자연어 전처리
Task 설계 → 필요 데이터 수집 → 통계학적 분석 → 전처리 → Tagging → Tokenizing → 모델 설계 → 모델 구현 → 성능 평가 → 완료
Task의 성능을 가장 확실하게 올릴 수 있는 방법이다.
주로 python의 string 관련 함수와 정규표현식 모듈(re)을 사용한다.
통계학적 분석
Token 개수 → 아웃라이어 제거
빈도 확인 → 사전(dictionary) 정의
전처리
- 개행문자 제거
- 특수문자 제거
- 공백 제거
- 중복 표현 제어 (ㅋㅋㅋㅋㅋ, ㅠㅠㅠㅠ, ...)
!pip install soynlpfrom soynlp.normalizer import *
print(repeat_normalize('와하하하하하하하하하핫', num_repeats=2))
# 와하하핫- 이메일, 링크 제거
- 제목 제거
- 불용어 (의미가 없는 용어) 제거
- 조사 제거
- 띄어쓰기, 문장분리 보정
!pip install git+https://github.com/haven-jeon/PyKoSpacing.gitfrom pykospacing import spacing
spacing('아버지가방에들어가신다.')
# '아버지가 방에 들어가신다.'!pip install git+https://github.com/ssut/py-hanspell.gitfrom hanspell import spell_checker
spell_checker.check('마춤뻡 너무 어렵따')
Checked(result=True, original='마춤뻡 너무 어렵따', checked='맞춤법 너무 어렵다', errors=2, words=OrderedDict([('맞춤법', 1), ('너무', 0), ('어렵다', 1)]), time=0.14646434783935547)- Filtering
유니코드 기반으로 사용하지 않는 언어를 제거할 수 있다.
sentence = 'hello world'
print('* 원본 문장')
print(sentence)
# hello world
print('\n* 10진수로 표현된 유니코드')
for w in sentence:
print(ord(w), end=' ') # 문자 -> 10진수 변환
# 104 101 108 108 111 32 119 111 114 108 100
print('\n\n* 16진수로 표현된 유니코드')
for w in sentence:
print(hex(ord(w)), end=' ') # 문자 -> 16진수 변환
# 0x68 0x65 0x6c 0x6c 0x6f 0x20 0x77 0x6f 0x72 0x6c 0x64 대소문자 변환
| 함수 | 설명 |
|---|---|
| upper() | 모두 대문자로 변환 |
| lower() | 모두 소문자로 변환 |
| capitalize() | 문자열의 첫 문자를 대문자로 변환 |
| title() | 문자열에서 각 단어의 첫 문자를 대문자로 변환 |
| swapcase() | 대문자와 소문자를 서로 변환 |
편집, 치환
| 함수 | 설명 |
|---|---|
| strip() | 좌우 공백을 제거 |
| rstrip() | 오른쪽 공백을 제거 |
| lstrip() | 왼쪽 공백을 제거 |
| replace(a,Sb) | a를 b로 치환 |
분리, 결합
| 함수 | 설명 |
|---|---|
| split() | 공백으로 분리 |
| split('\t') | 탭을 기준으로 분리 |
| ''.join(s) | 리스트 s에 대하여 각 요소 사이에 공백을 두고 결합 |
| lines.splitlines() | 라인 단위로 분리 |
구성 문자열 판별
| 함수 | 설명 |
|---|---|
| isdigit() | 숫자 여부 판별 |
| isalpha() | 영어 알파벳 여부 판별 |
| isalnum() | 숫자 혹은 영어 알파벳 여부 판별 |
| islower() | 소문자 여부 판별 |
| isupper() | 대문자 여부 판별 |
| isspace() | 공백 문자 여부 판별 |
| startswith(‘hi’) | 문자열이 hi로 시작하는지 여부 파악 |
| endswith(‘hi’) | 문자열이 hi로 끝나는지 여부 파악 |
검색
| 함수 | 설명 |
|---|---|
| count('hi') | 문자열에서 hi가 출현한 빈도 리턴 |
| find('hi') | 문자열에서 hi가 처음으로 출현한 위치 리턴, 존재하지 않는 경우 -1 |
| find('hi', 3) | 문자열의 index에서 3번부터 hi가 출현한 위치 검색 |
| rfind('hi') | 문자열에서 오른쪽부터 검사하여 hi가 처음으로 출현한 위치 리턴, 존재하지 않는 경우 -1 |
| index('hi') | find와 비슷한 기능을 하지만 존재하지 않는 경우 예외발생 |
| rindex('hi') | rfind와 비슷한 기능을 하지만 존재하지 않는 경우 예외발생 |
Tokenizing
자연어를 어떤 단위로 살펴볼 것인가
- 어절 tokenizing
- 형태소 tokenizing
- WordPiece tokenizing
현실에서는 예측과 많이 다른 상황이 많이 발생한다.
