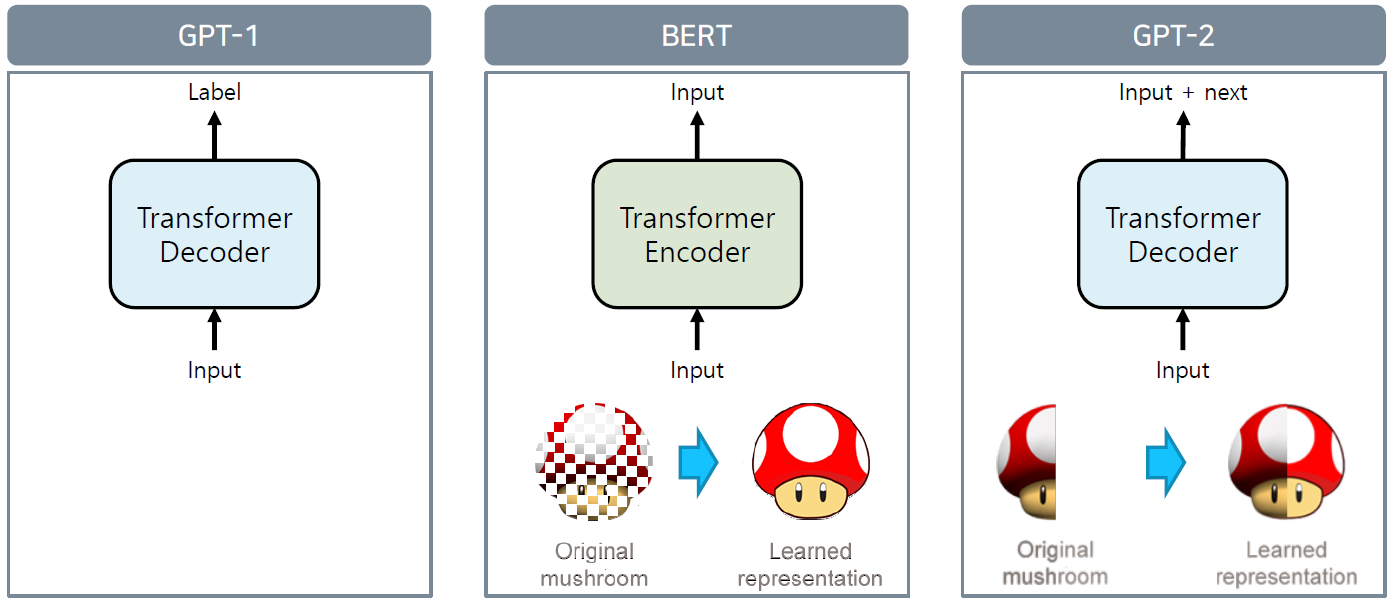
BERT
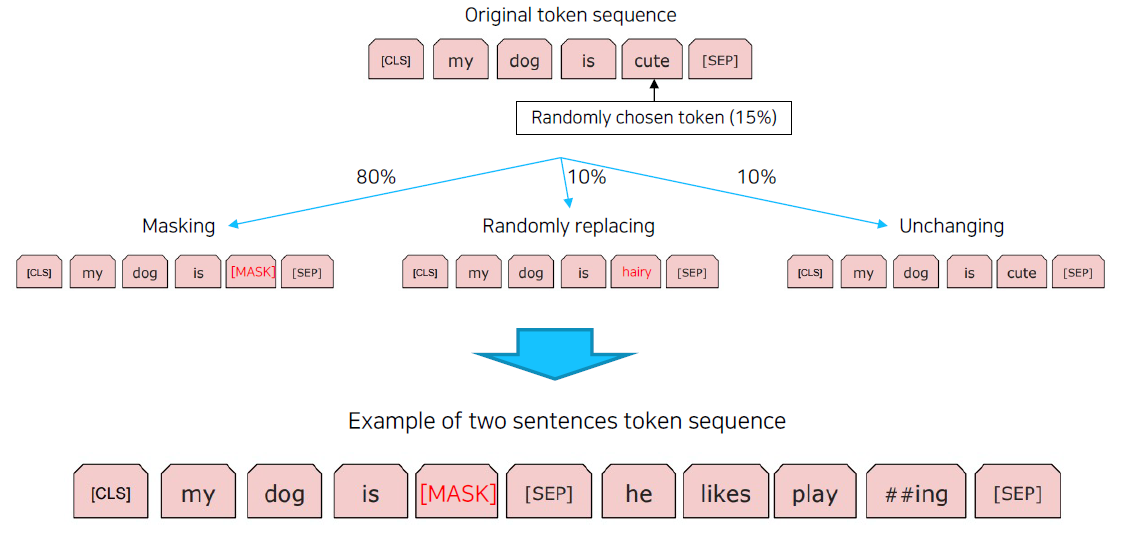
BERT는 문장에 MASK를 만들고, 앞뒤 문맥을 통해 그 MASK를 예측하는 방식으로 pretraine 된다.
