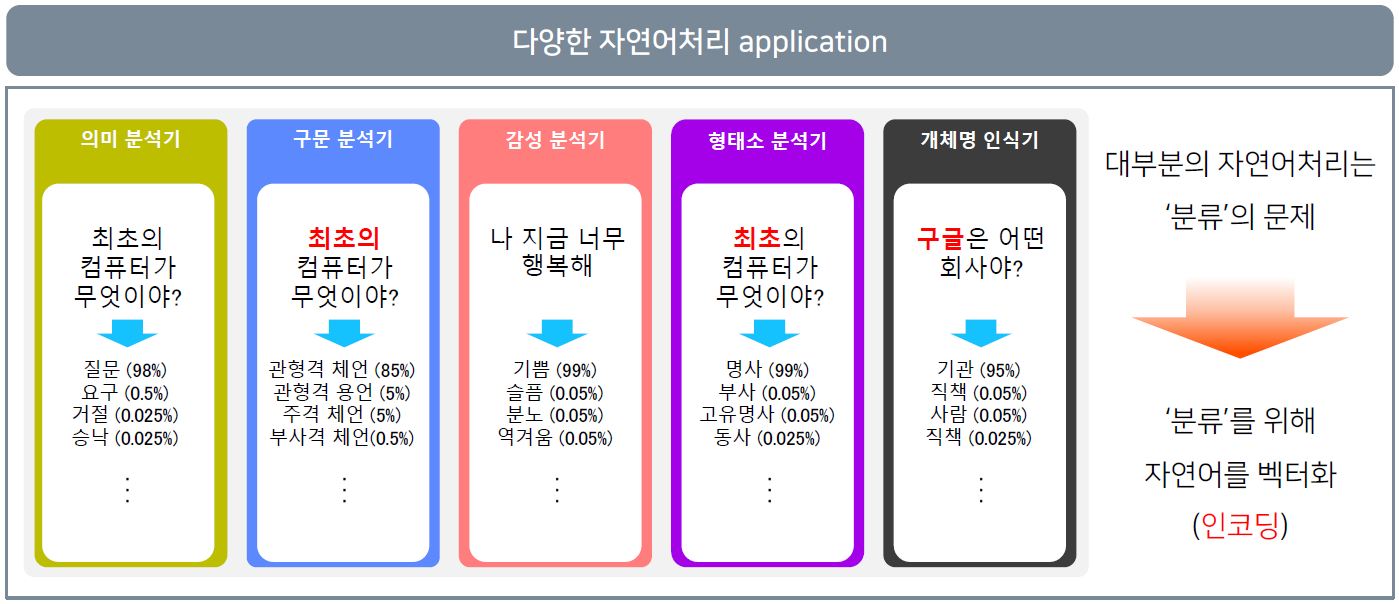
자연어 단어 임베딩
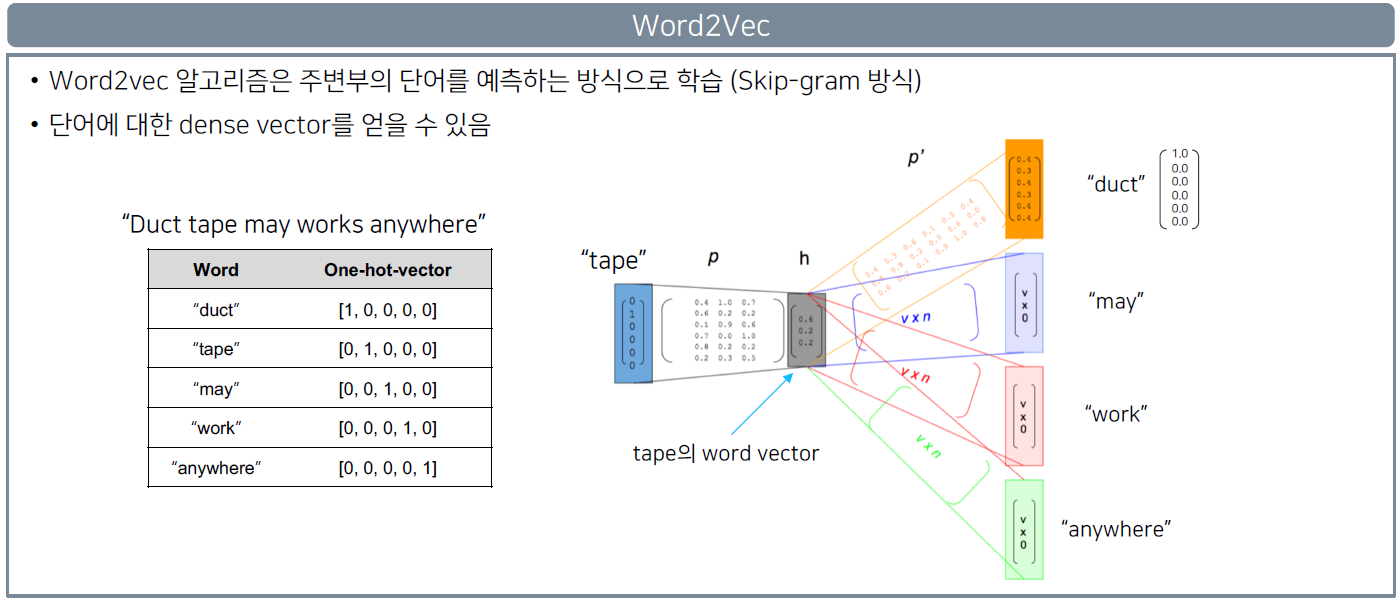
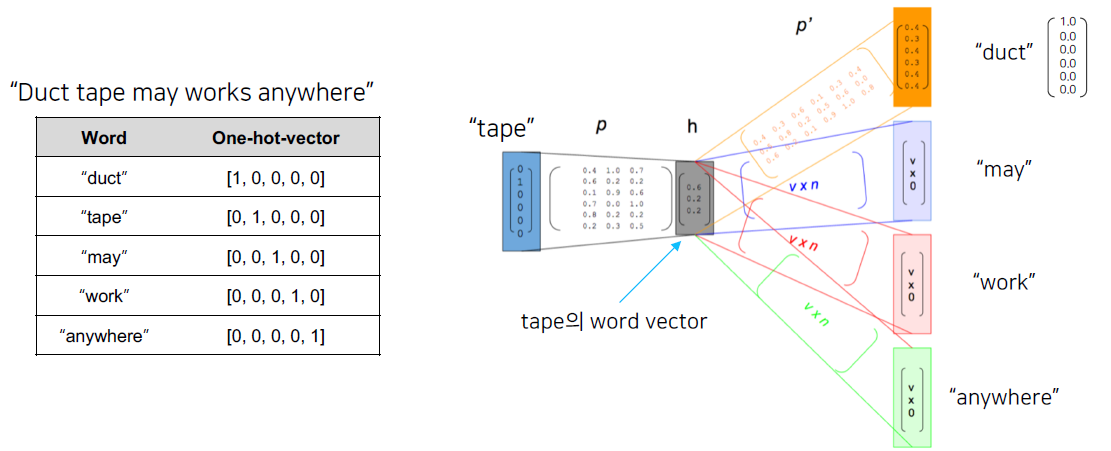