상상하고, 예상하고, 수집한 악성 댓글
게임 진짜 ** 못하네
**충 **같다 ㅋㅋ
수듄 ㅋㅋㅋㅋㅋ **이세요?
실제 유튜브 라이브 악성 댓글
이래서 여자한테 게임하게 시키면 안된다
수준 오지고 지리고 레릿고
멘탈 개복치냐고 ㅋㅋ
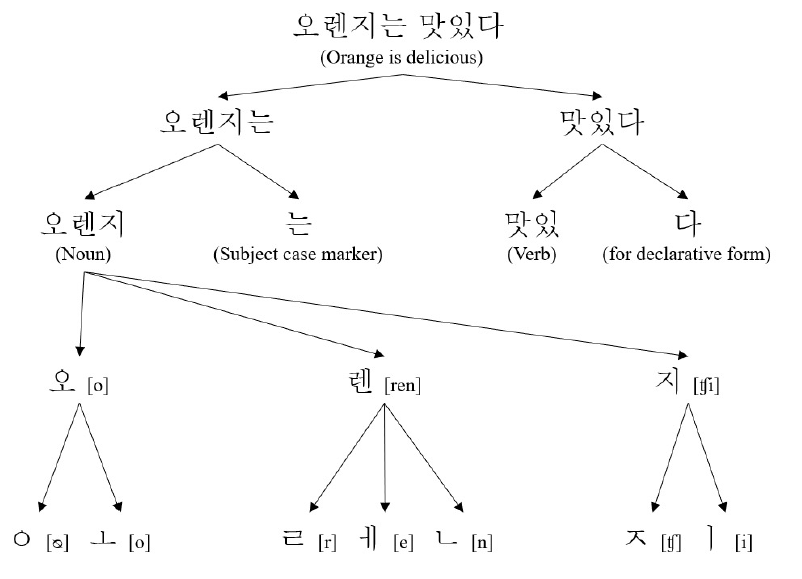
토큰화
토큰화(Tokenizing)
- 주어진 데이터를 토큰(Token)이라 불리는 단위로 나누는 작업
- 토큰이 되는 기준은 다를 수 있음(어절, 단어, 형태소, 음절, 자소 등)
문장 토큰화(Sentence+Tokenizing)
- 문장 분리
# 한국어 문장분리기
!pip install ksskss.split_sentences('나는 생각한다. 고로 살아있다.')
# ['나는 생각한다.', '고로 살아있다.']단어 토큰화(Word+Tokenizing)
- 구두점 분리, 단어 분리
"Hello, World!" -> "Hello", ",", "World", "!"
한국어 토큰화
-
영어는 New York과 같은 합성어 처리와 it's와 같은 줄임말 예외처리만 하면, 띄어쓰기를 기준으로도 잘 동작하는 편이다.
-
한국어는 조사나 어미를 붙여서 말을 만드는 교착어로, 띄어쓰기만으로는 부족하다.
예시) he/him -> 그, 그가, 그는, 그를, 그에게 -
한국어에서는 어절이 의미를 가지는 최소 단위인 형태소로 분리
예시) 안녕하세요 -> 안녕/NNG, 하/XSA, 세/EP, 요/EC
!pip install konlpy
from konlpy.tag import Mecab
mecab = Mecab()
morphs = mecab.pos("아버지가방에들어가신다.", join=False)
print(morphs)
# [('아버지', 'NNG'), ('가', 'JKS'), ('방', 'NNG'), ('에', 'JKB'), ('들어가', 'VV'), ('신다', 'EP+EF'), ('.', 'SF')]
초보 개발자입니다