학습 코퍼스 데이터
- BooksCorpus (800M words)
- English Wikipedia (2,500M words without lists, tables and headers)
- 30,000 token vocabulary
데이터의 tokenizing
- WordPiece tokenizing
- He likes playing → He likes play ##ing
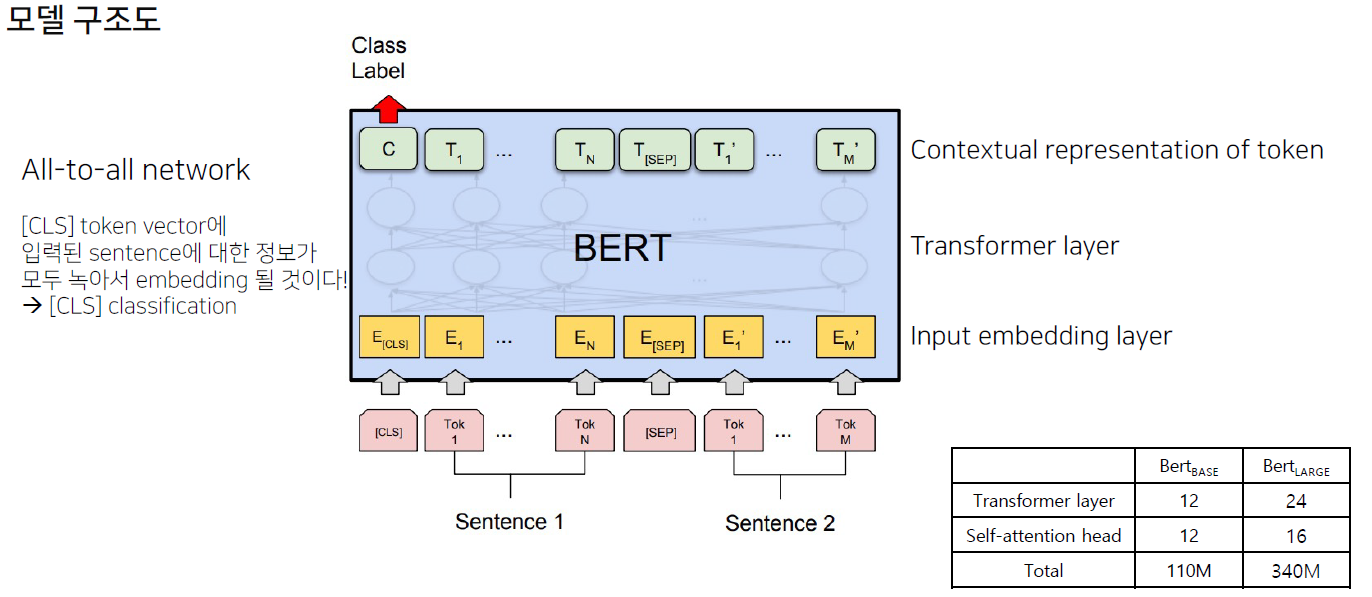
- 입력 문장을 tokenizing하고, 그 token들로 ‘token sequence’를 만들어 학습에 사용