Word2Vec
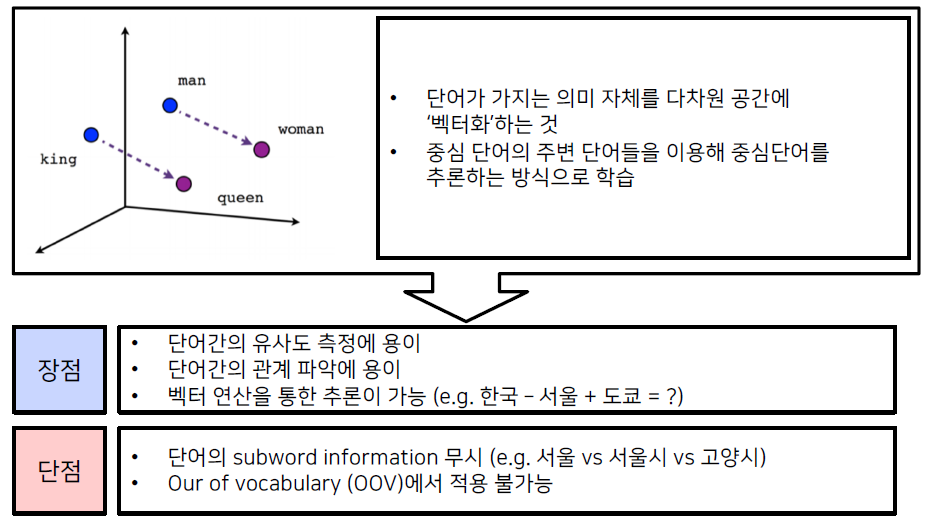
Word2vec (word to vector) 알고리즘: 자연어 (특히 단어)의 의미를 벡터 공간에 임베딩
한 단어의 주변 단어들을 통해 그 단어의 의미를 파악한다.