- 2개의 token sequence가 학습에 사용

MLB(Masked Language Model)
BERT Task
단일 문장 분류
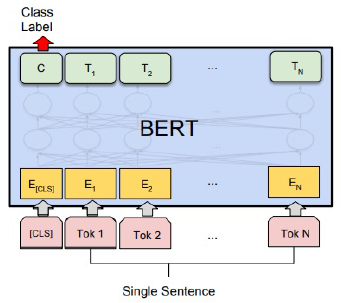
감성 분석
네이버 영화 리뷰 코퍼스 (https://github.com/e9t/nsmc) 로 감성 분석
학습: 150,000 문장 / 평가: 50,000 문장 (긍정: 1, 부정: 0)
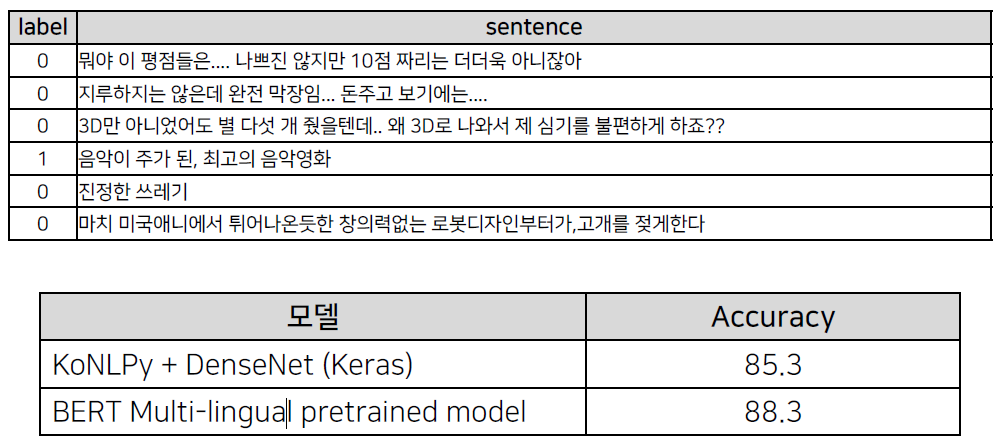
관계 추출
KAIST가 구축한 Silver data 사용 (1명의 전문가가 annotation)
학습: 985,806 문장 / 평가: 100,001 문장