Word2vec 알고리즘은 주변부의 단어를 예측하는 방식으로 학습한다.
(Skip-gram 방식)
단어에 대한 dense vector를 얻을 수 있다.
FastText

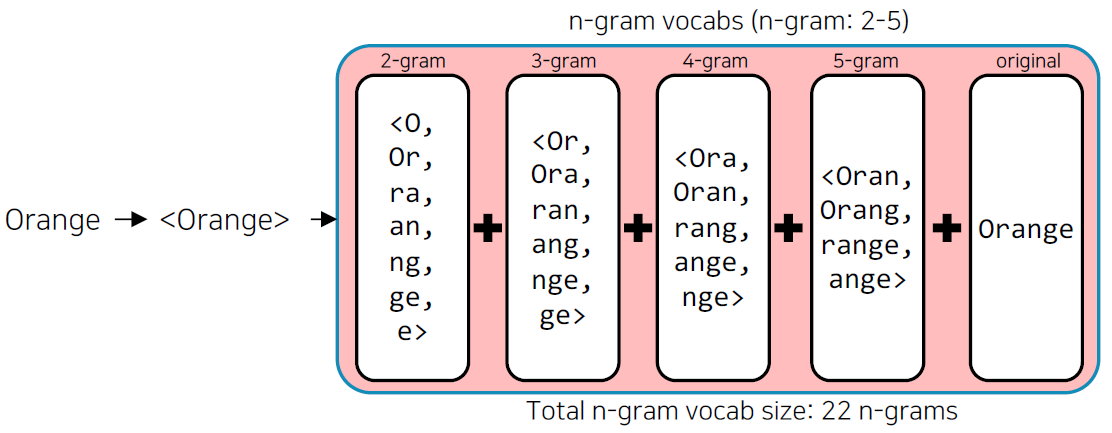
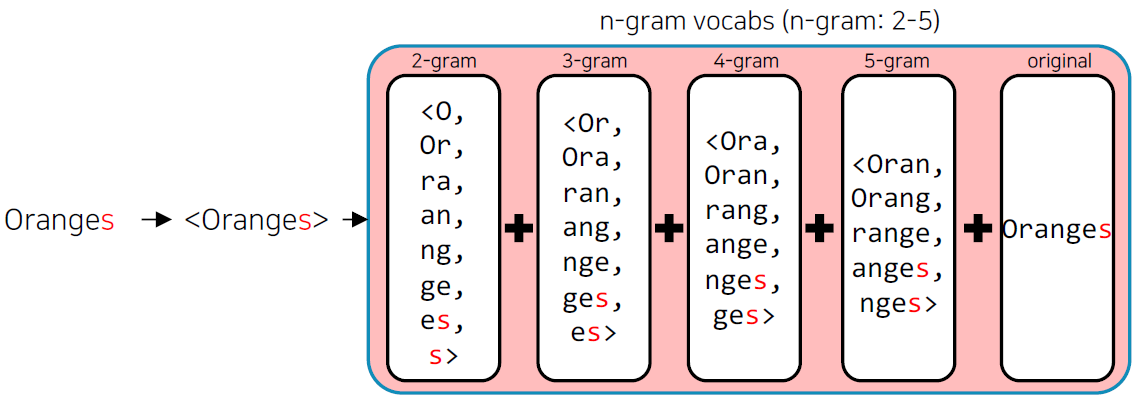
- 기존의 word2vec과 유사하나, 단어를 n-gram으로 나누어 학습을 수행한다.
- n-gram의 범위가 2-5일 때, 단어를 다음과 같이 분리하여 학습한다.
- "assumption" = as, ss, su, ..., ass, ssu, sum, ump, mpt, ..., ption, assumption}
- 이 때, n-gram으로 나눠진 단어는 사전에 들어가지 않으며, 별도의 n-gram vector를 형성한다.
FastText는 단어를 n-gram으로 분리를 한 후, 모든 n-gram vector를 합산한 후 평균을 통해 단어 벡터를 획득한다.
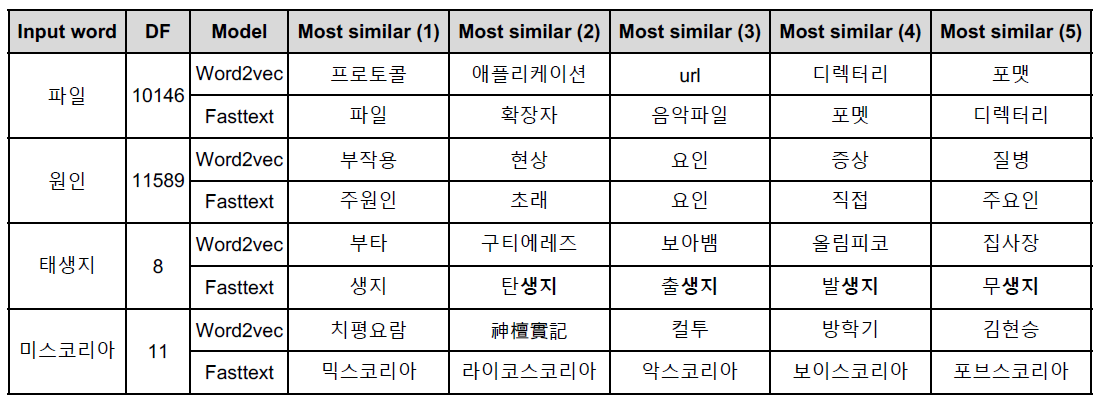
오탈자, OOV, 등장 회수가 적은 학습 단어에 대해서 강세
단어 임베딩 방식의 한계점
Word2Vec이나 FastText와 같은 word embedding 방식은 동형어, 다의어 등에 대해선 embedding 성능이 좋지 못하다는 단점이 있다.
(뜻이 여러개인 경우 그 모든 의미를 가지려하기 때문에 이도저도 아닌 벡터값을 갖는다.)
주변 단어를 통해 학습이 이루어지기 때문에, '문맥'을 고려할 수 없다.
언어 모델
'자연어'의 법칙을 컴퓨터로 모사한 모델 → 언어 '모델'
- 주어진 단어들로부터 그 다음에 등장한 단어의 확률을 예측하는 방식으로 학습 (이전 state로 미래 state를 예측)
- 다음의 등장할 단어를 잘 예측하는 모델은 그 언어의 특성이 잘 반영된 모델이자, 문맥을 잘 계산하는 좋은 언어 모델
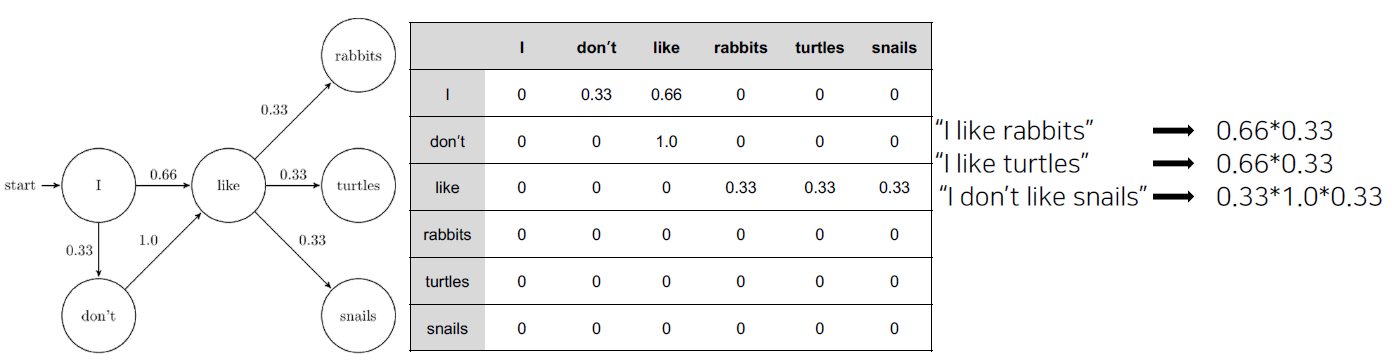
Markov 기반의 언어모델
마코프 체인 모델 (Markov Chain Model)
- 초기의 언어 모델은 다음의 단어나 문장이 나올 확률을 통계와 단어의 n-gram을 기반으로 계산
- 딥러닝 기반의 언어모델은 해당 확률을 최대로 하도록 네트워크를 학습
Recurrent Neural Network(RNN) 기반의 언어모델
RNN은 히든 노드가 방향을 가진 엣지로 연결돼 순환구조를 이룬다.