총 81개 label (관계 없음 포함)
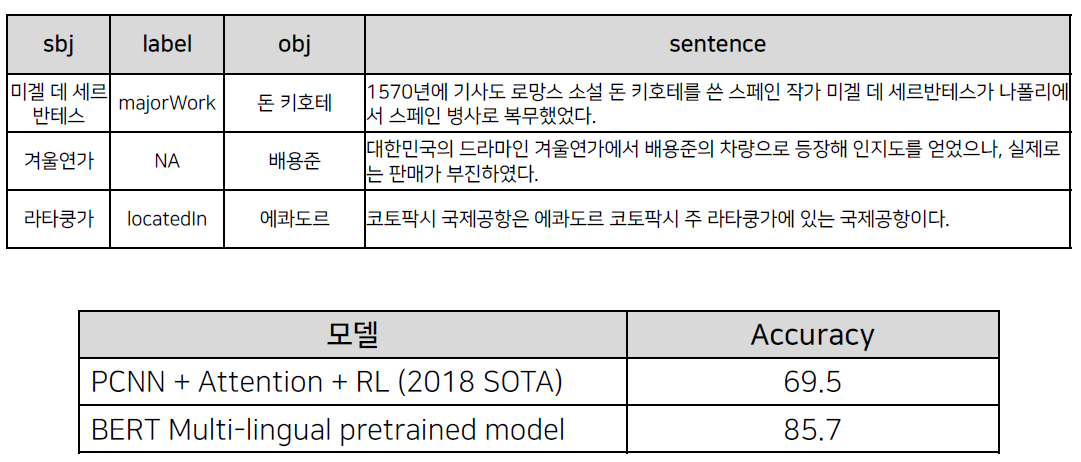
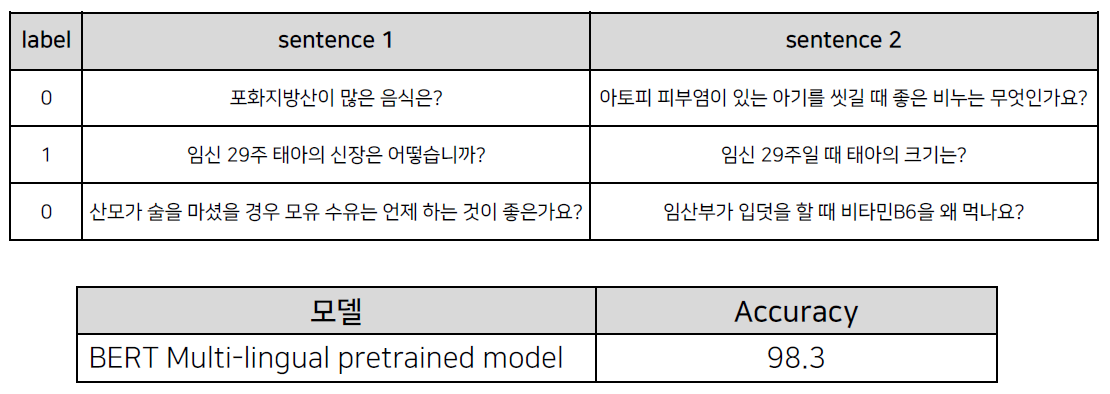
두 문장 관계 분류
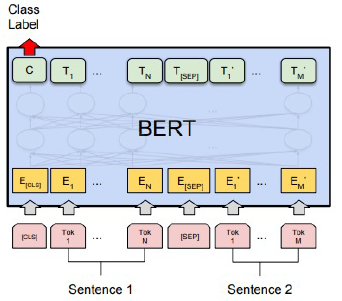
의미 비교
디지털 동반자 패러프레이징 질의 문장 데이터를 이용하여 질문-질문 데이터 생성 및 학습
학습: 3,401 문장 쌍 (유사 X: 1,700개, 유사 O: 1,701개)
평가: 1,001 문장 쌍 (유사 X: 500개, 유사 O: 501개)
문장 토큰 분류