(directed cycle)
- 이전 state 정보가 다음 state를 예측하는데 사용됨으로써, 시계열 데이터 처리에 특화
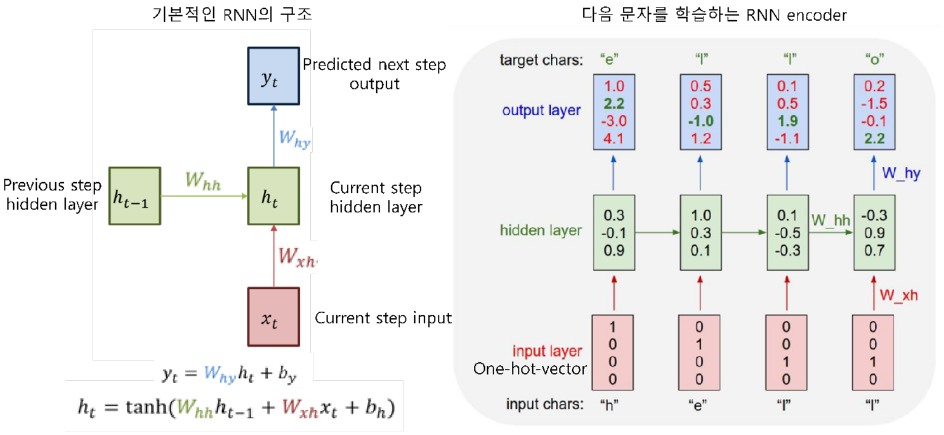
-
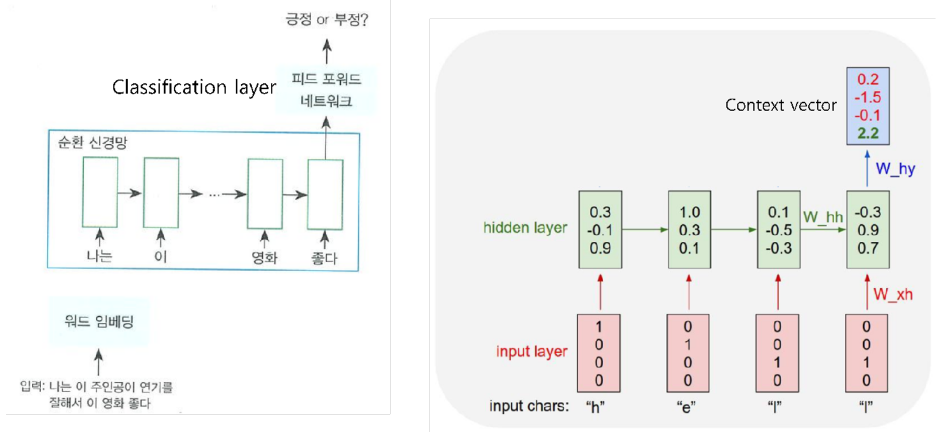
마지막 출력은 앞선 단어들의 '문맥' 을 고려해서 만들어진 최종 출력 vector → Context vector
-
출력된 context vector 값에 대해 classification layer를 붙이면 문장 분류를 위한 신경망 모델
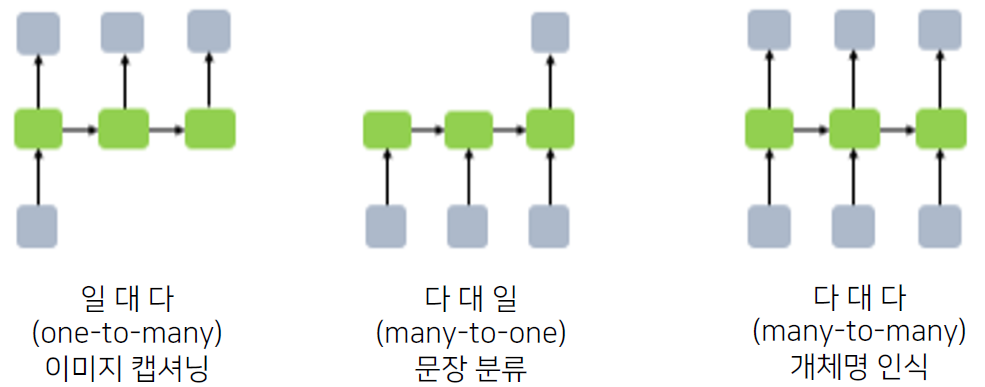