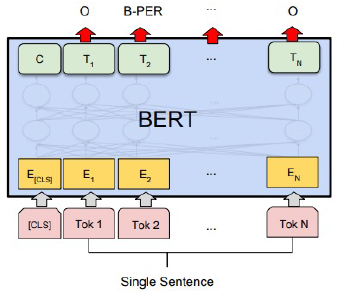
개체명 분석
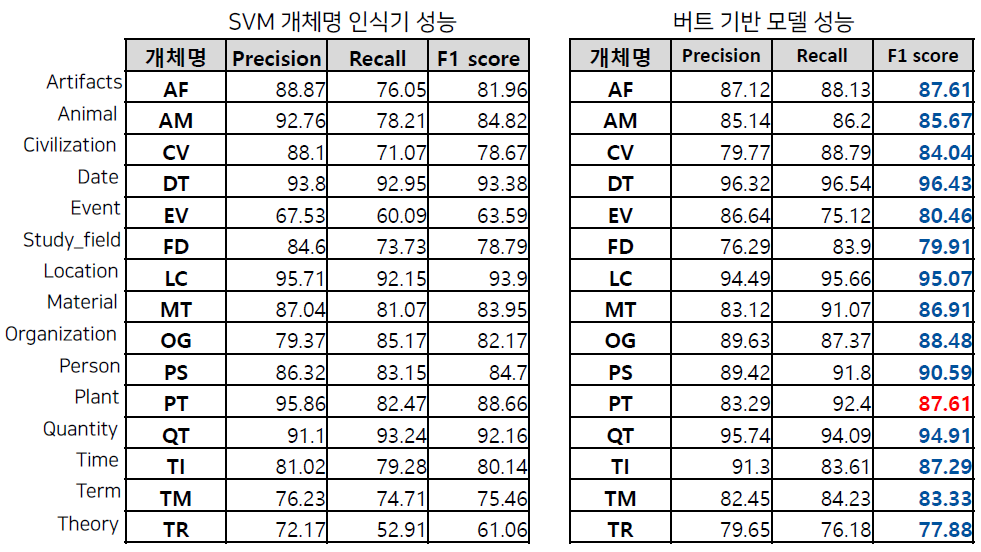
ETRI 개체명 인식 데이터를 활용하여 학습 및 평가 진행 (정보통신단체표준 TTA.KO-10.0852)
학습: 95,787 문장 / 평가: 10,503 문장
기계 독해 정답 분류
기계 독해
LG CNS가 공개한 한국어 QA 데이터 셋, KorQuAD (https://korquad.github.io/)
Wikipedia article에 대해 10,645 건의 문단과 66,181 개의 질의응답(Training set 60,407 개, Dev set 5,774 개)
한국어 BERT 모델
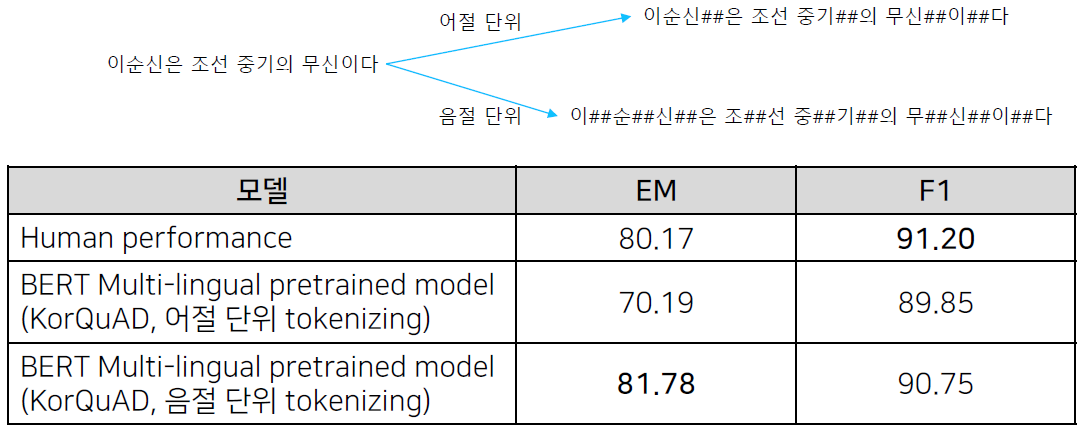
ETRI KoBERT의 tokenizing
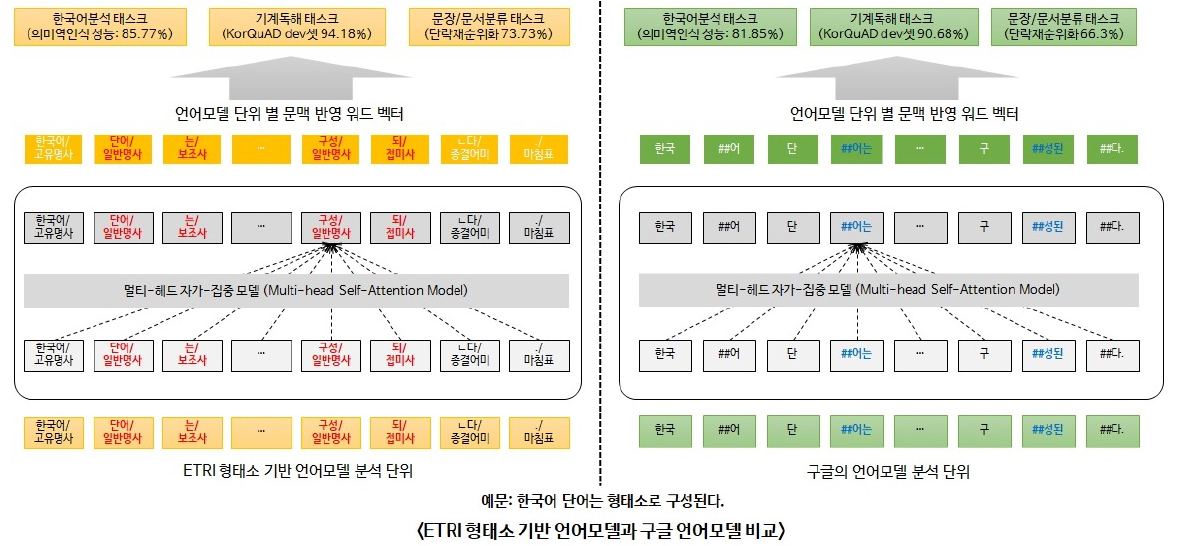
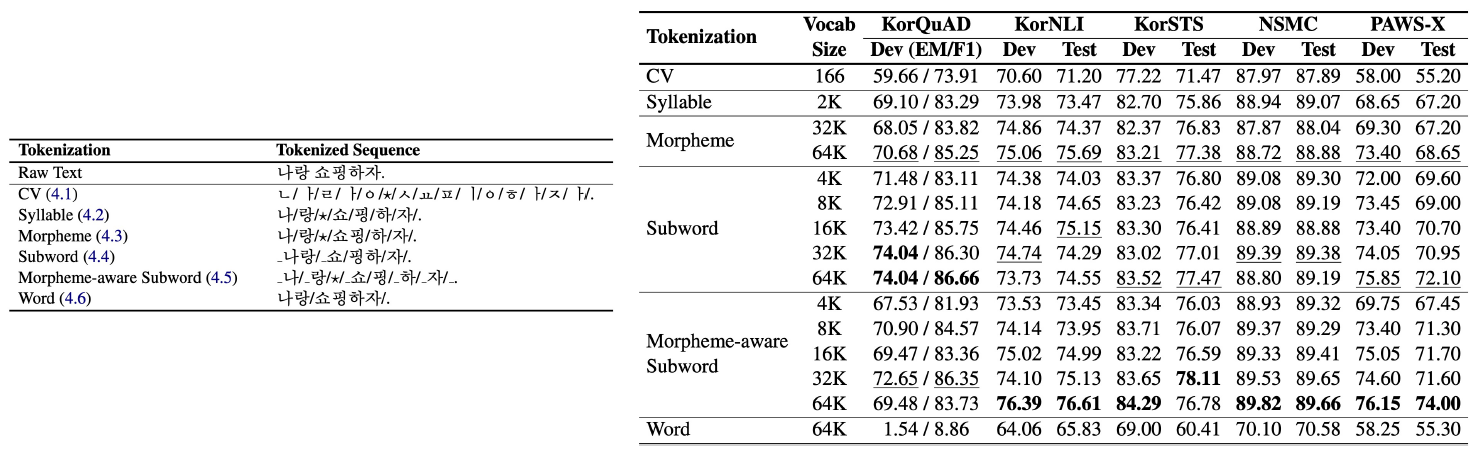
한국어 tokenizing에 따른 성능 비교 (https://arxiv.org/abs/2010.02534)
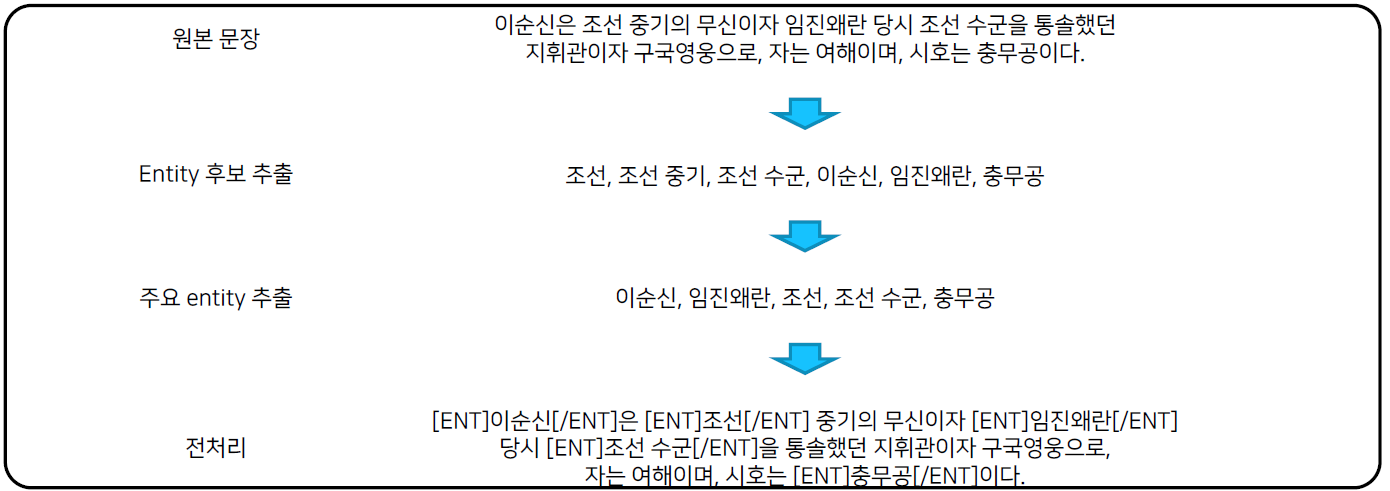
Advanced BERT model
KBQA에서 가장 중요한 entity 정보가 기존 BERT에서는 무시