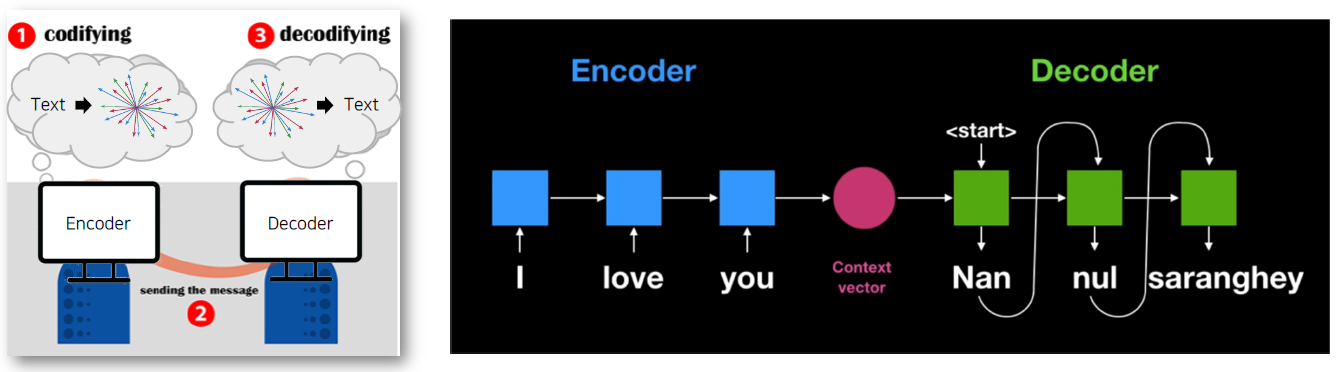
Recurrent Neural Network(RNN) 기반의 Seq2Seq
Encoder layer: RNN구조를 통해 Context vector 를 획득
Decoder layer: 획득된 Context vector를 입력으로 출력을 예측
Attention
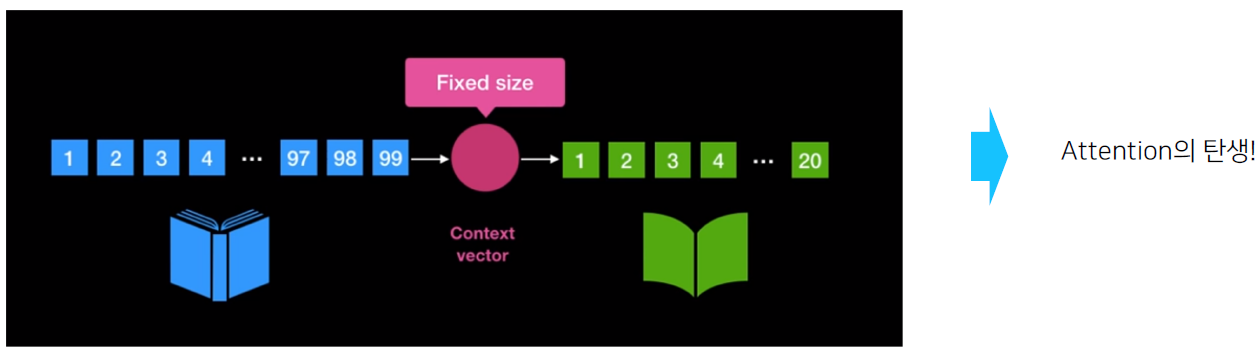
RNN 구조의 문제점
- 입력 sequence의 길이가 매우 긴 경우 처음에 나온 token에 대한 정보가 희석된다.