Entity linking을 통한 주요 entity 추출 및 entity tag 부착
Entity embedding layer의 추가
형태소 분석을 통해 NNP와 entity 우선 chunking masking
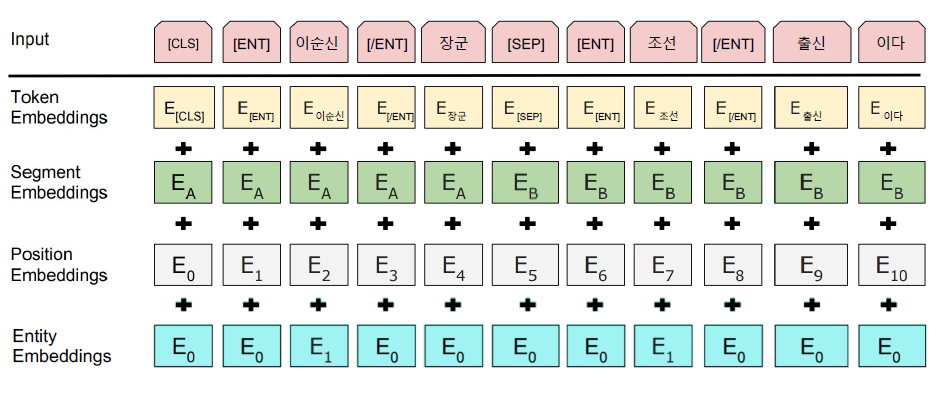
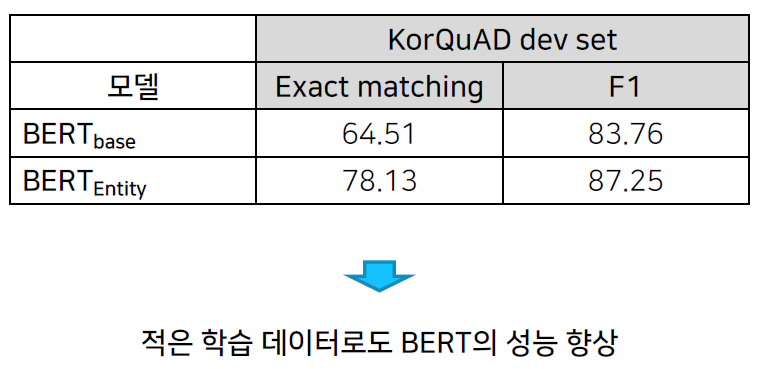
학습 데이터: 2019년 06월 20일 Wiki dump (약 4,700만 어절)
Batch: 128
Sequence length: 512
Training steps: 300,000 (대략 10 epochs)