- 고정된 context vector 사이즈로 인해 긴 sequence에 대한 정보를 함축하기 어렵다
- 모든 token이 영향을 미치니 중요하지 않은 token도 영향을 준다.
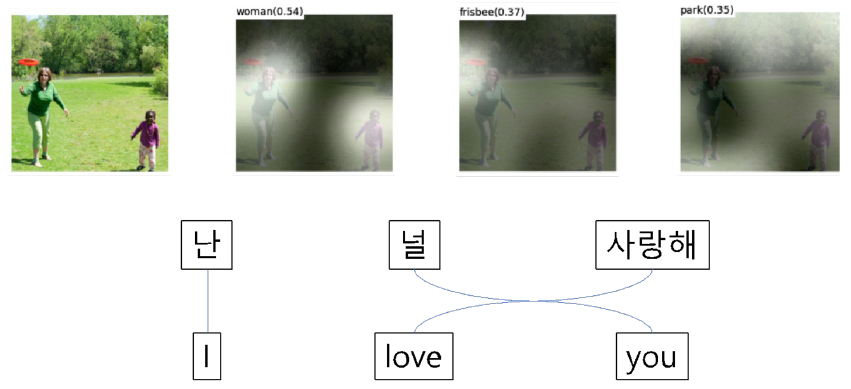
- 인간이 정보처리를 할 때 모든 sequence를 고려하면서 정보처리를 하는 것이 아니다.
- 인간의 정보처리와 마찬가지로 중요한 feature는 더욱 중요하게 고려하는 것이 Attention의 모티브
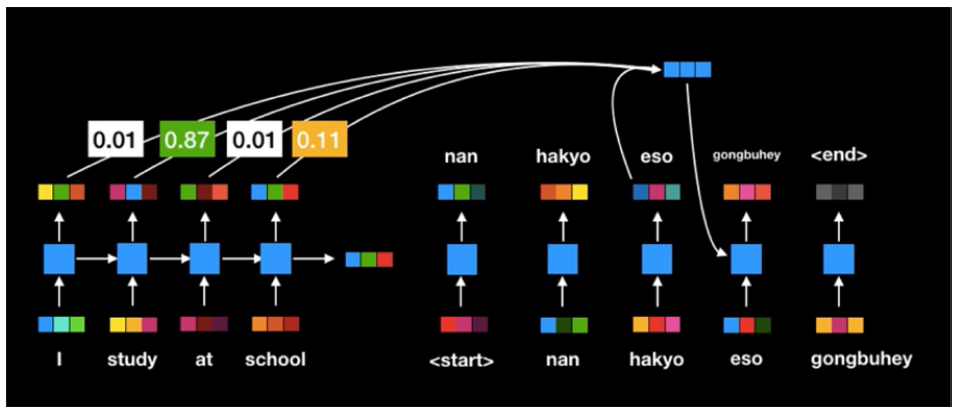
- 문맥에 따라 동적으로 할당되는 encode의 Attention weight로 인한 dynamic context vector를 획득한다.
- 기존 Seq2Seq의 encoder, decoder 성능을 비약적으로 향상시켰다.
하지만 여전히 RNN이 순차적으로 연산이 이뤄짐에 따라 연산 속도가 느리다.
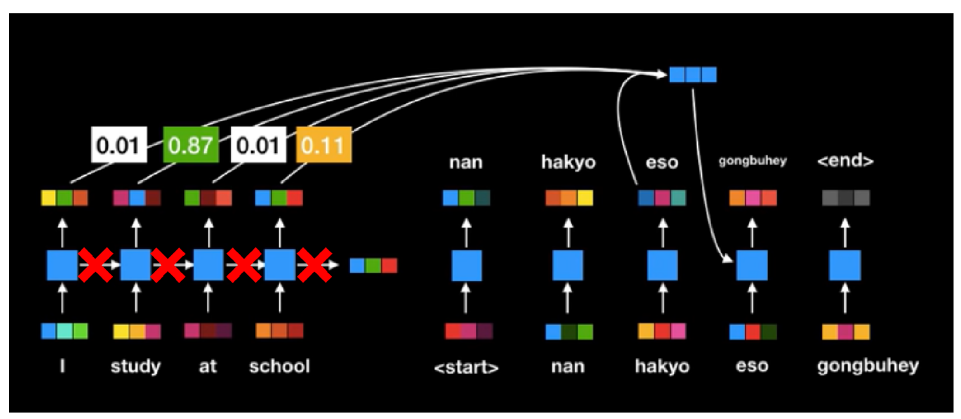
Self-attention 모델
Transformer
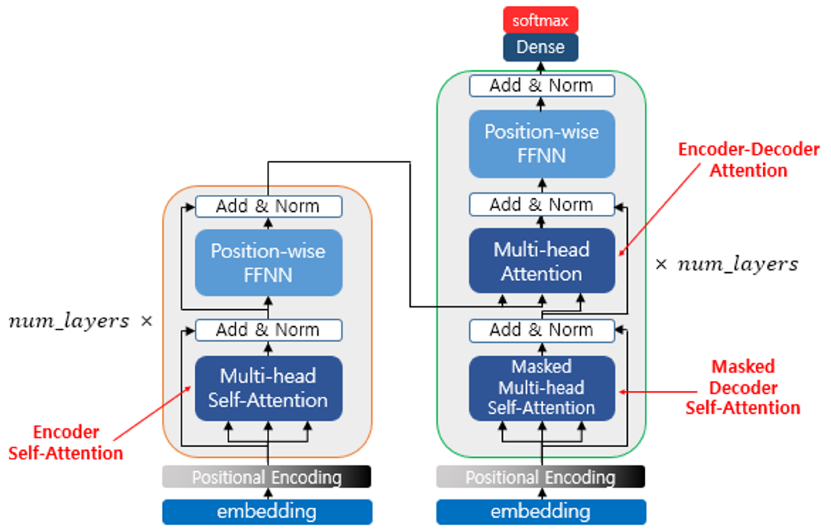
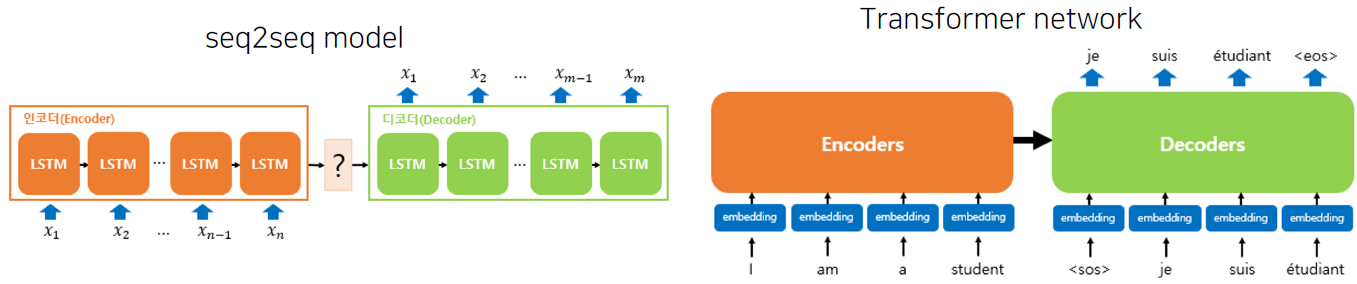
현재 쓰이는 BERT, GPT 등은 모두 Transformer 기반의 모델이다.